Kubernetes笔记
一、基础概念
1)k8s是什么
 kubernetes具有以下特性:
kubernetes具有以下特性:
● 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
● 存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
● 自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
● 自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
● 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
● 密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
2)架构-工作方式
Kubernetes Cluster = N Master Node + N Worker Node;N主节点+N工作节点; N>=1
3)架构-组件架构

(1)控制平面组件(Control Plane Components)
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。
①kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
②etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。
要了解 etcd 更深层次的信息,请参考 etcd 文档。
③kube-scheduler
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
④kube-controller-manager
在主节点上运行 控制器 的组件。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
● 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
● 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
● 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
● 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
⑤cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器允许您链接集群到云提供商的应用编程接口中, 并把和该云平台交互的组件与只和您的集群交互的组件分离开。
cloud-controller-manager 仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager 将若干逻辑上独立的 控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
● 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
● 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
● 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
(2)Node 组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
①kubelet
一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
②kube-proxy
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。

(3)架构演示

4)kubeadm创建集群
请参照以前Docker安装。先提前为所有机器安装Docker
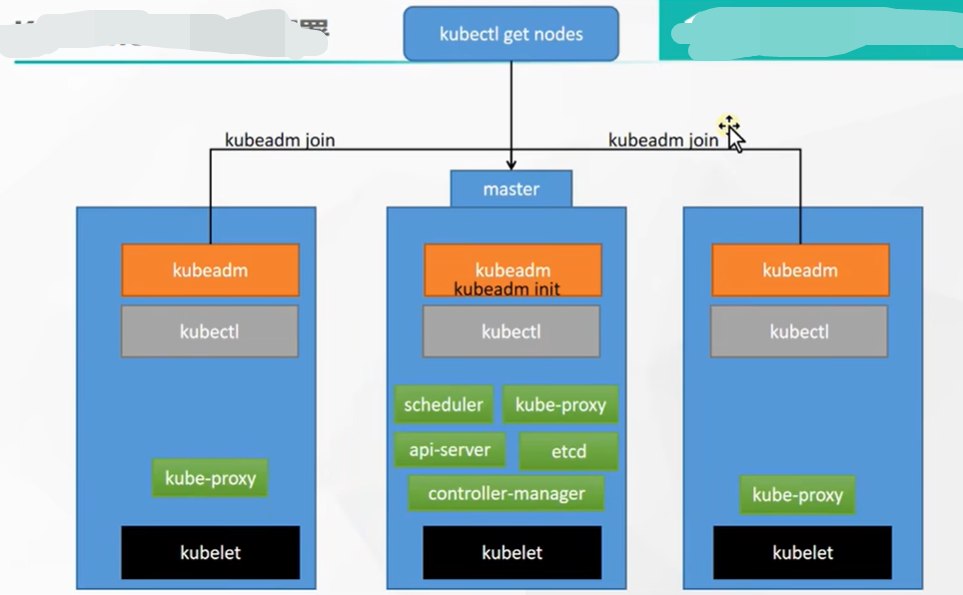
(1)安装kubelet、kubeadm、kubectl
● 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
● 每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
● 2 CPU 核或更多
● 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
○ 设置防火墙放行规则 ○ ip不要选择:192.168.0.0/16、172.16.0.0/16、172.17.0.0/16
● 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
○ 设置不同hostname
● 开启机器上的某些端口。请参见这里 了解更多详细信息。
○ 内网互信
● 禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区。
○ 永久关闭
①基础环境
所有机器执行以下操作
点击查看代码
#各个机器设置自己的域名
hostnamectl set-hostname xxxx
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
②安装kubelet、kubeadm、kubectl
点击查看代码
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes
sudo systemctl enable --now kubelet
kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环
systemctl status kubelet
(2)使用kubeadm引导集群
①下载各个机器需要的镜像
点击查看代码
sudo tee ./images.sh <<-'EOF'
#!/bin/bash
images=(
kube-apiserver:v1.20.9
kube-proxy:v1.20.9
kube-controller-manager:v1.20.9
kube-scheduler:v1.20.9
coredns:1.7.0
etcd:3.4.13-0
pause:3.2
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName
done
EOF
chmod +x ./images.sh && ./images.sh
②初始化主节点
#所有机器添加master域名映射,以下需要修改为自己的
echo "192.168.161.128 cluster-endpoint" >> /etc/hosts
点击查看代码
#主节点初始化
kubeadm init \
--apiserver-advertise-address=192.168.161.128 \
--control-plane-endpoint=cluster-endpoint \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.162.0/24
#所有网络范围不重叠
点击查看代码
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-endpoint:6443 --token nhllyd.o0fef74zw5vhjdjl \
--discovery-token-ca-cert-hash sha256:58fd09acbaa81fd5fbbcfeeb8da477e6e42cf1d669c1d61c89b4dfaef6a70d79 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-endpoint:6443 --token nhllyd.o0fef74zw5vhjdjl \
--discovery-token-ca-cert-hash sha256:58fd09acbaa81fd5fbbcfeeb8da477e6e42cf1d669c1d61c89b4dfaef6a70d79
#查看集群所有节点
kubectl get nodes
#根据配置文件,给集群创建资源
kubectl apply -f xxxx.yaml
#查看集群部署了哪些应用?
docker ps === kubectl get pods -A
# 运行中的应用在docker里面叫容器,在k8s里面叫Pod
kubectl get pods -A
③根据提示继续
master成功后提示如下:

