
Hive学习3(数据库操作DML、join、hive函数)
1.对数据库操作
1.1创建数据库
create database 库名字;
可以在webui查看在/user/hive/warehouse/目录下
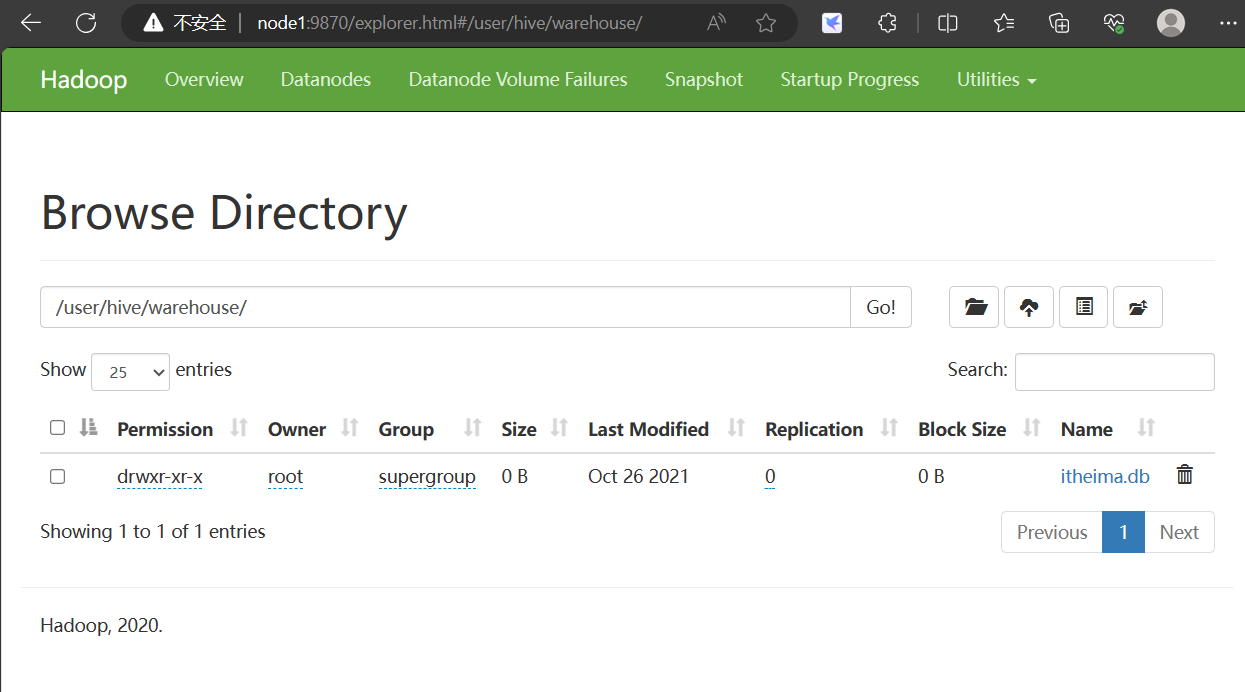
1.2切换到指定的数据库进行操作
到哪个数据库中,则所有操作默认都在这个数据库中进行。
use 库名;
1.3删除数据库
前提要求:该数据库中没有表,即该数据库为空。
drop database 库名;
2.导入数据
2.1创建表导入数据
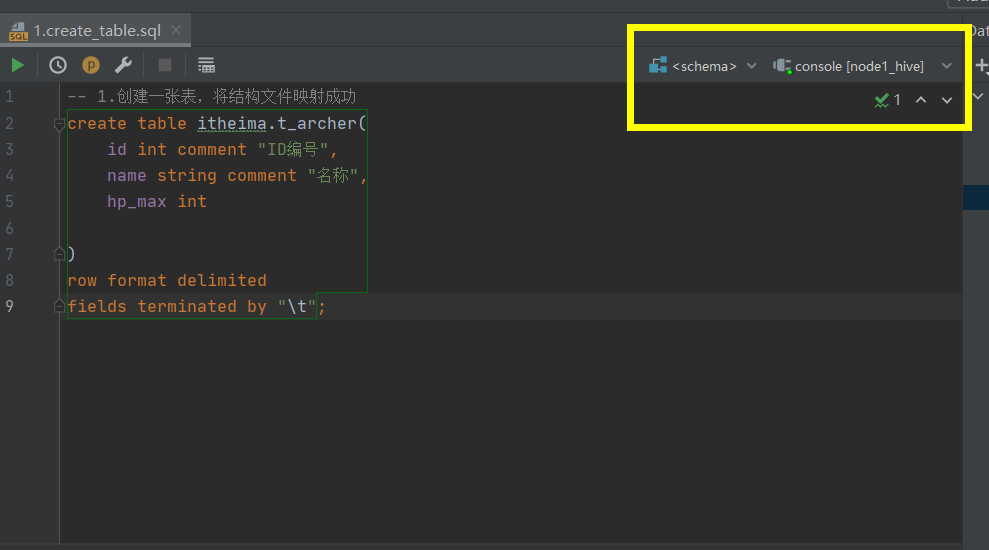
先创建表,注意session选择的地方,点击执行在itheima下面创建一张表
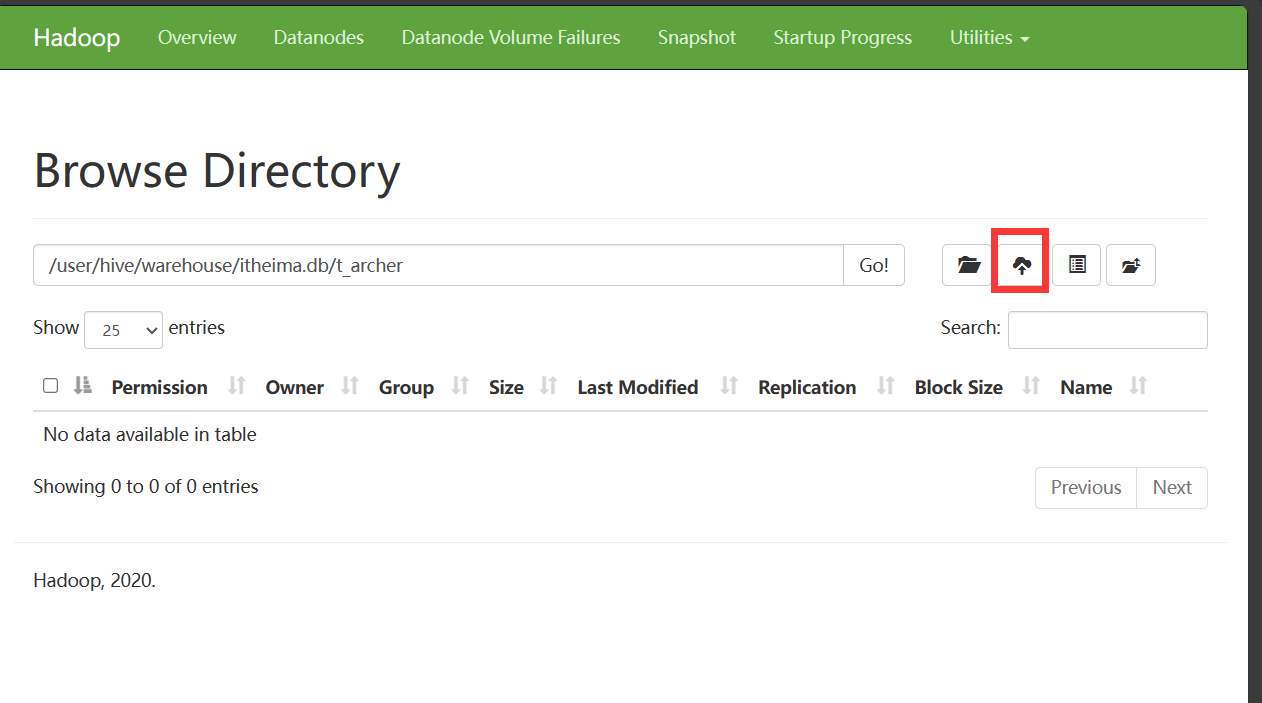
在webui页面,可以进行暴力上传文件,注意:一定要进入到表里面上传文件
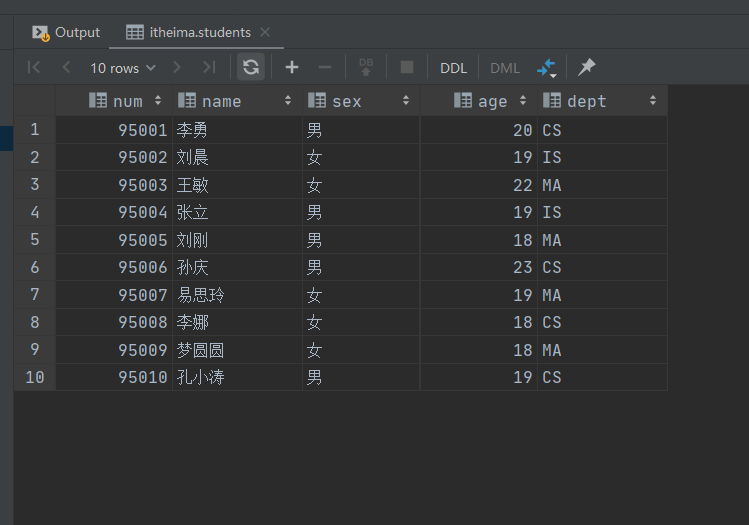
查询看是否成功
select * from 表名 limit 10;
2.2分隔符
上面的例子中,分隔符是\t,如果不写默认是\001
3.show语法
show databases;
show tables;
show tables in itheima;-- 显示itheima库下面的表
desc formatted 表名字; -- 显示表的信息
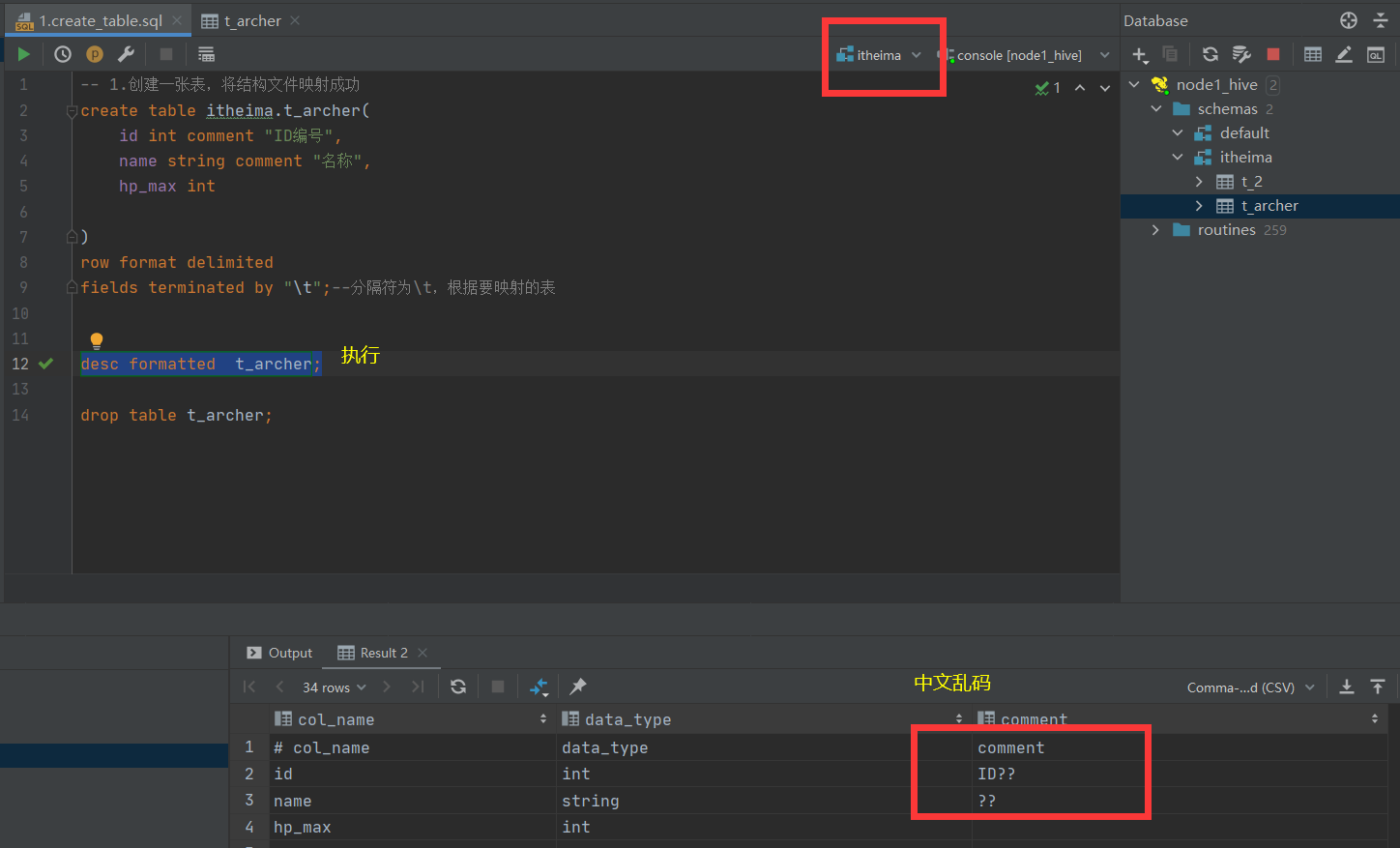
4.处理中文乱码问题
要在mysql中进行配置
现在node1上输入命令:mysql -u root -p
黑马配置好的sql密码为hadoop
切换到hive3
执行下面的语句
alter table hive3.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8; alter table hive3.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8; alter table hive3.