
Kafka 在华泰证券的探索与实践
引言
Apache Kafka 发源于 LinkedIn,于 2011 年成为 Apache 的孵化项目,随后于 2012 年成为 Apache 的顶级项目之一。按照官方定义,Kafka 是一个分布式流平台,具备流数据的发布及订阅(与消息队列或企业级消息系统类似)能力、容错方式的流数据存储能力以及流数据的实时处理能力。Kafka 的优势在于:
-
可靠性:具有分区机制、副本机制和容错机制的分布式消息系统。
-
可扩展性:消息系统支持集群规模的热扩展。
-
高性能:在数据发布和订阅过程中都能保证数据的高吞吐量。即便在 TB 级数据存储的情况下,仍然能保证稳定的性能。
目前,Kafka 在互联网、金融、传统行业等各种类型公司内部广泛使用,已成为全球范围内实时数据传输和处理领域的事实标准。
基本原理及概念
一个典型的 Kafka 集群中包含:(1)若干 Producer,用于生产数据;(2)若干 Broker,构成集群吞吐数据;(3)若干 Consumer 消费数据;(4)一个 Zookeeper 集群,进行全局控制和管理。Kafka 的拓扑结构如下图所示:
图1 kafka 架构图
Kafka 通过 Zookeeper 管理集群配置、选举 leader,以及在 Consumer Group 发生变化时进行再平衡(rebalance)。Producer 使用 push 模式将消息发布到 broker,Consumer 使用 pull 模式从 broker 订阅并消费消息并更新消费的偏移量值(offset)。
基本概念:
-
Broker(代理):Kafka 集群的服务器节点称为 broker。
-
Topic(主题):在 Kafka 中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为 topic。一个主题可以有零个、一个或多个消费者去订阅写到这个主题里面的数据。
-
Partition(分区):主题中的数据分割为一个或多个 partition,分区是一个有序、不变序列的记录集合,通过不断追加形成结构化的日志。
-
Producer(生产者):数据的发布者,该角色将消息发布到 Kafka 的 topic 中。生产者负责选择哪个记录分配到指定主题的哪个分区中。
-
Consumer(消费者):从 broker 中读取数据,消费者可以消费多个 topic 中的数据。
-
Consumer Group(消费者组):每个 consumer 都属于一个特定的 group 组,一个 group 组可以包含多个 consumer,但一个组中只会有一个 consumer 消费数据。
主题和分区:
Topic 的本质就是一个目录,由一些 Partition Logs(分区日志)组成,其组织结构如下图所示。每个 Partition 中的消息都是有序的,生产的消息被不断追加到 Partition log 上,其中的每一个消息都被赋予了一个唯一的 offset 值。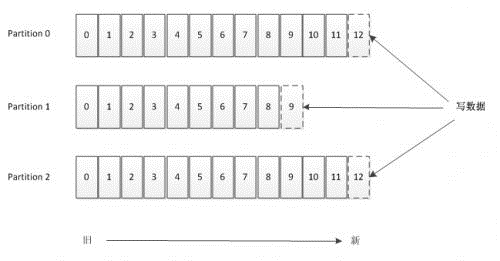
图 2 Kafka分区数据存储示意图
对于传统的 message queue 而言,一般会删除已经被消费的消息,Kafka 集群会保存所有的消息,不管消息有没有被消费。Kafka 提供两种策略删除旧数据:(1)基于时间;(2)基于 Partition 文件大小。只有过期的数据才会被自动清除以释放磁盘空间。
Kafka 需要维持的元数据只有“已消费消息在 Partition 中的 offset 值”,Consumer 每消费一个消息,offset 就会加 1。其实消息的状态完全是由 Consumer 控制的,Consumer 可以跟踪和重设这个 offset 值,这样 Consumer 就可以读取任意位置的消息。
