
记录一次 java内存泄漏的排查
1、问题:jar进程会随着时间由 30% 上涨到 70% 直到虚机报警。重启过后,还是会缓慢上涨:
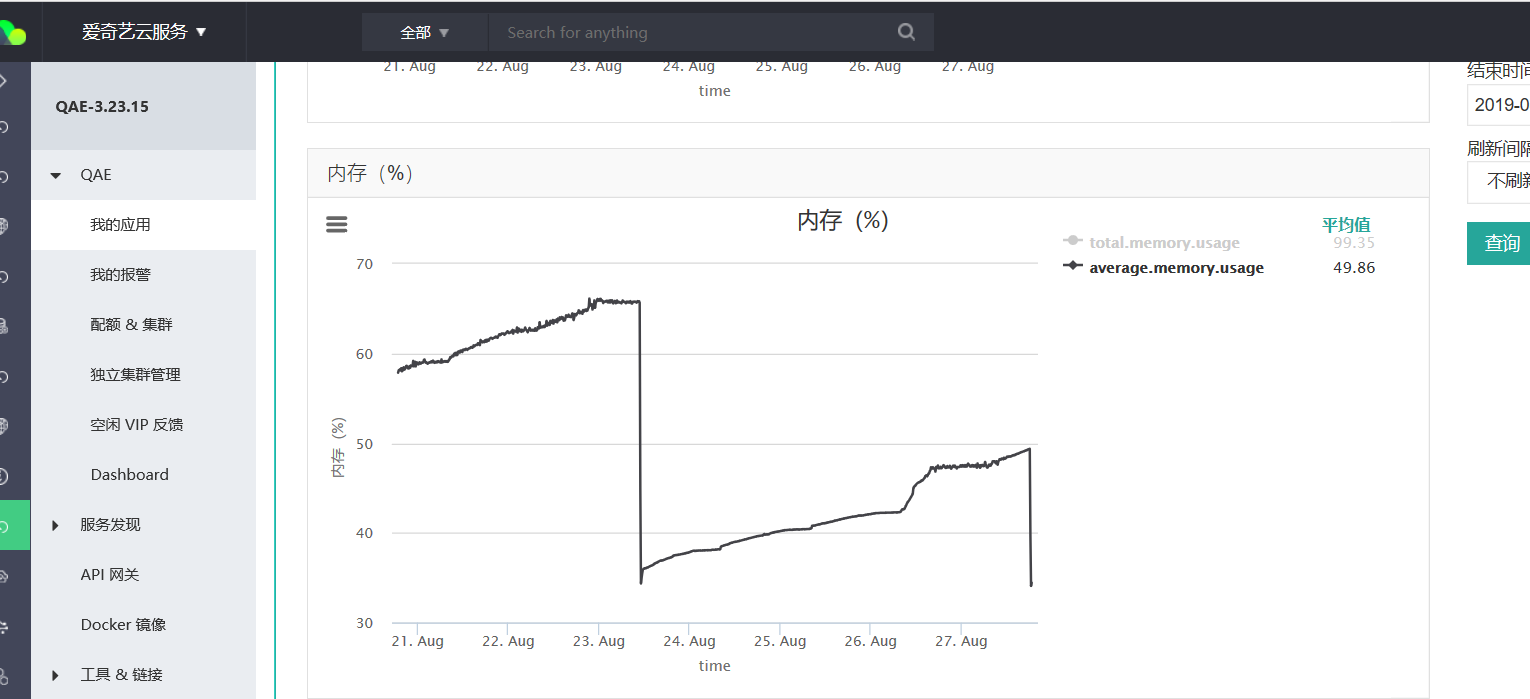
进程数也在上涨:
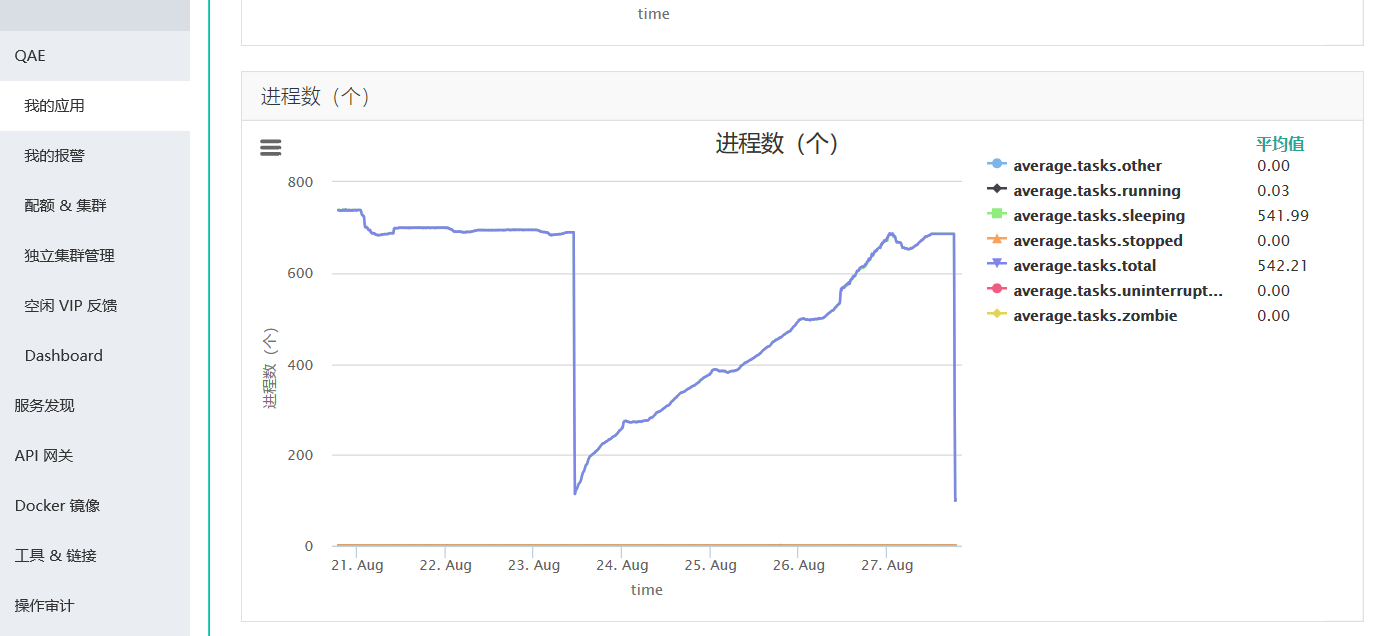
2、在排查内存问题时,可能会使用的命令
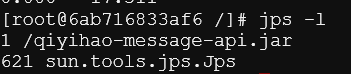
