Python数据挖掘之随机森林
主要是使用随机森林将four列缺失的数据补齐。
# fit到RandomForestRegressor之中,n_estimators代表随机森林中的决策树数量
#n_jobs这个参数告诉引擎有多少处理器是它可以使用。 “-1”意味着没有限制,而“1”值意味着它只能使用一个处理器。import pandas as pd #数据分析,引入pandas包,用以数据分析
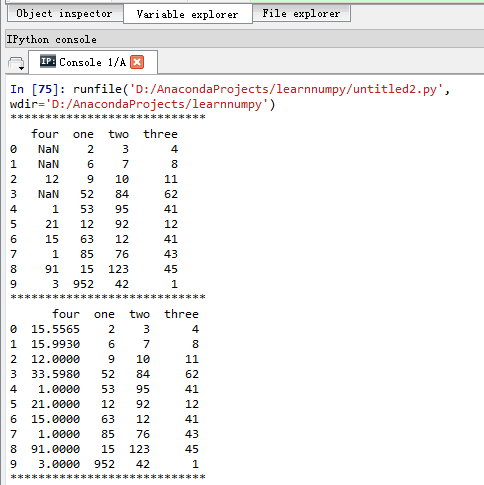
import pandas as pd #数据分析,引入pandas包,用以数据分析 from sklearn.ensemble import RandomForestRegressor #随机森林 data=[[2,3,4],[6,7,8],[9,10,11,12],[52,84,62],[53,95,41,1],[12,92,12,21],[63,12,41,15],[85,76,43,1],[15,123,45,91],[952,42,1,3]] df=pd.DataFrame(data,columns=['one','two','three','four']) df2=df[['four','one','two','three']] print('****************************') print(df2) known_data=df2[df2.four.notnull()].as_matrix() unknown_data=df2[df2.four.isnull()].as_matrix() y=known_data[:,0] X=known_data[:,1:] rfr = RandomForestRegressor(n_estimators=2000, n_jobs=-1) rfr.fit(X, y) predictedDatas = rfr.predict(unknown_data[:,1:]) print('****************************') df2.loc[(df2.four.isnull()),'four']=predictedDatas print(df2) print('****************************')
结果:
如果你真心觉得文章写得不错,而且对你有所帮助,那就不妨小小打赏一下吧,如果囊中羞涩,不妨帮忙“推荐"一下,您的“推荐”和”打赏“将是我最大的写作动力!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号