-
设置.kube/config
复制上面命令
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config -
安装网络组件
curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O
kubectl apply -f calico.yaml
注意一:
安装calico失败,可能是阿里镜像加速地址不够用,解决方法多加几个可用的镜像加速地址重新安装拉取镜像即可。
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://docker.m.daocloud.io","https://p5lmkba8.mirror.aliyuncs.com","https://registry.docker-cn.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
注意二:
在 初始化主节点 时,我们修改了192.168.0.0/16的网段,为--pod-network-cidr=192.168.162.0/24
故要修改calico.yaml的默认CALICO_IPV4POOL_CIDR值为value: "192.168.162.0/24"
④加入node节点
kubeadm join cluster-endpoint:6443 --token nhllyd.o0fef74zw5vhjdjl \
--discovery-token-ca-cert-hash sha256:58fd09acbaa81fd5fbbcfeeb8da477e6e42cf1d669c1d61c89b4dfaef6a70d79
新令牌
# 令牌有效期24h
kubeadm token create --print-join-command
⑤验证集群
# 验证集群节点状态
kubectl get nodes
[root@master-localhost ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master-localhost.localdomain.master Ready control-plane,master 3d4h v1.20.9
slave-localhost Ready3d4h v1.20.9
⑥部署dashboard
- ❶部署
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
- ❷设置访问端口
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
type: ClusterIP 改为 type: NodePort
kubectl get svc -A |grep kubernetes-dashboard
[root@master-localhost ~]# kubectl get svc -A |grep kubernetes-dashboard
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.228.1158000/TCP 4h5m
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.145.166443:30824/TCP 4h5m
找到端口,在安全组放行
访问: https://集群任意IP:端口
如果使用Google浏览器提示不安全打不开页面可以直接在键盘输入thisisunsafe或者尝试切换浏览器如Edge、火狐
- ❸创建访问账号
点击查看代码
#创建访问账号,准备一个yaml文件; vi dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
kubectl apply -f dash.yaml
- ❹令牌访问
#获取访问令牌
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
点击查看代码
eyJhbGciOiJSUzI1NiIsImtpZCI6ImRFalBaRGVNWE85YVR0NWp4cklPTXNzNVBXOTU1YzY0dTJpMXRGZjQtbXcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXpuZjVjIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI5Y2UxOWY3Yi01M2YwLTQxODQtODNhMS0yMTI2NWUzMDcyMWQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.iz-ypcD-b8IjpMvaTPiL6ymLK1k4UhTglyK_7QpwE3xAy12hNdtyaHqeHWnt6oqXib40WBsU_2p2BobEdkzWTbunP_7tE4S4OkHRIkZKI2rs71AFlFEju2MwHZZV36duwM9D9WWSQWkcFenfLp5L-mDTcohdGBRc3nqenPWAkvGk9Elrt2r35xvr2KBuKLTzmSlFEFlfeyu4j_8iJ2nJ4BoaQb4oaJi3kh2l6RaW_Wpg5xBncWZ_ly6dsBEnUqVIGIQhVOdZ8Xk4Gr7cxkaoTaYkHtHg2874LWvaGvgwxJIANvw-zf-If3lKvyvK6CdQC8j9jdvkiIAXKdcwKPtn4w
- ❺界面
二、核心实战
1)资源创建方式
命令行
YAML
2)Namespace
名称空间用来隔离资源。
kubectl create ns hello
kubectl delete ns hello
apiVersion: v1
kind: Namespace
metadata:
name: hello
3)Pod
运行中的一组容器,Pod是kubernetes中应用的最小单位。
#根据nginx镜像运行一个mynginx Pod
kubectl run mynginx --image=nginx
#进入pod内部
kubectl exec -it mynginx -- /bin/bash

