
通过groupby将数据分组后提取出来
groupby真是个好东西
参考:
python数据分析之Dataframe分组(group by)_dataframe groupby-CSDN博客
【Python】进阶学习:pandas--groupby()用法详解_pandas groupby函数-CSDN博客
get_group
pandas中groupby取出某一组的方法_pandasgroupby分组后 取出分组-CSDN博客
Python 在Python中检查是否(不)在列表中|极客教程 (geek-docs.com)
Python数据可视化的例子——饼图(pie)_python中pie是什么意思-CSDN博客
问题描述:
提取csv文件中的省市、标准行业字段后,将他们分组,要求知道每个省的某一标准行业字段的数量(问题在于提取)。
import matplotlib.pyplot as plt import pandas as pd plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 显示中文标签,处理中文乱码问题 plt.rcParams['axes.unicode_minus'] = False # 坐标轴负号的处理 plt.axes(aspect='equal') # 将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆 df = pd.read_csv("result_add.csv", encoding='utf-8') df3 = df[['省市', '行业标准字段']] df3_gb = df3.groupby(['省市', '行业标准字段']).value_counts() pro = [] name_num = [] # 行业名称以及数量 num = [] for i in range(len(df3_gb)): if df3_gb.index[i][0] not in pro: if len(num) != 0 : name_num.append(num) pro.append(df3_gb.index[i][0]) num = [[df3_gb.index[i][1], int(df3_gb.values[i])]] else: num.append([df3_gb.index[i][1], int(df3_gb.values[i])]) name_num.append(num) print(pro) for i in range(len(name_num)): print(name_num[i])
结果如下:

那如果我想变成这个样子的格式呢:

将代码修改一下即可
pro2=[] min_name=[] min_num=[] name_num2=[] for i in range(len(df3_gb)): if df3_gb.index[i][0] not in pro2: if len(min_name) != 0 and len(min_num) !=0 : name_num2.append([min_name, min_num]) pro2.append(df3_gb.index[i][0]) min_name=[df3_gb.index[i][1]] min_num=[df3_gb.values[i]] else: min_name.append(df3_gb.index[i][1]) min_num.append(df3_gb.values[i]) name_num2.append([min_name, min_num]) print(pro2) for i in range(len(name_num2)): print(name_num2[i])
