K-means算法应用:图片压缩
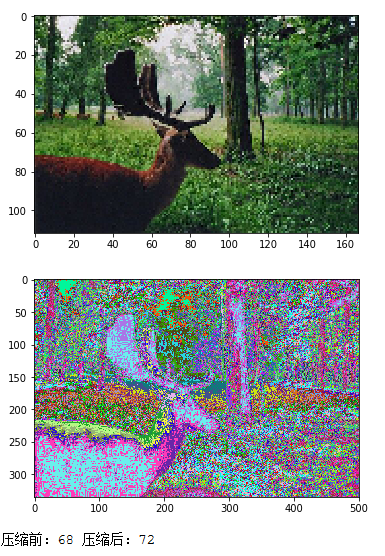
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import matplotlib.image as img import sys #读取一张示例图片或自己准备的图片,观察图片存放数据特点。 milu = img.imread("d:\\milu.jpg") plt.imshow(milu) plt.show() plt.imshow(milu[:,:,2]) print(milu.shape) plt.show() # 根据图片的分辨率,可适当降低分辨率 milus = milu[::3,::3] #降低图片3倍分辨率 plt.imshow(milus) plt.show() # 再用k均值聚类算法,将图片中所有的颜色值做聚类。 import numpy as np milu1 = np.reshape(milu,(-1,3)) #reshape()里面的数组形状第一个为-1,第二个为第二维元素的数目。 n_colors = 64 model = KMeans(n_colors) labels = model.fit_predict(milu1) colors = model.cluster_centers_ # 然后用聚类中心的颜色代替原来的颜色值。 new_milu = colors[labels] #把每个点替换成相对应的类别值 # 还原到原来的维度并转换数据类型 new_milu = new_milu.reshape(imgs.shape) new_milu.astype(np.uint8) #将浮点型数据转换为整型 plt.imshow(new_milu) plt.show() # 将原始图片与新图片保存成文件,观察文件的大小。 plt.imsave('D:\\imgs\\milu.jpg',milu) plt.imsave('D:\\imgs\\new_milu.jpg',new_milu) S1 = sys.getsizeof('D:\\imgs\\milu.jpg') #对比文件大小 S2 = sys.getsizeof('D:\\imgs\\new_milu.jpg') print('压缩前:'+str(S1),"压缩后:"+str(S2))


理解贝叶斯定理:
- M桶:7红3黄
- N桶:1红9黄
- 现在:拿出了一个红球
- 试问:这个红球是M、N桶拿出来的概率分别是多少?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号