1)查看 java 进程:jps -l 可以看到当前进程号为 1
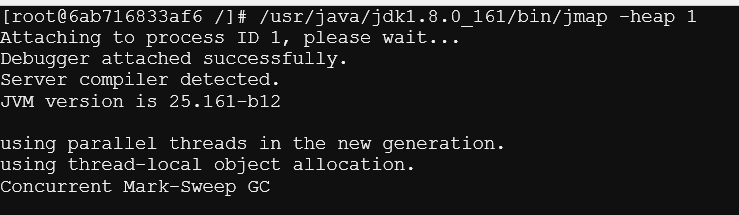
2)查看对上内存的使用情况:
/usr/java/jdk1.8.0_161/bin/jmap -heap 1
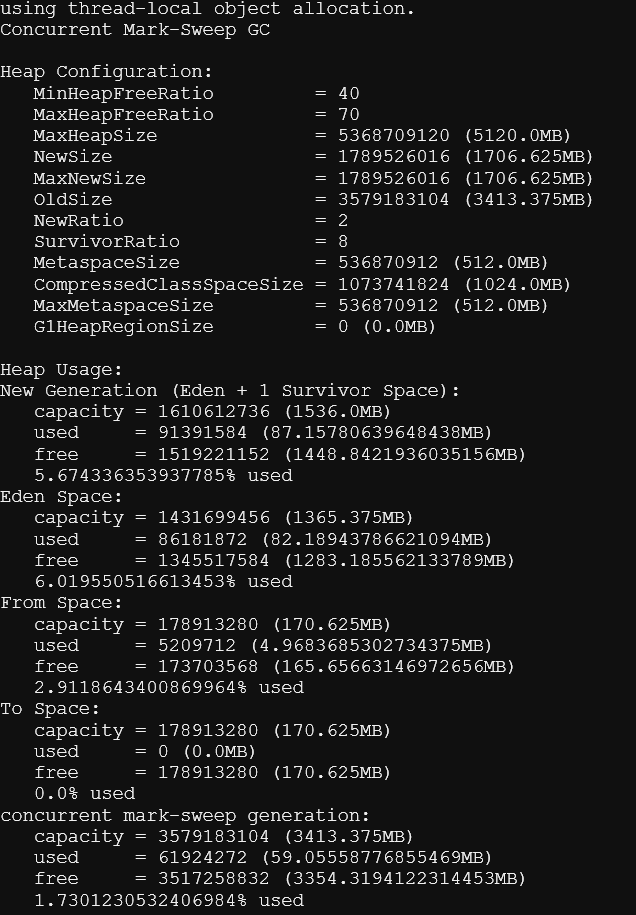
3)pmap -x 1
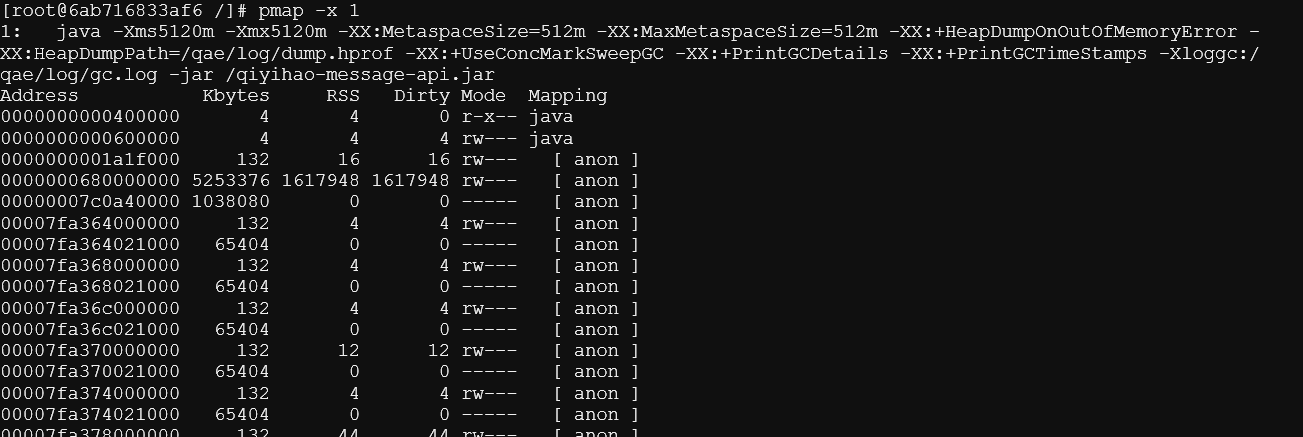
4)jstat -gc 1

