Golang笔记
本文主要为go的学习过程笔记。
一、基本介绍
1、开发环境安装-windows安装
打开Golang官网,选择对应版本,进行安装。
2、环境变量配置
1)步骤
(1)首先在环境变量中添加 GOROOT,值为 go 的安装目录:
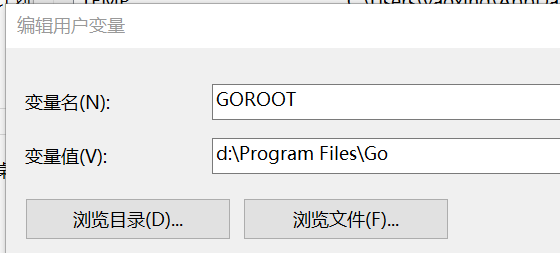
(2)然后在环境变量 PATH 中添加 go 安装目录下的 bin 文件夹。
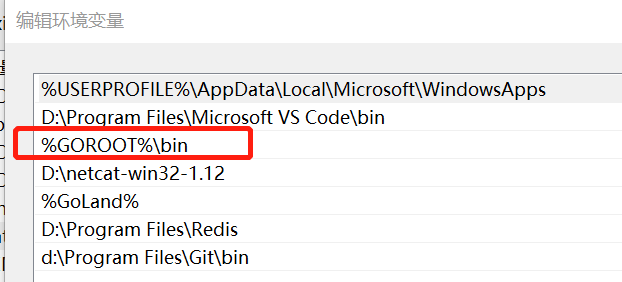
(3)接着添加一个环境变量 GOPATH,值为你自己希望的工作目录。
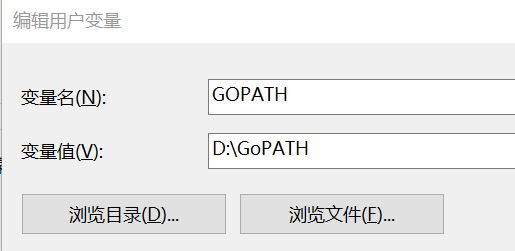
从Go 1.8版本开始,Go开发包在安装完成后会为GOPATH设置一个默认目录,并且在Go1.14及之后的版本中启用了Go Module模式之后,不一定非要将代码写到GOPATH目录下,所以也就不需要我们再自己配置GOPATH了,使用默认的即可。
(4)GOBIN
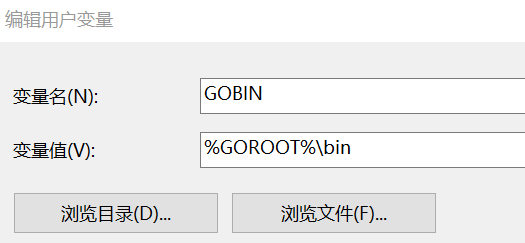
(5)最后重启一下 命令行工具,输入 go version命令即可查看版本信息
(6)GO ENV
命令行执行:go env查看go的环境变量。
(7)GOPROXY
默认GoPROXY配置是:GOPROXY=https://proxy.golang.org,direct,由于国内访问不到https://proxy.golang.org,所以我们需要换一个PROXY,这里推荐使用https://goproxy.io或https://goproxy.cn。
可以执行下面的命令修改GOPROXY:
go env -w GOPROXY=https://goproxy.cn,direct
2)GOROOT
$GOROOT,便是 Go 的安装路径,存放 Go 的内置程序库。通常你安装完后,你电脑的环境变量就会设好 GOROOT 路径。当你开发 Go 程序的时候,当你 import 内置程序库的时候,并不需要额外安装,而当程序运行后, 默认也会先去 GOROOT 路径下寻找相对应的库来运行。
3)GOPATH与Go工作区
GOPATH 是我们定义的自己的工作空间。
一个 GOPATH 工作区,一般这样:
./
├── bin
├── pkg
└── src
├── hello_github
└── hello_router.go
(1)bin:保存编译后生成的可执行文件。我们的操作系统使用$PATH环境变量来查找无需完整路径即可执行的二进制应用程序,建议将此目录:$GOPATH/bin添加到我们的全局 $PATH 变量中。
(2)pkg:它保存已安装的包对象(比如:.a)。每个目标操作系统和体系结构对都有自己的 pkg 子目录。 Go 编译包时生成的中间文件,用来缓存提高编译效率。
(3)src:包含源代码(比如:.go .c .h .s等)。 该路径决定 import 包时的导入路径或可执行文件名称。
import包的搜索顺序:
GOROOT/src:该目录保存了Go标准库代码。
GOPATH/src:该目录保存了应用自身的代码和第三方依赖的代码。
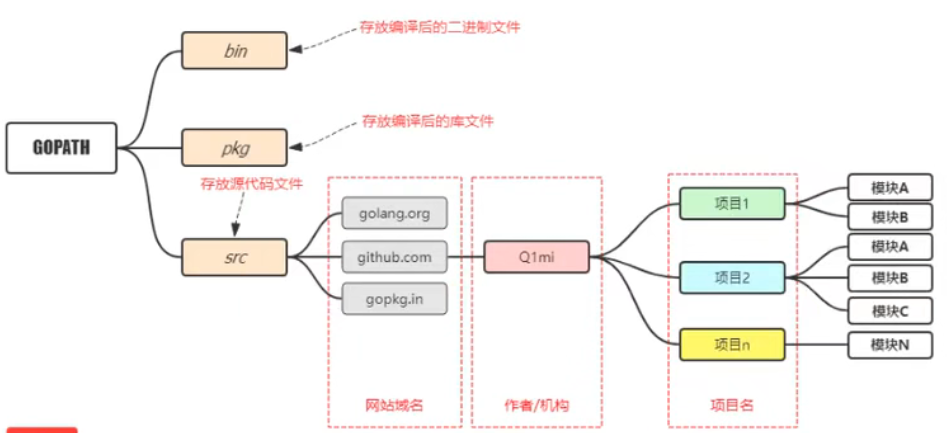
4)GOPATH项目结构
(1)一般开发者
(2)企业开发者
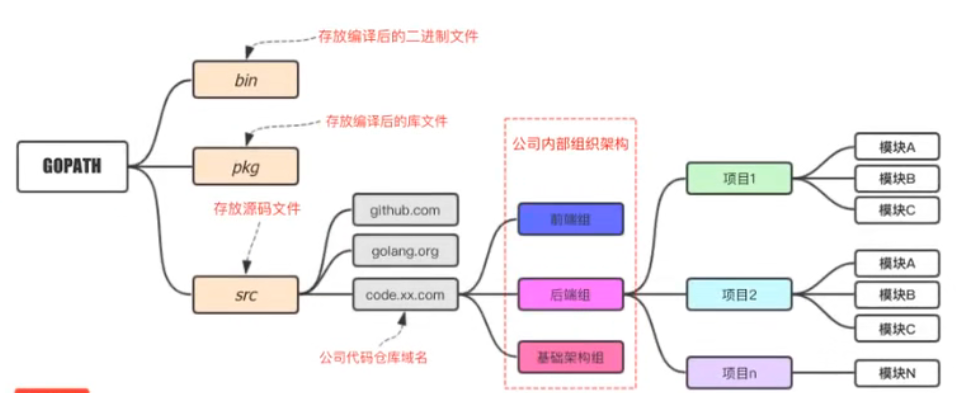
5)go.mod
Go.mod是Golang1.11版本新引入的官方包管理工具用于解决之前没有地方记录依赖包具体版本的问题,方便依赖包的管理。
Go.mod其实就是一个Modules,关于Modules的官方定义为:Modules是相关Go包的集合,是源代码交换和版本控制的单元。go命令直接支持使用Modules,包括记录和解析对其他模块的依赖性。Modules替换旧的基于GOPATH的方法,来指定使用哪些源文件。
Modules和传统的GOPATH不同,不需要包含例如src,bin这样的子目录,一个源代码目录甚至是空目录都可以作为Modules,只要其中包含有go.mod文件。
生成命令:
go mod init 模块名称
3、Go程序开发注意事项
1)Go源文件以“go”为扩展名
2)Go应用程序的执行入口是main()方法
3)Go语言严格区分大小写
4)Go方法由一条条语句构成,每个语句后不需要分号(Go语言会在每行后自动加分号)
5)Go编译器是一行行进行编译的,因此我们一行就写一条语句,不能把多余语句写在同一行,否则会报错。
6)Go语言定义的变量或者import的包如果没有使用到,代码不能编译通过。
7)大括号都是成对出现的,缺一不可。
4、常用的转义字符(escape char)
5、Go变量及常量
1)变量
变量(Variable)的功能是存储数据。不同的变量保存的数据类型可能会不一样。经过半个多世纪的发展,编程语言已经基本形成了一套固定的类型,常见变量的数据类型有:整型、浮点型、布尔型等。Go语言中的每一个变量都有自己的类型,并且变量必须经过声明才能开始使用。
(1)使用基本步骤
声明变量(定义变量)、赋值、使用
(2)Golang变量声明和赋值的三种方式
- 指定变量类型,声明后若不赋值,使用默认值(
标准声明)