数据备份机制:
Kafka 允许用户为每个 topic 设置副本数量,副本数量决定了有几个 broker 来存放写入的数据。如果你的副本数量设置为 3,那么一份数据就会被存放在 3 台不同的机器上,那么就允许有 2 个机器失败。一般推荐副本数量至少为 2,这样就可以保证增减、重启机器时不会影响到数据消费。如果对数据持久化有更高的要求,可以把副本数量设置为 3 或者更多。
核心api:
Producer API:允许应用去推送一个流记录到一个或多个 kafka 主题上。
Consumer API:允许应用去订阅一个或多个主题,并处理流数据。Consumer API 包含 high level API 和 Sample api 两套。使用 high level API 时,同一 Topic 的一条消息只能被同一个 Consumer Group 内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息。与之相对的 Sampleapi 是一个底层的 API,完全无状态的,每次请求都需要指定 offset 值。
Streams API:允许应用作为一个流处理器,消费来自一个或多个主题的输入流,或生产一个输出流到一个或多个输出主题,并可以有效地将输入流转换为输出流。
其它 Kafka 的特性将在下面华泰证券的使用示例中进一步介绍。
Kafka在华泰证券背景介绍及建设现状
长期以来,华泰证券的系统建设依赖于服务厂商,厂商之间技术方案的差异性造成了系统之间的异构化,各种类型的系统架构长期存在,在消息中间件领域尤是如此。如短信平台使用 IBMMQ,CRM 系统使用 ESB 架构,自营业务使用 Oracletuxedo 架构,柜台系统使用恒生 MessageCenter 架构等。随着华泰证券自主研发的大规模投入,迫切需要改变这种烟囱式的系统建设方式,以统一化的服务化平台架构来建设系统。
2015 年,我们通过对 Kafka、ActiveMQ 及 RabbitMQ 等开源消息中间件进行全面的测试对比,最终从性能及高可用方面考虑,选择 Kafka 作为了公司级消息中间件,经过两年多的探索和实践,Kafka 平台已承接大量重要生产业务系统,支撑了全公司业务的高速发展,积累了大量的生产实践经验。
经过将近三年的建设发展,目前在华泰证券内部已分别建设 0.9.0 和 0.10.1 版本的 Kafka 集群,总体集群数量 20 余台。
目前华泰内部 kafka 已为行情计算、交易回报、量化分析等核心系统提供稳定服务,同时涵盖了日志、数据分析等诸多运维领域的应用,日均消息吞吐量达 2.3TB,峰值流量超 4.8Gb/s,TOPIC 数量 190 余个,服务 30 个以上应用系统。
实践经验
(1)高可用双活架构
如图 3 所示,Kafka 高可用特性依赖于 zookeeper 来实现,由于 zookeeper 的 paxos 算法特性,故 zookeeper 采用同城三中心部署方式,保证 zookeeper 本身高可用,通常其中两个数据中心部署偶数台机器,另一数据中心部署单台机器。
Kafkabroker 跨数据中心两节点部署,所有 topic 的 partition 保证在两中心都有副本。如果单数据中心出现问题,另一个中心能自动进行接管,业务系统可以无感知切换。
由于Kafka的高带宽需求,主机采用万兆网卡,并且在网卡做 bond0 以保证网卡高可用,跨数据中心之间的网络通信采用独立的万兆波分通道。

图 3 KAFKA 平台部署架构图
(2)参数调优
• 首先我们在 JVM 层面做了很多尝试。对 Kafka 服务启动参数进行调优,使用 G1 回收器。kafka 内存配置一般选择 64G,其中 16G 给 Kafka 应用本身,剩余内存全部用于操作系统本身的 page cache.
