Golang学习笔记-魂士篇
一、开始
编译语言:需要解释器,比如jvm,解释称二进制,然后处理器才能执行
解释性:编译后为二进制语言
C、C++、Python、PHP/java/java script 等都是2005之前的,2005年出现了多核处理器,go在2007年出现,go天生支持并发
go语言特点:
- 语法简洁(关键字少)
- 开发效率高(自带垃圾回收)
- 执行性能好(执行效率高)
应用范围:
-
腾讯内部go语言:蓝鲸、微服务架构TarsGo、云平台
-
知乎go语言重构
-
docker,k8s
-
...
Go语言使用场景:
- 服务器编程,日志处理、数据打包、文件系统等
- 网络编程,web应用,api应用等
- 内存数据库,groupcache,couchbase等
- 云平台,CloudFoundy的部分
- 区块链
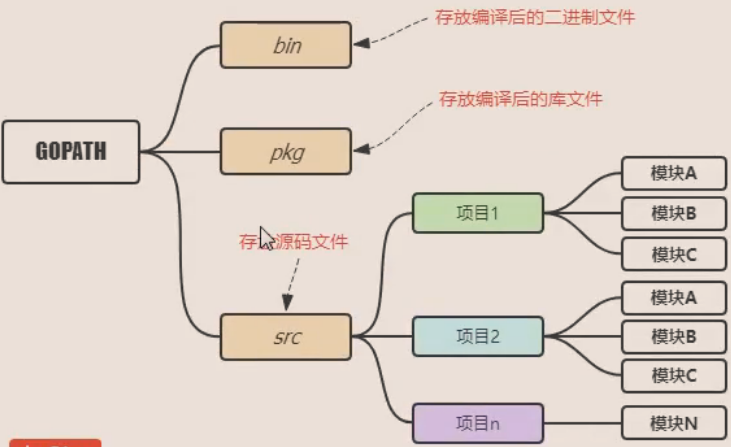
1.1、组织形式
go语言规定src,pkg,bin ...目录统称为工作区,其中src目录必须手动创建,
个人建议
公司:
企业:
如果是vscode安装,安装插件(1、chinses(中文),2、go 安装)
注意:在哪个目录下执行go build main.go,在哪个录下生成main.exe
go build -o hello.exe 默认编译当前目录
go install 安装
1、编译得到一个可执行文件
2、拷贝到GOATH/bin
1.2、跨平台编译
main函数是程序的入口文件
函数外(不在func内)只能放置 标识符(变量、常量、)
默认我们go build的可执行文件都是当前操作系统可执行的文件,如果我想在windows下编译一个linux下可执行文件,那需要怎么做呢?
只需要指定目标操作系统的平台和处理器架构即可:
SET CGO_ENABLED=0 // 禁用CGO
SET GOOS=linux // 目标平台是linux
SET GOARCH=amd64 // 目标处理器架构是amd64
使用了cgo的代码是不支持跨平台编译的
然后再执行go build命令,得到的就是能够在Linux平台运行的可执行文件了。
Mac 下编译 Linux 和 Windows平台 64位 可执行程序:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build
Linux 下编译 Mac 和 Windows 平台64位可执行程序:
CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go build
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build
Windows下编译Mac平台64位可执行程序:
SET CGO_ENABLED=0
SET GOOS=darwin
SET GOARCH=amd64
go build
现在,开启你的Go语言学习之旅吧。人生苦短,let’s Go.
注意:在目录内执行 go build,会生成一个 不带exe,文件名为目录名的二进制可执行文件
1.3、其他
Go1.14版本之后,都推荐使用go mod模式来管理依赖环境了,也不再强制我们把代码必须写在GOPATH下面的src目录了,你可以在你电脑的任意位置编写go代码。(网上有些教程适用于1.11版本之前。)
默认GoPROXY配置是:GOPROXY=https://proxy.golang.org,direct,由于国内访问不到https://proxy.golang.org,所以我们需要换一个PROXY,这里推荐使用https://goproxy.io或https://goproxy.cn。
可以执行下面的命令修改GOPROXY:
go env -w GOPROXY=https://goproxy.cn,direct
配置环境变量
创建目录:D:\Program_language\PRD\PG1
并添加系统环境变量:
GOPATH=D:\Program_language\PRD\PG1
GOBIN=D:\Program_language\PRD\bin
1.4、liteIde快捷键
ctrl + { | } #快速到函数头部或尾部
ctrl + / #选中范围进行注释
ctrl + shift +i #鼠标放在对应的函数上,提示函数参数信息
ctrl + alt +i #代码格式化
二、数据类型
2.1、变量和常量
标识符:(程序中具有特殊意义的词,比如常量名、变量名、函数名等)
标识符命名规范: 字母、数字、下划线,只能以字母和下划线开头
25个关键字:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
37个保留字:
Constants: true false iota nil
Types: int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
Functions: make len cap new append copy close delete
complex real imag
panic recover
-
变量的来历:程序运行过程中的数据是放在内存中的,利用变量在保存内存地址,使用方便
-
变量的类型:go语言中每个变量都有属于自己的类型,并且变量必须初始化后才能被使用
-
变量分类:go语言中变量要声明再使用(全局变量除外,全局变量声明在func外)(函数内的变量声明后必须使用,函数外的可以仅声明)
变量声明:
var s1 string;
var ( a string b int c bool )
变量声明后必须使用
- fmt.Print()没有换行
- fmt.Println()有换行
- fmt.Printf("hello: %s",a) 没有换行符
声明变量的几种方式:
- xiaoming_book //(下换线)
- Xiaoming_Book //(小驼峰)
- xiaoming_Book //(大驼峰)第一个小写,后面的首字母大写,go语言推荐
- var s1 string = "hello world"
- var s2 = "hello world" //类型推导
- s3 := "hello world" //简短变量
- __,age := "xiaoming",30 //匿名变量"_",匿名变量不用占用内存空间,因此也不存在重复声明
变量初始化:
#1、方式1
var 变量名 变量类型 = 表达式
#2、方式1
var stu1 int
stu1 = 18
#3、方式3
var age = 18 //类型推导
#4、方式4 多重赋值
var name,age = "小明",18
#5、方式5
mm := 3.14 //简短声明,
stu1, stu3 := 18, 19
fmt.Printf("%T",a) 可以打印数据类型
#6、方式6
func main() {
var ( // 这里单个变量初始化的方法,同样适用
stu1 = 20
stu2 = 30
stu3 = 40
)
fmt.Println(stu1, stu2, stu3)
}
注意:
- 函数外的每个语句必须以关键字开始(var,const,func等)
- := 不能再函数外 //pai := 3.14在函数外是会报错的,并且只能在首次使用
- "_"多用于占位符,表示忽略值
常量:
leixing const pi = 3.1415
const (
a = 100
b
c
)
fmt.Println(a,b,c) //结果为 100,100,100;
常量声明必须声明值,如果批量声明没有写值,后面的常量会沿用上一个有值的
注释:
// 单行注释
/*多行注释*/
变量交换
func main() {
stu1, stu2 := 10, 20
fmt.Println(stu1, stu2)
//1、变量交换
stu1 = stu2
fmt.Println(stu1, stu2) //20 20 结果
stu2 = stu1
fmt.Println(stu1, stu2) //20 20 结果
//2、变量交换-中间变量
stu1, stu2 = 10, 20
fmt.Println(stu1, stu2) //10 20
c := stu1
stu1 = stu2
stu2 = c
fmt.Println(stu1, stu2) //20 10
//2、变量交换-方式3
stu1, stu2 = 10, 20
stu1, stu2 = stu2, stu1
fmt.Println(stu1, stu2) //20 10
}
2.2、iota
iota是go的常量计数器,只能在常量的表达式中使用
const (
a = 100
b = 200
c = iota
)
fmt.Println(a,b,c) //100,200,2
const (
d = iota
e = 100
f = iota
)
fmt.Println(d,e,f) //0,100,2
const (
m1,m2 = iota+1,iota+2 //iota为0
m3,m4 = iota+1,iota+2 //iota为1
)
fmt.Println(m1,m2,m3,m4) //1,2,2,3
const (
_ = iota
KB = 1 << (10*iota) //iotao为1,1左移10位
MB = 1 << (10*iota)
GB = 1 << (10*iota)
TB = 1 << (10*iota)
PB = 1 << (10*iota)
)
fmt.Println(KB,MB,GB,TB,PB)
/*
1024 1048576 1073741824 1099511627776 1125899906842624
*/
容量单位:
- 1B(byte 字节)=8bit
- 1KB(Kilobyte 千字节)=1024B,
- 1MB(Megabyte 兆字节 简称“兆”)=1024KB,
- 1GB(Gigabyte 吉字节 又称“千兆”)=1024MB,
- 1TB(Terabyte 万亿字节 太字节)=1024GB,
- 1PB(Petabyte 千万亿字节 拍字节)=1024TB,
- 1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
- 1ZB(Zettabyte 十万亿亿字节 泽字节)= 1024EB,
- 1YB(Yottabyte 一亿亿亿字节 尧字节)= 1024ZB,
- 1BB(Brontobyte 一千亿亿亿字节)= 1024YB
注意: iota在const出现的时候将被重置为0(没有上下顺序)。const中每新增一行常量声明都将使iota计数一次(可以理解为const语句中的行索引),多用于枚举
2.3、Go数据类型
- 1 布尔型
布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。注意:
1)默认值为false,2)go语言中不允许将整形强制转换bool类型,3)bool类型无法参与数值运算,也无法与其他类型转换 - 2 数字类型
整型 int 和浮点型 float32、float64,Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 - 3 字符串类型:
字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本 - 4 派生类型:
包括:- (a) 指针类型(Pointer)
- (b) 数组类型
- (c) 结构化类型(struct)
- (d) Channel 类型
- (e) 函数类型
- (f) 切片类型
- (g) 接口类型(interface)
- (h) Map 类型
2.4、数字类型
整形:
| 序号 | 类型 | 描述 | ||
|---|---|---|---|---|
| 1 | uint8 | 无符号 8 位整型 (0 到 255) | ||
| 2 | uint16 | 无符号 16 位整型 (0 到 65535) | ||
| 3 | uint32 | 无符号 32 位整型 (0 到 4294967295) | ||
| 4 | uint64 | 无符号 64 位整型 (0 到 18446744073709551615) | ||
| 5 | int8 | 有符号 8 位整型 (-128 到 127) | ||
| 6 | int16 | 有符号 16 位整型 (-32768 到 32767) | ||
| 7 | int32 | 有符号 32 位整型 (-2147483648 到 2147483647) | ||
| 8 | int64 | 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
其他数字类型:
| 序号 | 类型 | 描述 | ||
|---|---|---|---|---|
| 1 | byte | 类似 uint8(英文字符),和ASCII相对应 | ||
| 2 | rune | 类似 int32(中文,韩文,等...) utf8字符,一个中文3个byte | ||
| 3 | uint/int | 32 或 64 位(32位系统上为32,64位系统为64) | ||
| 4 | uintptr | 无符号整型,用于存放一个指针 |
浮点型和复数:
| 序号 | 类型 | 描述 | ||
|---|---|---|---|---|
| 1 | float32 | IEEE-754 32位浮点型数 | 精确. 后7位 |
|
| 2 | float64 | IEEE-754 64位浮点型数 | 精确. 后15位,自动推导 |
|
| 3 | complex64 | 32 位实数和虚数 | ||
| 4 | complex128 | 64 位实数和虚数 |
#1、字符byte
var a1 byte = '0'
var a2 rune = '中'
fmt.Printf("%d,%T\n", a1, a1) //48,uint8 字符'0'对应的ASCII为48
fmt.Printf("%d,%T\n", a2, a2) //20013,int32
var a3 string = "a" //string "a"包含a和'\0',只是print的时候只会输出a,\0代表字符串的结束
var a4 string = "中"
fmt.Println(a3, len(a3), len(a4)) //a 1 3
a5 := a3 + a4
fmt.Println(a3, len(a3), len(a4), a5) //a 1 3 a中 字符串拼接
mat.Max$数据类型
MaxFloat32 = 3.40282346638528859811704183484516925440e+38 // 2**127 * (2**24 - 1) / 2**23
SmallestNonzeroFloat32 = 1.401298464324817070923729583289916131280e-45 // 1 / 2**(127 - 1 + 23)
MaxFloat64 = 1.797693134862315708145274237317043567981e+308 // 2**1023 * (2**53 - 1) / 2**52
SmallestNonzeroFloat64 = 4.940656458412465441765687928682213723651e-324 // 1 / 2**(1023 - 1 + 52)
MaxInt8 = 1<<7 - 1
MinInt8 = -1 << 7
MaxInt16 = 1<<15 - 1
MinInt16 = -1 << 15
MaxInt32 = 1<<31 - 1
MinInt32 = -1 << 31
MaxInt64 = 1<<63 - 1
MinInt64 = -1 << 63
MaxUint8 = 1<<8 - 1
MaxUint16 = 1<<16 - 1
MaxUint32 = 1<<32 - 1
MaxUint64 = 1<<64 - 1
#2、类型转换
func main() {
a, b, c := 2, 3, 3
sum := a + b + c
fmt.Println(float32(sum) / 3)
}
2.5、字面量
Go1.13版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:
v := 0b00101101, 代表二进制的 101101,相当于十进制的 45。 v := 0o377,代表八进制的 377,相当于十进制的 255。 v := 0x1p-2,代表十六进制的 1 除以 2²,也就是 0.25。 而且还允许我们用 _ 来分隔数字,比如说:
v := 123_456 等于 123456。
package main
import "fmt"
func main(){
// 十进制
var a int = 10
fmt.Printf("%d \n", a) // 10
fmt.Printf("%b \n", a) // 1010 占位符%b表示二进制
// 八进制 以0o开头
var b int = 077
fmt.Printf("%o \n", b) // 77
// 十六进制 以0x开头
var c int = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
}
2.6、八进制&十进制
go语言中无法直接定义二进制
func jinzhi(){
a := 10
fmt.Printf("%d\n",a) //10
fmt.Printf("%b\n",a) //1010
fmt.Printf("%o\n",a) //12
b := 076 //八进制以0(零)开头
fmt.Printf("%o\n",b) //76
fmt.Printf("%d\n",b) //62
c := 0x32 //十六进制0x开头
fmt.Printf("%x\n",c) //32
fmt.Printf("%d\n",c) //50
fmt.Printf("%o\n",c) //62 %b二进制,%o八进制,%x十六进制,%s字符串,
fmt.Printf("%v\t%T",c) //int,%v匹配任意数据类型,%T查看数据类型
d := int8(c)
fmt.Println(d) //强制类型转换
}
func float11(){
m := math.MaxInt16
n := "hello world"
fmt.Printf("value is %#v\n",m) //value is "hello world, %#会对于字符串自动添加""
fmt.Printf("value is %#v\n",n)
}
2.7、字符串
- go内部使用
utf-8编码,字符串只能使用" "表示字符串. go语言的单引号,单个字母,包含的是字符, - 只需要注意rune为utf8编码,英文字符称byte。字符串由字符组成
- "H",字符串类型,string(int32),占用1byte
- "中",字符串类型,string(int32),占用3byte(utf-8编码)
- 'H',字符类型(int32),可以转换为byte(uint8),c1 := byte('H') //注意只有ASCII"字符"(字符串不行)可以转换byte类型
- '中',字符类型(int32)
func chars(){
c := "c"
cc := 'm'
