Python爬虫之urllib-登录博客园
拟使用cookie登录网站(以博客园为例):
首先使用自己的账号和密码在浏览器登录,然后通过抓包拿到cookie,再将cookie放到请求之中发送请求即可
import urllib.request headers = { "authority": "passport.cnblogs.com", "method": "GET", "path": "/user/LoginInfo?callback=jQuery1709735225435330517_1546482577013&_=1546482577074", "scheme": "https", "accept": "*/*", #"accept-encoding": "gzip, deflate, br", #如果有gzip和deflate 后面会打印二进制处理 "accept-encoding": "br", "accept-language": "zh-CN,zh;q=0.9", "cookie": "ga=GA1.2.1160747923.15453653550; __gads=ID=2c50bb50d0bb45d90:T=1545369966:S=AL.......略", "referer": "https://i.cnblogs.com/", "user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36", "x-requested-with": "XMLHttpRequest" } request = urllib.request.Request("https://www.cnblogs.com/commitsession", headers=headers) response = urllib.request.urlopen(request) print(response.read().decode('utf-8')) #不replace 直接decode 会报错 UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte #print(response.read().decode('utf-8', errors="replace"))
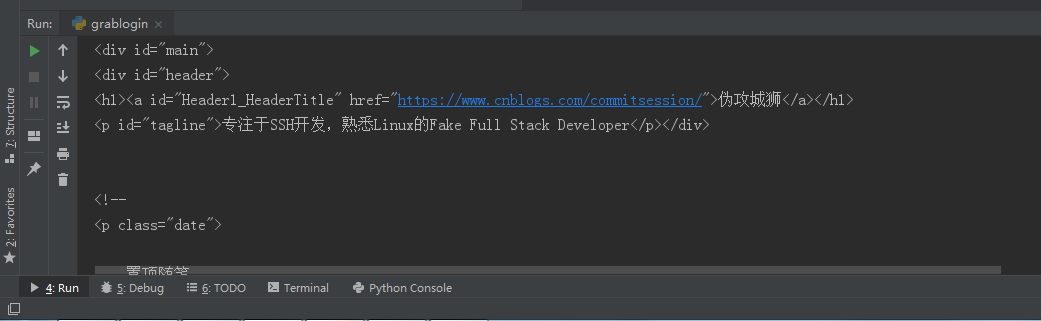
控制台打印:
如果你真心觉得文章写得不错,而且对你有所帮助,那就不妨小小打赏一下吧,如果囊中羞涩,不妨帮忙“推荐"一下,您的“推荐”和”打赏“将是我最大的写作动力!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号