哈希 02
1、哈希的概念:
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
特点: 输入相同,输出一定相同 。输入不同,输出有可能相同,这种情况就叫做 哈希碰撞
2、 常见的哈希使用: HashSet、HashTable、Dictionarty、MD5、SHA
3、常见的哈希算法: 直接寻址(如 A+B)、取余、折中、随机数、折叠发、等
4、哈希常用于分布式环境中,通过不同的业务来映射不同的服务器
最简单的一种算法就是 取余数 ,key%n=z ,n 也叫做负载因子,z就是对应映射的服务器,比如
// 假设这里有4台服务器
Dictionary<int, string> servers = new Dictionary<int, string>();
servers.Add(0, "A服务器"); //0对应A服务器
servers.Add(1, "B服务器");// 1对应B服务器
servers.Add(2, "C服务器");// 2对应C服务器
servers.Add(3, "D服务器");// 3对应D服务器
// 假设keys 中的 id 为业务模块或数据id,假设有30个
int[] keys = new int[30];
for (int i = 0; i < 30; i++)
{
keys[i] = i;
}
//这里模拟将业务Id进行哈希计算
var Hash = new Func<int, int>((x) =>
{
return x % servers.Count();
});
// 这个模拟数据请求
for (int j = 0; j < 50; j++)
{
Console.WriteLine($"该请求被转发到{servers[Hash(j)]}");
}
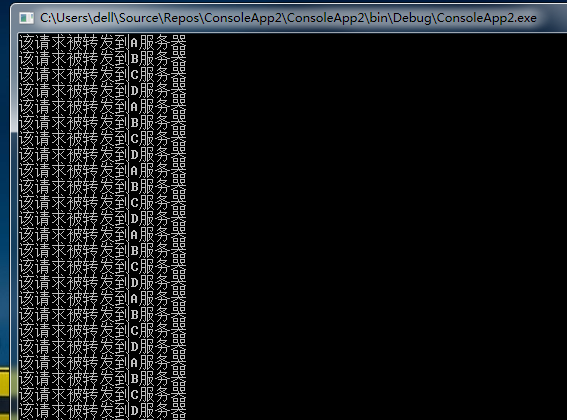
上面可以看出,当服务器数量固定的时候,根据业务id 取余数,被均匀的转发到了 ABC D 4台服务器,当然这是一种最简单的做法。在实际情况中,并没有这么简单。
5 哈希一致性
百度:一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,目的是解决分布式缓存的问题。 [1] 在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题 [2]
在实际应用中,往往服务器的数量不是固定的,有可能动态增加或减少,映射关系就会错乱,比如 原来 4%4 =0,映射在A服务器上,现在增加一台 编程4%5=4 映射在第四台服务器,后面的映射基本上全部错乱。为了减少这种情况,就有了哈希一致性的概念,哈希一致性其实是为了增强系统的鲁棒性。在宕机或者增加服务器时,把受到的影响降到最低。
为了解决 哈希一致性的问题,即出现了哈希环。
上面的只经过了1次Hash,哈希环需要进行两次哈希,即 将对应的key(比如业务id) 进行一次hash,然后将服务器进行一次hash。
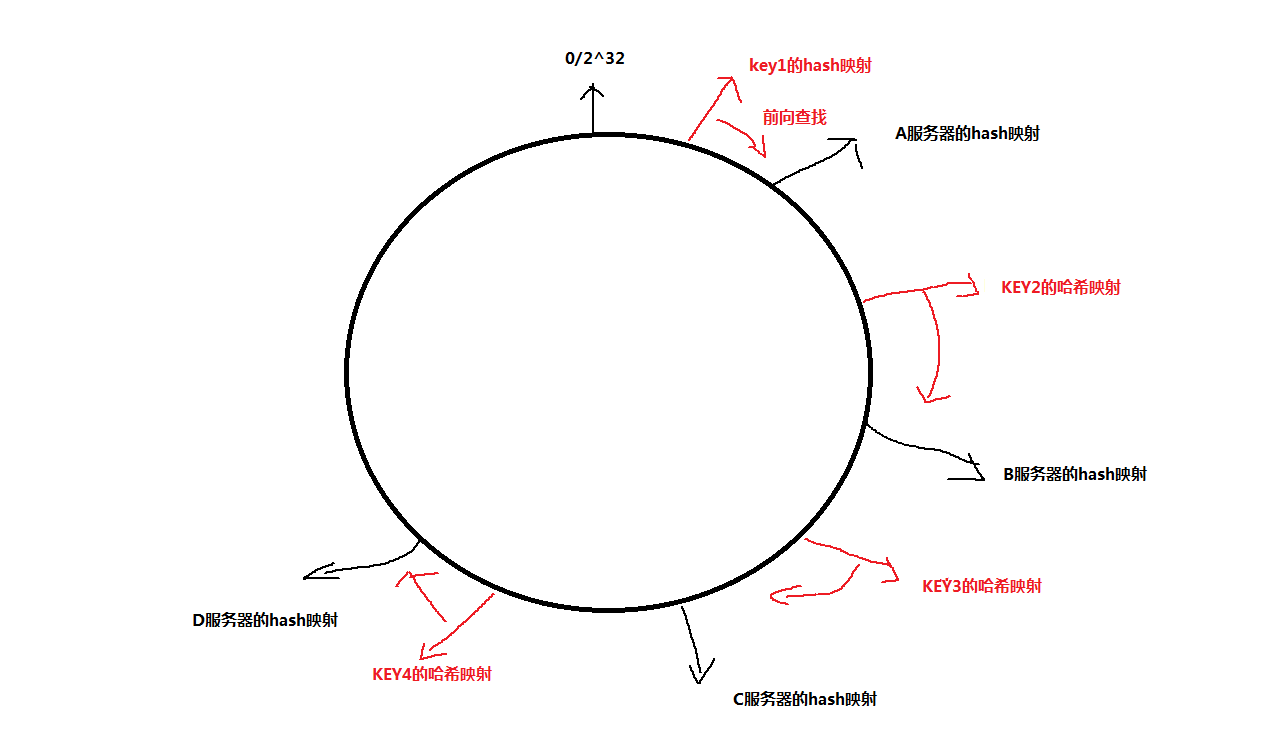