ccc := "中"
cccc := '中'
b := '1'
fmt.Printf("Len: %v,Type: %T\n",c,c) //Len: c,Type: string
fmt.Printf("Len: %v,Type: %T\n",cc,cc) //Len: 109,Type: int32
fmt.Printf("Len: %v,Type: %T\n",ccc,ccc) //Len: 中,Type: string
fmt.Printf("Len: %v,Type: %T\n",cccc,cccc) //Len: 20013,Type: int32
fmt.Printf("Len: %v,Type: %T\n",b,b) //Len: 49,Type: int32
}
func str2(){
info := "Hello"
for i:=0; i< len(info);i++ { //英文遍历
fmt.Printf("str[%d]=%c\n",i,info[i])
}
info2 := "Hello中国"
str2 := []rune(info2) //中文遍历必须转换为 []rune切换才可以
for i:=0; i< len(str2);i++ { //中文遍历
fmt.Printf("str[%d]=%c\n",i,str2[i])
}
}
字符转义
- \r 回车
- \n 换行
- \t 制表符
- ' 单引号
- " 双引号
- \ 反斜杠
func str(){
path1 := "D:\\Golang\\project\\project1\\src"
path2 := `D:\Golang\project\project1\src` //path1和path2效果一样
issue := `
床前明月光
疑是地上霜
举头望明月
低头思故乡
`
fmt.Println(path1)
fmt.Println(path2)
fmt.Println(issue)
}
字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.Contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置(只返回第一个),找不到返回-1 |
| strings.Join(a[]string, sep string) | join操作 |
Repeat: func Repeat(s string, count int) string |
重复s字符串count次,最后返回重复的字符串 |
Replace: func Replace(s, old, new string, n int) string |
在s字符串中,把old字符串替换为new字符串,n表示替换的次数,小于0表示全部替换 |
Trim: func Trim(s string, cutset string) string |
在s字符串的头部和尾部去除cutset指定的字符串 |
Fields: func Fields(s string) []string |
去除s字符串的空格符,并且按照空格分割返回slice |
func str2(){
a1 := "hello"
a2 := "world"
//info := a1 + a2 拼接方法1
//fmt.Println(info)
fmt.Printf("%s %s",a1,a2)
ss1 := fmt.Sprintf("%s %s",a1,a2) //拼接方法2,返回结果为一个字符串
fmt.Println(ss1)
//分割
ret := strings.Split(ss1,"o") //以"o"为分隔符 [hell w rld]
fmt.Println(ret)
//拼接
fmt.Println(strings.Join(ret,"+")) //hell+ w+rld
//包含判断
fmt.Println(strings.Contains(ss1,"world")) //true
fmt.Println(strings.Contains(ss1,"Hello")) //false
//前缀,后缀
fmt.Println(strings.HasPrefix(ss1,"hello")) //true
fmt.Println(strings.HasSuffix(ss1,"hello")) //false
ss2 := "aboddbc2oa"
//子串出现的位置
fmt.Println(strings.Index(ss2,"o")) //2
fmt.Println(strings.LastIndex(ss2,"o")) //8
}
修改字符串
字符串:不可变类型
修改字符串,需要先将其转换成[]rune,或者[]byte,完成后在转换string,无论哪种转换,都会重新分配内存。无论哪种转换,都会重新分配内存,并复制字节数组。
func str3(){
s1 := "白萝卜" //s1是string,由[ 白 萝 卜] 三个字符组成,s1[0]="红"这样是不可以的,sring为不可变类型
s2 := []rune(s1) //转换成切片,切片里面保存的也是字符
s2[0] = '红' //修改字符(注意非修改字符串)
fmt.Println(string(s2)) //红萝卜
//go语言规定了为了处理非ASCII类型的字符(byte),定义了新的rune类型(rune,utf-8字符)
for _,c := range s1 {
//fmt.Println(c) //30333,33821,21340
fmt.Printf("%c-",c) //白-萝-卜,中文一个字算是一个字符
}
fmt.Printf("\nlen is :%v,type is %T\n",len(s2),s2) //len is :3,type is []int32
fmt.Printf("\nlen is :%v,type is %T\n",len(s1),s1) //len is :9,type is string,一个中文占用3个byte,ASCII字符占用一个byte
s3 := []rune(s1)
s3[1],s3[2] = '雪','人'
fmt.Println(string(s3)) //白雪人
f1 := 10 //int类型
f2 := float64(f1) //强制转换
fmt.Printf("type: %T",f2)
}
2.8、字符串类型转换
- strocnv.Format* 系列函数:
Format系列函数把其他类型的转换为字符串。 - strconv.Parse*:
Parse系列函数把字符串转换为其他类型 - strconv.Append*: 其他类型转换为字符串,并存储到字符串切片中
GO 语言中是不允许隐式转换的,所有的类型转换都必须显式声明。而且需要相互兼容。
其他类型转换成字符串
func str1() {
str := "hello world"
slice := []byte(str)
fmt.Println(slice) //[104 101 108 108 111 32 119 111 114 108 100]
}
func str2() {
str := []byte{'h', 'e', 'l', 'l', '0', 97}
fmt.Println(str) //[104 101 108 108 48 97]
fmt.Println(string(str)) //hell0a
}
func str3() { //将其他类型转换为字符串format 系列函数
str := strconv.FormatInt(120, 8)
fmt.Println(str) //170 ,120转换成8禁止 120%8=15余0;15%8=1余7
//func FormatFloat(f float64, fmt byte, prec, bitSize int) string //fmt打印方式,prec:小数位保留个数,bitSize:float32还是float64
s2 := 3.1415926
s3 := strconv.FormatFloat(s2, 'f', 4, 32)
fmt.Printf("%T\t%v\n", s3, s3) //string 3.1416
}
字符串转换为其他类型
func str4() {
a, b, c := "3.14", "true", "12"
fmt.Printf("%T\t%T\t%T\n", a, b, c) //string string string
a1, err := strconv.ParseInt(a, 10, 32) //转换为int;数字是什么进制表示的,要存储为int32/int64
if err != nil {
fmt.Println(err) //parsing "3.14": invalid syntax
}
a2, _ := strconv.ParseFloat(a, 32) ///期望的接受类型为float32,具体以实际为准
a3, err := strconv.ParseInt(c, 16, 32) //c"12"为16进制,转换为int32
b1, _ := strconv.ParseBool(b)
fmt.Printf("%T\t%T\t%T\t%T\n", a1, a2, a3, b1) //int64 float64 int64 bool
fmt.Println(a1, a2, a3, b1) //0 3.14 18 true
}
其他类型字符串
func str5() {
slice := make([]byte, 0, 1024)
slice = strconv.AppendBool(slice, false)
slice = strconv.AppendInt(slice, 123, 10)
slice = strconv.AppendFloat(slice, 3.14159, 'f', 4, 64)
slice = strconv.AppendQuote(slice, "hello") //添加字符串
fmt.Println(string(slice)) //false1233.1416"hello"
}
func main(){
//str := "10000"
//str1 := int64(str) //不能这样转换
//数字转换成字符串
i := int32(68)
ret := int64(i)
ret2 := string(i)
fmt.Println(ret,ret2) //68 D, string会把 i 转换成编码对应的字符
ret3 := fmt.Sprintf("%d",i)
fmt.Printf("%T %#v\n",ret3,ret3) //"string "68"
//字符串解析成数字
str := "100"
str1,err := strconv.ParseInt(str,10,32) //10进制的str,转换成 对应的 int32类型(实际返回的是int64,需要手动转换为int32)
if err != nil {
fmt.Println(err)
}
fmt.Printf("%#v %T\n",str1,str1) //100 int64
//字符串解析成int (array to int) ,strconv.Itoa(),strconv.Atoi()
str2,err := strconv.Atoi(str)
if err != nil {
fmt.Println(err)
}
fmt.Printf("%#v %T\n",str2,str2) //100 int
//从字符串中解析出布尔值
boolStr := "true"
boolvalue,_ := strconv.ParseBool(boolStr)
fmt.Printf("%#v %T\n",boolvalue,boolvalue) //true bool ,只要传递的字符不是"true"都是false
}
2.9、rune和byte
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
var a := '中'var b := 'x'
Go 语言的字符有以下两种:
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。rune类型,代表一个UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
// 遍历字符串
func traversalString() {
s := "hello沙河"
for i := 0; i < len(s); i++ { //byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}
输出:
104(h) 101(e) 108(l) 108(l) 111(o) 230(æ) 178(²) 153() 230(æ) 178(²) 179(³) 104(h) 101(e) 108(l) 108(l) 111(o) 27801(沙) 27827(河)
因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的 字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
三、流控语法
程序的三大结构:顺序结构、选择结构、循环结构
3.1、if
用法
if condition { //单条件判断
//do something
}
if condition { //多条件判断
} else if condition {
//do something
} else {
//do something
}
if 单条件先跟个语句然后再做条件判断
if statement;condition{ //单条件,带语句的判断
//do something
}
func main(){ ////多条件,不带语句的判断
if num :=34, num <= 50{ //num的作用域只在if语句内有效
fmt.Println("Number is less then 50")
} else if num >= 51 && num <= 100{
fmt.Println("The number is between 51 and1 100")
} else{
fmt.Println("The number is greater than 100")
}
fmt.Println(num) //会失败,因为num的作用域只在if范围内有效
}
3.2 、for
- go只有for没有while循环
- for循环可以通过break,goto,return,panic语句强制退出循环
- go语言中
for range遍历数组、切片、字符串、map以及通道(channel)。通过for range遍历的返回值有一下规律: - 1、数组、切片、字符串返回索引和值
- 2、map返回键和值
- 3、通道只返回通道内的值
for 初始语句;条件表达式;结束语句{ //格式1
循环体
}
for ;条件表达式;结束语句{ //格式2
循环体
}
for 条件表达式{ //格式3
循环体
}
for { //格式4,死循环
循环体语句
}
示例1
func str6(){
info := "hello 中国"
for i,v := range info {
//fmt.Println(i,v) //默认输出的是 utf-8的编自值
fmt.Printf("%v %s\n",i,string(v))
// fmt.Printf("%d %c\n",i,v) //效果同上,打印字符
}
}
示例2
func break1(){
for i := 0 ; i< 10 ; i++ {
if i == 3 {
continue //跳过本次循环
}
if i == 5 {
break //跳出for循环
}
fmt.Println(i)
}
fmt.Println("over")
}
99乘法表
func a99(){
for i := 1; i<= 9 ; i++ {
for v :=1; v <= i ;v ++ {
fmt.Printf("%d*%d=%v\t",i,v,i*v)
}
fmt.Println()
}
}
3.3、switch
简化大量的判断和一个具体的值进行判断
func switch1(){
switch n:=7; n { //n也可以在外面声明,n的作用域不同
case 1,3,5,7,9: //case后面的判断对象,可以是多个
fmt.Println("奇数")
case 2,4,6,8,0:
fmt.Println("偶数")
default :
fmt.Println("Unknown: ",n)
}
h := 65
switch { //判断内容放在case中
case h < 18 :
fmt.Println("未成年")
case h >= 18 && h <=35:
fmt.Println("青壮年")
case h > 55 :
fmt.Println("老年") //打印"老年"和"老年人"
fallthrough //fallthrough语句可以在已经执行完成的 case 之后,把控制权转移到下一个case 的执行代码中。(建议不用)
case h >=60 :
fmt.Println("老年人")
default :
fmt.Println("are you ok")
}
}
3.4、goto(不建议用)
goto语句通过使用标签进行代码间的无条件跳转。goto语句可以在快速跳出循环、避免重复退出上有一定的帮助。go语言中使用goto语句能简化一些代码的实现过程。
func goDemo1(){
var breakFlag bool
for i := 0; i<10; i++ {
for v :=0 ;v <=10;v ++ {
if v == 3 {
breakFlag = true
break //1个break只跳出一层循环
}
fmt.Println(i,v)
}
if breakFlag { //如果breakFlag为ture,就跳出外层循环
break
}
}
}
func goDemo2(){ //优化后的go代码
for i := 0; i<10; i++ {
for v :=0 ;v <=10;v ++ {
if v == 3 {
goto breakFlag //跳转到指定label
}
fmt.Println(i,v)
}
}
breakFlag: //label名称
fmt.Println("Game Over... !")
}
3.5、break和continue
跳转语句:go和break break语句可以结束for、switch和select的代码块。
- continue:
continue语句可以结束当前循环,开始下一次的循环迭代过程,仅限在for循环内使用。 - break: 跳出break所在的for循环。如果break在内层for,则对外层无影响
- return: 函数结束,进行返回
break语句还可以在语句后面添加标签,表示退出某个标签对应的代码块,标签要求必须定义在对应的for、switch和 select的代码块上。 举个例子:
func breakDemo1() {
BREAKDEMO1:
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break BREAKDEMO1
}
fmt.Printf("%v-%v\n", i, j)
}
}
fmt.Println("...")