• 此外为了保证核心系统的达到最佳的读写效果,我们采用 SSD 硬盘,并做了 raid5 冗余,来保证硬盘的高效 IO 读写能力。
• 其次我们通过调整 broker 的 num.io.threads,num.network.threads, num.replica.fetchers 等参数来保证集群之间快速复制和吞吐。
(3)数据一致性保证
Kafka 有自己一套独特的消息传输保障机制(at least once)。当 producer 向 broker 发送消息时,由于副本机制(replication)的存在,一旦这条消息被 broker 确认,它将不会丢失。但如果 producer 发送数据给 broker 后,遇到网络问题而造成通信中断,那 producer 就无法判断该条消息是否已经被确认。这时 producer 可以重试,确保消息已经被 broker 确认,为了保证消息的可靠性,我们要求业务做到:
• 保证发送端成功
当 producer 向 leader 发送数据时,可以通过 request.required.acks 参数来设置数据可靠性的级别:
| 1(默认) | leader 已成功收到的数据并得到确认后发送下一条 message。如果 leader 宕机,则会丢失数据。 |
| 0 | 送端无需等待来自 broker 的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。 |
| -1(ALL) | 发送端需要等待 ISR 列表中所有列表都确认接收数据后才算一次发送完成,可靠性最高。 |
• 保证消费者消费成功(at least once)
我们要求消费者关闭自动提交(enable.auto.commit:false),同时当消费者每次 poll 处理完业务逻辑后必须完成手动同步提交(commitSync),如果消费者在消费过程中发生 crash,下次启动时依然会从之前的位置开始消费,从而保证每次提交的内容都能被消费。
• 消息去重
考虑到 producer,broker,consumer 之间都有可能造成消息重复,所以我们要求接收端需要支持消息去重的功能,最好借助业务消息本身的幂等性来做。其中有些大数据组件,如 hbase,elasticsearch 天然就支持幂等操作。
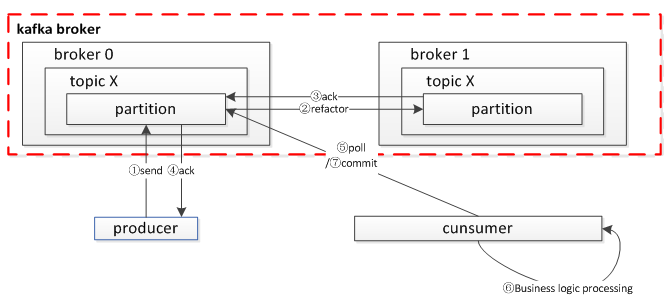
图 4Kafka 消息可靠性机制
场景事例:行情数据 hbase 存储
在华泰内部使用 kafka 来缓存一段时间的行情数据,并做相应处理为了保证 kafka 中数据的完整性,发送端 API 参数配置:
| props.put(“acks”, “all”); |
为了防止某条发送影响后续的消息发送,采用带异步回调的模式发送

在接收端,启动专门的消费者拉取 kafka 数据存入 hbase。hbase 的 rowkey 的设计主要包括 SecurityId(股票id)和 timestamp(行情数据时间)。消费线程从 kafka 拉取数据后反序列化,然后批量插入 hbase,只有插入成功后才往 kafka 中持久化 offset。这样的好处是,如果在中间任意一个阶段发生报错,程序恢复后都会从上一次持久化 offset 的位置开始消费数据,而不会造成数据丢失。如果中途有重复消费的数据,则插入 hbase 的 rowkey 是相同的,数据只会覆盖不会重复,最终达到数据一致。
所以,从根本上说,kafka 上的数据传输也是数据最终一致性的典型场景。
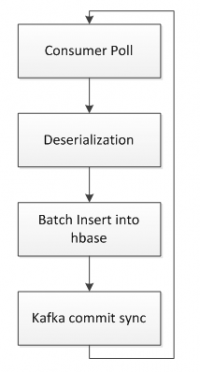
图 5hbase 持久化逻辑
(4)ACL安全
目前华泰内部通过配置 allow.everyone.if.no.acl.found 参数(:true)让 Kafka 集群同时具备 ACL 和非 ACL 的能力,避免资源的浪费。我们选用 SASL 作为 Kafka 鉴权方式,因为 SASL 虽然简单,但已满足需求,而 Kerberos 使用过重,过度复杂组件会给 Kafka 带来更多不确定的因素,如示例所示,根据部门划分来分配用户。
示例:
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
ser_dep1=“ password 1”
user_dep2=“ password 2”
user_dep3=“ password 3”;
};
服务启动后,通过 Kafka 的 command line 接口,配置基于用户、ip、topic、groupid 等的 acl 权限来保证各业务之间的隔离。
未来规划
随着业务的不断发展,Kafka 在华泰证券内部已成为核心组件。未来重点进行 PaaS 平台建设,建立分级保障和 ACL 权限管控,对重点业务进行独立管理。
目前 Kafka 的 topic 一般只有 2 个副本,在某些特殊场景下存在数据丢失的风险,未来我们会通过升级扩容,基于业务的重要程度提升副本数,强化集群的高可用性。
后续我们还会深入研究 Kafka1.0,与 KafkaStreaming、KQL、Storm、Spark、Flink 等流式计算引擎相结合,依托 Kafka 打造公司级流式计算平台。

