ptmalloc
1、ptmalloc的3个层级:arena、bin、chunk
1) arena
a) arena是内存分配区,主线程会创建main arena, 其他线程会创建thread arena, 也就是存在多个arena,这样可以避免锁的竞争。main arena会通过sbrk()来扩容,它始终是一个连续的内存块。thread arena 不是说每一个线程都是创建自身分配区,它的数量有上限,32bit是cpu核心数的2倍,64bit是核心数的8倍,当它的空间不够时,它通过mmap()重新申请一块内存来实现扩容,所以thread arena的内存区域有可能不连续,它通过内部的heap_info结构体来管理多个内存区域。
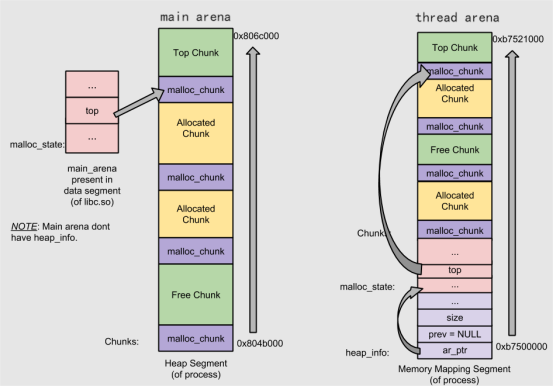
b) 上图中有个malloc_state结构体实例,它是用来存放arena的信息,单向链表,串联了不同的arena, 它包含锁,bins, topchunk,remainder chunk等信息。其中main_arena的malloc_state是全局静态实例,因此存放在.data区,thread arena的malloc_state实例存放在自身堆中。
struct malloc_state { /* Serialize access. */ mutex_t mutex; /* Flags (formerly in max_fast). */ int flags; #if THREAD_STATS /* Statistics for locking. Only used if THREAD_STATS is defined. */ long stat_lock_direct, stat_lock_loop, stat_lock_wait; #endif /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ unsigned int binmap[BINMAPSIZE]; /* Linked list */ struct malloc_state *next; #ifdef PER_THREAD /* Linked list for free arenas. */ struct malloc_state *next_free; #endif /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
c) thread arena空间扩展是通过mmap实现的,因此内存区域不是连续的,每块内存区域对应一个head_info结构体,通过单向链表串联起来。heap_info结构体数据也是存放在自身堆中。
struct _heap_info { mstate ar_ptr; /* Arena for this heap. */ struct _heap_info *prev; /* Previous heap. */ size_t size; /* Current size in bytes. */ size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */ /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;
2) chunk
chunk是最小的malloc分配单元,arena内存区域会分成多个大小不一的chunk,chunk的结构体视图如下,
struct malloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ struct malloc_chunk* fd; /* double links -- used only if free. */ struct malloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */ struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ struct malloc_chunk* bk_nextsize; };
这个结构体声明有一定的误导性,从上述注释字段可以看出,有些字段在不同场景是不使用的,例如prev_size在前一个chunk是空闲的才使用此字段,fd和bk只有在本chunk空闲时才会被使用,chunk实现了使用边界标记的方式分割内存块。
已分配的chunk如下,size字段的后3位分别代表
N--NON_MAIN_ARENA 0表示属于main arena, 1表示自身属于thread arena
M--IS_MMAPED 0表示是非直接通过mmap获取的内存,1表示通过mmap获取的内存,释放用unmap
P--PREV_INUSE 0表示前一个chunk未被使用,1表示已使用
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if allocated | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |N|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
空闲的chunk会有双向链表相连(fast bins为了更快的操作内存,使用单向链表,只用到了fd字段),如下:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
3) bin 是一个链表,它会串联不同类型的chunk,从而将其管理起来,根据不同大小的chunk,bin有几种:fastbin,smallbin,largebin,unsortedbin。
a) fast bin
