备用Spark-Python集高可用ZK-Spark配置----公司使用,赞未测试
1.Spark安装
1安装SCALA
1) 使用命令tar -zvxf scala-2.11.7.tgz解压该压缩包, 修改环境变量.
2) 与JDK一样,使用命令vi /etc/profile 修改环境变量的配置文件,之后使用命令 source /etc/profile,使文件修改生效。
3) 使用命令scala -version检查scala是否安装成功
unset i
unset -f pathmunge
export JAVA_HOME=/usr/java/jdk1.8.0_161
export MSMTP_HOME=/usr/local/msmtp
export FREETDS_HOEM=/usr/local/freetds
export ERLANG_HOME=/usr/local/erlang
export PATH=$PATH:$JAVA_HOME/bin:${ERLANG_HOME}/bin:${FREETDS_HOEM}/bin:${MSMTP_HOME}/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export TOMCAT_HOME=/usr/tomcat8.5.23
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${FREETDS_HOEM}/lib
export LD_LIBRARY_PATH=/usr/lib64:$LD_LIBRARY_PATH
export ZOOKEEPER_HOME=/home/zookeeper
export PATH=/usr/local/sbin:/usr/bin:/bin:/sbin:/usr/sbin:/mnt/sysimage/bin:/mnt/sysimage/usr/bin:/mnt/sysimage/usr/sbin:/mnt/sysimage/sbin:/sbin:/usr/sbin:/usr/java/jdk1.8.0_161/bin:/usr/local/erlang/bin:/usr/local/freetds/bin:/usr/local/msmtp/bin:/bin
export ORACLE_HOME="/usr/lib/oracle/11.2/client64"
export PATH=$PATH:$ORACLE_HOME/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib
export KAFKA_HOME=/opt/kafka
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$KAFKA_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
export SCALA_HOME=/opt/scala-2.11.7
export SPARK_HOME=/opt/spark-2.3.1
2.安装SSH服务
使用命令yum -y install openssh-server进行安装,
3配置SSH免密码登录
1) 在每台主机上生成公钥和私钥对
ssh-keygen -t rsa
连续按几次ENTER
2) 将所有公钥加载到用于认证的公钥文件authorized_key中,并查看生成的文件。
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
3) 最后使用SSH命令,检验是否能免密码登录。
ssh localhost
退出登录
exit
4安装Spark
1) 解压spark压缩包, tar –zvxf spark-2.3.1-bin-hadoop2.7.tgz。
2) 重命名文件夹mv spark-2.3.1-bin-hadoop2.7 spark-2.3.1
3) 配置环境变量 vi /etc/profile 配置SPARK_HOME、PATH,然后source /etc/profile
