Java调用Kafka生产者,消费者Api及相关配置说明
本次的记录内容包括:
1.Java调用生产者APi流程
2.Kafka生产者Api的使用及说明
3.Kafka消费者Api的使用及说明
4.Kafka消费者自动提交Offset和手动提交Offset
5.自定义生产者的拦截器,分区器
那么接下来我就带大家熟悉以上Kafka的知识说明
1.Java调用生产者APi流程
首先上一张从网上找的简单的图,来描述一下生产者的生产流程。这里这个的图描述的不是非常精确,稍微有点问题的地方就是省略了拦截器内容,这块的内容在实际场景中也经常使用
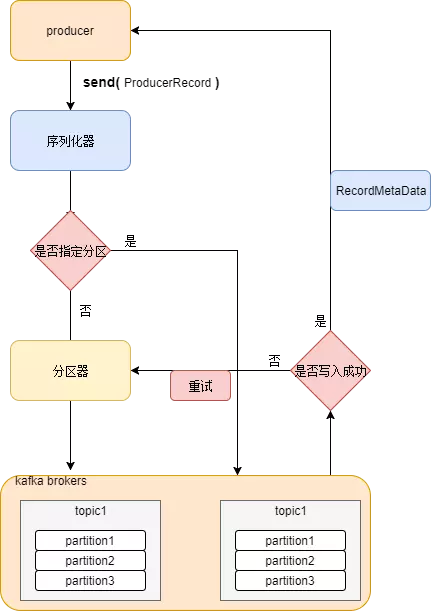
那么从图中我们可以看到。生产者通过调用api的Send方法开始进行一些列生产控制操作,首先进入的是一个叫序列化器的处理结构(这里就先按图来讲了--实际第一步会先经过拦截器),那么这一步主要的操作就是序列化相关数据,保证数据传输的稳定准确性,个人理解需要序列化的原因是因为kafka是磁盘文件写消息,序列化后悔经过分区器,主要就是我们上篇讲过的关于如何生产消息分区的策略,主要有三种,1.指定分区,2根据key的hash取余有效分区数分区,3初始化整数,轮训分区。具体细节请参考上一篇文章(https://www.cnblogs.com/hnusthuyanhua/p/12355216.html)。经过分区后消息将会发送到指定的分区供消费者消费。
那么从图中我们还可以看到有一个RecordMetaData的存在,这又是干什么的呢?这里就又设计到另一个知识点了。由于在网上未找打相关描述图,我这里就粗略说明一下
大致的kafka生产者程序一般是有两类线程进行,一个是主线程,另一个是生产消息的线程,他们质检有一个RecoderMetaData作为消息存储缓存,同时也是线程共享变量,当主线程不断生产消息,本质上就是不断累积RecoderMetaData的缓存值,当缓存值达到限定时,生产者线程开始讲数据发送至kafka.。那么kafka生产者的一个流程大概就是这样了
2.Kafka生产者Api的使用及说明
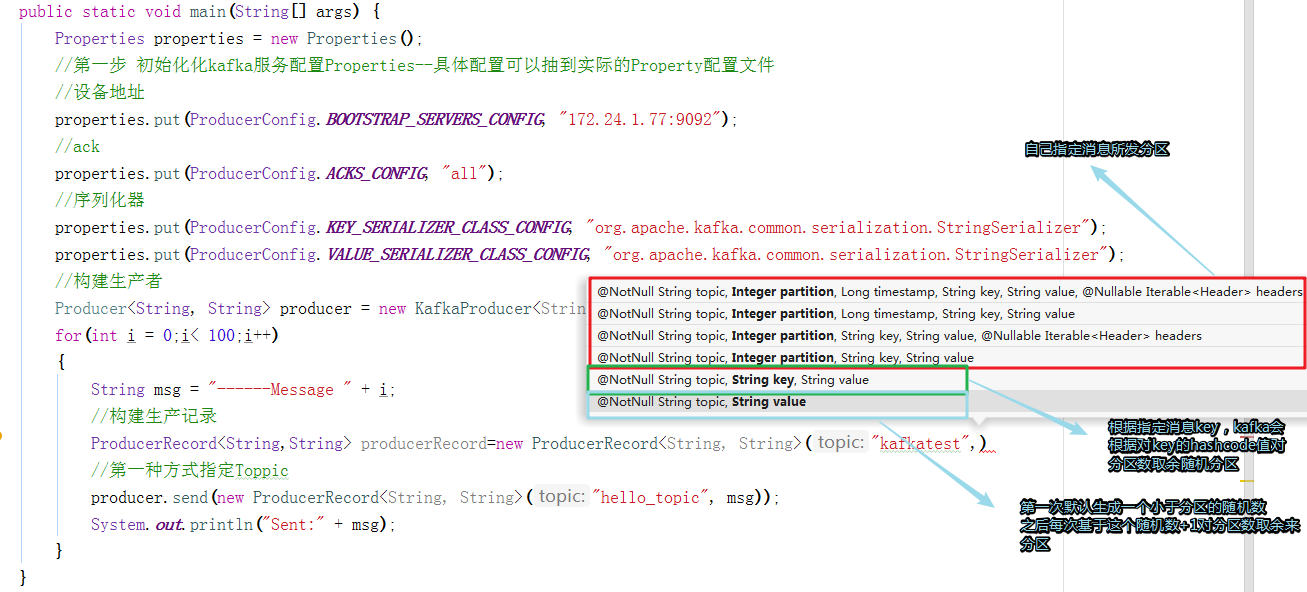
大致流程:配置kafka property信息---构建生产者---构建消息---发送消息---关闭资源
@Slf4j
public class KafkaProduce {
public static void main(String[] args) {
Properties properties = new Properties();
//第一步 初始化化kafka服务配置Properties--具体配置可以抽到实际的Property配置文件
//设备地址
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "172.24.1.77:9092");
//ack
properties.put(ProducerConfig.ACKS_CONFIG, "all");
//序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//构建生产者
Producer<String, String> producer = new KafkaProducer<String, String>(properties);
for(int i = 0;i< 100;i++)
{
String msg = "------Message " + i;
//构建生产记录
//第一种方式指定Toppic
ProducerRecord<String,String> producerRecord=new ProducerRecord<String, String>("kafkatest",msg);
//send方法分为有返回值和无返回值两种
// 无返回值简单发送消息
//producer.send(producerRecord);
//有返回值的在发送消息确认后返回一个Callback
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e==null){
//发送数据返回两个东西--一个是返回结果 一个是异常 异常为空时即发送操作正常
if (e==null){
//返回结果中可获取此条消息的相关分区信息
System.out.println(recordMetadata.offset()+recordMetadata.partition()+recordMetadata.topic());
}
}
}
});
log.info("kafka生产者发送消息{}",msg);
}
producer.close();
}
}
kafka分区策略方法说明:
3.Kafka消费者Api的使用及说明
大致流程:配置kafka property信息---构建消费者---订阅主题--消费消息
@Slf4j
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
//第一步 初始化化kafka服务配置Properties--具体配置可以抽到实际的Property配置文件
