为什么系统的Swap变高了(一)
系统的内存资源紧张时,系统又会如何应对呢?
这其实会导致两种可能结果,内存回收和 OOM 杀死进程。
我们这里重点看第一个可能的结果,内存回收,也就是系统释放掉可以回收的内存,比如我前面讲过的缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做文件页(File-backed Page)。
文件页 操作系统级别的语义
大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。
这些脏页,一般可以通过两种方式写入磁盘。
-
可以在应用程序中,通过系统调用 fsync ,把脏页同步到磁盘中;
-
也可以交给系统,由内核线程 pdflush 负责这些脏页的刷新。
除了缓存和缓冲区,通过内存映射获取的文件映射页,也是一种常见的文件页。它也可以被释放掉,下次再访问的时候,从文件重新读取。
除了文件页外,还有没有其他的内存可以回收呢?比如,应用程序动态分配的堆内存,也就是我们在内存管理中说到的匿名页(Anonymous Page),是不是也可以回收呢
我想,你肯定会说,它们很可能还要再次被访问啊,当然不能直接回收了。非常正确,这些内存自然不能直接释放。
但是,如果这些内存在分配后很少被访问,似乎也是一种资源浪费。是不是可以把它们暂时先存在磁盘里,释放内存给其他更需要的进程?
其实,这正是 Linux 的 Swap 机制。Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
Swap 原理
前面提到,Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程。
-
所谓换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
-
而换入,则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
所以你看,Swap 其实是把系统的可用内存变大了。这样,即使服务器的内存不足,也可以运行大内存的应用程序。
事实上,内存再大,对应用程序来说,也有不够用的时候。
一个很典型的场景就是,即使内存不足时,有些应用程序也并不想被 OOM 杀死,而是希望能缓一段时间,等待人工介入,或者等系统自动释放其他进程的内存,再分配给它。
除此之外,我们常见的笔记本电脑的休眠和快速开机的功能,也基于 Swap 。休眠时,把系统的内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以。这样就省去了很多应用程序的初始化过程,加快了开机速度。
话说回来,既然 Swap 是为了回收内存,那么 Linux 到底在什么时候需要回收内存呢?前面一直在说内存资源紧张,又该怎么来衡量内存是不是紧张呢?
一个最容易想到的场景就是,有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是 kswapd0。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是
页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。
这里,我画了一张图表示它们的关系。

kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
我们可以看到,一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下 :
pages_low = pages_min*5/4
pages_high = pages_min*3/2
NUMA 与 Swap
很多情况下,你明明发现了 Swap 升高,可是在分析系统的内存使用时,却很可能发现,系统剩余内存还多着呢。为什么剩余内存很多的情况下,也会发生 Swap 呢?
看到上面的标题,你应该已经想到了,这正是处理器的 NUMA (Non-Uniform Memory Access)架构导致的。
关于 NUMA,我在 CPU 模块中曾简单提到过。在 NUMA 架构下,多个处理器被划分到不同 Node 上,且每个 Node 都拥有自己的本地内存空间。
而同一个 Node 内部的内存空间,实际上又可以进一步分为不同的内存域(Zone),比如直接内存访问区(DMA)、普通内存区(NORMAL)、伪内存区(MOVABLE)等,如下图所示:
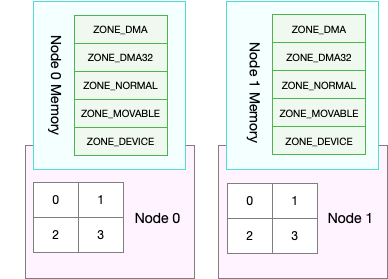
先不用特别关注这些内存域的具体含义,我们只要会查看阈值的配置,以及缓存、匿名页的实际使用情况就够了。
既然 NUMA 架构下的每个 Node 都有自己的本地内存空间,那么,在分析内存的使用时,我们也应该针对每个 Node 单独分析。
你可以通过 numactl 命令,来查看处理器在 Node 的分布情况,以及每个 Node 的内存使用情况。比如,下面就是一个 numactl 输出的示例:
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 7977 MB
node 0 free: 4416 MB
...
这个界面显示,我的系统中只有一个 Node,也就是 Node 0 ,而且编号为 0 和 1 的两个 CPU, 都位于 Node 0 上。另外,Node 0 的内存大小为 7977 MB,剩余内存为 4416 MB。
swappiness
到这里,我们就可以理解内存回收的机制了。这些回收的内存既包括了文件页,又包括了匿名页。
-
对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
-
而对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
不过,你可能还有一个问题。既然有两种不同的内存回收机制,那么在实际回收内存时,到底该先回收哪一种呢?
其实,Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
虽然 swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整 Swap 积极程度的权重,即使你把它设置成 0,当剩余内存 + 文件页小于页高阈值时,还是会发生 Swap。
Q&A
关于上面有同学表示 hadoop 集群建议关 swap 提升性能。事实上不仅 hadoop,包括 ES 在内绝大部分 Java 的应用都建议关 swap,这个和 JVM 的 gc 有关,它在 gc 的时候会遍历所有用到的堆的内存,如果这部分内存是被 swap 出去了,遍历的时候就会有磁盘IO
嗯嗯,大部分应用都不需要swap
为什么kubernetes要关闭swap呢?
一个是性能问题,开启swap会严重影响性能(包括内存和I/O);另一个是管理问题,开启swap后通过cgroups设置的内存上限就会失效。
swap应该是针对以前内存小的一种优化吧,不过现在内存没那么昂贵之后,所以就没那么大的必要开启了
numa感觉是对系统资源做的隔离分区,不过目前虚拟化和docker这么流行。而且node与node之间访问更耗时,针对大程序不一定启到了优化作用,针对小程序,也没有太大必要。所以numa也没必要开启。