}
continue语句可以结束当前循环,开始下一次的循环迭代过程,仅限在for循环内使用。
在 continue语句后添加标签时,表示继续执行开始标签对应的循环的下一次循环。例如:
#1、不加label
func main() {
for x := 1; x <= 9; x++ {
for y := x; y <= 9; y++ {
if y == 2 {
continue
}
fmt.Printf("%d*%d=%d\t", x, y, x*y)
}
fmt.Println()
}
}
D:\Program_language\PRD\PG1\src>go run main.go
1*1=1 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8=8 1*9=9
2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18
3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27
4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36
5*5=25 5*6=30 5*7=35 5*8=40 5*9=45
6*6=36 6*7=42 6*8=48 6*9=54
7*7=49 7*8=56 7*9=63
8*8=64 8*9=72
9*9=81
# 2、加上label
func main() {
test:
for x := 1; x <= 9; x++ {
for y := x; y <= 9; y++ {
if y == 2 {
continue test
}
fmt.Printf("%d*%d=%d\t", x, y, x*y)
}
fmt.Println()
}
}
D:\Program_language\PRD\PG1\src>go run main.go #continue到外层循环
1*1=1 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27
4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36
5*5=25 5*6=30 5*7=35 5*8=40 5*9=45
6*6=36 6*7=42 6*8=48 6*9=54
7*7=49 7*8=56 7*9=63
8*8=64 8*9=72
9*9=81
四、高级数据类型
4.1、运算符
go语言内置的运算符:
- 1、算数运算符:+ - * / % ++ --
- 2、关系运算符:== != > >= < <=
- 3、逻辑运算符:&& || !
- 4、位运算符: & | ^ << >>
- 5、赋值运算符: = += -= *= /= %= <<= >>= &= != ^=
位运算符:
| 运算符 | 描述 |
|---|---|
| & | 参与运算的两位数二进制位相与(2位均为1才为1) |
| | | 参与运算的两位数二进制相或(2位一位为1即为1) |
| ^ | 参与运算的两位数二进制相异或(2位不一样则为1) |
| << | 左移n位就是乘以2的次方,a<< b是把a的各二进制位左移b位,高位丢弃,低位补0 |
| >> | 右移n位就是除以2的n次方,"a>>b"就是把a的各二进制位全部右移b位 |
- 赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 |
| += | 相加后再赋值 |
| -= | 相减后再赋值 |
| *= | 相乘后再赋值 |
| /= | 相除后再赋值 |
| %= | 求余后再赋值 |
| <<= | 左移后赋值 |
| >>= | 右移后赋值 |
| &= | 按位与后赋值 |
| |= | 按位或后赋值 |
| ^= | 按位异或后赋值 |
- 练习题:统计每个字符出现次数
//版本1: 值传递(数组为值类型,默认为值传递),在内存中为独立的2份数据
package main
import "fmt"
func calc(n []int){
var sum = make(map[int]int,10)
for _,v := range n {
sum[v]++
}
fmt.Println(sum)
}
func main(){
s1 := []int{1,22,33,1,11,22,33,22} //思路,把切片的内容当作key
calc(s1)
}
//版本2,传递指针方式
package main
import (
"fmt"
)
func calc(a *[]int) {
fmt.Printf("%T,%v\n", a, a) //*[]int,&[1 22 33 1 11 22 33 22]
var m = make(map[int]int, len(*a))
for _, v := range *(a) {
m[v]++
}
(*a)[0] = 100
fmt.Println(m) //map[1:2 11:1 22:3 33:2]
fmt.Println(a) //&[100 22 33 1 11 22 33 22],传递的是指针,因此会改变原有的值
}
func main() {
s1 := []int{1, 22, 33, 1, 11, 22, 33, 22}
calc(&s1)
fmt.Println(s1) //[100 22 33 1 11 22 33 22]
}
4.2、数组(重点)
数组是一种数据类型元素的集合(存放基础类型元素的容器)。在Go语言中,数组从声明时就确定。使用时可以修改数组成员,但是数组大小不可变化
- 数组是值类型,函数传递传递的是副本
定义数组
var a [3]int定义一个数组类型var 数组变量 [元素数量]类型- [3]int 和[5]int是布偶听的类型(容量是数组的一部分)
初始化
- 如果不初始化:默认元素都是零值(布尔类型:false,string类型:"",整形和浮点型:0)
- 初始化方式1:a1 = [3]
- 数组是值类型(传递的是值)(引用类型,传递的为地址,可被修改)
- 数组支持== 和 != 操作符,
[n]*T表示指针数组,*[n]T表示数组指针 //谁在后,先念谁([数组]*指针)
func array1(){
var s1 [10]int //初始化方式1
s1 = [10]int{0,1,2,3,4,5,6,7,8,9}
fmt.Println(s1)
s2 := [...]int{0,1,2,3} //初始化方式2:[...]根据初始值自动推断数组的长度 [0 1 2 3]
fmt.Println(s2)
s3 := [5]int{1,2,3} //初始化方法3:只初始化部分值
fmt.Println(s3)
s4 := []int{0:12,1:1,4:22} //初始化方法4:根据索引初始化,中间的5也可以忽略 [12 1 0 0 22]
fmt.Println(s4) //长度为5
s5 := [...]string{"北京","河南","上海","广州"}
for k,v := range s5 {
fmt.Println(k,":",v)
}
for i:=0;i<len(s5);i++ { //range也可以实现遍历
fmt.Println(s5[i])
}
}
func modify(s1 [3]int){ //数组为值类型,传递的是副本
// go语言中函数的传递都是值,copy过去的,不会修改原值,除非用&,*
s1[0] = 100
}
func arr3(){
a1 := [3]int{1,2,3}
fmt.Println(a1) //[1 2 3]
modify(a1)
fmt.Println(a1) //[1 2 3]
a2 := a1 //传递的是副本
a2[1] = 30
fmt.Println(a1,a2) //[1 2 3] [1 30 3]
}
4.2.1、多维数组
func array2(){
//[[1 2],[3 4],[5 6]]
var arr1 [3][2]int
arr1 = [3][2]int{
[2]int{1,2},
[2]int{3,4},
[2]int{5,6},
}
arr2 := [...][2]int{
{1,2},
{2,3},
{3,4},
}
arr3 := [...][2]string{ //多为数组,外层的个数可以使用"..."",内从的不行
{"河北","石家庄"},
{"河南","郑州"},
{"湖北","武汉"},
}
fmt.Println(arr1) //[[1 2] [3 4] [5 6]]
fmt.Println(arr2) //[[1 2] [3 4] [5 6]]
fmt.Println(arr3) //[[河北 石家庄] [河南 郑州] [湖北 武汉]]
}
var a1 [3][2]int :表示3个[2]int类型,[[int,int],[int,int],[int,int]]
注意: 多维数组只有第一层可以使用...来让编译器推导数组长度。例如:
//支持的写法
a := [...][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
//不支持多维数组的内层使用...
b := [3][...]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
4.2.2、求和
- 求数组
[1, 3, 5, 7, 8]所有元素的和 - 找出数组中和为指定值的两个元素的下标,比如从数组
[1, 3, 5, 7, 8]中找出和为8的两个元素的下标分别为(0,3)和(1,2)。
package main
import "fmt"
func main(){
var a = [...]int{1,3,5,7,8}
var sum int = 0
for _,v := range a{
sum += v
}
fmt.Println("sum:",sum)
var f1 = func (t int) {
for c :=0;c <len(a)/2;c ++ {
for m,n := range a {
if a[c] + n == t {
fmt.Println("(",c,m,")")
}
}
}
}
f1(8)
}
4.2.3、数组逆置
func reverse() {
var s1 = [...]int{1, 2, 3, 4, 5}
for k, _ := range s1 {
tmp := s1[len(s1)-k-1]
s1[len(s1)-k-1] = s1[k]
s1[k] = tmp
if k >= len(s1)/2 {
break
}
}
fmt.Println(s1) //[5 4 3 2 1]
}
4.2.4、冒泡排序
相邻两个数进行比较,并根据需要交换顺序
func reverse() { //从大到小
var s1 = [...]int{11, 20, 3, 4, 55}
for k, _ := range s1 {
if k == 0 {
continue
} else if s1[k] > s1[k-1] {
tmp := s1[k-1]
s1[k-1] = s1[k]
s1[k] = tmp
}
}
fmt.Println(s1) //[20 11 4 55 3]
}
//每执行一个周期,就可以确定一个数据是有效的,上例中可以确定3是最小的
//完整版,冒泡排序
package main
import (
"fmt"
)
func reverse(s1 *[5]int) {
for k, _ := range s1 {
if k == 0 {
continue
} else if s1[k] > s1[k-1] {
s1[k-1], s1[k] = s1[k], s1[k-1] //go中可以直接这样写,不需要中间变量
}
}
fmt.Println(s1)
}
func main() {
var s1 = [...]int{11, 20, 3, 4, 55}
for i := 0; i < len(s1); i++ {
reverse(&s1)
}
}
/*
&[20 11 4 55 3]
&[20 11 55 4 3]
&[20 55 11 4 3]
&[55 20 11 4 3]
&[55 20 11 4 3]
*/
4.2.5、随机数-随机密码
#1、随机数
func main() {
//方式1
rand.Seed(10) //随机数种子如果相同,则每次生成的随机数是一样的(每次执行.exe文件结果都一样)
fmt.Println(rand.Int()) //5221277731205826435
fmt.Println(rand.Int()) //3852159813000522384
//方式2,真正的随机,10以内的随机数
rand.Seed(time.Now().UnixNano())
fmt.Println(rand.Intn(10)) // rand.Intn(10)对10进行取模
}
随机密码-方式1
package main
import (
"fmt"
"math/rand"
"time"
)
/*
1、定义const,确定取值范围
2、定义每个const的随机取值
3、随机在每个const中取出随机的值
*/
const (
NUmStr = "0123456789"
CharStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
SpecStr = "+=-@#~,.[]()!%^*$"
)
func ranSecret(n int) {
rand.Seed(time.Now().UnixNano())
var ranS = func() int {
return rand.Intn(3)
}
var ranNum = func() string {
return string(NUmStr[rand.Intn(len(NUmStr))])
}
var ranChart = func() string {
return string(CharStr[rand.Intn(len(CharStr))])
}
var ranSpec = func() string {
return string(SpecStr[rand.Intn(len(SpecStr))])
}
// var secret [n]string //non-constant array bound,go数组的长度必须是常量,不能是变量
secret := make([]string, n)
for i := 0; i < n; i++ {
switch r := ranS(); r {
case 0:
secret[i] = ranNum()
case 1:
secret[i] = ranChart()
case 2:
secret[i] = ranSpec()
}
}
for _, v := range secret {
fmt.Printf("%v", v)
}
fmt.Println()
}
func main() {
ranSecret(12)
}
随机密码-方式2
package main
import (
"fmt"
"math/rand"
"time"
)
/*
1、定义const,确定取值范围
2、定义每个const的随机取值
3、随机在每个const中取出随机的值
*/
const (
NUmStr = "0123456789"
CharStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
SpecStr = "+=-@#~,.[]()!%^*$"
)
func ranSecret(n int) {
rand.Seed(time.Now().UnixNano())
var ranS = func() int {
return rand.Intn(3)
}
var ranNum = func() byte {
return NUmStr[rand.Intn(len(NUmStr))]
}
var ranChart = func() byte {
return CharStr[rand.Intn(len(CharStr))]
}
var ranSpec = func() byte {
return SpecStr[rand.Intn(len(SpecStr))]
}
// var secret [n]string //non-constant array bound,go数组的长度必须是常量,不能是变量
secret := make([]byte, n)
for i := 0; i < n; i++ {
switch r := ranS(); r {
case 0:
secret[i] = ranNum()
case 1:
secret[i] = ranChart()
case 2:
secret[i] = ranSpec()
}
}
for _, v := range secret {
fmt.Printf("%v", string(v))
}
fmt.Println()
}
func main() {
ranSecret(12)
}
4.2.6、双色球
红球:1-33 选择6个,不重复,篮球 1-16 选择1个,可以和红球重复
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
rand.Seed(time.Now().UnixNano())
tmp := func() int {
return rand.Intn(33) + 1 //+1是因为有 0值,并且33也在范围内
}
var red [6]int
for i := 0; i < len(red); i++ {
v := tmp()
//去重方法1-死循环
// for k := 0; k < i; k++ { //去除重复项
// for red[k] == v {
// v = tmp()
// }
// }
//去重方法2-重置索引坐标(建议)
for k := 0; k < i; k++ {
if red[k] == v {
v = tmp()
k = -1
}
}
red[i] = v
}
blue := tmp()
fmt.Println(red, blue)
}
4.3、切片(重点)
-
数组的长度是固定的是,是类型的一部分。切片是一个拥有相同类型的可变长度的队列,是基于数组的做的一层封装。切片是引用类型,它的内部结构包含
地址、长度和容量。切片- 一般用于快速的操作一块数据集合.切片的本质:一块连续的内存,属于引用类型,真正的数据保存在数组内。 -
切片的三要素:指针、长度、容量 //指针:切片第一个元素
-
切片不能直接比较,切片唯一合法的比较操作是:
nil一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil,例如下面的示例:var s1 []int //len(s1)=0;cap(s1)=0;s1==nil s2 := []int{} //len(s2)=0;cap(s2)=0;s2!=nil s3 := make([]int, 0) //len(s3)=0;cap(s3)=0;s3!=nil var users = []string{"test", "test2"} //切片的类型声明在 = 后
举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下。
一个nil的底层切片是切片是没有底层数组的,长度和容量都是0。但我们不能说长度和容量都是0的切片一定是nil(len(s)==0和s == nil 是不一样的)