//声明同时赋值
var 变量名字 类型 = 表达式
//声明时不赋值
var 变量名字 类型
- 根据值自行判定变量类型(
类型推导)
var 变量名字 = 表达式
- 省略var,注意
:=左侧的变量不应该是一级声明过的,否则会导致编译错误(短变量声明)
变量名字 := 表达式
(3)多变量声明
//可以声明时赋值,也可以不赋值
var 变量名字1,变量名字2 类型
////声明时需赋值
var 变量名字1,变量名字2 =值1,值2
//类型推导,需要赋值
变量名字1,变量名字2 :=值1,值2
(4)匿名变量
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示,例如:
package main
import "fmt"
func foo() (int, string) {
return 10, "Q1mi"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。
2)常量
相对于变量,常量是恒定不变的值,多用于定义程序运行期间不会改变的那些值。
(1)声明及赋值
常量的声明和变量声明非常类似,只是把var换成了const,常量在定义的时候必须赋值。
const pi = 3.1415 const e = 2.7182
(2)iota
iota是go语言的常量计数器,只能在常量的表达式中使用。iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
const ( a, b = iota + 1, iota + 2 //1,2 c, d //2,3 e, f //3,4 g = iota //3 )
6、数据类型-基本数据类型、派生数据类型
1)基本数据类型:
变量存的就是值,也叫值类型。
(1)数值型
整数类型、浮点类型
(2)字符型
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,使用byte来保存单个字符字符:
c='a' //单引号
Go 语言的字符有以下两种:
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。rune类型,代表一个UTF-8字符。rune类型实际是一个int32
(3)布尔型(bool)
- 布尔类型变量的默认值为
false。 - Go 语言中不允许将整型强制转换为布尔型.
- 布尔型无法参与数值运算,也无法与其他类型进行转换。
(4)字符串(string):官方将string归属到基本数据类型
- 使用
双引号括起来
s1 := "hello"
- 字符串转义字符
- 多行字符串:Go语言中要定义一个多行字符串时,就必须使用
反引号字符:
s := `第一行 第二行 第三行 `
- 修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
package main
import "fmt"
func changeString() {
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "白萝卜"
runeS2 := []rune(s2)
runeS2[0] = '红'
fmt.Println(string(runeS2))
}
func main(){
changeString()
}
2)派生数据类型
(1)指针(Pointer)-引用类型
指针类型:变量存的是一个地址,这个地址指向的空间存的才是值。(在对普通变量使用&操作符取地址后会获得这个变量的指针(地址),然后可以对指针使用*操作,也就是指针取值)获取指针类型所指向的值,使用:*。
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用&字符放在变量前面对变量进行“取地址”操作。 Go语言中的值类型(int、float、bool、string、array、struct)都有对应的指针类型,如:*int、*int64、*string等(定义一个指针类型要先初始化(使用make或者new)后才能使用。)。
取变量指针的语法如下:
ptr := &v // v的类型为T
其中:
- v:代表被取地址的变量,类型为
T - ptr:用于接收地址的变量,ptr的类型就为
*T,称做T的指针类型。*代表指针。
举个例子:
package main
import "fmt"
func main() {
i := 10
var p *int = &i
fmt.Println(p, *p)
}总结: 取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
(2)数组-值类型
(3)结构体(struct)-值类型
(4)管道(Channel)-引用类型
(5)函数
(6)切片(slice)-引用类型
(7)接口(interface)-引用类型
(8)字典(map)-引用类型
3)类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。强制类型转换的基本语法如下:
T (表达式)
其中,T表示要转换的类型。表达式包括变量、复杂算子和函数返回值等.