//设备地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "172.24.1.77:9092");
//反序列化器
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group-1");
//offset自动提交
//properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//重置offset---当团体名发生改变时且消费者保存的初始offset未过期时,消费者会从头消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
//初始化消费者
Consumer consumer=new KafkaConsumer(properties);
//初始化消费者订阅主题
consumer.subscribe(Arrays.asList("kafkatest"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
//消费完按自动提交时间自动提交消费Offset
log.info("kafka消费者消费分区:{}-消息内容:{}",record.partition(),record.value());
}
//异步提交-即消费某条数据时发送offset更新,但消费继续运行 不等待提交完成 效率较高 但当消费者异常挂掉时容
//易造成消费重复
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
//如果失败E不为null 失败的话E为Null
//对于需要绝对保证消息不丢失的 可在此处重新进行消费提交
}
});
//同步提交-即消费一条数据提交一次offset更新,消费必须等待offset更新完才可继续运行。通常来讲此方法可尽可能
//的减少数据丢失 但效率较低
//consumer.commitSync();
}
}
}
4.Kafka消费者自动提交Offset和手动提交Offset
自动提交:即消费者消费后自己提交消费offset标记去kafka更新信息,那么通常是通过时间来控制的,比如每10秒更新一次本地的offset到kafka, 缺点:实际应用场景中难以控制时间,太短容易造成数据丢失(offset已经更新 消费者还没消费完就挂了),太长容易导致数据重复(offset还未更新,消费者挂了重新从kafka拉取之前的offset).
手动提交:消费完成后自行提交offset,根据同步情况分为两种方式,syn提交(提交时相当于阻塞主线程,等offset提交完成后方可继续进行)和asyn提交(异步提交),大致流程:配置kafka property配置文件,将配置文件中的自动提交关闭。--构建消费者订阅主题并消费--消费完成后手动提交offset. 缺点:同样还是会有上面自动提交的数据重复问题。但减少了数据丢失的可能性。
5.自定义生产者的拦截器,分区器
@Slf4j
public class KafkaFilter implements ProducerInterceptor {
public static int i=0;
@Override
public ProducerRecord onSend(ProducerRecord producerRecord) {
/**
* 发送消息的方法 可对消息进行处理 比如加时间戳啥的
*/
log.info("{}:{}",producerRecord.topic(),producerRecord.partition(),producerRecord.value());
return producerRecord;
}
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
/**
* ack标记回调方法,有点类型Callback回调的方法
* 可在这统计一下成功发送的条数和失败发送的条数
*/
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
public class KafkaPartion implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
/**
* 自定义分区 可通过该接口的默认分区器进行参考 默认为根据订阅的主题来分区方式
*/
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
6.消费者如何消费历史数据
大致流程:配置kafka property信息,开启AutoOffset配置---构建消费者---订阅主题--消费消息
那么每次开启消费者如果想从头开始消费,需要满足以下条件之一:1.消费者的组名改变 2.消费者的初始offset未过期
相关参考文章:
https://www.jianshu.com/p/1f9e18e926f6
kafka消费者监听方式
https://www.jianshu.com/p/a64defb44a23