func slice1(){
//1、切片定义
var s1 []int //定义一个存放int类型元素的切片(注意长度不要定义),底层为数组
var s2 []string
//2、切片初始化,使用如下方法或者使用make初始化(slice一定要初始化)
s1 = []int{1,2,3}
s2 = []string{"Red","Green","Gray"}
var s3 []bool
s3 = []bool{false,true}
s3 = append(s3, true)
fmt.Println(s1,s2) //
fmt.Println(s3 == nil) //判断是否为空(是否开辟内存空间)
//fmt.Println(s3 == s1) 切片是引用类型,不支持直接比较
//3、切片的长度和容量 (自定义类型切片:切片容量和长度都是一样的)
fmt.Printf("Len: %d,Cap: %d\n",len(s1),cap(s1)) //Len: 3,Cap: 3
fmt.Printf("Len: %d,Cap: %d\n",len(s2),cap(s2)) //Len: 3,Cap: 3
fmt.Printf("Len: %d,Cap: %d\n",len(s3),cap(s3)) //Len: 3,Cap: 8 append后会发生变化,另说
//4、由数组得到切片
a1 := [...]int{1,3,5,7,9,11,13}
array1 := a1[:4] //a1[0]-a1[3],左包含,右不包含,其他切割方式: a1 := array1[1:] ,a2 := array1[:4](下标0-3),a3 := array1[:](所有)
array2 := a1[3:]
array3 := a1[:]
array4 := a1[3:5]
fmt.Println(array1,array2,array3,array4) //[1 3 5 7] [7 9 11 13] [1 3 5 7 9 11 13] [7 9]
fmt.Printf("Len: %d,Cap: %d\n",len(array1),cap(array1)) //Len: 4,Cap: 7
// 数组类型切片:切片的容量是切片的第一个元素到底层数组的最后一个元素的容量(append后另说)
// 自定义类型切片:初始化后的切片容量和长度都是一样的(append后另说)
fmt.Printf("Len: %d,Cap: %d\n",len(array2),cap(array2)) //Len: 4,Cap: 4 [7 9 11 13]
fmt.Printf("Len: %d,Cap: %d\n",len(array4),cap(array4)) //Len: 2,Cap: 4
//5、切片再切片
arr5 := array2[2:] //[7 9 11 13]
fmt.Println(arr5)
a1[6] = 100
fmt.Printf("Len: %d,Cap: %d,Value: %d\n",len(arr5),cap(arr5),arr5) //Len: 2,Cap: 2,Value: [11 100]
//切片是引用类型。对底层数组元素的修改,会影响上层的切片
}
func slice2() {
s := []int{10, 20, 30, 40, 50}
slice := s[0:3:5] //截取s[low:high:max},max为容量max(cap)=max-low不能大于原有的切片的cap,一般不用max
fmt.Printf("%v\t%v\n", slice, cap(slice)) //[10 20 30],5
}
func slice2(){
//1、make函数创建切片(var []int不能定义切片长度,make可以)
s1 := make([]int,5,10) // s1 := make([]int,5)表示长度和容量都是5
fmt.Printf("Len: %d,Cap: %d,Value: %d\n",len(s1),cap(s1),s1) //Len: 5,Cap: 10,Value: [0 0 0 0 0]
//2、一个nil的底层切片是切片是没有底层数组的,长度和容量都是0。但我们不能说长度和容量都是0的切片一定是nil(len(s)==0和s == nil 是不一样的),nil是没有分配内存的意思,需要初始化内存空间才能赋值
//var ss1 []int //Len: 0,Cap: 0,ss1==nil
//ss2 := []int{} //Len: 0,Cap: 0,ss2!=nil
//ss3 := make([]int,0) //Len: 0,Cap: 0,ss3!=nil
//所以,要判断一个切片是否为空,要使用len(s)==0,而不应该使用s == nil判断
//3、切片的赋值
s2 := s1 //s2和s1共用相同的底层数组
_ = s2 //单纯为了语法不报错
//4、切片的遍历和数组遍历同
//for i=0;i<len(s);i++ ;和for _,v := range s
}
4.3.1、append和copy
使用Copy()函数复制切片,由于切片是引用类型,修改引用切片a的 切片 a1 的值也会发生变化
切片的扩容策略:
- 首先判断:如果新申请的容量cap 大于2倍的旧容量oldcap,最终容量newcap就是新申请的容量cap
- 否则判断,如果旧切片的长度小于1024,则最终容量newcap就是旧容量oldcap的2倍(newcap=doublecap)
- 否则判断,如果旧切片长度大于1024,则最终容量newcap从旧容量oldcap开始循环增加原来的1/4,(newcap=old.cap,for{newcap += newcap/4}),直到最终容量大于等于新申请的容量
- 如果最终容量cap计算值溢出,则最终容量就是新申请容量cap
- 注意:切片扩容还会根据切片中元素的类型的不同而做出不同的处理,比如int和string类型的切片的处理方式是不一样。
func slice3(){
//1、append基础使用
s1 := []string{"北京","上海","广州"}
//s1[3] = "深圳" //会报错 index out of range,只能append的形式添加
s1 = append(s1,"杭州")
//注意,调用append函数必须用原来的 切片变量 保存返回值。append追加元素,原来的底层数组放不下的时候。go底层会开辟一块新的内存使用
fmt.Printf("Len: %v,Cap: %v,Value: %v\n",len(s1),cap(s1),s1) //Len: 4,Cap: 6,Value: [北京 上海 广州 杭州]
s2 := []string{"武汉","苏州","四川","郑州"}
s1 = append(s1,s2...) //... 表示展开
fmt.Printf("Len: %v,Cap: %v,Value: %v\n",len(s1),cap(s1),s1) //Len: 8,Cap: 12,Value: [北京 上海 广州 杭州 武汉 苏州 四川 郑州]
//2、copy函数
a1 := []int{1,2,3,4,5}
a2 := a1
//var a3 []int
//copy(a3,a1)
//fmt.Println(a1,a2,a3) //[1 2 3 4 5] [1 2 3 4 5] [],注意:a3位空,因为var a3 []int这种声明a3没有内存空间,copy失败
a3 := make([]int,5,5)
copy(a3,a2) //a2的值copy给a3,a3将使用新的内存空间,不会因为a1和a2值的改变而改变
a1[2]=5
fmt.Println(a1,a2,a3) //[1 2 5 4 5] [1 2 5 4 5] [1 2 3 4 5]
//3、从切片中删除元素,go语言中没有专用的删除切片元素的方法,需要自己定义:比如要删除index为2的元素
a3 = append(a3[:2],a3[3:]...) //[1 2 4 5]
fmt.Println(a3)
//4、slice的变与不变(1、切片不保存具体的值,2、切片对应一个底层数组,3、底层数组都是占用一块连续的内存)
a11 := make([]int,10)
a11 = []int{1,3,5,7,9,11,13}
array1 := a11[:4]
array2 := a11[3:]
array3 := a11[:]
array4 := a11[3:5]
fmt.Println(a11,array1,array2,array3,array4) //没变:[1 3 5 7 9 11 13] [1 3 5 7] [7 9 11 13] [1 3 5 7 9 11 13] [7 9]
array1[0] = 0
fmt.Println(a11,array1) //[0 3 5 7 9 11 13] [0 3 5 7] ,对slice的slice的操作会影响到原切片
a11 = append(a11[:2],a11[3:]...) //
fmt.Println(a11) //变化:[0 3 7 9 11 13]
a11 = append(a11[:5],a11[2:]...)
fmt.Printf("Address: %p, Value: %v\n",a11,a11) //%p 打印内存地址,如果要取单个元素 fmt.Printf("%v",&a11[0])
//5、追加坑
m1 := make([]int,5,10)
for i:=0;i<10;i++ {
m1 = append(m1,i)
}
fmt.Println(m1) //[0 0 0 0 0 0 1 2 3 4 5 6 7 8 9],从index为5开始追加,因为初始化容量为5
}
- 练习1:使用sort排序
func sort1(){
a1 := [...]int{7,2,1,5}
sort.Ints(a1[:]) // 传递的参数只能是slice类型,因此不能直接传递a1
fmt.Println(a1) //[1 2 5 7]
}
练习2:copy
func copy1(){ //copy 目标slice未初始化,会copy失败,但是不会报错
a1 := []int{1,2,3}
a2 := a1
a2[0] = 100
var a3 []int
copy(a3,a1)
fmt.Println(a1) //[100 2 3]
fmt.Println(a2) //[100 2 3]
fmt.Println(a3 == nil) //true
fmt.Println(a3) //[] 因为a3是nil ,需要对a3初始化后才能使用。
}
func copy2(){ //copy 目标slice初始化但是len为0,仍会copy失败
a1 := []int{1,2,3}
a2 := a1
a2[0] = 100
var a3 []int
a3 = make([]int,0,3)
copy(a3,a1)
fmt.Println(a1) //[100 2 3]
fmt.Println(a2) //[100 2 3]
fmt.Println(a3 == nil) //false
fmt.Println(a3) //[] ,copy不会自动扩容切片,而a3的长度为0,因此拷贝不进去结果为 []
}
func copy3(){
a1 := []int{1,2,3}
a2 := a1
var a3 []int
a3 = make([]int,3,3)
copy(a3,a1)
a2[0] = 100
fmt.Println(a1) //[100 2 3]
fmt.Println(a2) //[100 2 3]
fmt.Println(a3 == nil) //false
fmt.Println(a3) //[1 2 3]
}
4.3.2、切片传递
数组参数传递为值传递,切片是引用传递,在被调函数内修改会修改原有切片值
func slice4(a []int) {
a[0] = 100 //这里修改的是原slice的
a = append(a, 4, 5, 6)
a[0] = 200
fmt.Println(a) //[200 2 3 4 5 4 5 6],这里不会修改原slice,因为slice进行了扩容,开辟了新的内存地址
}
func main() {
slice := []in{1, 2, 3, 4, 5}
slice4(slice) //传递的是地址,切片名本身就是地址
fmt.Println(slice) //[100 2 3 4 5]
}
4.3.3、make和new
make也是用来分配内存的,区别于new,他只用于slice、map以及chan的内存创建。而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种就是引用类型,所以他们没有必要返回他们的指针了。make函数的函数签名如下:
func make(t Type,size ...IntegerType) Type
make函数是无可替代的,我们在使用slice、map和channel的时候。都需要使用make进行初始化,然后才可以对他们进行
make和new的区分:
- make和new都是用来申请内存的(基础类型初始化会直接分配内存,引用类型不会)
- new很少用,主要用来给基础类型申请内存(int,string,bool...) ,初始化数据类型返回的是对应数据类型的指针
- make是用来给slice,channel,map申请内存的,make返回的是对应的
代码示例1:会panic
func mk(){
var a *int //nil
fmt.Println(a) //nil
*a =100 //*a 根据 nil的内存地址找值,自然找不到
fmt.Println(a) //invalid memory address or nil pointer dereference
var b map[string]int
b["洛阳"] = 379
fmt.Println(b) //panic: assignment to entry in nil map
}
原因:在Go语言中对于引用类型的变量(指针,slice,map,chan...),我们在使用的时候不仅要声明它,还要为他分配内存。否则我们的值就无法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来了new和make。Go语言中new和make是内建的两个函数,主要用来分配内存
解决:
func mk(){
var a *int //nil
*a =100 //*a 根据 nil的内存地址找值,自然找不到
fmt.Println(a) //invalid memory address or nil pointer dereference
var b map[string]int
b["洛阳"] = 379
fmt.Println(b) //panic: assignment to entry in nil map
}
func mk(){
var a1 *int
fmt.Println(a1) //nil
var a2 = new(int)
fmt.Println(a2) // 0xc0000100c0
fmt.Println(*a2) //0
*a2 = 100
fmt.Println(*a2) //100
var b = make(map[string]int,5)
b["洛阳"] = 379
fmt.Println(b)
}
4.4、指针(重点)
4.4.1、指针
参数传递涉及两个概念:值(存储在内存中的数据)和地址(数据所在内存的地址)
go语言不存在指针操作(不能修改),只需要记住2个字符:1、 &取出地址 ;2、 *根据地址取值
func pointer(){
n := 20
p := &n //&获取地址,p存储的是n的内存地址(16进制的数字)。指针变量p的值是指针地址
fmt.Printf("type: %T,Value: %v\n",p,p) //type: *int(int类型的指针),Value: 0xc000010098
m := *p //*根据地址取值
fmt.Println(m) //20
}
func p1(a *int) {
*a = 99
fmt.Println(a)
}
func main() {
//1、定义指针变量
var p *int
fmt.Printf("%p\t%v\n", p, p) //0x0 <nil>
//内存地址中0x 0-255空间为系统占用,不允许用户访问
i := 100
p = &i
fmt.Printf("%v\t%v\t%v\n", p, *p, &p) //0xc00000e180 100 0xc000006028
//2、参数传递,引用传递
b := 20
p = &b
p1(p)
fmt.Printf("%v\t%v\t%v\n", p, *p, &p) //0xc00000e1b0 99 0xc000006028
}
4.4.2、数组-指针
func modify(x *[]int) {
(*x)[0] = 100
}
func modify2(x []*int) {
*(x[0]) = 100
}
func main() {
//1、指针切片,指针数组同理
arry := []int{11, 12, 13}
var p *[]int
p = &arry
modify(p) //为引用传递
fmt.Println(arry) //[100 12 13]
//2、切片指针
a, b, c := 21, 22, 23
// var arry2 []*int //会报错runtime error: index out of range [0] with length 0
arry2 := make([]*int, 3) //切片要先初始化,否则会报错 index out of range
arry2[0] = &a
arry2[1] = &b
arry2[2] = &c
modify2(arry2)
fmt.Println(arry2, *(arry2[0])) // [0xc0000a2088 0xc0000a20b0 0xc0000a20b8] 100
}
4.5、结构体
4.5.1、类型别名和自定义类型
- 根据基础数据类型(int,string,...)创建自己的类型
- type myInt int //自定义类型
- type yourInt = int //类型别名
- 类型别名,目的是为了编写代码的时候更清晰
type myInt int
type yourInt = int
func main(){
var m myInt
m = 10
fmt.Printf("m is %T,%v\n",m,m) //m is main.myInt,10
var n yourInt
n = 10
fmt.Printf("m is %T,%v\n",n,n) //m is int,10
var c rune //rune本身也是int32的别名
c = '中'
fmt.Printf("m is %T,%v\n",c,c) //m is int32,20013
var d byte //byte本身也是int8的别名
d = 10
fmt.Printf("m is %T,%v\n",d,d) //m is uint8,10
}
4.5.2、结构体
- go语言中使用
struct来实现面向对象 - 结构体定义的时候字段之间不需要, 初始化的时候需要
type 类型名 struct {
字段名 字段类型
字段名 字段类型
...