# 查看default名称空间的Pod
kubectl get pod -n default
# 删除
kubectl delete pod Pod名字
#强制删除Terminating状态的Pod
kubectl delete pod mytomcat-6f5f895f4f-pg4kk --grace-period=0 --force -n default
# 查看Pod的运行日志
kubectl logs Pod名字
# 描述
kubectl describe pod 你自己的Pod名字
# 查看Pod里运行某个容器的日志
kubectl logs my-pod -c container1
#
watch -n 1 kubectl get pod
kubectl get pod -A -w
# 每个Pod - k8s都会分配一个ip
kubectl get pod -owide
# 使用Pod的ip+pod里面运行容器的端口
curl 192.168.169.136
# 集群中的任意一个机器以及任意的应用都能通过Pod分配的ip来访问这个Pod
点击查看代码
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
# namespace: default
spec:
containers:
- image: nginx
name: mynginx
点击查看代码
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat
此时的应用还不能外部访问
4)工作负载-Deployment
控制Pod,使Pod拥有多副本,自愈,扩缩容等能力
# 清除所有Pod,比较下面两个命令有何不同效果?
kubectl run mynginx --image=nginx
kubectl create deployment mytomcat --image=tomcat:8.5.68
# 自愈能力
(1)多副本
kubectl create deployment my-dep --image=nginx --replicas=3
点击查看代码
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep
name: my-dep
spec:
replicas: 3
selector:
matchLabels:
app: my-dep
template:
metadata:
labels:
app: my-dep
spec:
containers:
- image: nginx
name: nginx
(2)扩缩容
kubectl scale --replicas=5 deployment/my-dep
# yaml方式修改
kubectl edit deployment my-dep
#修改 replicas
(3)自愈&故障转移
- 停机
- 删除Pod
- 容器崩溃
(4)滚动更新
kubectl set image deployment/my-dep nginx=nginx:1.16.1 --record
kubectl rollout status deployment/my-dep
# yaml方式修改
kubectl edit deployment/my-dep
(5)版本回退
#历史记录
kubectl rollout history deployment/my-dep
#查看某个历史详情
kubectl rollout history deployment/my-dep --revision=2
#回滚(回到上次)
kubectl rollout undo deployment/my-dep
#回滚(回到指定版本)
kubectl rollout undo deployment/my-dep --to-revision=2
5)工作负载-更多
除了Deployment,k8s还有
StatefulSet、DaemonSet、Job等 类型资源。我们都称为工作负载。有状态应用使用
StatefulSet部署,无状态应用使用Deployment部署
6)Service
将一组 Pods 公开为网络服务的抽象方法。

#暴露deployment
kubectl expose deployment my-dep --port=8000 --target-port=80
#使用标签检索Pod
kubectl get pod -l app=my-dep
# k8s都会分配一个ip:port
kubectl get service -owide
# 编辑svc
kubectl edit svc hello-server -n default
点击查看代码
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
selector:
app: my-dep
ports:
- port: 8000
protocol: TCP
targetPort: 80
没有取消expose的方法,但是可以通过删除service的方实现:
kubectl delete service <service-name> -n <namespace>
[root@master ~]# kubectl delete service my-dep
service "my-dep" deleted
[root@master ~]#
(1)ClusterIP
# 等同于没有--type的
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=ClusterIP
点击查看代码
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep
type: ClusterIP
[root@master ~]# kubectl get service -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1443/TCP 5h35m
mytomcat ClusterIP 10.96.88.1358080/TCP 2s app=my-dep
可以通过10.96.88.135:8080访问
(2)NodePort
NodePort范围在 30000-32767 之间
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=NodePort
点击查看代码
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep
type: NodePort
[root@master ~]# kubectl get service -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1443/TCP 5h37m
mytomcat NodePort 10.96.43.1858080:30662/TCP 4s app=my-dep
[root@master ~]#
可以通过机器的k8s任意节点ip:30662或者10.96.43.185:8080访问
7)Ingress