4)值类型与引用类型
(1)值类型:变量直接存储值,内存通常在栈中分配。都有对应的指针类型,形式未*数据类型,比如int的对应的指针就是*int,依次类推。
(2)引用类型:变量存储的是一个地址,这个地址对应的空间才是真正存储数据(值),内存通常在堆上分配,当没有任何变量引用这个地址时,该地址对应的数据空间就成为一个垃圾,由GC来回收。
7、函数
1)函数声明
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
func name(parameter-list) (result-list) {
body
}
形式参数列表描述了函数的参数名以及参数类型。这些参数作为局部变量,其值由参数调用者提供。返回值列表描述了函数返回值的变量名以及类型。如果函数返回一个无名变量或者没有返回值,返回值列表的括号是可以省略的。如果一个函数声明不包括返回值列表,那么函数体执行完毕后,不会返回任何值。
函数的类型被称为函数的签名。如果两个函数形式参数列表和返回值列表中的变量类型一一对应,那么这两个函数被认为有相同的类型或签名。形参和返回值的变量名不影响函数签名,也不影响它们是否可以以省略参数类型的形式表示。
每一次函数调用都必须按照声明顺序为所有参数提供实参(参数值)。在函数调用时,Go语言没有默认参数值,也没有任何方法可以通过参数名指定形参,因此形参和返回值的变量名对于函数调用者而言没有意义。
在函数体中,函数的形参作为局部变量,被初始化为调用者提供的值。函数的形参和有名返回值作为函数最外层的局部变量,被存储在相同的词法块中。实参通过值的方式传递,因此函数的形参是实参的拷贝。对形参进行修改不会影响实参。但是,如果实参包括引用类型,如指针,slice(切片)、map、function、channel等类型,实参可能会由于函数的间接引用被修改。
你可能会偶尔遇到没有函数体的函数声明,这表示该函数不是以Go实现的。这样的声明定义了函数签名。
2)init函数
略
3)Deferred函数
见异常处理章节
4)匿名函数
拥有函数名的函数只能在包级语法块中被声明,通过函数字面量(function literal),我们可绕过这一限制,在任何表达式中表示一个函数值。函数字面量的语法和函数声明相似,区别在于func关键字后没有函数名。函数值字面量是一种表达式,它的值被称为匿名函数(anonymous function)。
(1)定义
func (参数列表) (返回值列表) {
函数体
}
(2)在定义时调用匿名函数
func main() {
// 将匿名函数保存到变量
add := func(x, y int) {
fmt.Println(x + y)
}
add(10, 20) // 通过变量调用匿名函数
//自执行函数:匿名函数定义完加()直接执行
func(x, y int) {
fmt.Println(x + y)
}(10, 20)
}
匿名函数多用于实现回调函数和闭包。
5)函数值
在Go中,函数被看作第一类值(first-class values):函数像其他值一样,拥有类型,可以被赋值给其他变量,传递给函数,从函数返回。对函数值(function value)的调用类似函数调用。
6)闭包
函数值不仅仅是一串代码,还记录了状态。在squares中定义的匿名内部函数可以访问和更新squares中的局部变量,这意味着匿名函数和squares中,存在变量引用。这就是函数值属于引用类型和函数值不可比较的原因。Go使用闭包(closures)技术实现函数值,Go程序员也把函数值叫做闭包。
闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境。
func adder2(x int) func(int) int {
return func(y int) int {
x += y