5)导出堆栈信息:jmap -dump:format=b,file=/qae/log/dump.dat

2、将上面 5)中导出的堆栈文件,使用 MemoryAnalyzer.exe 打开:
3、通过 mat 的泄漏分析中,可以看到有两个问题,其中第一个可以大概猜出是 JPA的相关数据库操作导致的泄漏,点开 detail 继续分析:
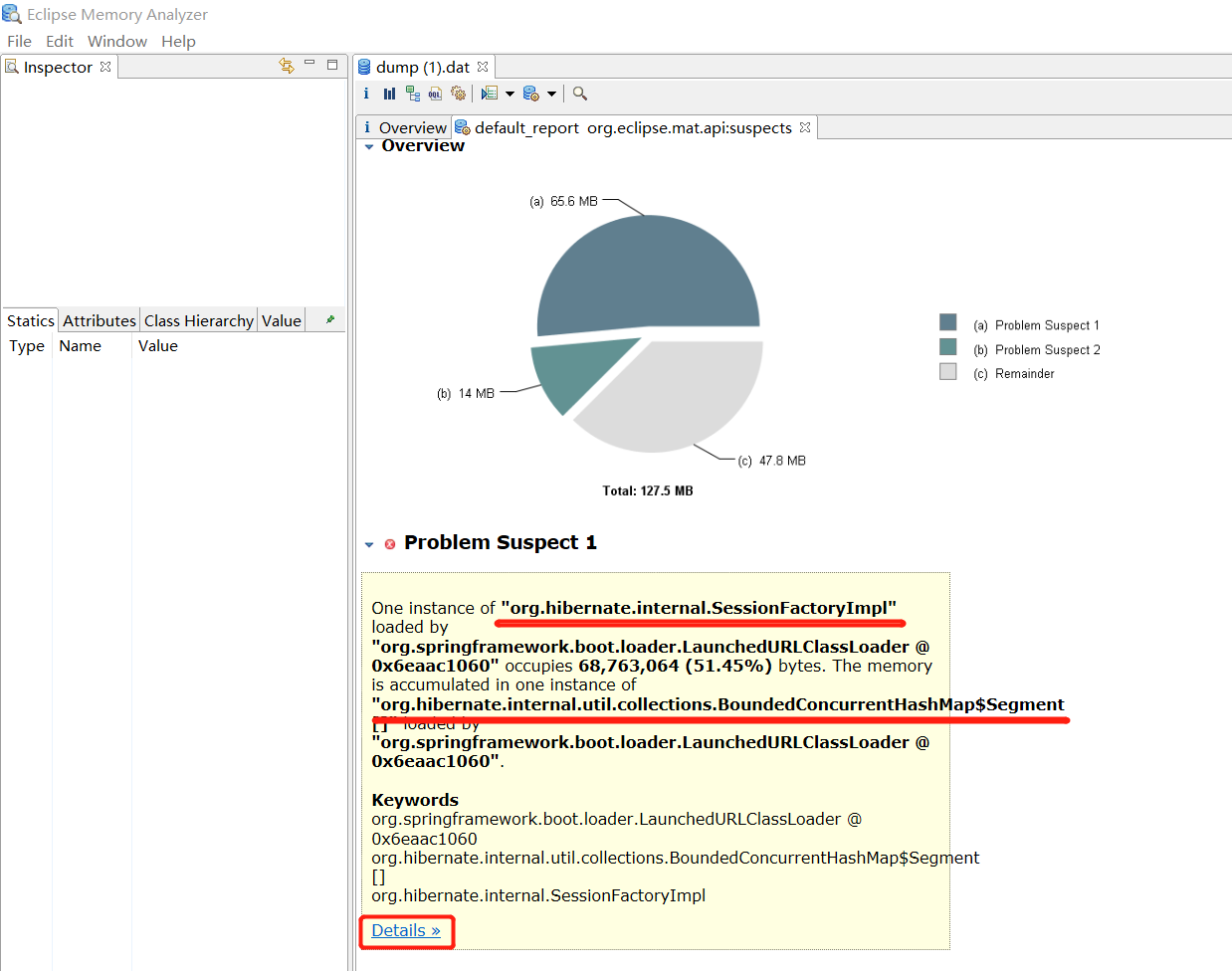
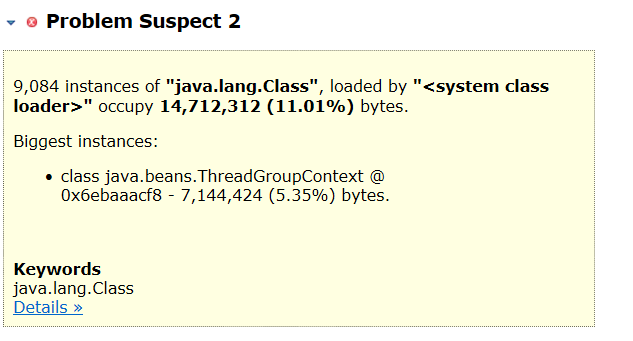
