HBase学习11(项目01分析及准备)
海量数据
1.准备
在idea中创建项目,然后创建脚本包hbase_shell。
添加文件说明readme.md,写入相关项目结构说明。
通过复制hbase_shell文件目录,在VSCode中打开进行对脚本文件的编写。
在VSCode中编写方便。
2.创建名称空间namespace
当表的数量比较多的时候,为了方便管理,不同的业务域以名称空间(namespace)来划分。
启动hbase shell
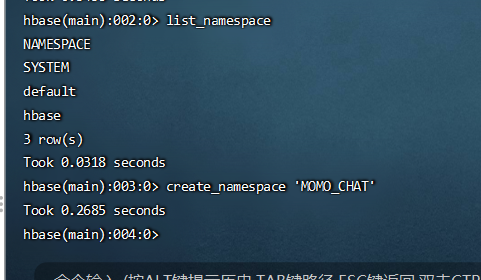
命名空间的基本操作:
# 创建命名空间 create_namespace 'MOMO_CHAT' # 查看命名空间 list_namespace # 删除命名空间,注意删除前该命名空间必须是空的,无表 drop_namespace 'XX' # 查看某个具体的命名空间 describe_namespace 'MOMO_CHAT'
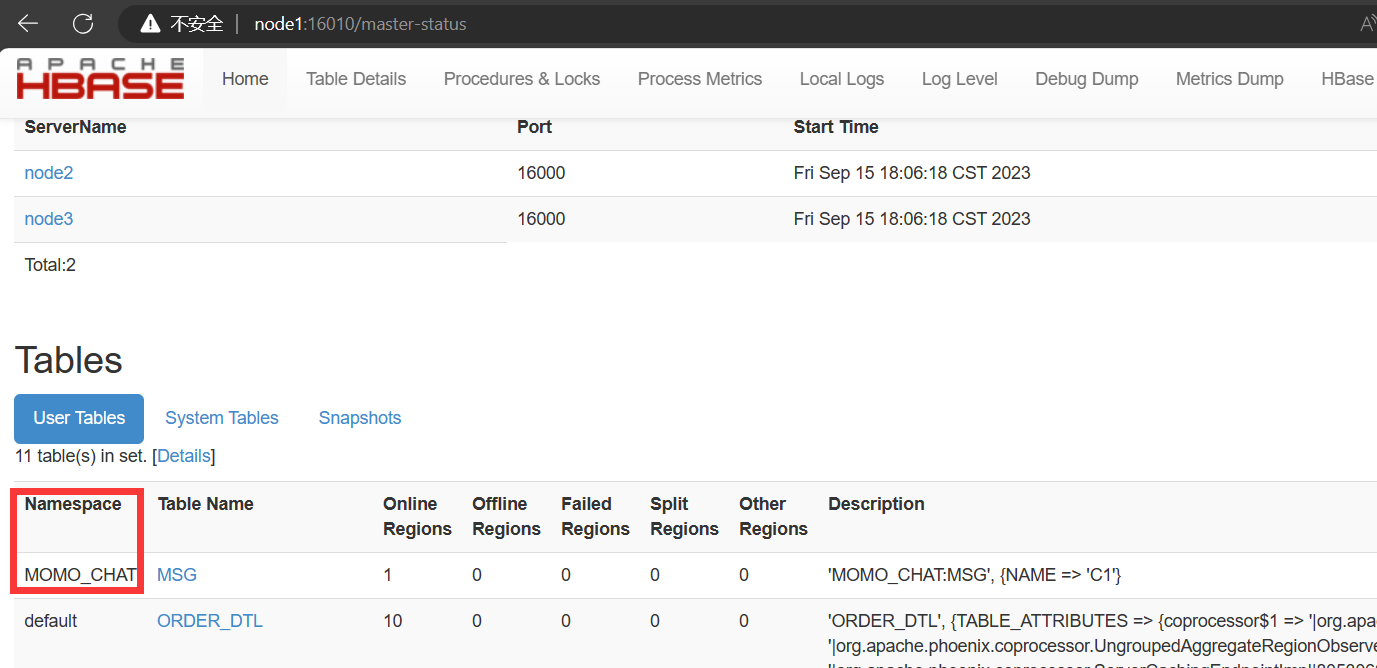
在指定命名空间中创建表,不指定命名空间会自动在default命名空间中创建表。
# 在MOMO_CHAT命名空间下创建表MSG create "MOMO_CHAT:MSG","C1"
3.注意事项