return x
}
}
func main() {
var f = adder2(10)
fmt.Println(f(10)) //20
fmt.Println(f(20)) //40
fmt.Println(f(30)) //70
f1 := adder2(20)
fmt.Println(f1(40)) //60
fmt.Println(f1(50)) //110
}
8、包
包的本质就是创建不同的文件夹来存放程序文件。每个包一般都定义了一个不同的名字空间用于它内部的每个标识符的访问。每个名字空间关联到一个特定的包,让我们给类型、函数等选择简短明了的名字,这样可以在使用它们的时候减少和其它部分名字的冲突。每个包还通过控制包内名字的可见性和是否导出来实现封装特性。通过限制包成员的可见性并隐藏包API的具体实现,将允许包的维护者在不影响外部包用户的前提下调整包的内部实现。通过限制包内变量的可见性,还可以强制用户通过某些特定函数来访问和更新内部变量,这样可以保证内部变量的一致性和并发时的互斥约束。当我们修改了一个源文件,我们必须重新编译该源文件对应的包和所有依赖该包的其他包。
1)包的三大作用
(1)区分相同名字的函数、变量等标识符
(2)当程序文件很多时,可以很好的管理项目
(3)控制函数、变量等访问范围,即作用域
2)包的相关说明
(1)打包基本语法/声明基本语法
package 包名
在每个Go语言源文件的开头都必须有包声明语句。包声明语句的主要目的是确定当前包被其它包导入时默认的标识符(也称为包名)。
(2)引入包的基本语法
import "包的路径"
每个包是由一个全局唯一的字符串所标识的导入路径定位。出现在import语句中的导入路径也是字符串。(在import包时,路径从$GOPATH的src下开始,不用带src。)
_来重命名导入的包。像往常一样,下划线_为空白标识符,并不能被访问。import _ "image/png" // register PNG decoder
匿名导入。它通常是用来实现一个编译时机制,然后通过在main主程序入口选择性地导入附加的包。9、数组
数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的,不能动态变化。
1)基本介绍(定义和初始化)
定义:var 数组名 [数组大小]数据类型
以下是三种数组初始化方式:
- 默认情况下,数组的每个元素都被初始化为元素类型对应的零值,对于数字类型来说就是0。我们也可以使用数组字面值语法用一组值来初始化数组:
var q [3]int = [3]int{1, 2, 3}
var r = [3]int{1, 2}
p := [3]int{1, 2}
fmt.Println(r[2]) // "0"
- 在数组字面值中,如果在数组的长度位置出现的是“...”省略号,则表示数组的长度是根据初始化值的个数来计算。因此,上面q数组的定义可以简化为:
b := [...]int{1, 2, 3}
var c = [...]int{1, 2, 3}
fmt.Println(b[2])
fmt.Println(c[2])
- 也可以指定元素值对应的下标:
var names=[3]string{1:"tom",0:"jack",2:"marry"}
数组的长度是数组类型的一个组成部分,因此[3]int和[4]int是两种不同的数组类型。数组的长度必须是常量表达式,因为数组的长度需要在编译阶段确定。
2)数组遍历
(1)常规遍历
package main
import "fmt"
func main() {
var score [5]float64 = [5]float64{1.0, 2.0, 3.0, 4.0, 5.0}
for i := 0; i < len(score); i++ {
fmt.Println(score[i])
}
}