}
类型名:结构体名称,同一个包内不能重复
字段名:结构体字段名,结构体内名称唯一
字段类型:结构体字段的具体类型
type person struct {
name string
age uint8
gender string
hobby []string //爱好
}
func main(){
var p1 person
p1.name = "小红"
p1.age = 18
p1.gender = "男"
p1.hobby = []string{"篮球","瑜伽"}
fmt.Println(p1) //{小红 18 男 [篮球 瑜伽]}
}
4.5.3、匿名结构体
func main(){
var p1 person
p1.name = "小红"
p1.age = 18
p1.gender = "男"
p1.hobby = []string{"篮球","瑜伽"}
fmt.Println(p1) //{小红 18 男 [篮球 瑜伽]}
var s1 struct{ //匿名结构体,多用于临时只用一次要使用匿名结构体,不使用type声明
name string
age int
}
s1.name = "小刚"
s1.age =20
fmt.Printf("Type: %T,value: %v\n",s1,s1) //Type: struct { name string; age int },value: {小刚 20}
}
4.5.4、值类型结构体
- 结构体本身是值类型
- new是用来为基本数据类型开辟内存,比如int,string,struct 等,返回的值是指针
- make是用来slice,map,channel,开辟内存,返回的是数据类型
- 一个结构体在内存上是连续的
type person struct {
name,gender string
age uint8
}
func f(x person) {
x.name = "小蔡"
}
func main(){
var p person
p.name = "小红"
p.gender = "女"
p.age = 18
f(p)
fmt.Println(p) //传递的是值类型,因此不会修改原值,{小红 女 18}
}
type person struct {
name,gender string
age uint8
}
func f(x *person) {
//(*x).name = "小蔡" ,上下效果一样
x.name = "小蔡" //语法糖,自动根据指针找到的变量
}
func main(){
var p person
p.name = "小红"
p.gender = "女"
p.age = 18
f(&p)
fmt.Println(p) //传递的是指针类型,因此不会修改原值,{小蔡 女 18}
}
type person struct {
name,gender string
age uint8
}
func f(x *person) {
//(*x).name = "小蔡" ,上下效果一样
x.name = "小蔡" //语法糖,自动根据指针找到的变量
}
func main(){
var p person //初始化方式1:声明变量和初始化分开
p.name = "小红"
p.gender = "女"
p.age = 18
f(&p)
fmt.Println(p) //传递的是指针类型,因此不会修改原值,{小蔡 女 18}
var p2 = new(person)
//p2.name = "小刚" //得先赋值才能看到内存地址,不然结果地址就是 &{ 0}
(*p2).name = "小刚" //正常写法应该是(*p2)只不过有语法糖,得先赋值才能看到内存地址,不然结果地址就是 &{ 0}
fmt.Printf("%T\n",p2) // *main.person
fmt.Println(p2) //&{小刚 0}
fmt.Printf("%x\n",p2) //查看内从地址,16进制表示.&{e5b08fe5889a 0}
fmt.Printf("%p\n",p2) //0xc00006c270 是p2这个变量的内存地址
a := 100
b := &a
fmt.Printf("type a:%T\t type b:%T\n",a,b) //type a:int type b:*int
fmt.Printf("address a:%p\n",&a) //address a:0xc0000100d0 a的内存地址
fmt.Printf("address a:%p\n",b) //address a:0xc0000100d0 b的值(a的内存地址)
fmt.Printf("address a:%p\n",&b) //address a:0xc000006030 b的内存地址
var p3 = person { //初始化方式2:声明变量并初始化,(推荐)
name: "小帅",
gender: "男",
age: 18,
}
fmt.Println(p3) //{小帅 男 18}
var p4 = person { //初始化方式3:列表的方式初始化,要求值得顺序要和声明struct时定义的一致
"小飞飞",
"男",
20,
}
fmt.Println(p4) //{小飞飞 男 20}
}
4.5.5、数组结构体
func main() {
type person struct {
id int
name string
score int
}
var stu = []person{ //结构体切片,结构体数组同理,map也一样(注意初始化)
{id: 0, name: "小明", score: 18}, //因为这里有多个元素,要用","一定不能少,不然会报错
{id: 0, name: "小杠", score: 20}, //不然会报错:unexpected newline, expecting comma or }
}
for i := 0; i < len(stu); i++ {
fmt.Println(stu[i].name, stu[i].score)
}
}
4.6、map字典(重点)
- go语言中提供的映射关系,其内部使用
散列表(hash)实现 - map为引用类型,必须初始化 才能使用
- 键是唯一的,value可以重复,map是无序的(每次执行获取到的顺序可能不一致)
- map的len是可以实现动态扩缩容的,可以不指定大小
- map中的key建议使用基本数据类型(int,string,..)[key必须支持==,!=等判断]不建议使用 slice/map/channel/等
初始化:
func map1(){
var m1 map[string]int
fmt.Println(m1 == nil) //true,map为引用类型,需要先使用make进行初始化
m1["小明"] = 18 //panic: assignment to entry in nil map
fmt.Println(m1)
}
func map1(){
var m1 map[string]int
fmt.Println(m1 == nil) //true
m1 = make(map[string]int,5) //容量建议规划合理,避免需要多次扩容
fmt.Println(m1 == nil) //false
m1["小明"] = 18
fmt.Println(m1) //map[小明:18]
delete(m1,"小刚刚") //如果删除了一个不存在的,则什么都不会做
fmt.Println(m1["小刚刚"]) //如果不存在,范围0或者空
v,ok := m1["小刚"] //判断值是否存在
if !ok {
fmt.Println("小刚不存在")
} else {
fmt.Println(v)
}
}
go doc builtin.delete
func s2(){
a1 := "fuck"
a2 := "dad"
a3 := "abc"
a4 := "Geook"
fmt.Println(a1,a2,a3,a4)
var s1 = make([]string,10)
s1 = append(s1,a1)
s1 = append(s1,a2)
for k,v := range s1 {
fmt.Println(k,v) //10 fuck 11 dad(0-9为s1的初始化大小),[]string在go中存储为key-value形式([int]string 数组)
}
fmt.Println(s1[10]) //fuck
fmt.Println(s1[11]) //dad
}
//根据key名称 进行排序
func rand01(){
rand.Seed(time.Now().UnixNano()) //初始化随机种子
var scoreMpa = make(map[string]int,200)
for i:=0;i<100;i++ {
key := fmt.Sprintf("stu%02d",i) //生成stu开头的字符串
value := rand.Intn(100) //生成0-99的随机整数
scoreMpa[key] = value
}
//取出map中所有的key放到切片keys中
var keys = make([]string,200)
for key := range scoreMpa{
keys = append(keys,key)
}
sort.Strings(keys) //对字符型切片进行排序
for _,key := range keys {
fmt.Println(key,scoreMpa[key])
}
}
map和slice组合:
func map2(){
//1、元素类型为map的切片
var s1 = make([]map[int]string,0,10) //对切片进行初始化,注意map并没有初始化,s1[0]表示的是s1切片的第一个元素(元素类型为map)
fmt.Println(s1[0] == nil) //true
s1[0][100] = "A"
fmt.Println(s1) // runtime error: index out of range,因为s1的第0个元素是没有的
}
func map2(){
//1、元素类型为map的切片
var s1 = make([]map[int]string,10,10)
fmt.Println(s1[0] == nil) //true
s1[0] = make(map[int]string,1) //对s1[0]初始化
fmt.Println(s1[0] == nil) //false
s1[0][100] = "A"
fmt.Println(s1) //[map[100:A] map[] map[] map[] map[] map[] map[] map[] map[] map[]]
//2、值为切片类型的map
var m1 = make(map[string][]int,10)
m1["北京"] = []int{10,20,30}
m1["上海"] = []int{11,21,31}
fmt.Println(m1) //map[北京:[10 20 30] 上海:[11 21 31]]
}
练习题1:统计中文字符个数:
func count1(){ //统计中文个数
info := "Hello 中国我爱你!"
//1、依次获取到字符串的值
sum:=0;
for _,v := range info {
//2、判断当前这个字符是不是汉字
if unicode.Is(unicode.Han,v) {
//3、统计和输出汉字
sum ++
}
}
fmt.Printf("info is: %v\nnum of 中文字符: %d\n",info,sum)
}
练习题2:统计单词出现的次数:
func count2(){ //统计"how do you do!"单词出现个数
//1、字符串按照空格切割得到切片。2、遍历切片存储到一个map。3、累加出现的次数
info := "how do you do"
m1 := strings.Split(info," ") //按照空格切割为一个切片
map1 := make(map[string]int,10)
for _,v := range m1 {
map1[v]++
}
for i,k := range map1 {
fmt.Printf("Word: \"%v\",appear %d times.\n",i,k)
}
}
func count3(){
info := "how do you do"
m1 := strings.Split(info," ")
map1 := make(map[string]int,10)
for _,v := range m1 {
//如果原来map中不存在w这个key那么出现次数为=1
if _,ok := map1[v];!ok {
map1[v] = 1
} else {
map1[v] ++
}
}
for i,k := range map1 {
fmt.Printf("Word: \"%v\",appear %d times.\n",i,k)
}
}
练习题3:回文判断:
func analyse_str1(){ //方法1和方法2都是把string放到一个[]rune中再次进行判断,只不过info2的赋值方式不太一样。
//回文:字符串从前往后和从后往前读一样,比如"上海自来水来自海上","山西运煤车煤运西山",""黄山落叶松落叶山黄,""
var corr int
info1 := "上海自来水来自海上"
info2 := []rune(info1) //中文string遍历,一定要转换为[]rune
for i:=0 ;i<len(info2)/2;i++ {
dis := len(info2)-i-1
fmt.Printf("%c==%c\n",info2[i],info2[dis])
if info2[i] != info2[dis] {
corr ++
}
}
if corr >= 1 {
fmt.Println("not a return string")
} else {
fmt.Println("ok")
}
}
func analyse_str2(){
//1、把中文字符串放到rune类型的切片中,2、
info1 := "黄山落叶松叶落山黄"
info2 := make([]rune,0,len(info1))
for _,c := range info1 {
info2 = append(info2,c)
}
for i:=0 ;i<len(info2)/2;i++ {
dis := len(info2)-i-1
fmt.Printf("%c==%c\n",info2[i],info2[dis])
if info2[i] != info2[dis] {
fmt.Println("不是回文")
return
}
}
fmt.Println("是回文")
}
func str2(){
info := "Hello"
for i:=0; i< len(info);i++ { //英文遍历
fmt.Printf("str[%d]=%c\n",i,info[i])
}
info2 := "Hello中国"
str2 := []rune(info2) //中文string遍历,注意一定要转换为[]rune
for i:=0; i< len(str2);i++ { //中文遍历
fmt.Printf("str[%d]=%c\n",i,str2[i])
}
}
4.7、内存模型
五、函数
主函数作为程序的入口,是不允许有参数的
5.1、函数定义
- 函数:一段代码的封装
- 为什么要封装为函数:为了避免代码的重复编写
- 函数返回参数可以命名也可以不命名
- return 返回值也可以命名或者不命名
- go语言中没有默认参数那个概念
- 参数划分:
- 实参:实际传递给目标函数的参数
sum(a,b) - 形参:接受参数中函数定义的参数
func sum(x,y int)(ret int)
- 实参:实际传递给目标函数的参数
func 函数名(参数)(返回值) {
函数体
}
函数名:字母、数字、下换线组成,第一个字母不能是数字,同一个包内函数名不能重复
参数:参数由参数var和参数变量类型组成,逗号分隔
返回值:返回值和返回值类型组成,也可以只写返回值的类型,多个返回值必须用()包裹,逗号分隔
func sum(x,y int)(ret int) { //有参数和返回值的函数
return x+y
}
func sum1(x,y int)(ret int) { //有参数但是没有返回值的函数
fmt.Println(x+y)
return ret
}
func sum2(){ //没有参数,没有返回值
fmt.Println("hello world")
}
func sum3()int{ //没有参数,有返回值(参数可以命名也可以不命名,本函数的返回值就没有命名)
return 3
}
//命名的返回值就相当于在函数中声明了一个变量
func sum4(x,y int)(ret int) { //ret在函数返回值中已经声明,不再需要重复在函数体中声明
ret = x + y
return //如果是return 命名的返回值(ret int)返回值可以不写(return ret)
// s1 = x + y
//return s2 //如果是return 自己定义的返回值(return s1)返回值需要写
}
//多个返回值,返回值不命名
func sum5()(int,string){
return 1,"黑马腾空"
}
//函数的输入参数类型简写
//func sum6(x int,y int)int{
//func sum6(x ,y int)int{ //同上
func sum6(x,y int,m,n string) int{
return x+y
}
//可变长参数,b可以不传递,也可以传递多个。但是必须放在函数参数的最后
func sum7(a string,b... int){
fmt.Println(a)
fmt.Println(b) //[1 2 3 4 5],b为int类型的切片
}
5.1.1、匿名函数
- 没有函数名的函数,匿名函数一般用在函数内部
- 如果要使用多次,可以使用变量保存匿名函数。如果只使用一次,在匿名函数尾部直接调用即可
- 没有名字变量
_称为匿名变量, 没有名字的函数称为匿名函数
var f1 = func(x,y int) int{ ///函数外部定义匿名函数
fmt.Println(x,y)
}
func str2(){ //命名函数str2
fmt.Println("Hello world")
func str3(){ //命名函数str3,不合法(go不允许在一个命名函数中再次声明其他的命名函数,但是可以声明匿名函数)
fmt.Println("hello world")
}
}
func main() {
// 将匿名函数保存到变量
add := func(x, y int) {
fmt.Println(x + y)
}
add(10, 20) // 通过变量调用匿名函数,参数传递方式1
//自执行函数:匿名函数定义完加()直接执行
func(x, y int) {
fmt.Println(x + y)
}(10, 20) //参数传递方式2
}
func test1(){
add := func(x,y int) int {
return x+y
}
sum:=add(10,20)
fmt.Println(sum)
sum1 := func(x,y int)int{
fmt.Println(x,y)
return x+y
}(10,20) //这里代表一次函数调用
fmt.Println(sum1)
type myFunc func(int,int) int
var f1 myFunc
f1 = sum1
sum1(2,3)
}
func test2() {
add := func(x, y int) int {
return x + y
}
type myFunc func(int, int) int
var f1 myFunc
f1 = add
tmp := f1(2, 3)
fmt.Println(tmp)
fmt.Printf("%T\t%T\n", f1, add) //main.myFunc func(int, int) int
}
5.1.2、变量作用域
- 全局变量:定义在func外部,整个运行周期内部有效,在函数内可以访问到全局变量
- 局部变量:分为两种,函数内定义的变量无法在改函数外使用
- 函数内变量查找顺序:1、先在函数内部查找。2、找不到就往函数的外面查找,一直找不到全局。
var pai float32 = 3.14
func local(){
//函数内查找变量的顺序:
pai := 12
fmt.Println(pai) //12
for i:=0;i<10;i++ {
i++
}
fmt.Println(i) //undefined: i,
}
5.1.3、函数类型和变量
- 定义函数类型:
type calculation(int,int) int(定义一个函数类型,这种函数接收2个int类型的参数并且返回一个int类型的返回值) - 简单来说,凡是满足这个条件的函数都是calculation类型的函数,
- 函数可以作为参数的类型
- 函数也可以作为返回值
func m1(){
fmt.Println("Hello world")
}
func m2() int{
return 10
}
func m3(x func() int) { //函数也可以作为参数的类型,x:函数名(函数内名称有效), func():没有入参的函数,int:函数的返回值为int
//注意m3函数只有入参,没有出参
ret := x()
fmt.Println(ret)
}
func ff(a,b int) int{
return a + b
}
//func m5(x func() int) (func(int,int )int) { //函数也可以作为返回值,m5接收一个函数(类型为:"func() int"),返回一个函数(类型为:"func(int,int )int")
func m5(x func() int) func(int,int )int { //同上
return ff
}
func main(){
a := m1
b := m2
fmt.Printf("type is %T\n",a) //type is func() ,注意:a和b是两种类型
fmt.Printf("type is %T\n",b) //type is func() int
m3(m2) //10,只有函数类型为"func() int"的函数才可以传递
f7 := m5(m2)
fmt.Printf("type is %T\n",f7) //type is func(int, int) int
}
5.1.4、内置函数
| 内置函数 | 介绍 |
|---|---|
| close | 关闭channel |
| len | 用来求长度,比如string,array,slice,map,channel |
| new | 分配内存,主要用来分配值类型,比如int,struct 返回的是指针 |
| make | 分配内存,只要用来分配引用类型,比如chan,map,slice |
| append | 用来追加元素到数组,slice中 |
| panic和recover | 用来做错误处理 |
内置函数链接: http://docs.studygolang.com/pkg/builtin/
5.1.5、递归函数(难点)
- 函数自己调用自己
- 递归一定要有一个明确的退出条件
- 永远不要高估自己
func jiecheng(n uint8)uint8 {
if n <=1 {
return 1
}
return n*jiecheng(n-1)
}
func main(){
ret := jiecheng(5)
fmt.Println(ret)
}
n个台阶,一次可以走1步,也可以走2步,有多少种走法。
int fun(int n)
{
if (1 == n)
return 1;
else if (2 == n)
return 2;
return fun(n - 1) + fun(n - 2);
}
5.2、defer(难点)
- Go语言中
defer语句将其后面跟随的语句进行延迟处理,在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后执行,最后被defer的函数,先执行 //常见用于file的关闭,socket的关闭等 - defer的执行时机:在go中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机是在返回值赋值操作后。RET执行执行前
- 函数中调用return语句底层实现:return x (执行顺序为:1、返回值=x ; 2、RET指令)
- defer语句的执行时机:return x (执行顺序为:1、返回值=x ; 2、运行defer;3、RET指令)
- 分析defer,先看return
package main
import (
"fmt"
)
func main() {
//1、defer和panic
defer fmt.Print("老王")
// panic("something error") //panic之前的defer才会执行,放在这里只会输出 “老王"
defer fmt.Print("老李")
defer fmt.Print("王小姐")
fmt.Print("Hello ")
//Hello 王小姐老李老王,后进先出的顺序执行
//2、defer 参数传递注意事项:,只有传递了命名的参数和并且defer的参数信息一致时,参数的值才会被保存在defer的栈中
fmt.Println()
a, b := 10, 20
defer func() { //defer延迟了函数的执行,虽然调用了函数,但是要在main函数return之前才会被真正调用
fmt.Println("defer: ", a, b)
}()
defer func(x, y int) {
fmt.Println("test1: ", a, b)
}(a, b)
defer func(a, b int) { //已经对函数进行了初始化
fmt.Println("test2: ", a, b)
}(a, b)
defer func(int, int) {
fmt.Println("test3: ", a, b)
}(a, b)
a, b = 1, 2
fmt.Println("main函数: ", a, b)
/*
main函数: 1 2
test3: 1 2
test2: 10 20
test1: 1 2
defer: 1 2
*/
}
注意:在defer func(x int) (y int) :只有x或者y和入参或者出参信息名称一致时,才会保存在defer的栈中,值才会被真正修改
//第一步返回值复制
//第二步真正的RET返回
//函数中如果存在defer,那么defer执行时机在第一步和第二步之间
func f1() int{
x := 5 //1、返回值赋值(函数使用的是没有命名的返回值)
defer func(){
x++ //2、修改的是x,不是返回值 ,return会将返回值先保存起来,对于无名返回值来说,保存在一个临时对象中,defer是看不到这个临时对象的
}()
return x //执行顺序:1、返回值赋值(没有命名的返回值,定义返回值为一个随机变量存储该值,return的是x(x赋值该返回值),返回值的值是5) 2、 defer 3、真正的RET指令
}
func f2() (x int){
x = 5 //1、返回值赋值(函数使用的是命名的返回值x),x就是返回值
defer func(){
x++ //2、修改的是返回值,也是x
}()
//return 5 //6
return 3 //4 执行顺序:1、return的是x==命名的返回值==3 2、defer操作x, 3、返回x
}
func f3() (y int){
x := 5 //1、返回值赋值(函数使用的不是命名的返回值y)
defer func(){
x++ //2、修改的是x,不是返回值
}()
return x //执行顺序:1、return的是x,copy x的值给y == 5 2、defer修改的是x 对y/返回值没影响 3、返回RET
}
func f4() (x int){
defer func(x int){ //函数传参改变的是副本
x++ //2、修改的是x
}(x)
return 5 //1、返回值是5 == x 2、修改x的副本 3、返回
}
func f5() (x int){
defer func(x *int){ //传参改变的是地址
*x++ //2、修改的是x
}(&x)
return 5 //1、返回值是5 == x 2、修改x 3、返回
}
func main(){
fmt.Println(f1()) //5
fmt.Println(f2()) //4
fmt.Println(f3()) //5
fmt.Println(f4()) //5
fmt.Println(f5()) //6
}
func calc(index string,a,b int)int {
ret := a+b
fmt.Println(index,a,b,ret )
return ret
}
func main(){
a := 1
b := 2
defer calc("1",a,b) // 1 1 2 3,defer会先保存环境上文(a,b)之后才存储都栈中,最后执行,保存的内容是"defer calc(index,"1",1,2)
a = 0
defer calc("2",a,b) //2 0 2 2
b = 10
}
5.3、闭包(难点)
- 闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境 //函数的二次封装
- 闭包就是一个函数捕获了和它在同一个作用域的其他常量和变量。这就意味着在闭包使用过程中该变量会被一直keep,而不会被重复初始化
- 底层原理:1、函数可以作为返回值 2、函数内部查找var的顺序(先在自己内部找,找不到外层找)
- 匿名函数的主要一个作用就是实现了闭包,所有的匿名函数都是一个闭包
func main() {
//1、因为x会被释放,所以结果一直都是1
fmt.Println(test1()) // 1,因为x会被释放
fmt.Println(test1()) //1
fmt.Println(test1()) //1
//2、使用匿名函数作为返回值
a := test2() //直接用test()进行print出来的是一个地址,需要用一个变量接收地址
fmt.Println(a()) //1
fmt.Println(a()) //2
fmt.Println(a()) //3
}
func test1() int {
var x int
x++
return x
}
func test2() func() int {
var x int
return func() int {
x++
return x
}
}
func f11(){
fmt.Println("this is f11")
}
func f22(x,y int){
fmt.Println("this is f22")
fmt.Println(x+y)
}
func f33(x func(int,int) ,m,n int) func(){ //f33接收"func(int,int)",和2个int
tmp := func(){
x(m,n)
}
return tmp
//tmp() //在外部调用
}
func main(){
ret := f33(f22,10,20)
ret()
}
func adder(x int) func(int) int{
return func(y int )int{
x += y
return x
}
}
func main(){
ret := adder(100) //ret函数可以调用外部的变量x
ret2 := ret(200)
fmt.Println(ret2) //300
}
练习1:要求实现f1(f2)
func f11(f func()){ //自己的
fmt.Println("this is f11")
f()
}
func f22(x,y int){ //别人的
fmt.Println("this is f22")
fmt.Println(x+y)
}
func f33(x,y int)func(){
tmp := func(){
fmt.Println(x,y)
}
return tmp
}
func main(){
//1、调用方法1
test := f33(10,20)
f11(test) //this is f11; 10 20
//2、调用方法2
f11(f33(10,20)) //结果同上
}
练习2:文件名添加后缀
//思路1,每一个jpg,txt定义一个函数,这样就比较累赘
//思路2,使用闭包,返回一个函数
func makeSuffix(suffix string)func(file string)string { //入参为后缀(string),出参为函数
tmp := func(file string) string { //定义"func(file string)string " 返回函数
if !strings.HasSuffix(file,suffix) {
return file + suffix
} else {
return file
}
}
return tmp
}
func main(){
jpgFunc := makeSuffix(".jpg") //创建jpg函数
txtFunc := makeSuffix(".txt") //创建txt函数
fmt.Println(jpgFunc("test"))
fmt.Println(jpgFunc("test.jpg"))
fmt.Println(txtFunc("test"))
}
练习3
func Base (base int)(func (int) int,func(int) int) {
add := func(x int) int{
base += x
return base
}
sub := func(y int) int{
base -= y
return base
}
return add,sub
}
func main(){
f1,f2 := Base(10)
fmt.Println(f1(1),f2(2)) //11(10+1),9(11-2),调用f1(1)和f2(2)修改的都是公用的base,因此会影响。每一次只有在用到的时候才会去获取外部变量 base 的值
fmt.Println(f1(3),f2(4)) //12(9+3),8(12-4)
}
5.4、fmt标准库
- fmt包实现了类似C语言printf和scanf的格式化I/O。主要分为向外输出内容和获取输入内容两大部分。
通用占位符:
| 占位符 | 说明 |
|---|---|
| %v | 值的默认格式表示,一般和fmt.Printf结合使用 |
| %+v | 类似%v,但输出结构体时会添加字段名 |
| %#v | 值的Go语法表示 |
| %T | 打印值的类型 |
| %% | 百分号 |
| %p | 打印地址 |
布尔型:
| 占位符 | 说明 |
|---|---|
| %t | true或false |
整形:
| 占位符 | 说明 |
|---|---|
| %b | 表示为二进制 |
| %c | 该值对应的unicode码值 |
| %d | 表示为十进制 |
| %o | 表示为八进制 |
| %x | 表示为十六进制,使用a-f |
| %X | 表示为十六进制,使用A-F |
| %U | 表示为Unicode格式:U+1234,等价于”U+%04X” |
| %q | 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示 |
浮点数和复数:
| 占位符 | 说明 |
|---|---|
| %b | 无小数部分,二进制指数的科学计算法,如-123456p-78 |
| %e | 科学计数法,如-12344e+78 |
| %E | 科学计数法,如-12344E+78 |
| %f | 有小数部分,但无指数部分,如123.456 |
| %F | 等价于%F |
| %g | 根据实际情况采用%e或者%f格式(以获得更简洁、准确的输出) |
| %G | 根据实际情况采用%E或者%F格式(以获得更简洁、准确的输出) |
字符串和[]byte:
| 占位符 | 说明 |
|---|---|
| %s | 直接输出字符串或者[]byte |
| %q | 该值对应的双引号括起来的go语法字符串字面值,必要时会采用安全的转义表示 |
| %x | 每个字节用两字符十六进制数表示(使用a-f) |
| %X | 每个字节用两字符十六进制数表示(使用A-F) |
宽度标识符:
| 占位符 | 说明 |
|---|---|
| %f | 默认宽度,默认精度 |
| %9f | 宽度9,默认精度 |
| %.2f | 默认宽度,精度2 |
| %9.2f | 宽度9,精度2 |
| %9.f | 宽度9,精度0 |
其他flag:
| 占位符 | 说明 |
|---|---|
| ’+’ | 总是输出数值的正负号;对%q(%+q)会生成全部是ASCII字符的输出(通过转义); |
| ’ ‘ | 对数值,正数前加空格而负数前加负号;对字符串采用%x或%X时(% x或% X)会给各打印的字节之间加空格 |
| ’-’ | 在输出右边填充空白而不是默认的左边(即从默认的右对齐切换为左对齐); |
| ’#’ | 八进制数前加0(%#o),十六进制数前加0x(%#x)或0X(%#X),指针去掉前面的0x(%#p)对%q(%#q),对%U(%#U)会输出空格和单引号括起来的go字面值; |
| ‘0’ | 使用0而不是空格填充,对于数值类型会把填充的0放在正负号后面; |
func main() { name := "令狐冲" fmt.Print("在终端打印该信息。") //不带换行 fmt.Printf("我是:%s\n", name) //格式化输出 fmt.Println("在终端打印单独一行显示") //自带换行 //在终端打印该信息。我是:令狐冲 //在终端打印单独一行显示 var m1 = make(map[string]int,10) m1["小明"] = 100 m1["小刚"] = 200 fmt.Printf("%v\n",m1) //map[小刚:200 小明:100] fmt.Printf("%#v\n",m1) //map[string]int{"小刚":200, "小明":100} fmt.Printf("%+v\n",m1) //map[小明:100 小刚:200] fmt.Printf("%v%%\n",m1["小明"]) //100% fmt.Printf("%q\n",65) // 'A' num := 123.456 fmt.Printf("%b\n",num) //8687443681197687p-46 fmt.Printf("%e\n",num) //1.234560e+02 fmt.Printf("%E\n",num) //1.234560E+02 fmt.Printf("%f\n",num) //123.456000 fmt.Printf("%F\n",num) //123.456000 fmt.Printf("%g\n",num) //123.456 fmt.Printf("%G\n",num) //123.456 fmt.Printf("%f\n",num) fmt.Printf("%9f\n",num) //新版本的9 不包括"."老版本的包括 fmt.Printf("%.2f\n",num) //宽度未知,精度为2 fmt.Printf("%9.2f\n",num) //宽度为9(带.),精度为2 fmt.Printf("%9.f\n",num) //宽度为9(不带.),精度为0 //123.456000 //123.456000 //123.46 // 123.46 // 123}
** 获取输入:**
- Go语言fmt包下有fmt.Scan、fmt.Scanf、fmt.Scanln三个函数,可以在程序运行过程中从标准输入获取用户的输入。
- fmt.Scan:函数定签名如下: func Scan(a ...interface{}) (n int, err error)
- Scan从标准输入扫描文本,读取由空白符分隔的值保存到传递给本函数的参数中,换行符视为空白符。本函数返回成功扫描的数据个数和遇到的任何错误。如果读取的数据个数比提供的参数少,会返回一个错误报告原因。
func main(){
//var s string
//fmt.Scan(&s)
//fmt.Println(s) //输入"tet for mine",输出"tet"
var (
name string
age int
class string
)
//fmt.Scanf("%s %d %s\n",&name,&age,&class)
//fmt.Println(name,age,class)
fmt.Scanln(&name,&age,&class)
fmt.Println(name,age,class)
}
5.5、分金币
/*
你有50枚金币,需要分配给以下几个人:Matthew,Sarah,Augustus,Heidi,Emilie,Peter,Giana,Adriano,Aaron,Elizabeth。
分配规则如下:
a. 名字中每包含1个'e'或'E'分1枚金币
b. 名字中每包含1个'i'或'I'分2枚金币
c. 名字中每包含1个'o'或'O'分3枚金币
d: 名字中每包含1个'u'或'U'分4枚金币
写一个程序,计算每个用户分到多少金币,以及最后剩余多少金币?