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ; alter table hive3.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8; alter table hive3.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
执行完成后:ctrl+d结束
我们这个时候去查看还是乱码,原因是之前的表已经写死了,所以需要删除表再创建这时候就没有乱码了。
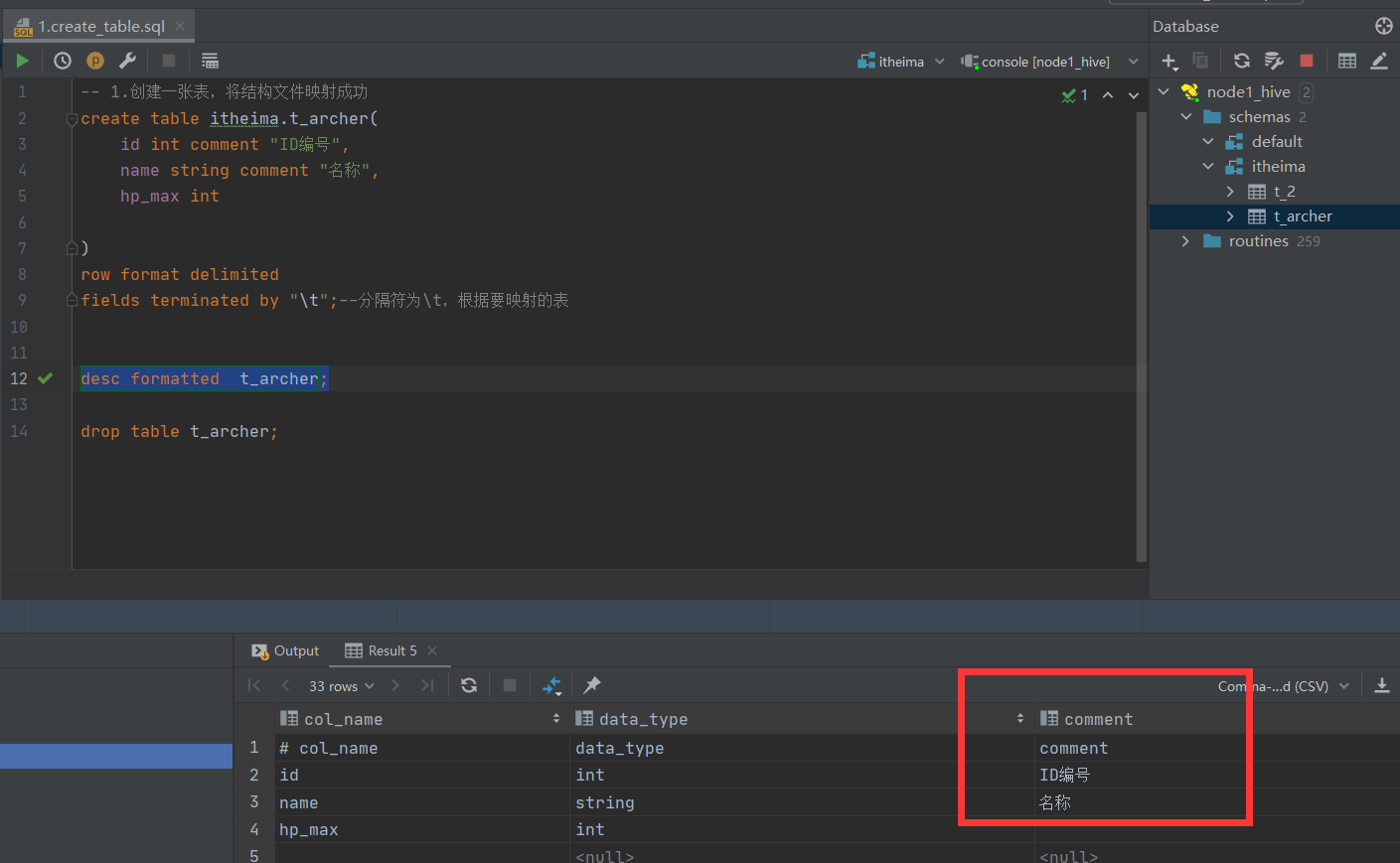
删除后再创建表执行查询:
5.SQL-DML
5.1Load加载
hive服务所在的本地
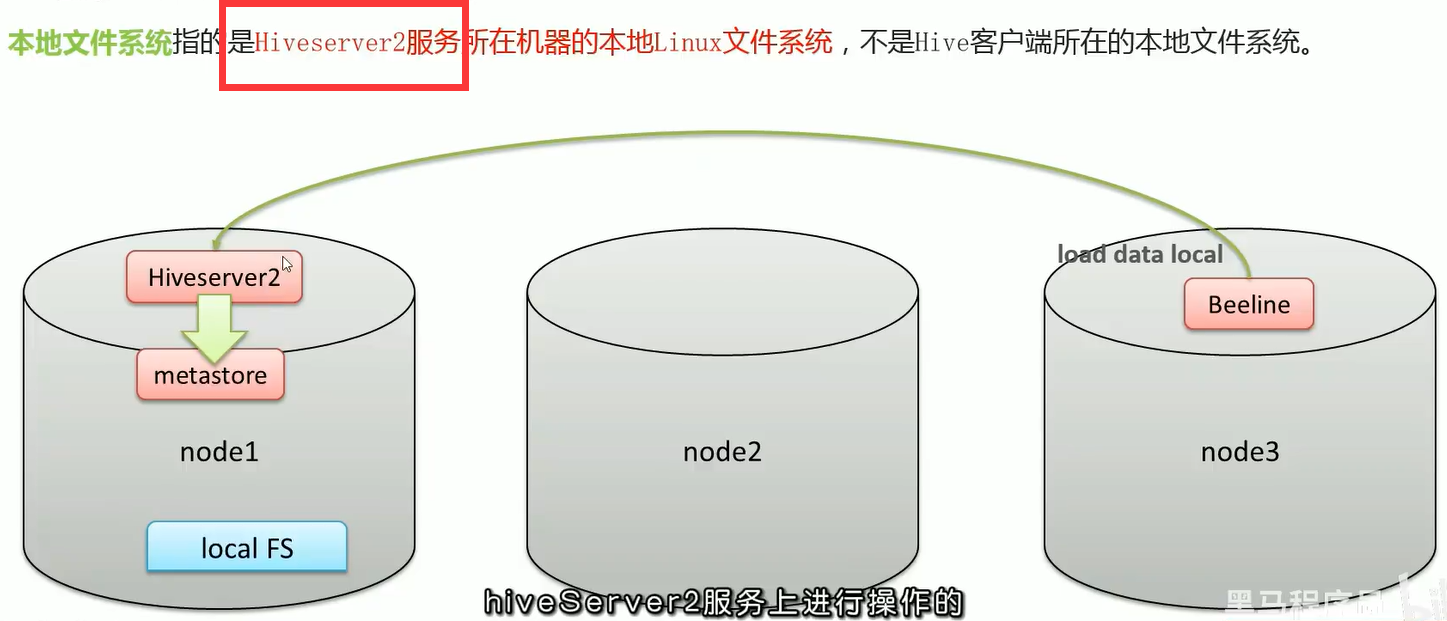
02-Hive SQL-DML-Load加载数据操作_哔哩哔哩_bilibili
5.2insert插入
1.一条条数据上传不推荐使用,慢。
2.通常是 insert+select 组合使用
如再原有的students表中挑出num和name,插入到新的students_insert表中
-- insert+select使用 create table students_insert(sno int,sname string); insert into table students_insert select num,name from students; -- 查看结果 select * from students_insert limit 10;
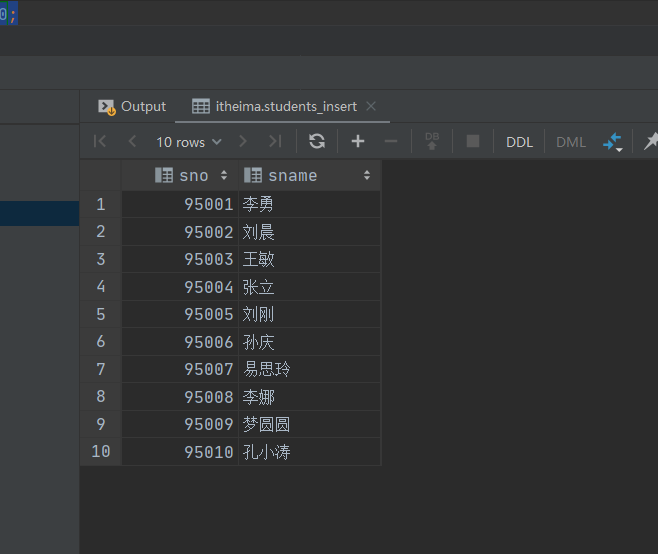
5.3select
执行顺序:from>where>group>having>order>select
5.3.1select去重,select查询数据库