(2)for-range结构遍历
这个是go语言一种独有的结构,可以用来遍历访问数组的元素,
基本语法:for index,value:=range array01{}
第一个返回值index是数组的下标,第二个value是在该下标位置的值,它们都是仅在for循环内部可见的局部变量,遍历数组元素的时候如果不想使用下标index,可以直接把下标index标记为下划线>_,index和value的名称是不固定的,也可以自行指定。
package main
import "fmt"
func main() {
var score [5]float64 = [5]float64{1.0, 2.0, 3.0, 4.0, 5.0}
for index, value := range score {
fmt.Println(index, value)
}
}
10、切片
1)基本介绍
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已。
数组和slice之间有着紧密的联系。一个slice是一个轻量级的数据结构,提供了访问数组子序列(或者全部)元素的功能,而且slice的底层确实引用一个数组对象。一个slice由三个部分构成:指针、长度和容量。指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
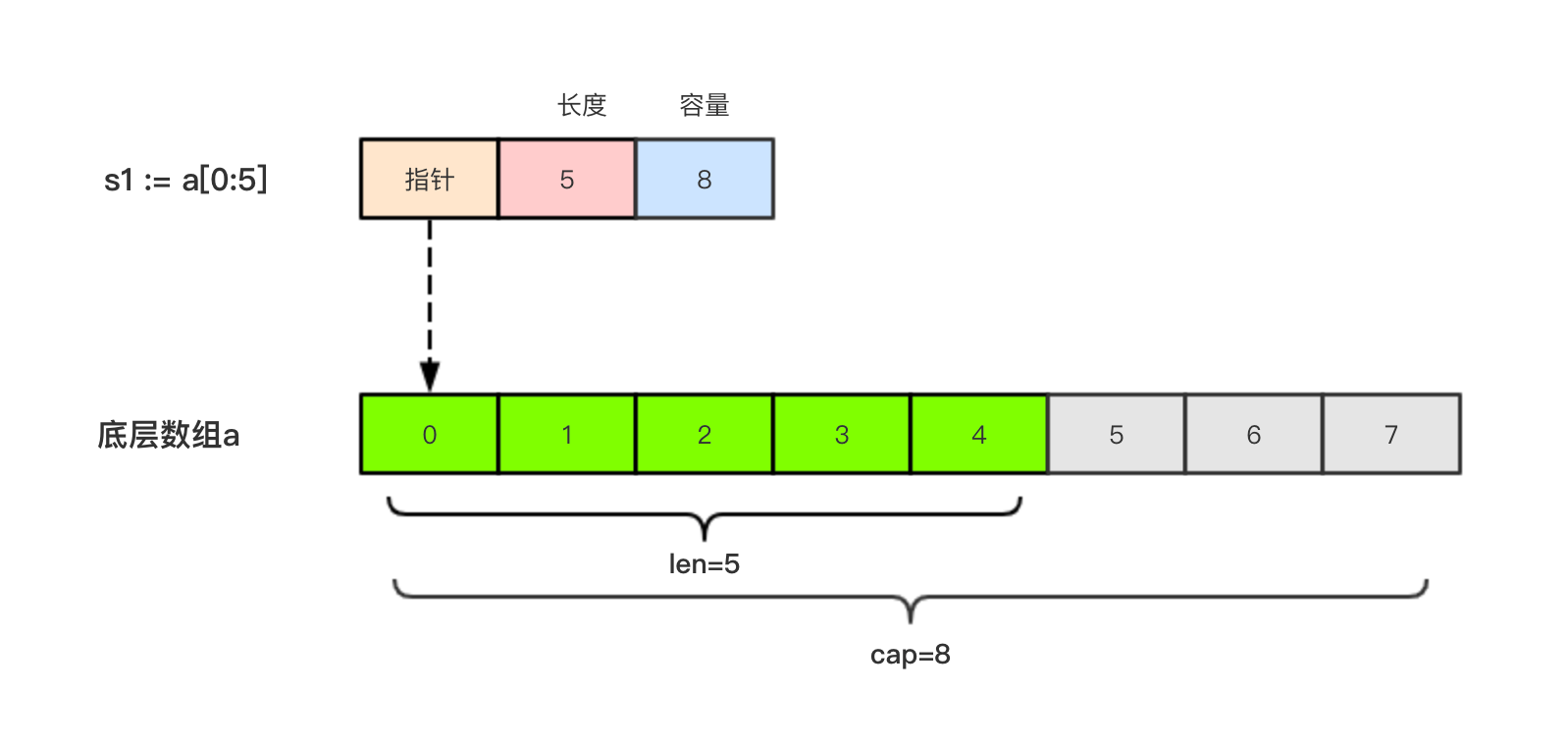 |
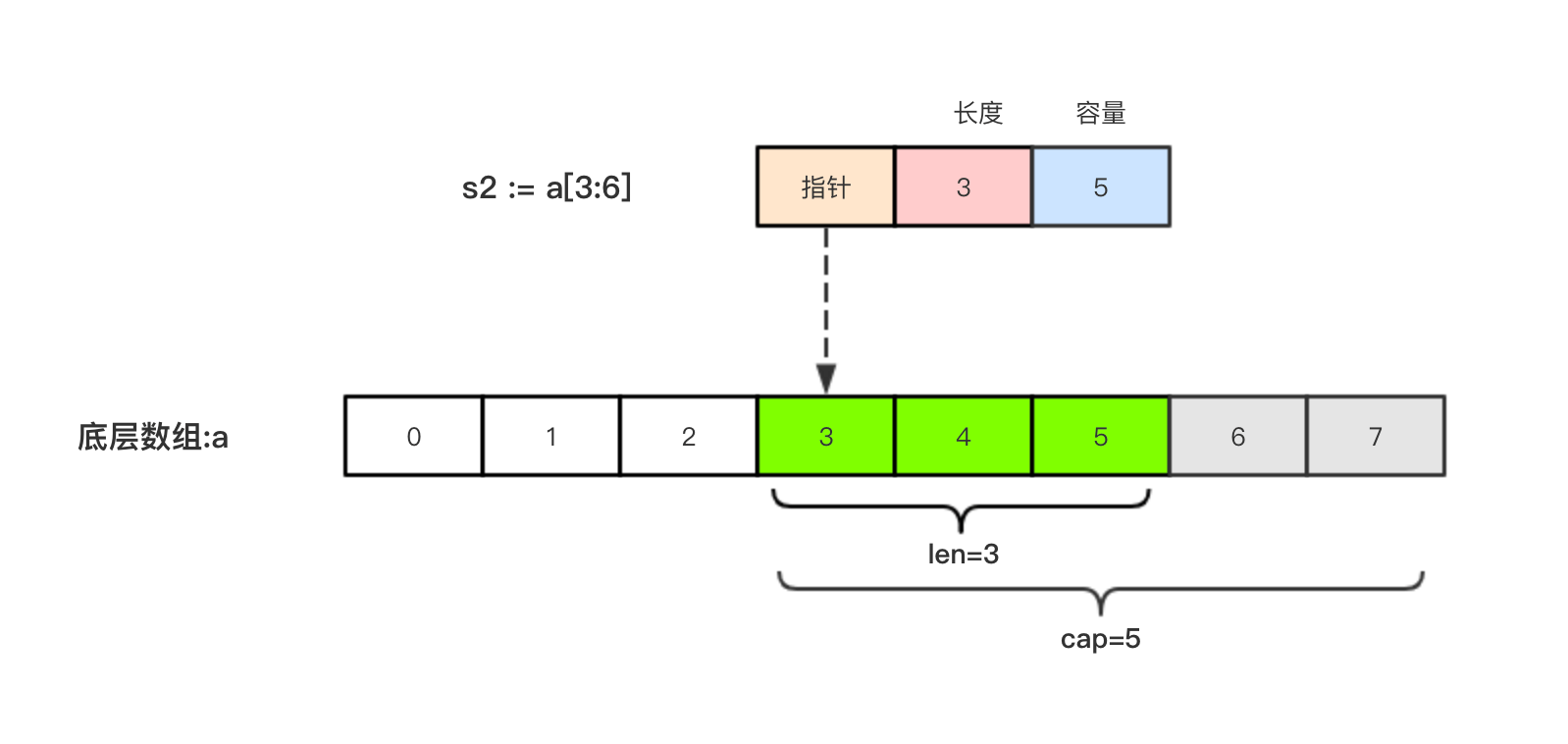 |
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
2)切片定义的基本语法
定义:var 变量名 []类型
例如:
package main
func main() {
var intArr [5]int = [...]int{1, 2, 3, 4, 5}
myslice:=intArr[1:4]
var myslice2 []int = intArr[0:3]
}
3)切片的创建(初始化)
(1)方式一:定义一个切片,然后让切片去引用一个已经创建好的数组。
直接引用数组,这个数组是事先存在的,程序员是可见的。
package main
import "fmt"
func main() {
var t1 [5]int = [5]int{1, 2, 3, 4, 5} //数组
var s3 []int = t1[:] //切片
fmt.Println(s3)
}
(2)方式二:通过make来创建切片。
基本语法:var 切片名 []type=make([]type,len,[capacity])
参数说明:type:切片的类型,len:长度,capacity:容量(可选的)。
package main
import "fmt"
func main() {
var myslice []int = make([]int, 4)
myslice[0] = 100
fmt.Println(myslice)
}
通过make来创建切片,make也会创建一个数组,是由切片在底层进行维护,程序员是看不见的。
(3)方式三:定义一个切片,直接就指定具体数组,使用原理类似make的方式
package main
import "fmt"
func main() {
var myslice []int = []int{1, 2, 3, 4, 5}
fmt.Println(myslice)
}
注意:使用数组创建切片时,如果改变了切片某个位置的值,数组的对应元素的值也会改变:
package main
import "fmt"
func main() {
x1 := [...]int{1, 3, 5}
s1 := x1[:]
s1 = append(s1[:1], s1[2:]...)
