实验1-波士顿房价预测
1
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
# from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
# from sklearn.externals import joblib
import joblib
from sklearn.metrics import r2_score
from sklearn.neural_network import MLPRegressor
import pandas as pd
import numpy as np
# lb = load_boston()
# x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.2)
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 为数据增加一个维度,相当于把[1, 5, 10] 变成 [[1, 5, 10],]
y_train = y_train.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)
# 进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
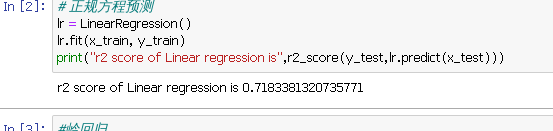
# 正规方程预测
lr = LinearRegression()
lr.fit(x_train, y_train)
print("r2 score of Linear regression is",r2_score(y_test,lr.predict(x_test)))
2
from sklearn.linear_model import RidgeCV
cv = RidgeCV(alphas=np.logspace(-3, 2, 100))
cv.fit (x_train , y_train)
print("r2 score of Linear regression is",r2_score(y_test,cv.predict(x_test)))

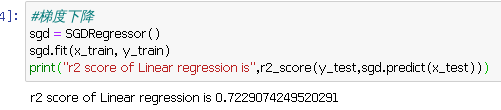
3
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print("r2 score of Linear regression is",r2_score(y_test,sgd.predict(x_test)))
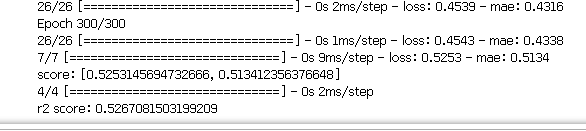
4
from keras.models import Sequential
from keras.layers import Dense
seq = Sequential()
seq.add(Dense(64, activation='relu'))
seq.add(Dense(64, activation='relu'))
seq.add(Dense(1, activation='relu'))
seq.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
seq.fit(x_train, y_train, epochs=300, batch_size = 16, shuffle = False)
score = seq.evaluate(x_test, y_test,batch_size=16)
print("score:",score)
print('r2 score:',r2_score(y_test, seq.predict(x_test)))



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
2023-04-25 python实验笔记1