列簇越少越好,不然对hbase性能有影响。
GZIP的压缩率最高,但是其实CPU密集型的,对CPU的消耗比其他算法要多,压缩和解压速度也慢;
LZO的压缩率居中,比GZIP要低一些,但是压缩和解压速度明显要比GZIP快很多,其中解压速度快的更多;
Zippy/Snappy的压缩率最低,而压缩和解压速度要稍微比LZO要快一些
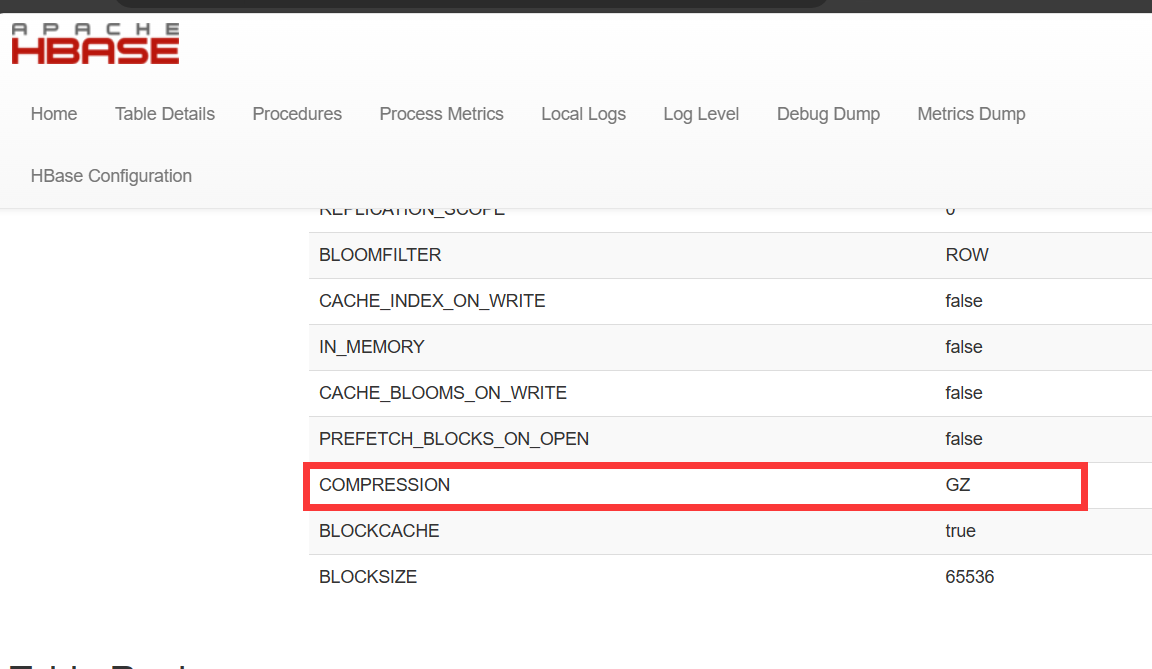
4.设置数据压缩
hbase shell
# 设置数据压缩 # 表创建的时候指定压缩方式 create "MOMO_CHAT:MSG", {NAME => "C1", COMPRESSION => "GZ"} # 指定修改某个表的列簇的压缩方式 alter "MOMO_CHAT:MSG",{NAME => "C1", COMPRESSION => "GZ"}
5.ROWKEY
注意事项:
1.避免使用递增行键/时序数据
如果ROWKEY设计的都是按照顺序递增(例如:时间戳),这样会有很多的数据写入时,负载都在一台机器上。我们尽量应当将写入大压力均衡到各个RegionServer。
2. 避免ROWKEY和列的长度过大