ok,有数据后就可以可视化一下了。额 。毁灭吧。什么时候bz
测试代码如下:
plt.pie(x=name_num2[2][1], #绘图数据edu # explode=explode, #指定饼图某些部分的突出显示,即呈现爆炸式 labels=name_num2[2][0], #添加教育水平标签 # colors=colors, autopct='%.2f%%', #设置百分比的格式,这里保留两位小数 pctdistance=0.8, #设置百分比标签与圆心的距离 labeldistance=1.1, #设置教育水平标签与圆心的距离 startangle=180, #设置饼图的初始角度 radius=1.2, #设置饼图的半径 counterclock=False, #是否逆时针,这里设置为顺时针方向 wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, #设置饼图内外边界的属性值 textprops={'fontsize':10, 'color':'black'}, #设置文本标签的属性值 ) #添加图标题 plt.title('河北省项目比例') #显示图形 plt.show()
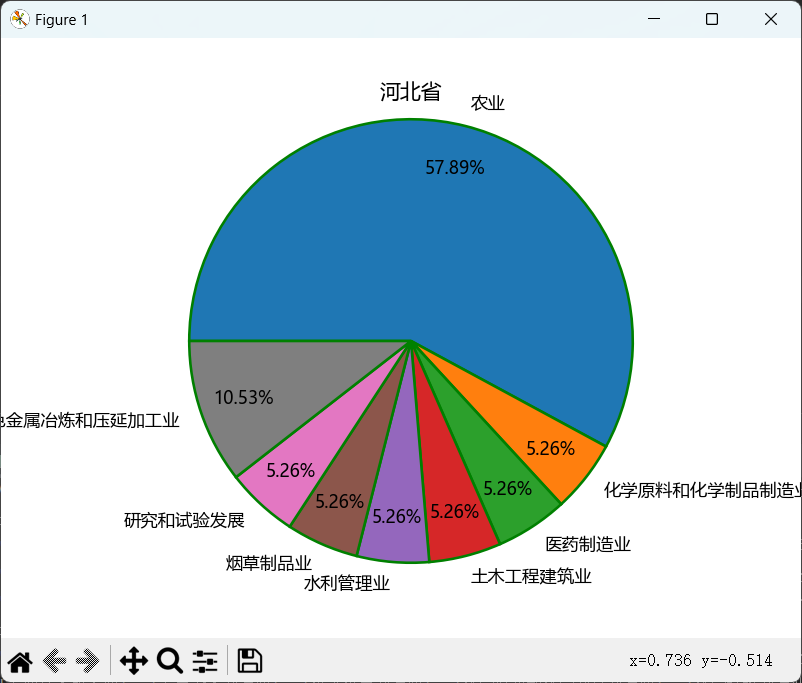
当然这是测试指定某一条数据的,那我们需要遍历pro2里面的省份然后画出该省份的比例呢:
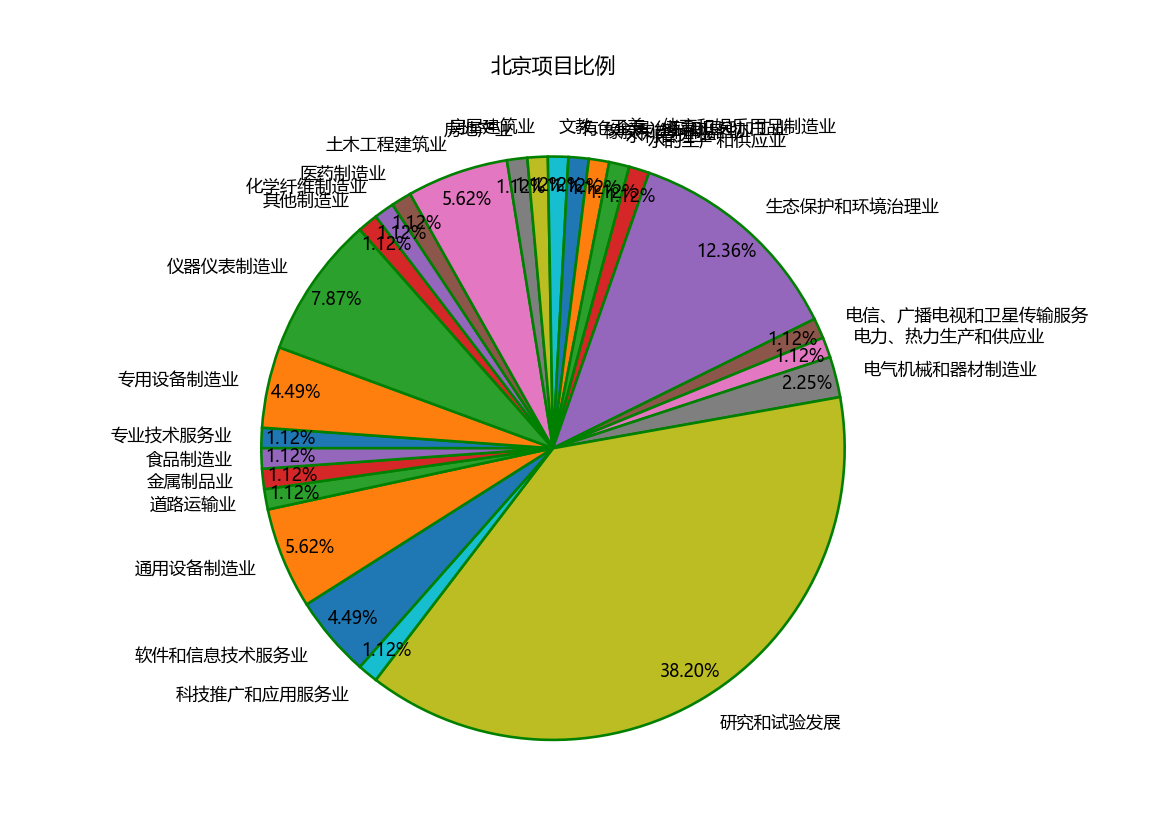
def plot_pie(data1,data2,title): plt.pie(x=data1, #绘图数据 labels=data2, #添加水平标签 autopct='%.2f%%', #设置百分比的格式,这里保留两位小数 pctdistance=0.9, #设置百分比标签与圆心的距离 labeldistance=1.1, #设置教育水平标签与圆心的距离 startangle=180, #设置饼图的初始角度 radius=1, #设置饼图的半径 counterclock=False, #是否逆时针,这里设置为顺时针方向 wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, #设置饼图内外边界的属性值 textprops={'fontsize':10, 'color':'black'}, #设置文本标签的属性值 ) plt.title(title) plt.show() for i in range(len(pro2)): title=""+pro2[i]+"项目比例" plot_pie(name_num2[i][1],name_num2[i][0],title)
不过当数据比较多的时候标签会重合就不美观了,需要的自己修改一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号