4) 使用命令cd /spark-2.3.1/conf,在该目录下,看到很多文件都是以template结尾的,这是因为spark给我们提供的是模板配置文件,我们可以先拷贝一份,然后将.template给去掉,变成真正的配置文件后再编辑
5) 配置spark-env.sh,该文件包含spark的各种运行环境
cd /spark-2.3.1/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
配置以下信息(最上面的原始文件有)
export SCALA_HOME=/opt/scala-2.11.7
export SPARK_LOCAL_DIRS=/opt/spark-2.3.1/tmp #缓存目录
export SPARK_MASTER_IP=172.21.1.254 #master ip
export SPARK_MASTER_WEBUI_PORT=8085 #webui端口
export SPARK_WORKER_CORES=6 #worker节点核心数
export SPARK_WORKER_MEMORY=6g # worker节点内存
6) 配置slaves文件
cp slaves.template slaves
vim slaves
配置以下信息
localhost
7) 启动spark集群
cd /spark-2.3.1/sbin
./start-all.sh
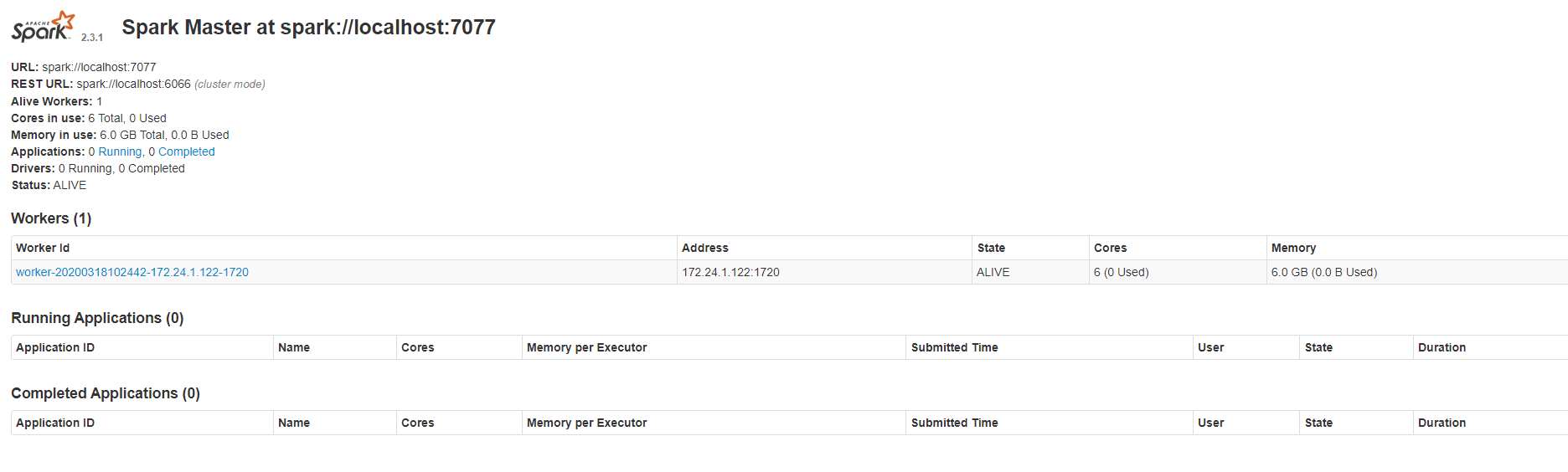
8) 查看Spark集群信息
使用jps命令查看spark进程。
Worker
Master
查看spark管理界面,在浏览器中输入: http://172...:8085
运行 spark-shell,可以进入 Spark 的 shell 控制台
./bin/spark-shell
5停止运行集群
运行sbin/stop-all.sh停止Spark集群
6、依赖包导入(这部是自己写的Spark分析程序,实际就是自己的业务包)
将我们提供的依赖包放入/ spark-2.3.1/jars 目录下
--------那么Spark的安装说明就到此结束啦
5.Python环境搭建
一 前期组件安装
1.安装readline-devel
yum –y install readline-devel
2.安装python-devel
yum install python-devel
3. 安装sqlite-devel
yum install sqlite*
二 python安装
1、安装包准备Python-3.6.0.tgz放在/usr/local/
2、以root权限打开终端,进入安装包的存放路径,解压安装包:
tar -xzvf Python-3.6.0.tgz
3、进入解压好的安装包路径:
cd Python-3.6.0
4、编译安装包,指定安装路径,并执行安装命令:
注意:prefix参数用于指定将Python安装在新目录,防止覆盖系统默认安装的python
./configure --prefix=/usr/local/python36
make && make install
6、建立新的软连接,指向Python-3.6.0:
注:这里的python36是第4步指定的安装路径,python3.6是Python包里的可执行程序
ln -s /usr/local/python36/bin/python3.6 /usr/bin/python3
7、输入python3验证是否装好

退出 exit()
现在linux下有两个版本的python,输入python进入的是以前的Python2.7的版本,输入python3进入的是刚安装的python3.6版本

8、导入依赖包
将我们准备的site-packages包替换python里的site-packages
cd /usr/local/python36/lib/python3.6
mv site-packages site-packages_1
将site-packages复制到/usr/local/python36/lib/python3.6目录下
安装了以前版本的修改
mv /usr/bin/python /usr/bin/python3
cp /usr/bin/python-2.7 /usr/bin/python