在HBase中,要访问一个Cell(单元格),需要有ROWKEY、列族、列名,如果ROWKEY、列名太大,就会占用较大内存空间。所以ROWKEY和列的长度应该尽量短小。ROWKEY的最大长度是64KB,建议越短越好
3.使用long等类型比String类型更省空间
long类型为8个字节,8个字节可以保存非常大的无符号整数,例如:18446744073709551615。如果是字符串,是按照一个字节一个字符方式保存,需要快3倍的字节数存储。
4.ROWKEY唯一性
由于在HBase中数据存储是Key-Value形式,若向HBase中同一张表插入相同RowKey的数据,则原先存在的数据会被新的数据覆盖。
6.预分区P24
可以避免数据热点
热点是指大量的客户端(client)直接访问集群的一个或者几个节点(可能是读、也可能是写)
大量地访问量可能会使得某个服务器节点超出承受能力,导致整个RegionServer的性能下降,其他的Region也会受影响
hbase设置预分区:
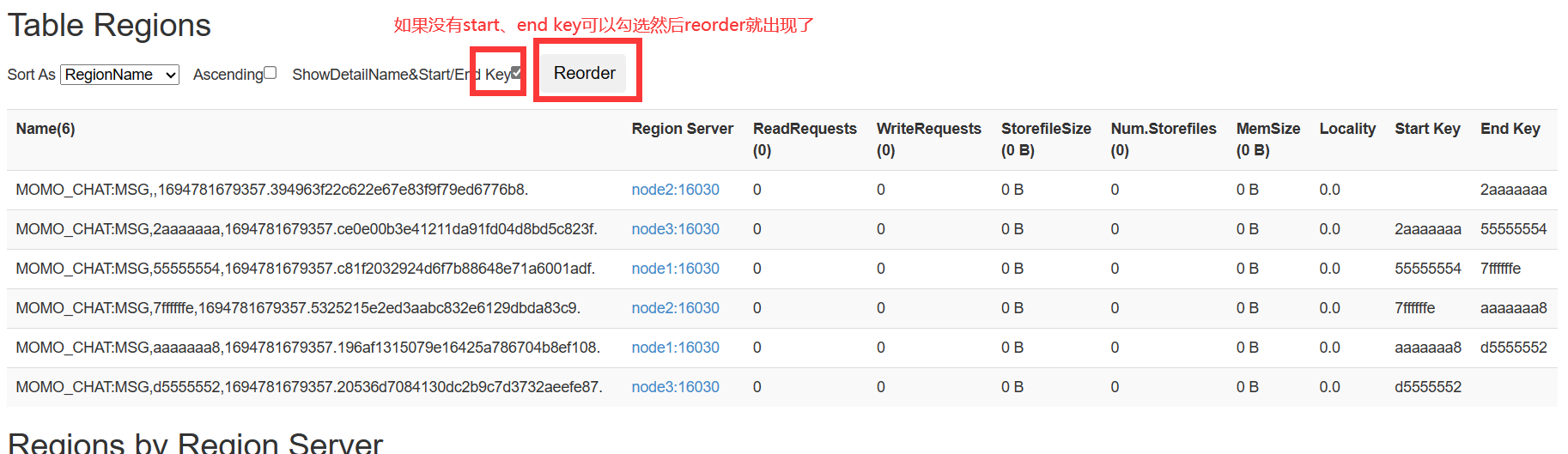
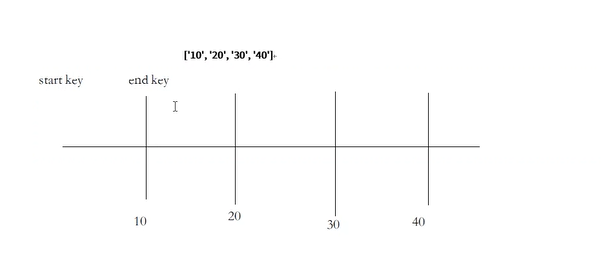
1指定 start key、end key来分区