另一个是 java.beans.ThreadGroupContext 泄漏
4、点开上面问题1 的 detail 按钮,依次查看各个对象,以及对象中的值:
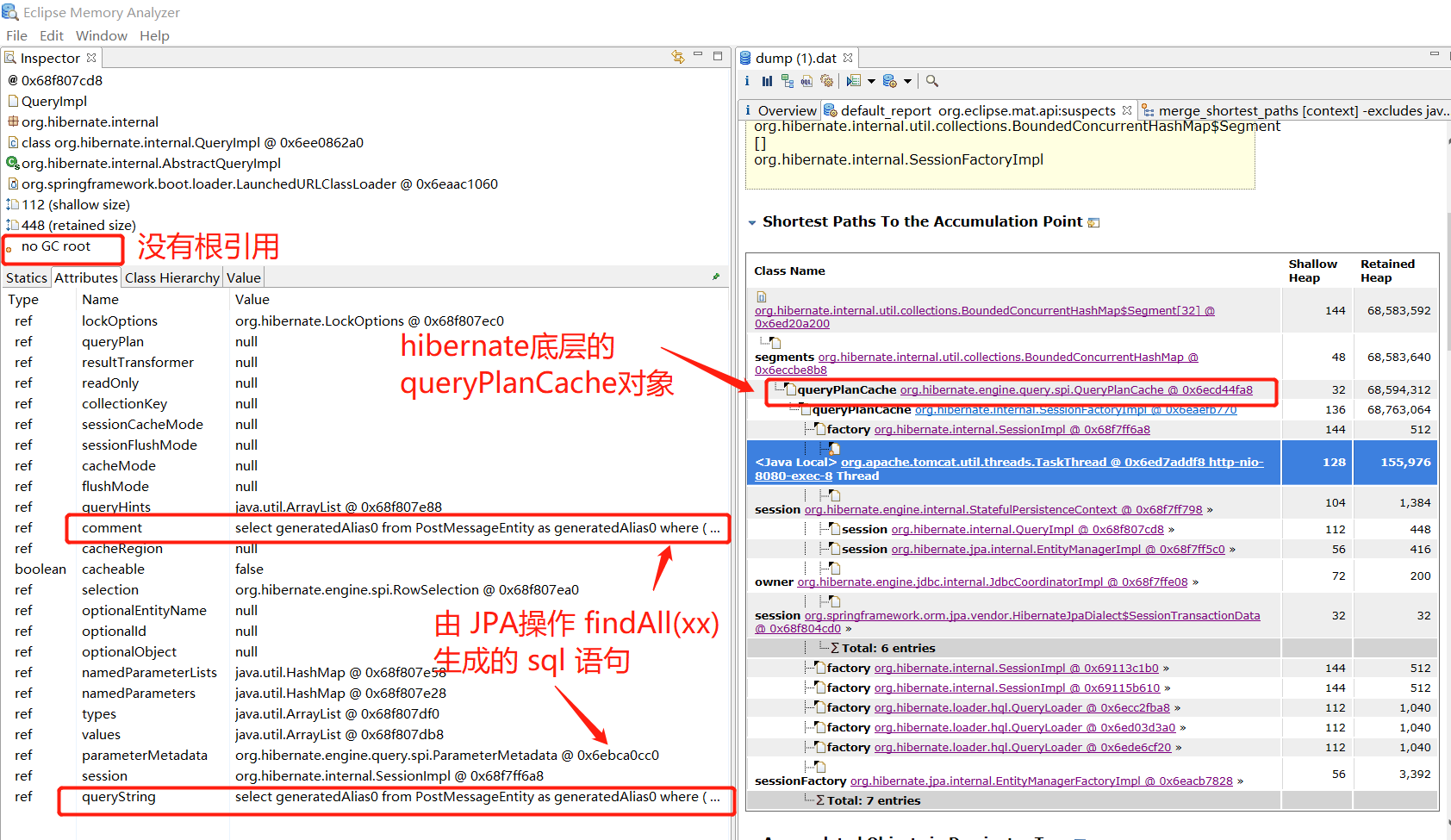
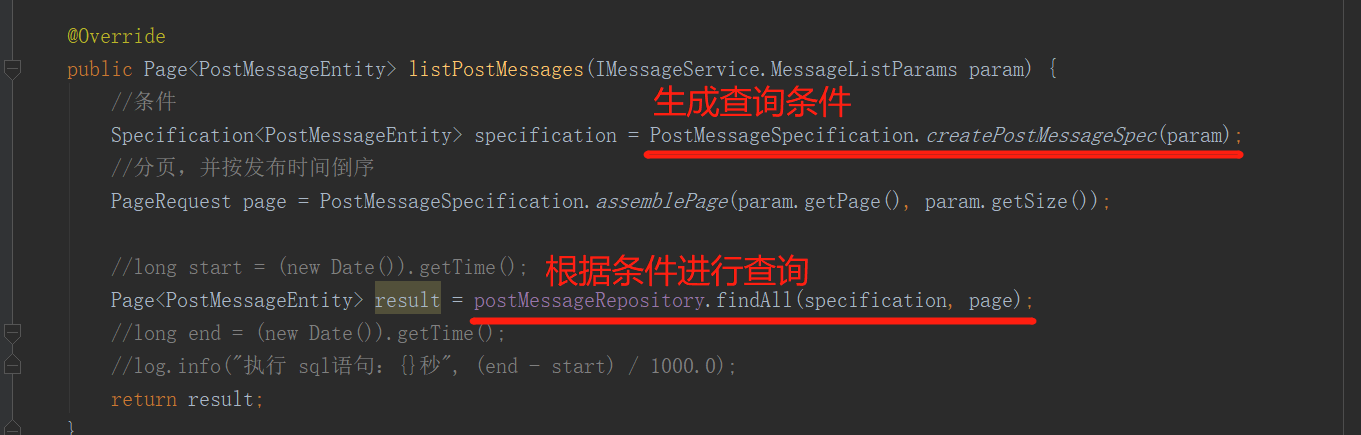
目前基本能够判断,该内存泄漏是由 jpa 中的 findAll()导致的,相关代码:
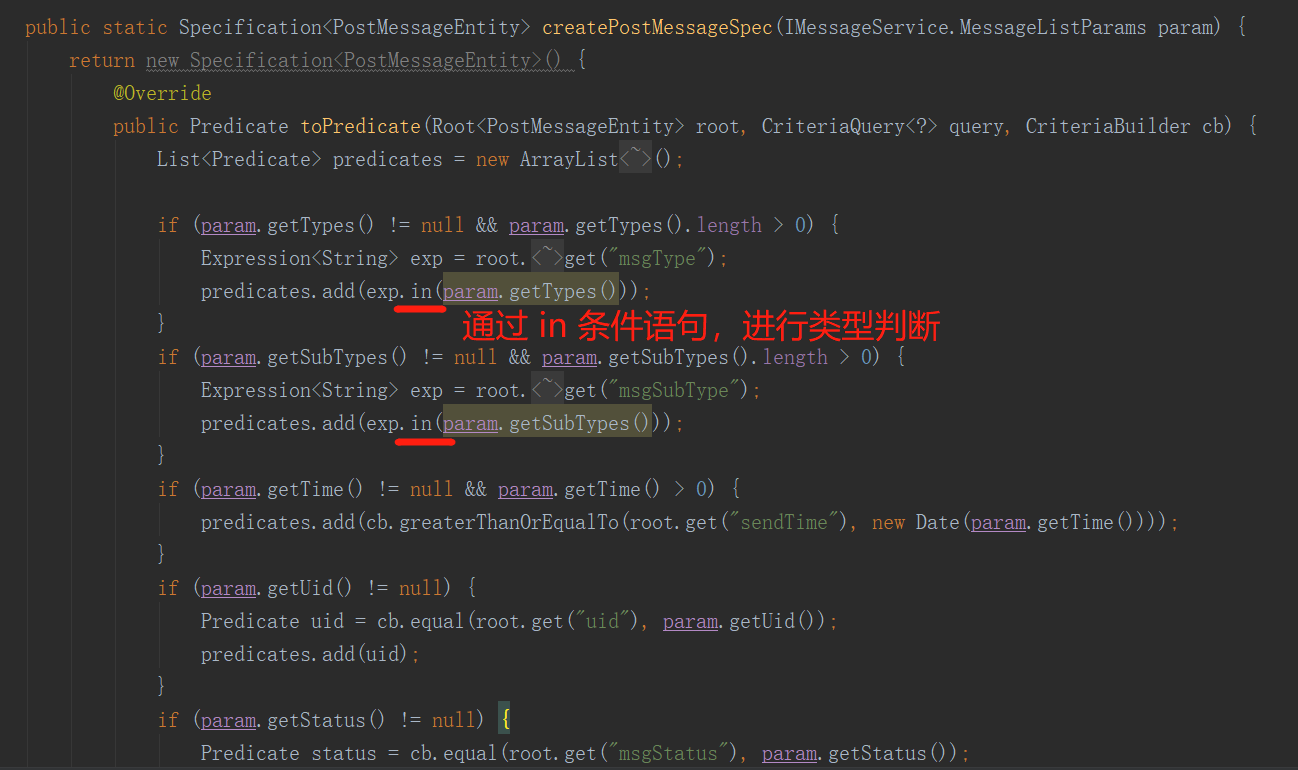