fmt.Println(s1) //[1 5]
fmt.Println(x1) //[1 5 5]
s1[1] = 55
fmt.Println(x1) //[1 55 5]
}
4)使用append()方法为切片添加元素
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
func main(){
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
var t []int
t = append(s, 1, 2, 3) //没有初始化,直接添加
}
注意:通过var声明的零值切片可以在append()函数直接使用,无需初始化。
5)切片遍历
(1)常规遍历
同数组
for i := 0; i < len(myslice); i++ {
fmt.Println(myslice[i])
}
(2)for-range结构遍历
同数组
for index, value := range myslice2 {
fmt.Println(index, value)
}
11、map
1)基本语法(声明)
var map变量名 map[keytype]valuetype
key的类型通常为:int、string。
声明是不会分配内存的,初始化需要make,分配内存后才能赋值和使用(map在使用前一定要make)。
var a map[string]string a=make(map[string]string,10) a["u01"]="jack"
2)map的三种使用方式
在Go语言中,一个map就是一个哈希表的引用,map类型可以写为map[K]V,其中K和V分别对应key和value。map中所有的key都有相同的类型,所有的value也有着相同的类型,但是key和value之间可以是不同的数据类型。其中K对应的key必须是支持==比较运算符的数据类型,所以map可以通过测试key是否相等来判断是否已经存在。虽然浮点数类型也是支持相等运算符比较的,但是将浮点数用做key类型则是一个坏的想法,最坏的情况是可能出现的NaN和任何浮点数都不相等。对于V对应的value数据类型则没有任何的限制。
(1)先声明,再make
//声明,这时map=nil var ages map[string]string //make(map[string],string,10)分配一个map ages=make(map[string]string,10)
(2)声明时直接make,内置的make函数可以创建一个map:
ages := make(map[string]int) // mapping from strings to ints
或者
var ages map[string]int=make(map[string]int)
(3)声明时直接赋值,我们也可以用map字面值的语法创建map,同时还可以指定一些最初的key/value:
var ages map[string]int=map[string]int{
"alice":31
}
或
ages := map[string]int{
"alice": 31,
"charlie": 34,
}
这相当于:
ages := make(map[string]int)
ages["alice"] = 31
ages["charlie"] = 34
因此,另一种创建空的map的表达式是map[string]int{}。
3)map的crud操作
使用内置的delete函数可以删除元素:
delete(ages, "alice") // remove element ages["alice"]
4)map遍历
todo
5)map排序
todo
12、结构体
结构体是一种聚合的数据类型,是由零个或多个任意类型的值聚合成的实体。每个值称为结构体的成员。用结构体的经典案例是处理公司的员工信息,每个员工信息包含一个唯一的员工编号、员工的名字、家庭住址、出生日期、工作岗位、薪资、上级领导等等。所有的这些信息都需要绑定到一个实体中,可以作为一个整体单元被复制,作为函数的参数或返回值,或者是被存储到数组中,等等。
下面两个语句声明了一个叫Employee的命名的结构体类型,并且(直接声明)声明了一个Employee类型的变量dilbert:
type Employee struct {
ID int
Name string
Address string
DoB time.Time
Position string
Salary int
ManagerID int
}
var dilbert Employee
赋值:
type Point struct{ X, Y int }
p := Point{1, 2}
var q Point = Point{12, 12}的
说明:
通过 reflect.Type 获取结构体成员信息 reflect.StructField 结构中的 Tag 被称为结构体标签(Struct Tag)。结构体标签是对结构体字段的额外信息标签。
1)成员变量
如果一个结构体的成员变量名称是首字母大写的,那么这个变量是可导出的。(即在其它包中可以访问),一个结构体可以同时包含可导出和不可导出的成员变量。
type Person struct {
Name string //不可导出
age int // 可导出
}
命名结构体类型s不可以定义一个拥有相同结构体类型s的成员变量,也就是一个聚合类型不可以包含它自己。但是s中可以定义一个s的指针类型,即*s。
type Person struct {
Name string
p1 Person //错误
p2 *Person //正确
}
结构体的成员变量如果是引用类型,如指针、切片、map,需要make再赋值。
2)创建结构体变量和访问结构体字段的四种方法
(1)直接声明
var dilbert Employee(2){}
type Point struct{ X, Y int }
p := Point{1, 2}
(3)new-返回的是结构体指针
var person *Person=new(Person)
(4)&-返回的是结构体指针
var person *Person=&Person{}
结构体指针访问字段的标准方式应该是:(*结构体指针).字段名,go做了一个简化,也支持结构体指针.字段名
3)tag
结构体的每个字段上,可以写一个tag,该tag可以通过反射机制获取,常见的场景就是序列化和反序列化。
4)匿名结构体实现继承
当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体,在该结构体中定义这些相同的属性和方法。其他的结构体不需要重新定义这些属性和方法,只需要嵌套一个匿名结构体即可。
也就是说:在golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性。
type Goods struct{
Name string
Price int
}
type Book struct{
Goods //这里就算嵌套匿名结构体Goods
Writer string
}
13、方法
Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。接收者的概念就类似于其他语言中的this或者 self。
Golang中的方法是作用在指定的数据类型上的(即:和指定的数据了下绑定),因此自定义类型,都可以有方法,而不仅仅是struct。
在函数声明时,在其名字之前放上一个变量,即是一个方法。这个附加的参数会将该函数附加到这种类型上,即相当于为这种类型定义了一个独占的方法。
package main
import (
"fmt"
"math"
)
type Point struct{ x, y float64 }
//func
func Distance(p, q Point) float64 {
return math.Hypot(q.x-p.x, q.y-p.y)
}
//method
func (p Point) Distance(q Point) float64 {
return math.Hypot((q.x - p.x), q.y-p.y)
}
func main() {
var p Point = Point{12, 12}
var q Point = Point{8, 8}
x := Distance(p, q)
//function call
fmt.Println(x)
//method call
y := p.Distance(q)
fmt.Println(y)
}
上面的代码里那个附加的参数p,叫做方法的接收器(receiver),早期的面向对象语言留下的遗产将调用一个方法称为“向一个对象发送消息”。在Go语言中,我们并不会像其它语言那样用this或者self作为接收器;我们可以任意的选择接收器的名字。由于接收器的名字经常会被使用到,所以保持其在方法间传递时的一致性和简短性是不错的主意。这里的建议是可以使用其类型的第一个字母,比如这里使用了Point的首字母p。
