局部性原理:数据库性能跟不上,加个缓存就好了?
平时进行服务端软件开发的时候,我们通常会把数据存储在数据库里。而服务端系统遇到的第一个性能瓶颈,往往就发生在访问数据库的时候。这个时候,大部分工程师和架构师会拿出一种叫作“缓存”的武器,通过使用 Redis 或者 Memcache 这样的开源软件,在数据库前面提供一层缓存的数据,来缓解数据库面临的压力,提升服务端的程序性能。
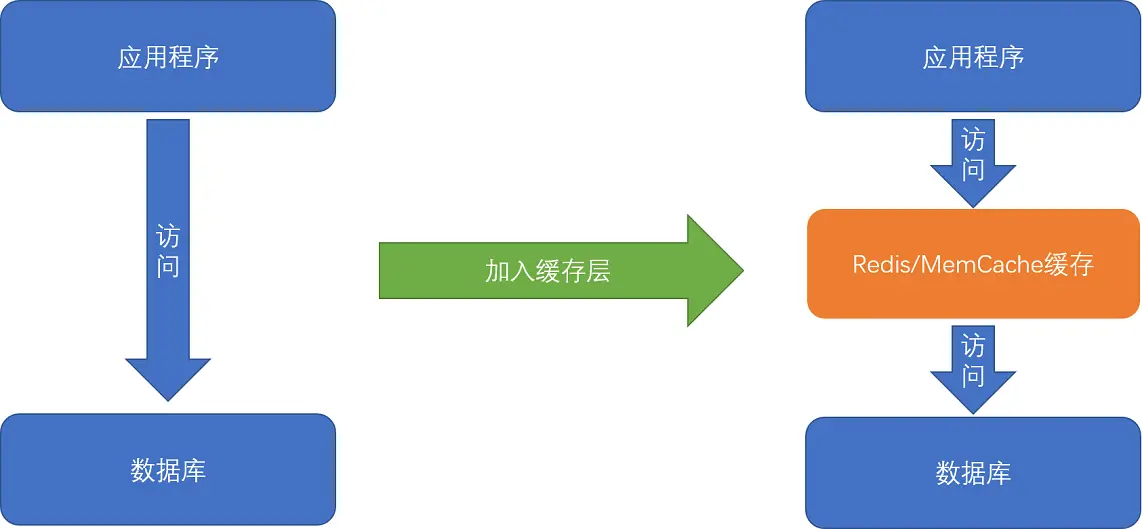
那么,不知道你有没有想过,这种添加缓存的策略一定是有效的吗?或者说,这种策略在什么情况下是有效的呢?如果从理论角度去分析,添加缓存一定是我们的最佳策略么?进一步地,如果我们对于访问性能的要求非常高,希望数据在 1 毫秒,乃至 100 微秒内完成处理,我们还能用这个添加缓存的策略么?
理解局部性原理
我们先来回顾一下,上一讲的这张不同存储器的性能和价目表。可以看到,不同的存储器设备之间,访问速度、价格和容量都有几十乃至上千倍的差异。
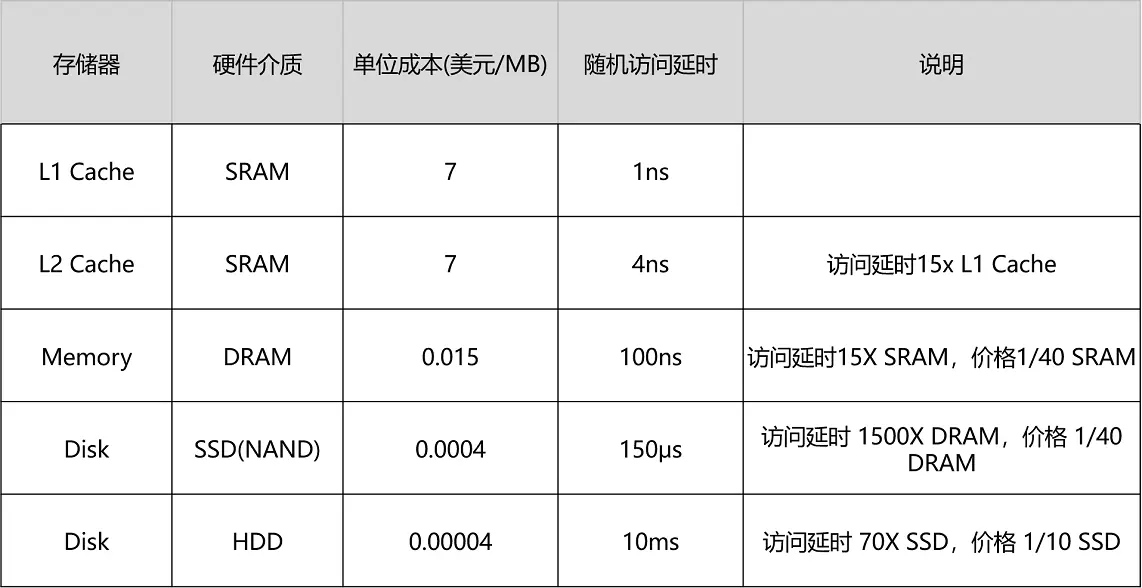
以上一讲的 Intel 8265U 的 CPU 为例,它的 L1 Cache 只有 256K,L2 Cache 有个 1MB,L3 Cache 有 12MB。一共 13MB 的存储空间,如果按照 7 美元 /1MB 的价格计算,就要 91 美元。