- 安装步骤如下:
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml
#修改镜像
vi deploy.yaml
#将image的值改为如下值:
registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/ingress-nginx-controller:v0.46.0
# 检查安装的结果,最后别忘记把svc暴露的端口要放行
kubectl get pod,svc -n ingress-nginx
ingress安装后会生成ingress服务(可以看到暴露的端口 80:31535/TCP,443:30793/TCP ):
kubectl get svc -n ingress-nginx
[root@master ingress]# kubectl get pod,svc -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-ms2jr 0/1 Completed 0 6h16m
pod/ingress-nginx-admission-patch-2pwh7 0/1 Completed 0 6h16m
pod/ingress-nginx-controller-65bf56f7fc-ndgmd 1/1 Running 1 6h16mNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller NodePort 10.96.68.10780:31535/TCP,443:30793/TCP 6h16m
service/ingress-nginx-controller-admission ClusterIP 10.96.155.66443/TCP 6h16m
[root@master ingress]#
测试环境(Deployment):
点击查看代码
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
spec:
replicas: 2
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server
ports:
- containerPort: 9000
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-server
name: nginx-server
spec:
replicas: 2
selector:
matchLabels:
app: nginx-server
template:
metadata:
labels:
app: nginx-server
spec:
containers:
- image: nginx
name: nginx
点击查看代码
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-server
name: nginx-server
spec:
selector:
app: nginx-server
ports:
- port: 8000
protocol: TCP
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
labels:
app: hello-server
name: hello-server
spec:
selector:
app: hello-server
ports:
- port: 8000
protocol: TCP
targetPort: 9000
测试环境架构( 域名后面是ingress服务暴露的端口 ):

修改ingress:
kubectl edit ing ingress-host-bar -n default
- 有以下三种使用:
(1)域名访问
点击查看代码
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.hoaprox.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "nginx.hoaprox.com"
http:
paths:
- pathType: Prefix
path: "/nginx" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-server ## java,比如使用路径重写,去掉前缀nginx
port:
number: 8000
(2)路径重写
点击查看代码
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.hoaprox.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "nginx.hoaprox.com"
http:
paths:
- pathType: Prefix
path: "/nginx(/|$)(.*)" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-server ## java,比如使用路径重写,去掉前缀nginx
port:
number: 8000
(3)流量限制
点击查看代码
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-limit-rate
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
ingressClassName: nginx
rules:
- host: "haha.hoaprox.com"
http:
paths:
- pathType: Exact
path: "/"
backend:
service:
name: nginx-demo
port:
number: 8000
8)存储抽象

(1)环境准备(安装nfs)

