

python爬虫学习第一天
一个简单的爬虫程序
# -*-coding:utf-8-*- from urllib.request import urlopen url = "https://blog.csdn.net/weixin_53475254?spm=1000.2115.3001.5343" resp = urlopen(url) with open("my.html",mode = 'w',encoding='utf-8') as f: f.write(resp.read().decode('utf-8')) print("ok")
库
urllib 为与网页相关的库,lib为库的缩写,下面是百度关于url的解释

from urllib.request import urlopen 代码的意思就是从urllib库的request模块里面引入urlopen函数
定义字符串来储存网站。
url = "https://blog.csdn.net/weixin_53475254?spm=1000.2115.3001.5343"
通过urlopen函数打开网站,返回一个对象,存储在resp中。
resp = urlopen(url)
以写的模式打开一个名为my.html的文件,通过read函数把和decode函数以"utf-8"编码方式将数据写入my,html中
with open("my.html",mode = 'w',encoding='utf-8') as f: f.write(resp.read().decode('utf-8'))
效果
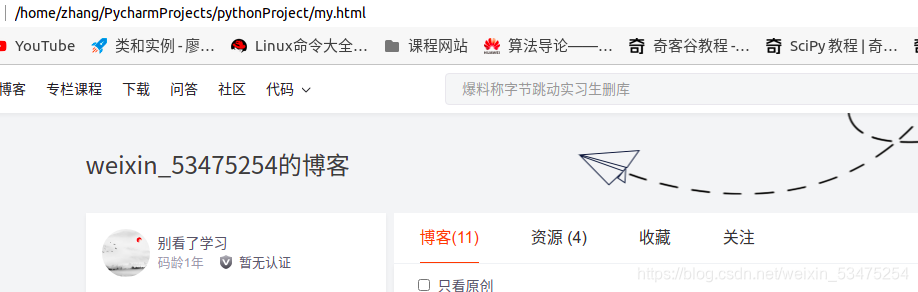
得到文件,这个文件是网页的源码,在浏览器中打开就是对应的网页
总结
- 请求类型为GET和POST,分别用get和post函数来抓取。
- get的参数为params,post类的参数为data,且都必须通过字典传入
- 爬虫需要的3个基本要素
- URL
- 类型(GET,POST)
- 参数(非必要)
- 一些简单的反爬虫机制:识别User-Agent
正常的:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36
爬虫程序
{'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
可以通过传入参数来绕过这个反爬机制(改变headers)
# -*-coding:utf-8-*- import requests url = "https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=20" header = { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36" } resp = requests.get(url=url,headers=header) print(resp.json()) resp.close()
本文来自博客园,作者:墨镜一戴谁也不爱,转载请注明原文链接:https://www.cnblogs.com/hnuzmh/p/16196559.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!