我们的内存有 8GB,容量是 CPU Cache 的 600 多倍,按照表上的价格差不多就是 120 美元。如果按照今天京东上的价格,恐怕不到 40 美元。128G 的 SSD 和 1T 的 HDD,现在的价格加起来也不会超过 100 美元。虽然容量是内存的 16 倍乃至 128 倍,但是它们的访问速度却不到内存的 1/1000。
性能和价格的巨大差异,给我们工程师带来了一个挑战:我们能不能既享受 CPU Cache 的速度,又享受内存、硬盘巨大的容量和低廉的价格呢?你可以停下来自己思考一下,或者点击文章右上方的“请朋友读”,邀请你的朋友一起来思考这个问题。然后,再一起听我的讲解。
好了,现在我公布答案。想要同时享受到这三点,前辈们已经探索出了答案,那就是,存储器中数据的局部性原理(Principle of Locality)。我们可以利用这个局部性原理,来制定管理和访问数据的策略。这个局部性原理包括时间局部性(temporal locality)和空间局部性(spatial locality)这两种策略。
我们先来看时间局部性。这个策略是说,如果一个数据被访问了,那么它在短时间内还会被再次访问。这么看这个策略有点奇怪是吧?我用一个简单的例子给你解释下,你一下就能明白了。
比如说,《哈利波特与魔法石》这本小说,我今天读了一会儿,没读完,明天还会继续读。同理,在一个电子商务型系统中,如果一个用户打开了 App,看到了首屏。我们推断他应该很快还会再次访问网站的其他内容或者页面,我们就将这个用户的个人信息,从存储在硬盘的数据库读取到内存的缓存中来。这利用的就是时间局部性。
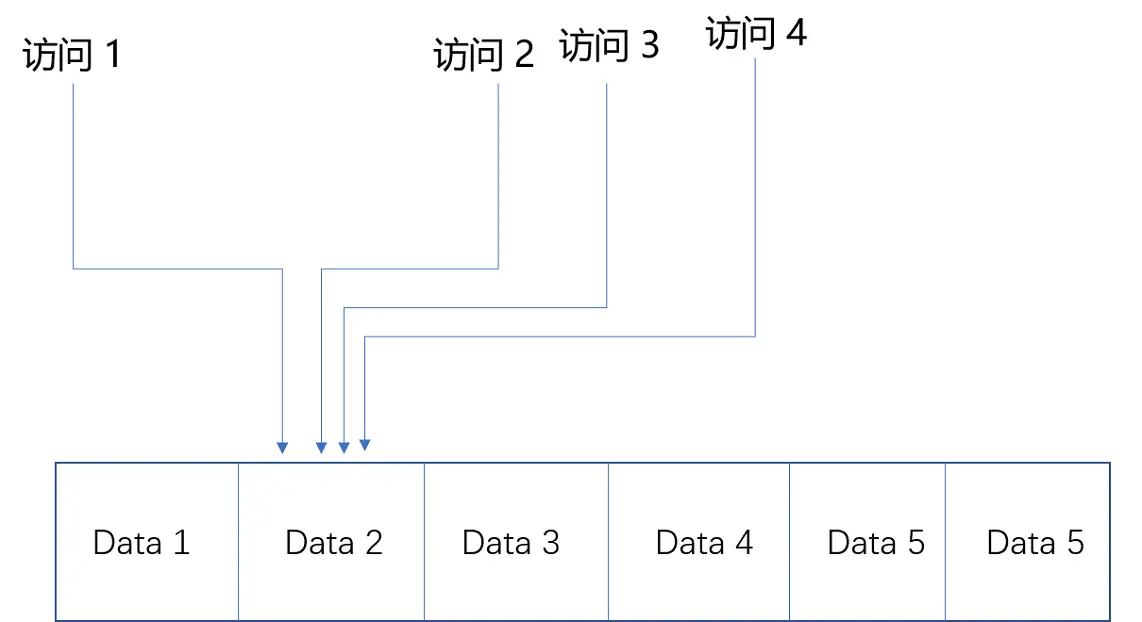
同一份数据在短时间内会反复多次被访问
我们再来看空间局部性。这个策略是说,如果一个数据被访问了,那么和它相邻的数据也很快会被访问。
们还拿刚才读《哈利波特与魔法石》的例子来说。我读完了这本书之后,感觉这书不错,所以就会借阅整套“哈利波特”。这就好比我们的程序,在访问了数组的首项之后,多半会循环访问它的下一项。因为,在存储数据的时候,数组内的多项数据会存储在相邻的位置。这就好比图书馆会把“哈利波特”系列放在一个书架上,摆放在一起,加载的时候,也会一并加载。我们去图书馆借书,往往会一次性把 7 本都借回来。
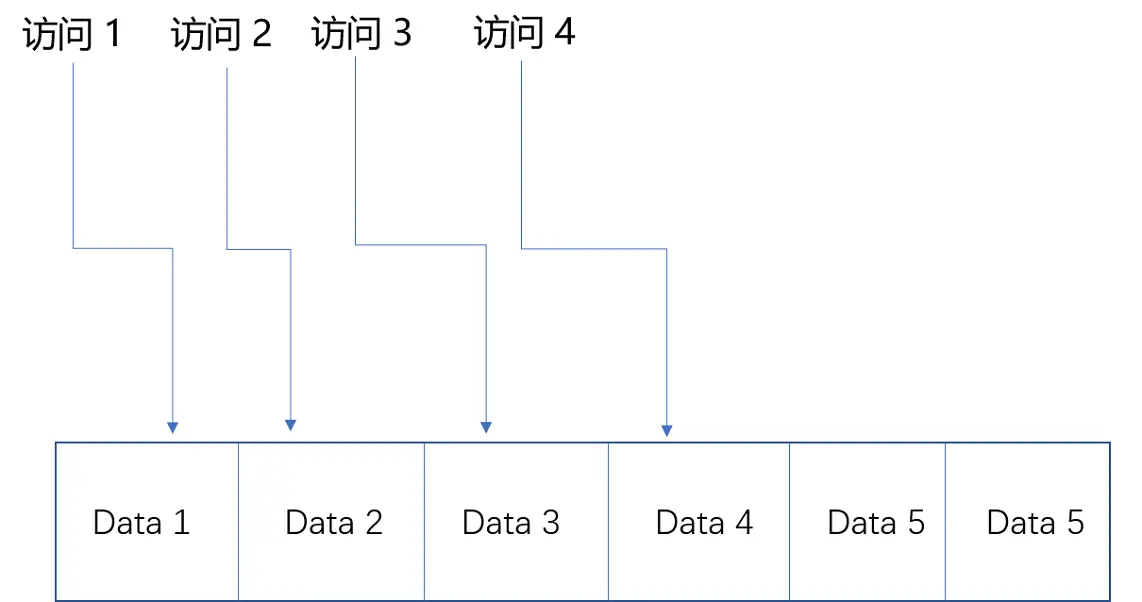
相邻的数据会被连续访问
有了时间局部性和空间局部性,我们不用再把所有数据都放在内存里,也不用都放在 HDD 硬盘上,而是把访问次数多的数据,放在贵但是快一点的存储器里,把访问次数少的数据,放在慢但是大一点的存储器里。这样组合使用内存、SSD 硬盘以及 HDD 硬盘,使得我们可以用最低的成本提供实际所需要的数据存储、管理和访问的需求。