①所有节点
#所有机器安装
yum install -y nfs-utils
②主节点
#nfs主节点
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
mkdir -p /nfs/data
systemctl enable rpcbind --now
systemctl enable nfs-server --now
#配置生效
exportfs -r
③从节点
showmount -e 192.168.161.128
#执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /nfs/data
mkdir -p /nfs/data
mount -t nfs 192.168.161.128:/nfs/data /nfs/data
# 写入一个测试文件
echo "hello nfs server" > /nfs/data/test.txt
(2)原生方式数据挂载
在/nfs/data/nginx-pv下新建index.html文件。
点击查看代码
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-pv-demo
name: nginx-pv-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-pv-demo
template:
metadata:
labels:
app: nginx-pv-demo
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
nfs:
server: 172.31.0.4
path: /nfs/data/nginx-pv
(3)PV & PVC
在 Kubernetes 中,PV 是在集群中提供给用户使用的存储资源的抽象,就像一种云上的硬盘。而 PVC 则是用户对这些资源的请求或申请,就像租赁一块硬盘。
这种设计策略是一种很明智的区分:PV 是供应方的角色,是管理员的事情,管理集群内的实际存储资源。而 PVC 则是消费方的角色,是用户或开发者的事情,他们只需要关心如何消费这些存储资源。
PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置
PVC:持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格
PV 在 Kubernetes 中是集群级别的资源,具有以下特性:
PV 不受 Pod 生命周期限制:当删除与 PV 对象关联的 Pod 时,PV 仍然存在。
PV 在故障中仍然存在:当 Pod 崩溃时,PV 仍然在集群中存在。
PV 是集群范围的:PV 可以附加到在集群中运行的任何 Pod。
PV 支持三种访问模式:
- ReadWriteOnce(单节点读写)
- ReadOnlyMany(多节点只读)
- ReadWriteMany(多节点读写)
PV 和 PVC 的交互过程可以分为两部分:静态供应和动态供应。
①静态供应
对于 PVC,开发者在其应用的配置文件中创建一个 PVC,其中指定了所需的存储大小和访问模式。Kubernetes 会查找符合这些要求的 PV 并将其与 PVC 绑定。这被称为静态供应。静态供应需要管理员先创建 PV,然后用户通过 PVC 来申请使用 PV。这个过程就像管理员为用户准备了一系列的储物柜(PV),用户则通过储物柜钥匙(PVC)来申请使用这些储物柜。
- nfs下创建目录
#nfs主节点
mkdir -p /nfs/data/01
mkdir -p /nfs/data/02
- 创建PV池-本案例是nfs
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01-10m
spec:
capacity:
storage: 10M
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/01
server: 192.168.161.128
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02
server: 192.168.161.128
②动态供应
动态供应则更为方便,它不需要管理员事先创建 PV。当用户创建 PVC 时,Kubernetes 会自动为这个 PVC 创建一个满足其请求的 PV。这就好比你走到一个储物柜前,自动售货机会根据你的需求,为你现场制造一个储物柜。
## 配置动态供应的默认存储类
## 创建了一个存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "true" ## 删除pv的时候,pv的内容是否要备份
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
#image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2
image: yuufnn/nfs-external-provisioner:v4.0.0
# resources:
# limits:
# cpu: 10m
# requests:
# cpu: 10m
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.161.128 ## 指定自己nfs服务器地址
- name: NFS_PATH
value: /nfs/data ## nfs服务器共享的目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.161.128
path: /nfs/data
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
③使用
- PVC创建与绑定
创建PVC:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi
storageClassName: nfs
创建pod绑定PVC:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy-pvc
name: nginx-deploy-pvc
spec:
replicas: 2
selector:
matchLabels:
app: nginx-deploy-pvc
template:
metadata:
labels:
app: nginx-deploy-pvc
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim:
claimName: nginx-pvc
(4)ConfigMap
抽取应用配置,并且可以自动更新
- redis示例
①把之前的配置文件创建为配置集
# 创建配置,redis保存到k8s的etcd;
kubectl create cm redis-conf --from-file=redis.conf
apiVersion: v1
data: #data是所有真正的数据,key:默认是文件名 value:配置文件的内容
redis.conf: |
appendonly yes
kind: ConfigMap
metadata:
name: redis-conf
namespace: default
②创建Pod
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
command:
- redis-server
- "/redis-master/redis.conf" #指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts:
- mountPath: /data
name: data
- mountPath: /redis-master
name: config
volumes:
- name: data
emptyDir: {}
- name: config
configMap:
name: redis-conf
items:
- key: redis.conf
path: redis.conf
③检查默认配置
kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET appendonly
127.0.0.1:6379> CONFIG GET requirepass
④修改ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: example-redis-config
data:
redis-config: |
maxmemory 2mb
maxmemory-policy allkeys-lru
⑤检查配置是否更新
kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET maxmemory
127.0.0.1:6379> CONFIG GET maxmemory-policy
配置值未更改,因为需要重新启动 Pod 才能从关联的 ConfigMap 中获取更新的值。
原因:我们的Pod部署的中间件自己本身没有热更新能力*
(5)Secret
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
kubectl create secret docker-registry leifengyang-docker \
--docker-username=leifengyang \
--docker-password=Lfy123456 \
--docker-email=534096094@qq.com
##命令格式
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
点击查看代码
apiVersion: v1
kind: Pod
metadata:
name: private-nginx
spec:
containers:
- name: private-nginx
image: leifengyang/guignginx:v1.0
imagePullSecrets:
- name: leifengyang-docker
如果你真心觉得文章写得不错,而且对你有所帮助,那就不妨小小打赏一下吧,如果囊中羞涩,不妨帮忙“推荐"一下,您的“推荐”和”打赏“将是我最大的写作动力!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号