-- select -- 查询students表10 条数据 select * from students limit 10; -- 查询具体的num、name字段 select name,dept from students limit 10; -- 去重 select distinct dept from students; -- 注意这样子写是整体重复会去重,就是dept和name这两个字段都重复才会去掉 -- a AAA和a AAA会被去掉,而a AAA和a BBB不会被认为是重复 select distinct dept,name from students; -- 查询当前的数据库名称 select current_database();
5.3.2select---where
-- select where select * from students where sex = '女'; -- 可以指定长度:例查询name中长度大于3的信息 select * from students where length(name) > 3; select * from students where age >=19 and age <=23; select * from students where age in(18,19,20);
5.3.3select聚合
在where中不可以直接用聚合,可以先用having+聚合获得结果
-- 聚合函数,再where中不可以使用 --AVG、COUNT(column):不包括NULL、COUNT(*)、MAX、MIN、SUM select count(num) as student_num from students; -- 去重 select count(distinct num) as student_num from students; -- SUM和COUNT select sum(age) as total_age from students;
5.3.4GROUP BY
通常和聚合函数一起使用
-- GROUP BY -- 根据院系分组,统计院系为MA有多少个学生 select count(num) from students where dept = "MA" group by dept; select dept, count(num) from students where dept = "MA" group by dept;
5.3.5Having
--having -- 找出院系人数大于6人,列出院系和人数 select dept,count(num) as total_student from students group by dept having total_student > 6 ;
5.3.6order by
默认是升序
-- order by --默认升序asc select * from students order by age; --规定降序 select * from students order by age desc,num asc ;
5.3.7limit
这里需要注意的是行偏移量
-- limit -- 注意:行是从0开始,从第二行开始读取三行 select * from students; select * from students limit 2,3;
6.JOIN
13-Hive SQL Join关联查询_哔哩哔哩_bilibili
7.hive函数
hive内置函数:
-- hive内置函数
show functions; -- 查看函数
-- 查看函数使用方法
describe function extended 函数名字
官方文档:LanguageManual UDF - Apache Hive - Apache Software Foundation
------------String Functions 字符串函数------------ select length("itcast"); select reverse("itcast"); select concat("angela","baby"); --带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+) select concat_ws('.', 'www', array('itcast', 