在方法调用过程中,接收器参数一般会在方法名之前出现。这和方法声明是一样的,都是接收器参数在方法名字之前。
1)方法的声明(定义)
func (recevier type) methodName(参数列表) (返回值列表){
方法体
return 返回值
}
(1)参数列表:表示方法输入
(2)receiver type:表示这个方法和type这个类型进行绑定,或者说改方法作用于type类型。type可以是结构体,也可以是其他的自定义类型。receiver就是type的一个变量(实例)
(3)参数列表:表示方法输入
(4)返回值列表:表示返回的值,可以多个
(5)方法主体:表示为了实现某一功能代码块
(6)return语句不是必须的。
2)方法注意事项
(1)结构体类型是值类型,在方法调用中,遵守值类型的传递机制,是值拷贝传递方式
(2)如果希望在方法中修改结构体变量的值,可以通过结构体指针的方式来处理
(3)golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定)
(4)方法的访问范围控制的规则和函数一样。方法名首字母小写,只能在本包中访问,方法首字母大写,可以在本包和其他包访问
(5)如果一个变量实现了String()这个方法,那么fmt.Println()默认会调用这个变量的String()进行输出
3)方法和函数区别
(1)调用方式不一样
函数的调用方式:函数名(实参列表)
方法的调用方法:变量.方法名(实参列表)
(2)对于普通函数,接受者为值类型时,不能将指针类型的数据直接传递,反之亦然。
(3)对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以。
14、接口
inerface类型可以定义一组方法,但是这些不需要实现。并且interface不能包含任何变量。到某个自定义类型要使用的时候,在跟进具体情况把这些方法写(实现)出来。type 接口名 interface{
method1(参数列表) 返回值列表
method2(参数列表) 返回列表
}
//实现接口所有方法
func (t 自定义类型) method1(参数列表)返回列表{
//方法实现
}
func(t自定义类型) method2(参数列表)返回值列表{
//方法实现
}
(1)接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低耦合的思想。
(2)golang中的接口,不需要显式的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现这个接口。因此,golang中没有implement这样的关键字。
package main
import "fmt"
type AInterface interface{
Say()
}
type Stu struct{
Name string
}
func(stu Stu) Say(){
fmt.Println("Stu Say()")
}
func main(){
var stu Stu
var a AInterface =stu
a.Say()
}
package main
type BInterface interface{
test01()
}
type CInterface interface{
test02()
}
type AInterface interface{
BInterface
CInterface
test03()
}
type Stu struct{
}
func(stu Stu)test01(){
}
func(stu Stu)test02(){
}
func(stu Stu)test03(){
}
func main(){
var stu Stu
var a AInterface =stu
a.test01()
}
(8)interface类型默认是一个指针(引用类型),如果没有对interface初始化就使用,那么会输出nil
(9)空接口interface{}没有任何方法,所以所有类型都实现了空接口。
4)实现对hero结构体切片的排序
sort.Sort(data Interface)
结构体切片要实现Interface的所有方法
package main
import(
"fmt"
"sort"
"math/rand"
)
type Hero struct{
Name string
Age int
}
//声明结构体对应的切片类型
type HeroSlice []Hero
//实现Interface接口
func (hs HeroSlice) Len()int{
return len(hs)
}
func (hs HeroSlice) Less(i,j int)bool{
return hs[i].Age >hs[j].Age
}
func(hs HeroSlice)Swap(i,j int){
temp:=hs[i]
hs[i]=hs[j]
hs[j]=temp
}
func main(){
var intSlice=[]int{0,-1,4,3,20}
sort.Ints(intSlice)
fmt.Println(intSlice)
//对结构体切片进行排序
var heroes HeroSlice
for i:=0;i<10;i++{
hero:=Hero{
Name:fmt.Sprintf("英雄~%d",rand.Intn(100)),
Age:rand.Intn(100),
}
heroes=append(heroes,hero)
}
for _,v:=range heroes{
fmt.Println(v)
}
//sort.Sort(data Interface)
sort.Sort(heroes)
for _,v:=range heroes{
fmt.Println(v)
}
}
5)接口与继承的比较
(1)实现接口是对继承机制的补充
(2)接口和继承解决的问题不同
继承的价值主要在于:解决代码的复用性和可维护性
接口的价值主要在于:设计好各种规范或者方法,让其他自定义类型去实现这些方法。
(3)接口比继承更加灵活
继承是满足is-a的关系,而接口只需满足like-a的关系。
(4)接口在一定程度上实现代码解耦
15、错误处理机制-defer、panic、recover
defer、panic、recover不要忘记defer语句后的圆括号,否则本该在进入时执行的操作会在退出时执行,而本该在退出时执行的,永远不会被执行。return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示: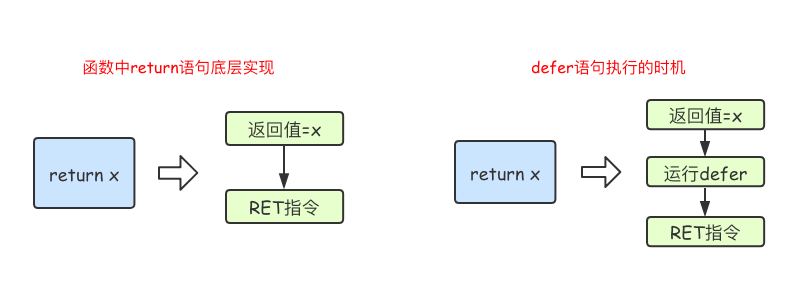
func f1() int {
x := 5
defer func() {
x++
}()
return x
}
func f2() (x int) {
defer func() {
x++
}()
return 5
}
func f3() (y int) {
x := 5
defer func() {
x++
}()
return x
}
func f4() (x int) {
defer func(x int) {
x++
}(x)
return 5
}
func main() {
fmt.Println(f1())
fmt.Println(f2())
fmt.Println(f3())
fmt.Println(f4())
}
func funcA() {
fmt.Println("func A")
}
func funcB() {
defer func() {
err := recover()
//如果程序出出现了panic错误,可以通过recover恢复过来
if err != nil {
fmt.Println("recover in B")
}
}()
panic("panic in B")
}
func funcC() {
fmt.Println("func C")
}
func main() {
funcA()
funcB()
funcC()
}
package main
import "fmt"
func test() {
//使用defer +recover来捕获和处理异常
defer func() {
err := recover()
if err != nil { //说明捕获到异常
fmt.Println("err:", err)
}
}()
num1 := 10
num2 := 0
res := num1 / num2
fmt.Println("rest=", res)
}
func main() {
test()
fmt.Println("main()...")