程序结构如下,请实现 ‘dispatchCoin’ 函数
*/
var (
coins = 50
users = []string{
"Matthew", "Sarah", "Augustus", "Heidi", "Emilie", "Peter", "Giana", "Adriano", "Aaron", "Elizabeth",
}
distribution = make(map[string]int, len(users))
)
func cal(v string)(num int){ //计算其应该分得的金币格式,并返回结果
num = 0
for _,v := range v {
switch v {
case 'e', 'E':
num ++
case 'i', 'I':
num += 2
case 'o', 'O':
num += 3
case 'U', 'u':
num += 4
}
}
return num
}
func dispatchCoin() (left int) {
left = coins
//var get_coin int
for _,v := range users { //1、遍历所有名字,然后初始化map(初始化后map的值为0)
get_coin := cal(v) //2、计算每个人的硬币个数(遍历每个人的名字,字符串匹配)
distribution[v] = get_coin //3、每个人分配的金币数存储到 map中
left -= get_coin //4、计算剩余的硬币个数
}
return
}
func main() {
left := dispatchCoin()
fmt.Println("剩下:", left)
for i,v := range distribution {
fmt.Printf("%v get coins: %v \n",i,v)
}
}
1、依次拿取所有人的名字
2、拿到一个人根据规则分金币
2.1、每个人的金币保存到 map中
2.2、修改剩余的金币个数
3、输出和展示
5.6、回顾
func xiaoming(name string){ //A程序员写的
fmt.Println(name)
}
func xiaolong(f func(string),name string){
f(name)
}
func low(f func()){ //B程序员写的
f()
}
//闭包示例
//本来 函数xiaoming是不能直接传递给函数low的,借助于闭包可以实现
func bibao(f func(string),name string)func(){ //入参中包含"xiaoming"类型,出参为low类型
return func(){
f(name)
}
}
func main(){
xiaolong(xiaoming,"fuckBMC")
ret := bibao(xiaoming,"小刚")
low(ret) //小刚
}
5.7、不定参传递
package main
import (
"fmt"
)
func sum2(args ...int) {
fmt.Println(args)
}
func sum(args ...int) { //可以接受0个或多个参数,如果有固定参数和不定参数组合,则必须保证不定参数在最后
sum := 0
for _, v := range args {
sum += v
}
fmt.Printf("type of args is %T\n", args) //type of args is []int
sum2(args[0], args[1], args[2]) //[6 2 4]
sum2(args[0:3]...) //[6 2 4] ...是展开的意思,同上
sum2(args...) //[6 2 4 8 5],传递切片内所有内容
}
func main() {
sum(6, 2, 4, 8, 5)
}
5.8、内存
内存相对一个可执行程序来说,主要分四个区:代码区、数据区、堆区、栈区栈:用来存储程序执行过程中函数内部定义的信息和局部变量,栈是先进后出,后进先出堆:一个很大的空间,在使用时开辟空间结束时释放数据区:初始化数据区和未初始化数据区,常量区代码区:计算机指令,只读
5.9、regex
- 相关的 有两个包:
regexp和bytes
详细说明:https://studygolang.com/pkgdoc
查找字符串/Index
func main() {
//1、包含-regexp.matchString
str1 := "hello world world ! hello world"
match, _ := regexp.MatchString("he(..)o", str1)
fmt.Println(match) //true
//2、1的增强版,regexp.Compie/regexp.matchString
r, _ := regexp.Compile("he(..)o")
fmt.Println(r.MatchString(str1)) //true;str1中是否包含"he(..)o"结果为true
//3、返回匹配的子串-输出首次匹配结果/索引;r.FindString| r.FindStringIndex
tmp := r.FindString(str1)
fmt.Println(tmp) //返回子串, hello
fmt.Println(string(r.Find([]byte(str1)))) //hello ,同上
//4、返回所有匹配的字串-r.FindAllString //FindAllString和FindAllStringSubmatch 用的多
str2 := "abc cde fgh acm ask answer prequest"
r2, _ := regexp.Compile("a.")
tmp2 := r2.FindAllString(str2, -1)
fmt.Println(tmp2) //[ab ac as an]
tmp3 := r2.FindAllStringSubmatch(str2, -1)
fmt.Println(tmp3) //[[ab] [ac] [as] [an]]
tmp4 := r2.FindAllSubmatch([]byte(str2), -1)
fmt.Println(tmp4) //[[[97 98]] [[97 99]] [[97 115]] [[97 110]]]
}
替换
func main() {
str := "abc cde fgh acm ask answer prequest"
r, _ := regexp.Compile("a.")
// 1、替换字符串-r.ReplaceAllString
tmp := r.ReplaceAllString(str, "a#")
fmt.Println(tmp) //a#c cde fgh a#m a#k a#swer prequest
//2、 `Func`变量可以让你将所有匹配的字符串都经过该函数处理
tmp1 := r.ReplaceAllFunc([]byte(str), bytes.ToUpper) //注意这里不能写函数bytes.ToUpper(),因为不执行函数
fmt.Println(string(tmp1)) //ABc cde fgh ACm ASk ANswer prequest
}
func main() {
//1、findReaderIndex 返回第一个匹配的index的起始位置
str := "hello welcome to china,china is good,welcome !"
b := bytes.NewReader([]byte(str))
reg := regexp.MustCompile(`\w+`) // \w == [0-9A-Za-z_]
fmt.Println(reg.FindReaderIndex(b)) //[0 5]对应 hello的起始位置和结束位置(不包含)
//2、Expand分组匹配
reg = regexp.MustCompile(`(\w+),(\w+)`)
src := []byte("Golang,World!") // 源文本
dst := []byte("Say: ") // 目标文本
template := []byte("Hello $1, Hello $2") // 模板
m := reg.FindSubmatchIndex(src) // 解析源文本
// 填写模板,并将模板追加到目标文本中
fmt.Printf("%q", reg.Expand(dst, template, src, m)) //"Say: Hello Golang, Hello World"
}
Split() SplitAfter() SplitAfterN()
func main() {
str := "1,2,3,4,5"
tmp := strings.Split(str, ",")
fmt.Println(tmp) //[1 2 3 4 5]
tmp = strings.SplitAfter(str, ",")
fmt.Println(tmp) //[1, 2, 3, 4, 5]
tmp = strings.SplitAfterN(str, ",", 3)
fmt.Println(tmp, len(tmp)) //[1, 2, 3,4,5] 3 ;对'1,'和'2,'进行了切分,后面的是一块
}
六、结构体-方法和接收者
面向对象概念:
对象:一个实体类:对象具有的属性和方法,模板。go中没有类,可以把结构体当作类使用,类还可以用来实现继承,但是go不支持继承,可以用匿名字段来实现这些特性,但是并不是继承属性:结构体的字段方法:结构体方法
6.1、构造函数
- 返回一个结构体变量的函数,可以理解为构造结构体对象
- go面向接口编程语言,面向对象、面向过程
- 构造函数约定使用new开头
type person struct {
name string
age int
}
//要返回的值结构体值还是结构体指针。当结构体比较大的时候尽量使用结构体指针,减少程序的内存开销
//使用结构体值返回,需要复制原有的结构体开销较大
func newPerson(name string,age int )person {
//func newPerson(name string,age int ) *person {
// return &person{
return person{
name,
18,
}
}
func main(){
p1 := newPerson("小红",18)
p2 := newPerson("小刚",20)
fmt.Println(p1,p2)
}
6.2、方法和接收者
- go语言中
方法(method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(reciever)。接收者的概念就类似于其他语言中的this或者self - 方法可以理解为 面向对象的 对象的属性,比如狗是一个对象,狗的一个方法(属性) 是 狗叫
- 标识符:具有特殊函数的字符,比如类型名、变量名、方法名、函数名
- 什么时候应该使用指针接收者:1、需要修改接收者中的值 2、接收者是拷贝代价较大的对象时 3、保证一致性,如果有某个方法使用了指针接收者,那么其他的方法也要使用指针接收
- 接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。但是基本类型要使用别名才能添加方法
func (接收者变量 接收者类型) 方法名 (参数列表) (返回参数) { 函数体}接收者变量:接收者中的参数变量名在命名时,官方建议使用接收者类型名的第一个小写字母,例如Person类型的接收者变量应该命名为p,Connector类型的接收者变量命名c等接收者类型:接收者类型和参数类似,可以是指针类型也可以是非指针类型方法名、参数列表、返回参数:具体格式与函数定义相同
type dog struct {
name string
}
type person struct {
name string
age uint8
}
func (d dog) wangwang(){ //方法是作用于特定类型的函数,只能是dog类型的才能调用改方法
fmt.Println("汪汪汪...")
}
func (p person) newyear(){ //传递的是值类型,因此不会修改源值
p.age ++
}
func (p *person) newyear2(){ //传递的是指针类型,因此会修改源值
p.age ++
}
type myInt int //给基本类型添加别名后,才可以使用方法(因为不能给别的包里面的类型添加方法,只能给自己的包内部添加方法,除非使用别名)
func (m myInt)hello(){
fmt.Println("hello")
}
func main(){
var az = dog{
"旺财",
}
az.wangwang() //调用az的方法dog
var a1 = person {
"小工",
18,
}
fmt.Println(a1.age) //18
a1.newyear()
fmt.Println(a1.age) //18
a1.newyear2()
fmt.Println(a1.age) //19
m := myInt(8)
m.hello()
}
6.3、结构体遇到的问题
type myInt int
type person struct {
name string
age uint8
}
//问题3:为什么需要构造函数 ,构造函数定义:调用改函数,返回一个对应类型的变量,或者面向对象的实例。
//要返回一个person类型,person需要2个字段,name和age;person函数的作用:谁调用我,我返回一个person类型的变量给对方
func newPerson(x string,y age) person{
return person{
x,
y,
}
}
func newPerson2(x string,y age) *person{
return &person{
x,
y,
}
}
func main(){
//问题1:myInt(100)是什么?myInt是一个类型, 声明一个myInt类型的值
m := myInt(100)
//赋值写法1:var x int32 ; x = 100
//赋值写法2:var x int32 = 10
//赋值写法3:x := int32(10)
//写法3延伸:x := 10 //此写法和3写法一样,只不过使用了类型推导,注意这里默认推导为int类型,非int32
//问题2:结构体初始化
var p person //初始化方法1:独立赋值
p.name = "元帅"
p.age = 18
var p2 = person { //初始化方法2 key-value形式
name: "王子",
age:18,
}
var p3 = person { //初始化方法3 自动初始化方式,按照顺序填写
"王子",
18,
}
var s2 = []int{1,2,3,4} //切片初始化方法1:
var s1 = []int{ //切片初始化方法2: 值列表初始化 不带key
1,
2,
3,
4,
}
var s3 = []int{ //切片初始化方法3: key-value方式(索引-值)
0:1,
1:2,
2:3,
3:4,
}
fmt.Println(s1,s2,s3,p,p2,p3,m)
}
6.4、学生管理系统
- 函数基础版
package main
import (
"fmt"
"os"
)
/*
函数版学生管理系统,能够查看\新增\删除 学生
学生是对象:单个学生(name,id),所有学生使用map组织起来
*/
type student struct {
id int64
name string
}
var (
allstu map[int64]*student //变量声明
)
func check() {
for k,v := range allstu {
fmt.Printf("学号:%d,姓名:%s\n",k,v.name)
}
}
//newstudent返回的是指针
func newStudent(id int64,name string) *student{
return &student{
id,
name,
}
}
//结构体和方法结合,返回一个对象
func add() {
//向allstu中添加一个学生
//1、创建一个新学生, 判断id是否存在,不存在则添加
var (
id int64
name string
)
fmt.Print("请输出学生的学号:")
fmt.Scanln(&id)
fmt.Print("请输出学生的名字:")
fmt.Scanln(&name)
//2、追加到allstu中(调用构造函数)
newStu := newStudent(id,name)
allstu[id] = newStu //id当做map的 key,newStu当做map的value
fmt.Printf("%v\n",allstu)
}
func del() {
var deleteID int64
fmt.Print("请输出你要删除的学生的学号:")
//判断id是否存在,存在则删除,不存在则返回提示信息
fmt.Scanln(&deleteID) //这里是取地址
delete(allstu,deleteID)
}
func main(){
allstu = make(map[int64]*student,50) //初始化内存空间,如果这里使用:= 就相当于使用了一个新的var ,如果使用 = 相当于引用全局的allstu
for { //4、支持循环操作
//1、打印菜单,系统支持的操作
fmt.Printf("Welcome to 学生管理系统 !")
fmt.Println(`
1、查看所有学生
2、新增学生
3、删除学生
4、退出
`)
//2、等待用户选择对应的操作
fmt.Print("请输入你要干啥:")
var choice int
fmt.Scanln(&choice)
//3、执行对应的函数
switch choice {
case 1:
check()
case 2:
add()
case 3:
del()
case 4:
os.Exit(0) //退出
default:
fmt.Print("Unknown options...")