malloc_state中的fastbinsY[NFASTBINS],NFASTBINS为10,每一个元素都是一个单向链表,存放对应大小的空闲chunk,对于linux64bit系统来说,最小是32B,然后每个数组下标递增16B。对于小块内存申请,直接从fast bin中获取,释放也直接存回fast bin。对比其他三种bin,为追求高效,只有fast bin使用chunk的单向链表,通过cas操作增删chunk指针。fast bin会被合并操作,回收碎片内存,以下四种情况会执行合并操作
(1)small bin中未找到空闲chunk后,执行合并
(2)要到large bin中寻找合适chunk,先执行合并,避免太多碎片
(3)调用brk或者mmap函数前再合并一次
(4)free释放的时候,如果前后chunk合并的size > 64K 则先合并fastbin,因为后面要收缩top chunk
b) small bin
malloc_state中的 bins[NBINS * 2 - 2],NBINS 宏定义为128, 第0下标表示unsortedbin,1~128表示smallbin,剩下的表示largebin。小于1024B(64bit)/512B(32bit)的chunk块存放在此容器中,chunk块使用双向链表,chunk的大小也是按照数组下标递增
c) large bin
大于等于1024B(64bit)/512B(32bit)的chunk块存放在此容器中
d) unsorted bin
起一个缓冲作用, 其他bin合并后的新chunk块先存放在这里面,chunk块大小无限制,执行申请内存时,在fast bin 和small bin中未找到chunk后,会从unsorted bin中寻找空闲chunk, 如果没有找到, 会将unsorted bin上的chunk重新分配至其他bin上。
2、malloc流程
1) 找内存分配器arena。
查找线程本地存储key值为arena_key对应的malloc_state结构体指针,即查找arena,如果沒有arena,如果未查过上限数,则创建新的thread arena,超过上限则复用之前的arena(main_arena在ptmalloc_init()中被存入arena_key中)。首次申请的arena内存区块不小于32k,不大于32bit512K/64bit32M,获取到arena后再附上锁。
2) 规范化入参长度size
判断申请size是否超过上限值(unsigned long - 2*最小长度),是否小于最小长度(chunk结构体前四个指针的长度,32位系统16字节,64位系统32字节),是否对齐(对齐长度为2*sizeof(size_t), 32位系统8字节,64位系统16字节)
3) if申请size如果小于max_fast(默认值32bit64字节/64bit128字节,可通过mallopt设置),则从fast bins上寻找合适的chunk,如果未找到则继续往下走
4) if申请的size小于1024字节(32位512字节),从small bins寻找合适的空闲chunk,如果未找到,则合并fastbin至unsortedbin
5) else 如果size >= 1024,且有fastbin, 先合并fastbin至unsortedbin。
6) 遍历unsortedbin,针对unsortedbin里的每一个chunk,先移出unsortedbin,如果此chunk大小合适,则返回此chunk的mem指针,否则迁入smallbin或者largebin,如果最后只剩一个remainder chunk,且申请的size小于1024,且remainder chunk的size大于申请的对齐字节,则切割remainder chunk,分配内存。
6) 至此,fastbin和smallbin都没找到空闲chunk,fastbin也经过合并至unsortedbin,然后分配至smallbin和largebin。这时,在largebin中寻找,如果仍没有找到,则从top chunk中切割内存,
7) 如果top chunk的size也不够申请的size+chunk的头两个字节长度,则调用sysmalloc再向系统申请内存,如果size >128k,则直接调用mmap在mmap区域申请内存作为mmap类型的chunk返回给用户,否则,对于main_arena, 调用sbrk扩展top_chunk的长度,对于thread_arena, 调用mmap在堆区申请新的arena分配区来增加新的top chunk的长度
3、free的过程
1) 如果参数为0,直接return
2) 判断指针所属chunk是否IS_MMAPPED, 如果是,直接调用unmap释放内存
3)if释放的size小于max_fast(默认值32bit64字节/64bit128字节,可通过mallopt设置), 获取所属arena的malloc_state的锁,将chunk插入fastbin, 并且设置malloc_state的fastbin标志位flag为0(表示有fastbin非空),否则进入4)
4) else 前一个chunk空闲,则合并前一个chunk, 如果后一个chunk是空闲的,且非top chunk,合并后一个chunk,否则置空后一个chunk的P位,合并后的新chunk存入unsorted bin
5) 如果后一个chunk是top chunk,合入top chunk
6) 判断合并后的新chunk是否大于FASTBIN_CONSOLIDATION_THRESHOLD(64k),如果是的,合并fastbin至unsortedbin
7) 在6)的前提下,如果是main_arena,且top chunk的size >= trim_threshold(默认128K),则systrim,调用sbrk进行内存回收。如果是thread_arena, 则heap_trim,调用madvise 进行内存回收(thread_arena不判断trim_threshold,它总是会缩减内存)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号