5、通过 google 搜索 JAP query plan cache 相关的泄漏问题,找到帖子:
Spring + Hibernate Query Plan Cache Memory usage:https://stackoverflow.com/questions/31557076/spring-hibernate-query-plan-cache-memory-usage
大致意思是:
基本上归结为在IN子句中具有可变数量的值,而Hibernate试图缓存这些查询计划:
Hibernate缓存这些解析的HQL查询。具体来说,Hibernate SessionFactoryImpl包含带有queryPlanCache和parameterMetadataCache的QueryPlanCache。
但是当插入子句的参数数量很大并且变化时,这被证明是一个问题。hibernate.query.plan_cache_max_size,默认为2048(对于具有许多参数的查询而言,这个属性太大)。
由于hibernate中存在一些模糊的错误,有些情况下参数未正确处理并被呈现到JPQL查询中(作为示例,请查看HHH-6280)。如果您的查询受到此类缺陷的影响并且以高速执行,
则会破坏您的查询计划缓存,因为生成的每个JPQL查询几乎都是唯一的(例如,包含您的实体的ID)
6、根据上面帖子的建议,将缓存计划的值改小:
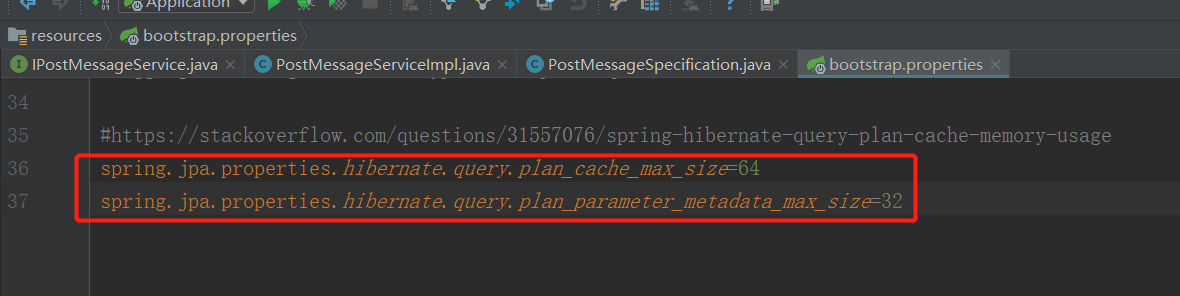 、
、
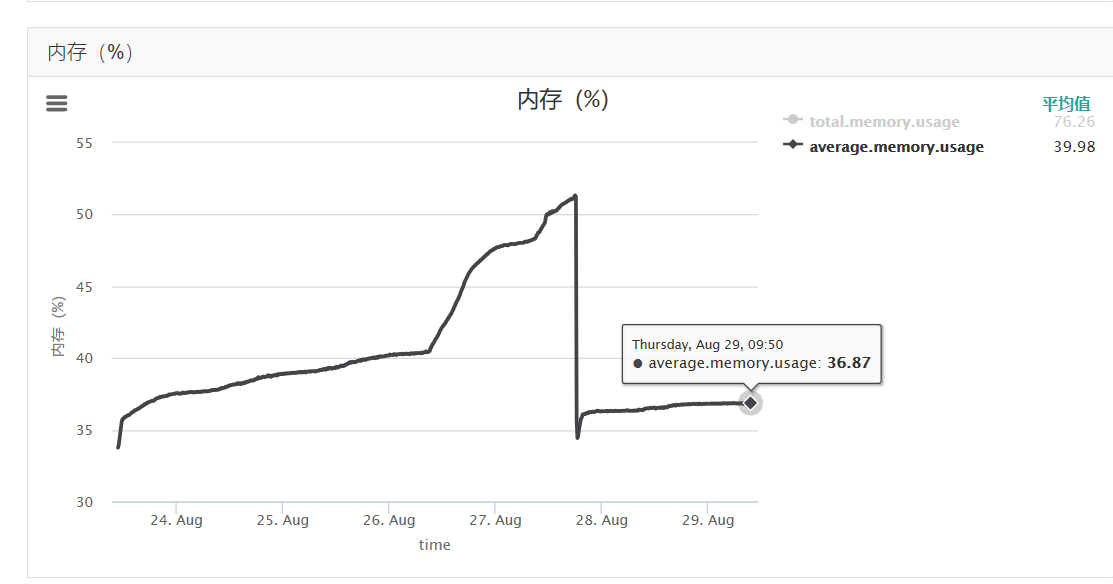