# 预分区 # 1.指定 start key、end key来分区 hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']
划分出来五个区:
2.指定分区数量、分区策略
# 2.指定分区数量、分区策略 hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} # HexStringSplit: ROWKEY是十六进制的字符串作为前缀的 # DecimalStringSplit: ROWKEY是10进制数字字符串作为前缀的 # UniformSplit: ROWKEY前缀完全随机
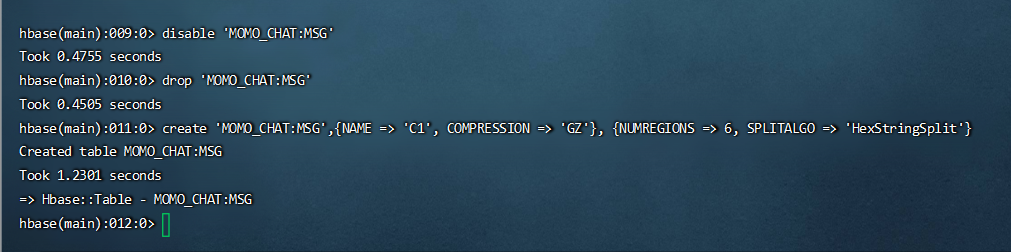
了解上面的知识后,我们要在建表的时候就要指定预分区,所以我们先把表删掉,再重新建立
注意,删除表分两步: 先 disable "MOMO_CHAT:MSG" ,后 drop "MOMO_CHAT:MSG"
然后建表:
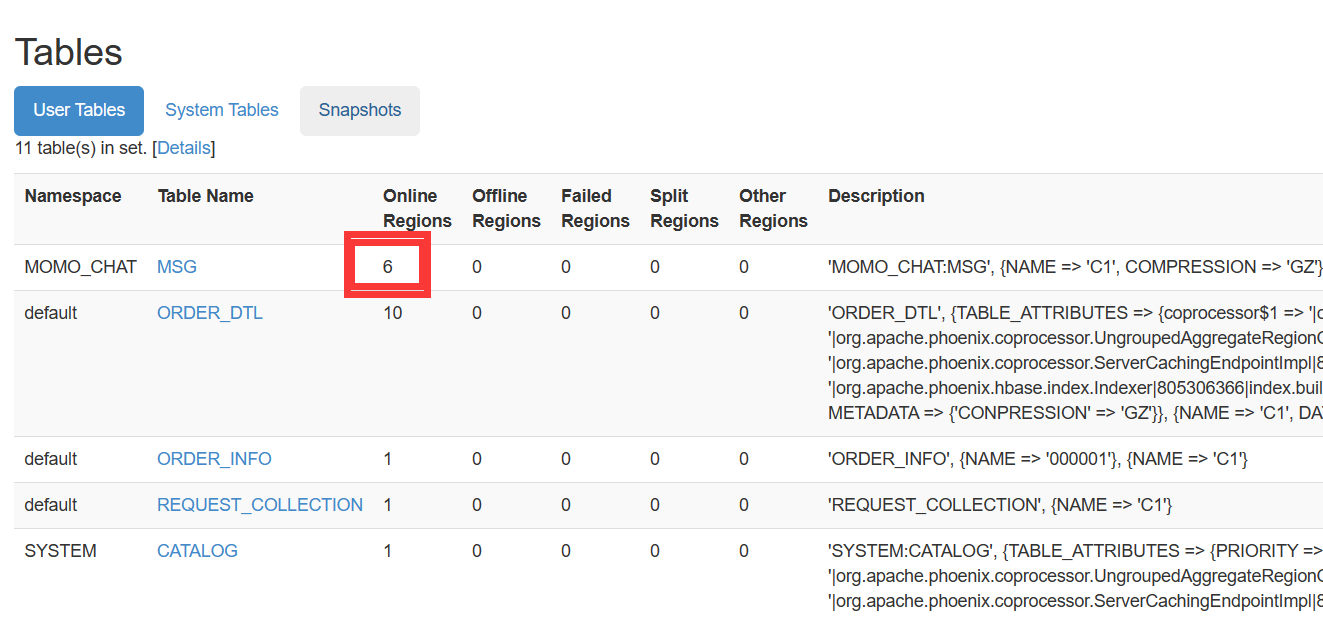
create 'MOMO_CHAT:MSG',{NAME => 'C1', COMPRESSION => 'GZ'}, {NUMREGIONS => 6, SPLITALGO => 'HexStringSplit'}