'cn')); --字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len]) select substr("angelababy",-2); --pos是从1开始的索引,如果为负数则倒着数 select substr("angelababy",2,2); --分割字符串函数: split(str, regex) --split针对字符串数据进行切割 返回是数组array 可以通过数组的下标取内部的元素 注意下标从0开始的 select split('apache hive', ' '); select split('apache hive', ' ')[0]; select split('apache hive', ' ')[1]; ----------- Date Functions 日期函数 ----------------- --获取当前日期: current_date select current_date(); --获取当前UNIX时间戳函数: unix_timestamp select unix_timestamp(); --日期转UNIX时间戳函数: unix_timestamp select unix_timestamp("2011-12-07 13:01:03"); --指定格式日期转UNIX时间戳函数: unix_timestamp select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss'); --UNIX时间戳转日期函数: from_unixtime select from_unixtime(1618238391); select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss'); --日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd' select datediff('2012-12-08','2012-05-09'); --日期增加函数: date_add select date_add('2012-02-28',10); --日期减少函数: date_sub select date_sub('2012-01-1',10); ----Mathematical Functions 数学函数------------- --取整函数: round 返回double类型的整数值部分 (遵循四舍五入) select round(3.1415926); --指定精度取整函数: round(double a, int d) 返回指定精度d的double类型 select round(3.1415926,4); --取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数 select rand(); --指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列 select rand(3); -----Conditional Functions 条件函数------------------ --使用之前课程创建好的student表数据 select * from student limit 3; --if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull) select if(1=2,100,200); select if(sex ='男','M','W') from student limit 3; --空值转换函数: nvl(T value, T default_value) select nvl("allen","itcast"); select nvl(null,"itcast"); --条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end; select case sex when '男' then 'male' else 'female' end from student limit 3;