a 哈希环的取值空间我们用Uint(无符号32位整形),范围为 0~2^32 ,我们将吧key 和 服务器都进行hash算法,映射到这个环上面。如下:
如图: 先把4台服务器进行hash 映射,然后将key值也进行映射,都映射在这个环上。(理论上输入的值足够多的话,会出现hash碰撞,实际过程中应该够用了,也就是输入远大于输出的hash值)
b 计算:
如下图,进行映射之后,key1 进行相关的计算,找出离他最近的1台服务器,也就是A服务器,然后(key1,A服务器)形成了一对映射关系,依次key2,key3,key4顺时针方向都找到他最近的一台服务器形成映射关系。
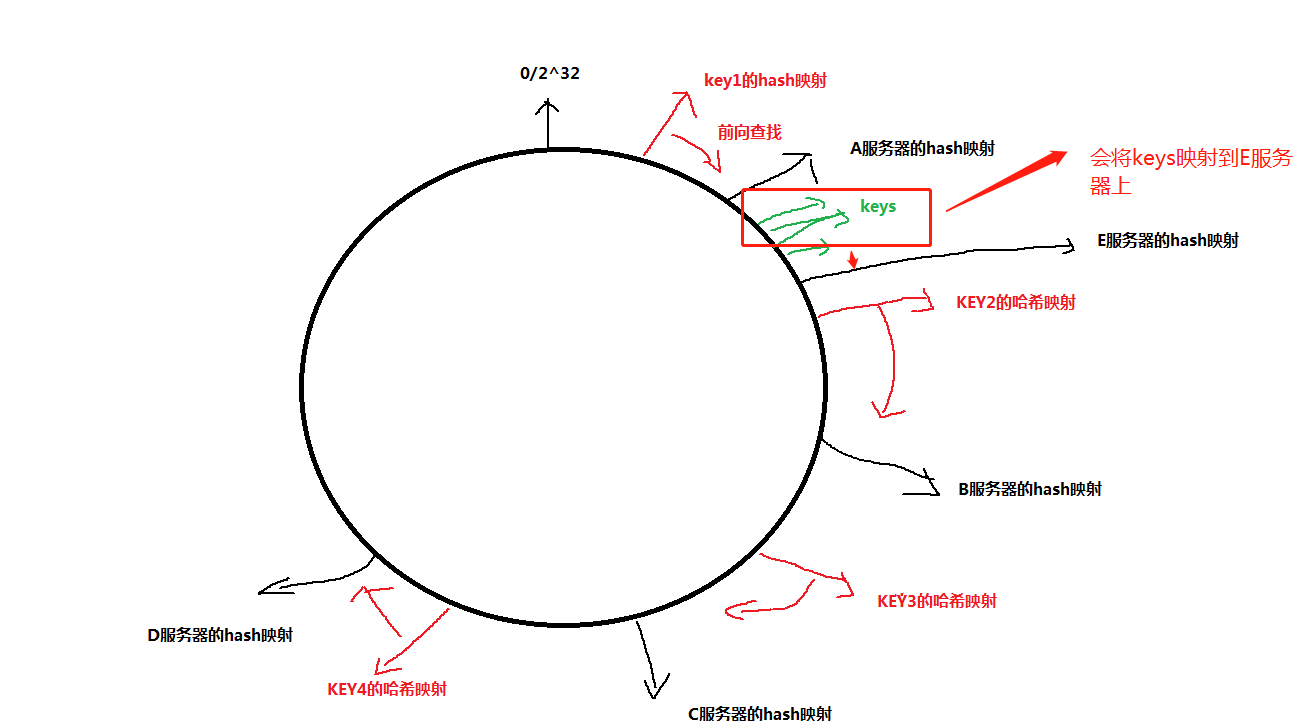
c 实际过程中,我们可能动态的添加或减少服务器如上图,加入我们把A服务器去调,那key1 就会影射到离他最近的B服务器, key2,key3,key4 的映射关系不会改变,这样大大增加系统的鲁棒性,将影响降到最低。
同样我们增加1台服务器E在A和B 之间, 如下面,绿色的keys 会映射到E 服务器,但是并没有影响KEY2以及其他服务器的映射关系。
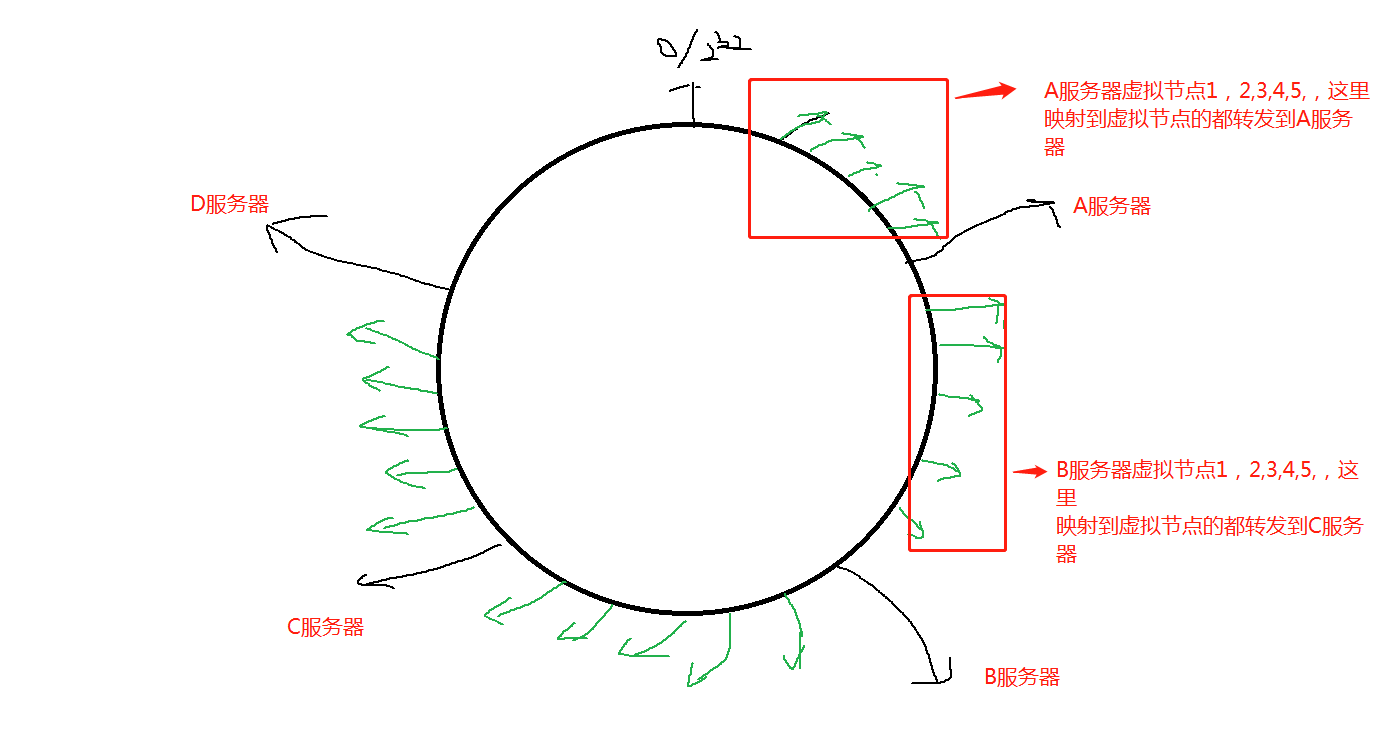
6、 数据倾斜
当服务器的数量非常少的时候,有可能会将大量的数据映射到1台服务器,其他服务器的映射非常少,如下图。

所以,我们可以通过增加 虚拟节点的方式 使得 负载 均衡,比如A,,B,C,D 没太不服务器建立 5个虚拟节点,通过以下方式,大大降低了 某个服务器负载过重的情况