}
4)自定义错误
使用errors.New和panic内置函数
(1)errors.New("错误说明"),会返回一个error类型的值,表示一个错误。
(2)panic内置函数,接收一个interface{}类型的值(也就是任何值)作为参数。可以接收error类型的变量,输出错误信息,并退出程序。
(3)示例
package main
import (
"errors"
"fmt"
)
func readConf(name string) (err error) {
if name == "config.ini" {
return nil
} else {
return errors.New("读取文件错误...")
}
}
func test() {
err := readConf("config.in1i")
if err != nil {
panic(err)
}
fmt.Println("test()...")
}
func main() {
test()
}
16、类型断言
1)介绍
由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言,具体如下:
b=a.(Point)就是类型断言,表示判断a是否指向Point类型的变量,如果是就转成Point类型并赋给b变量,否则报错(panic)。
package main
import "fmt"
type Point struct{
x int
y int
}
func main(){
var a interface{}
var point Point=Point{1,2}
a=point
var b Point
b=a.(Point)//类型断言
fmt.Println(b)
}
二、其他说明
1、new和make
在Go语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的new和make。 Go语言中new和make是内建的两个函数,主要用来分配内存。
1)new
new是一个内置的函数,它的函数签名如下:
func new(Type) *Type
其中,
- Type表示类型,new函数只接受一个参数,这个参数是一个类型
- *Type表示类型指针,new函数返回一个指向该类型内存地址的指针。
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
示例代码中var a *int只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new函数对a进行初始化之后就可以正常对其赋值了:
func main() {
var a *int
a = new(int)
*a = 10
fmt.Println(*a)
}
2)make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数的函数签名如下:
func make(t Type, size ...IntegerType) Type
make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。
示例中var b map[string]int只是声明变量b是一个map类型的变量,需要像下面的示例代码一样使用make函数进行初始化操作之后,才能对其进行键值对赋值:
func main() {
var b map[string]int
b = make(map[string]int, 10)
b["沙河娜扎"] = 100
fmt.Println(b)
}
3)new和make区别
(1)二者都是用来做内存分配的;
(2)make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
(3)而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针;
2、文件
os.File封装所有文件相关操作,File是一个结构体。os.Open(name string)(*File,error)package main
import (
"fmt"
"os"
)
func main() {
//打开一个文件
file,error:=os.Open("./test.txt")
if error!=nil{
fmt.Println("open file error=",error)
}
fmt.Printf("file=%v",file)
//关闭文件
file.Close()
}
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
file, error := os.Open("./test.txt")
if error != nil {
fmt.Println("open file error=", error)
}
fmt.Printf("file=%v\n", file)
defer file.Close()
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF {
break
}
fmt.Print(str)
}
}
3、命令行参数
1)使用os.Args获取
os.Args是一个string的切片,用来存储所有的命令行参数。
4、json基本介绍
package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string
Age int
}
func testStruct() {
monster := Monster{
Name: "牛魔王",
Age: 500,
}
data, error := json.Marshal(&monster)
if error != nil {
fmt.Printf("序列化错误,error=%v\n", error)
}
fmt.Printf("monster序列化后=%v", string(data))
}
func main() {
testStruct()
}
package main
import (
"encoding/json"
"fmt"
)
func testMap() {
var a map[string]interface{}
a = make(map[string]interface{})
a["name"] = "红孩儿"
a["age"] = 99
data, error := json.Marshal(a)
if error != nil {
fmt.Printf("序列化错误,error=%v\n", error)
}
fmt.Printf("a序列化后=%v", string(data))
}
func main() {
testMap()
}
package main
import (
"encoding/json"
"fmt"
)
func testSlice() {
var slice []string
slice = append(slice, "1")
slice = append(slice, "2")
data, error := json.Marshal(slice)
if error != nil {
fmt.Printf("序列化错误,error=%v\n", error)
}
fmt.Printf("slice序列化后=%v", string(data))
}
func main() {
testSlice()
}
2)反序列化
package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string
Age int
}
func unserial() {
str := "{\"Name\":\"牛魔王\",\"Age\":500}"
var monster Monster
error := json.Unmarshal([]byte(str), &monster)
if error != nil {
fmt.Printf("unmarshal error=%v", error)
}
fmt.Printf("反序列化后monster=%v", monster)
}
func main() {
unserial()
}
5、goroutine(协程)
package main
import (
"fmt"
"strconv"
"time"
)
func test() {
for i := 1; i < 10; i++ {
fmt.Println("test():hello world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
go test() //开启了一个协程
for i := 1; i < 10; i++ {
fmt.Println("main():hello golang " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
6、Module
1)基本命令
(1)go mod init
(2)go mod graph
(3)go mod download
参考:如果你真心觉得文章写得不错,而且对你有所帮助,那就不妨小小打赏一下吧,如果囊中羞涩,不妨帮忙“推荐"一下,您的“推荐”和”打赏“将是我最大的写作动力!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号