7、上线后,重启应用,经过一段时间运行,基本维持在 36%:
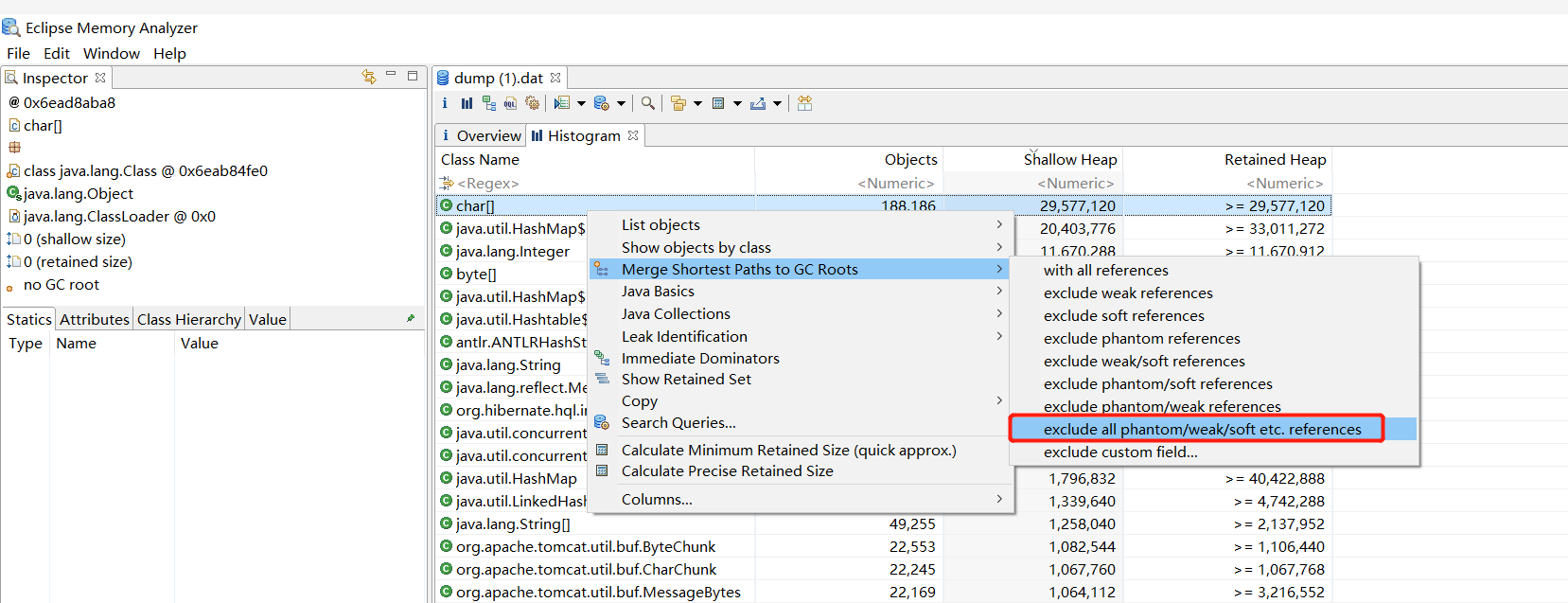
8、另外,可以通过直方图(Histogram)查看内存中的主要内存对象:
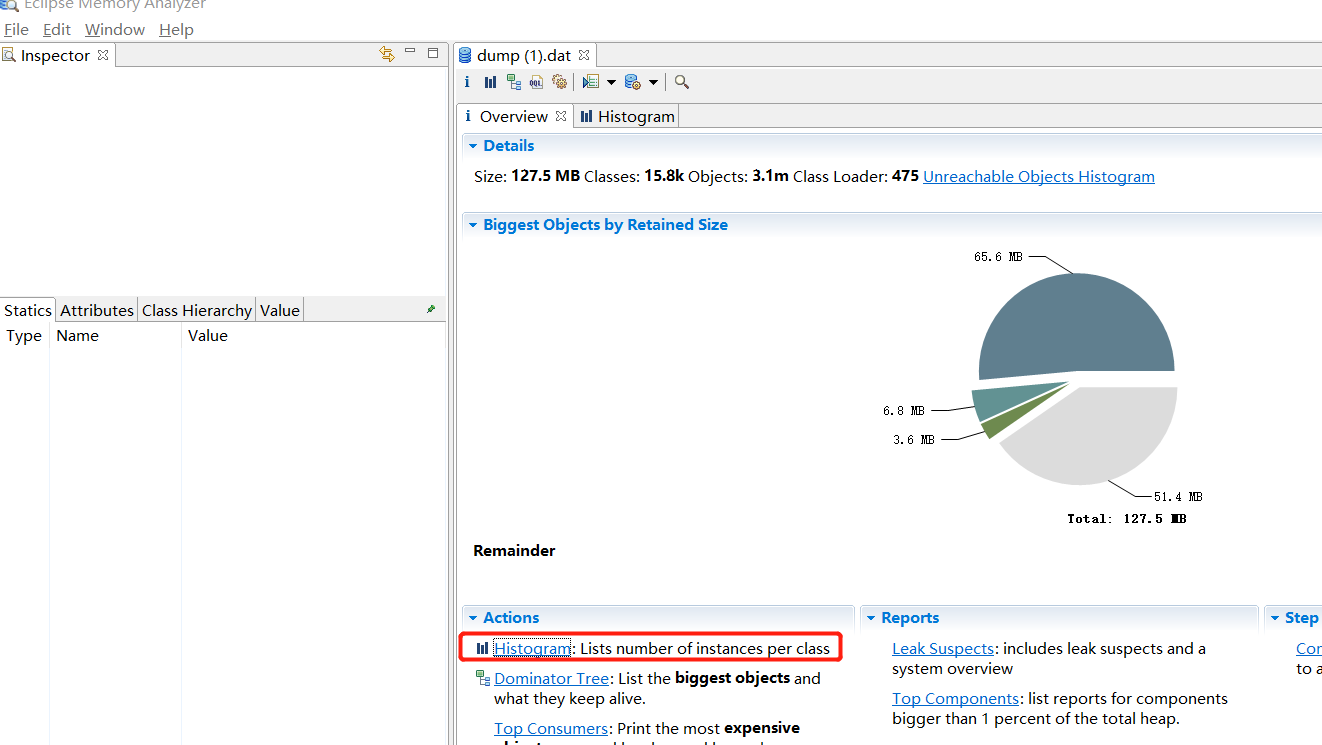
排除掉虚引用、弱引用、软引用:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号