}
}
}
6.5、结构体的匿名字段
- 结构体允许其成员在声明时没有字段而只有类型,这种没有名字的字段成为匿名字段 (没有名字的字段)
type person struct { //匿名结构体,不常用
int
string
}
func main(){
p1 := person{
18,
"小刚",
}
fmt.Println(p1) //{18 小刚}
fmt.Println(p1.string) //小刚 ,问题:如果person对象有其他的int字段,该怎么引用?
}
6.6、嵌套的结构体
type address struct {
province string
city string
}
type person struct { //匿名结构体,不常用
name string
age int
addr address
}
type company struct{
name string
addr address
}
func main(){
p1 := person{
name: "小刚",
age:18,
addr:address{
province:"河南",
city:"郑州",
},
}
fmt.Println(p1) //{小刚 18 {河南 郑州}}
fmt.Println(p1.addr.province) //河南
//fmt.Println(p1.province) //直接访问city是访问不到的,因此可以使用匿名嵌套的方式实现
}
type address struct {
province string
city string
}
type workPlace struct { //工作地
province string
city string
}
type person struct {
name string
age int
address //匿名嵌套
//workPlace //如果嵌套多个结构体,且存在重复的字段,不建议使用匿名嵌套结构体
}
type company struct{
name string
addr address //命名嵌套,有名字
}
func main(){
p1 := person{
name: "小刚",
age:18,
address:address{
"河南",
"郑州",
},
}
fmt.Println(p1) //{小刚 18 {河南 郑州}}
fmt.Println(p1.province) //河南,使用匿名嵌套就不用了再使用p1.address.province
//先在自己结构体内找改字段,找不到就去匿名的结构体中查找该字段。如果嵌套多个结构体,且存在重复的字段,不建议使用匿名嵌套结构体
}
6.7、模拟实现继承-方法
- go语言中没有继承的概念。Go语言中使用结构体也可以实现其他编程语言中的面向对象的继承
package main
import (
"fmt"
)
type person struct { //父类
id int
name string
age int
}
type student struct { //子类
person //结构体嵌套,实现继承,person为匿名字段,没有结构体名称只有类型
score int
}
func newPerson(name string, age int) person {
return person{
0,
name,
age,
}
}
func (p person) move() {
fmt.Println(p.name, "会跑步")
}
func (s student) exam() {
fmt.Println(s.name, "学生会考试")
}
func (s student) move() { //和父类拥有同样的方法 move
fmt.Println(s.name, "新的方法-会散步")
}
func (p person) printInfo1() {
fmt.Printf("%p, %v\n", &p, p)
}
func (p *person) printInfo2() {
fmt.Printf("%p, %v\n", p, *p)
}
func main() {
//1、初始化注意写法,stu1,stu2,stu3可以理解为一个对象
var stu1 = student{
person: person{ //这里必须这样写,否则会报错: "field:value and value initializers"
id: 1,
name: "令狐冲",
age: 28,
},
score: 98,
}
stu2 := student{person{1, "欧阳锋", 30}, 2} //自动推到类型初始化
stu4 := student{score: 20} //只初始化部分,没有初始化的部分使用默认值
var stu3 = student{person: person{1, "欧阳锋", 30}, score: 2}
//2、使用构造函数初始化
fmt.Println(stu1, stu2, stu3, stu4)
v := newPerson("方丈", 20)
v.id = 0
fmt.Println(v)
//3、属性和方法继承
p1 := person{name: "风清扬", id: 0, age: 88}
p1.move() //风清扬只会跑步,不会考试
fmt.Println(stu2.name) //属性继承
stu2.move() //欧阳锋 即会跑步也会考试,方法继承
stu2.exam() //方法继承
//4、方法重写
p2 := student{person: person{name: "段誉", id: 0, age: 88}, score: 100}
p2.move() // 出现子方法和父方法重名的时候,优先使用子方法。这就叫方法重写
//5、方法值和方法表达式。方法也是可以进行赋值和传递的,根据调用者的不通,方法分为两种形式:方法值和方法表达式
//方法值需要绑定实例,方法表达式需要显示传参
p3 := person{1, "逍遥子", 89}
pfunc1 := p3.printInfo1 //方法值,隐式传递,不传递接收者p3,就可以打印出p3对象的属性
pfunc1() //0xc0000044e0, {1 逍遥子 89},等同于 p3.printInfo1()
pfunc2 := p3.printInfo2 //0xc000004520, {1 逍遥子 89}
pfunc2()
pfunc3 := person.printInfo1 //方法表达式,需要进行显式传参
pfunc3(p3) //0xc000004560, {1 逍遥子 89}
// pfunc4 := person.printInfo2 //invalid method expression person.printInfo2 (needs pointer receiver: (*person).printInfo2)
pfunc4 := (*person).printInfo2 //因为 printInfo2接受的指针类型
pfunc4(&p3) //0xc0000044c0, {1 逍遥子 89}
fmt.Printf("%T\t%T\t%T\t%T\n", pfunc1, pfunc2, pfunc3, pfunc4) //func() func() func(main.person) func(*main.person)
}
6.8、结构体回顾
- 基本数据类型只能保存单个数据类型,编程是用来解决现实生活中的实际问题。使用基本数据类型解决现实生活中的问题有局限,因此出现了结构体
- 凡是
type开头的都是新增了一个类型 - 匿名结构体:多用于临时场景,一个结构体仅使用一次场景 ,相对的是命名结构体
var a = struct { x int y int }{10,20}
- 结构体初始化:1、方法1 p1.age= p1.name= 2、方法2 p2 := person{ name:"小红",age:18} 3、方法3 只写value的形式,p2 := person
- 构造函数,构造结构体变量的函数
func newPerson(nmae string,age int) person {...}约定是new开头 - 方法:有接收者的函数,接收者指的是哪个类型的变量可以调用这个函数
func (p person) dream() {...}p是接收者,建议使用对应类型的首字母小写 - 方法:指定了接收者后,只有接收者这个类型的变量可以调用它
type person struct {
name string
age int
}
func (p person) dram(str string) {
fmt.Printf("%s的梦想是%s",p.name,str)
}
- 结构体是值类型,引用类型存放的是内存地址
- 方法也可以传递指针,当在方法需要修改结构体的值时候需要使用指针,或者结构体本身值较大时copy开销较大时,保持一致性:如果有一个方法使用了指针接收者,其他的方法为了统一也要使用指针接收者
func (p *person) guonian(){ p.age ++ }
- 结构体的嵌套
- 结构体的匿名字段
- JSON序列化与反序列化,经常出现的问题:1、结构体内部的字段首字母要大写,不然别人访问不到
- 自定义类型和类型别名
type myInt int //自定义类型
type newint = int //类型别名,只在代码编译过程中有效,编译后不存在,内置的byte和rune都是类型别名
6.9、结构体和json互转
- json:java script的对象表示法
- 把Go语言中的结构体变量-- >json 格式的字符串
- json格式的字符串 --> Go语言中能够识别的结构体变量
/把Go语言中的结构体变量-- >json 格式的字符串 序列化
//json格式的字符串 --> Go语言中能够识别的结构体变量 反序列化
type person struct {
Name string
Age int
}
func main(){
p1 := person{
Name:"小刚",
Age:18,
}
b,err := json.Marshal(p1)
if err != nil {
fmt.Printf("marsha1: err:%v\n",err)
}
//fmt.Println(string(b)) //{} 使用首字母小写的age,name 因为 json是在其他package中的,因此无法直接获取到var的值
fmt.Println(string(b)) //{"Name":"小刚","Age":18} 修改为Age,Name后;
}
type person struct {
Name string `json:"name" db:"name" ini:"name"` //使用json解析的时候使用name
Age int
}
func main(){
p1 := person{
Name:"小刚",
Age:18,
}
b,err := json.Marshal(p1)
if err != nil {
fmt.Printf("marsha1: err:%v\n",err)
}
fmt.Printf("%#v\n",string(b)) //变成了小写"{\"name\":\"小刚\",\"Age\":18}"
str := `{"name":"理想","age":18}`
var p2 person
json.Unmarshal([]byte(str),&p2) //传递指针为了能够修改p2的指针
fmt.Printf("%#v\n",p2) //main.person{Name:"理想", Age:18}
}
- JSON序列化与反序列化,经常出现的问题:1、结构体内部的字段首字母要大写,不然别人访问不到
type point struct{
X int `json:"x"` //如果使用json包处理的话,修改名字为x
Y int //x和y需要大写,json包才能读取到该var
}
p1 := point{100,200}
b,err := json.Marshal(p1) //go语言通常把err返回,并且放在最后一个参数
if err != nil {
fmt.Printf("something error : %s\name",err )
}
fmt.Println(string(b))
//反序列化:由字符串->Go中的结构体变量
str1 = `{"x":100,"Y":200}`
var po2 point //创造一个结构体变量,准备接收反序列化值
err = json.Unmarshal([]byte(str1),&po2) //str1反序列化后赋值为po2
if err != nil {
fmt.Printf("something error : %s\name",err )
}
fmt.Println(po2)
type point struct{
X int `json:"xx"` //如果使用json包处理的话,修改名字为x
Y int //x和y需要大写,json包才能读取到该var
}
func main(){
p1 := point{100,200}
b,err := json.Marshal(p1) //go语言通常把err返回,并且放在最后一个参数
if err != nil {
fmt.Printf("something error : %s\name",err )
}
fmt.Println(string(b))
//反序列化:由字符串->Go中的结构体变量
str1 := `{"xx":100,"Y":200}` //{"xx":100,"Y":200}
var po2 point //创造一个结构体变量,准备接收反序列化值
err = json.Unmarshal([]byte(str1),&po2) //str1反序列化后赋值为po2
if err != nil {
fmt.Printf("something error : %s\name",err )
}
fmt.Println(po2) //{100 200}
}
6.10、学生管理系统-函数版
//main.go ,注意运行go build 整个目录
package main
import (
"fmt"
"os"
)
func showMenu(){
fmt.Println("welcome to sms !.")
fmt.Println(`
1、查看所有学生
2、添加学生
3、修改学生
4、删除学生
5、退出
`)
}
var smr stuMGR //声明一个全局的学生管理对象
func main(){
smr = stuMGR{ //修改的是全局变量的值,map注意需要初始化才能用
allStudent:make(map[int64]student,100),
}
for {
showMenu()
fmt.Print("请输出您的选择: ")
var choice int
fmt.Scanln(&choice)
switch choice {
case 1:
smr.check()
case 2:
smr.add()
case 3:
smr.modify()
case 4:
smr.del()
case 5:
os.Exit(0)
default:
fmt.Println("Unknown options: ",choice)
}
}
}
//student.go
package main
import "fmt"
//1、定义单个学生对象
type student struct {
id int64
name string
}
//2、一个对象存储和管理所有学生
type stuMGR struct {
allStudent map[int64]student
}
//3、对象的增加方法
func (s stuMGR) add(){
var (
id int64
name string
)
fmt.Print("请输入你要添加的学生id: ")
fmt.Scanln(&id)
fmt.Print("请输入你要添加的学生姓名: ")
fmt.Scanln(&name)
newStu := student{ //多层结构体(结构体嵌套)建议先实现底层结构体
id:id,
name:name,
}
s.allStudent[newStu.id] = newStu
//方法2
// _,ok := s.allStu[id]
// if ok {
// fmt.Printf("ID: %v is exit..\n",id)
// } else {
// newStu := student{
// id,
// name,
// }
// s.allStu[newStu.id] = newStu
// }
}
//4、对象的查看方法
func (s stuMGR) check(){
for _,v := range s.allStudent {
fmt.Printf("学号: %v 姓名: %v\n",v.id,v.name)
}
}
//5、对象的删除方法
func (s stuMGR) del(){
var id int64
fmt.Print("请输出你要删除的学生id: ")
fmt.Scanln(&id)
value,ok := s.allStudent[id] //删除前先查询,注意查询方法
if !ok {
fmt.Println("没有这个学生: ",value)
return
}
delete(s.allStudent,id)
}
//6、对象的修改方法
func (s stuMGR) modify(){
//获取用户输入的学号
var (
id int64
name string
)
fmt.Print("请输入要修改的学生id: ")
fmt.Scanln(&id)
//展示该学号对应的学生信息,如果没有提示查无此人
value,ok := s.allStudent[id] //如果key不存在,则为对应类型的空值,并非nil
if !ok {
fmt.Println("没有此用户")
} else {
fmt.Printf("要修改的学生信息:\"学号:%v 姓名:%v\"\n",id,value)
}
fmt.Print("请输入修改后的学生姓名: ")
fmt.Scanln(&name)
//请输入修改后的学生名
//更新学生名称
//newStu := student{ //修改方式1
// id:id,
// name:name,
//}
//s.allStudent[id] = newStu //建议先实现底层student类型,然后再对上层allStudent进行赋值
//或者使用如下方法
value.name = name //修改方式2
s.allStudent[id] = value
}
方式2:
package main
//学生管理系统
//1、定义一个学生结构体,定义学生对象
//2、一个对象存储和管理所有学生
//3、实现2对象的 "增删查"这些方法
// 这个对象有三个功能,对应结构体的方法 。注意学生是不能删除自己的。因此有了学生管理者,由他去实现"增删查"这些方法
import (
"fmt"
"os"
)
//1)定义一个学生的对象
type student struct {
id int
name string
score uint8
}
//2)定义一个全局的字典,存储所有的学生信息,也可以定义一个结构体包含student struct存储全局信息
type stuAdmin map[int]student
//3)全局字典初始化,初始化一个示例
var Admin = make(stuAdmin, 0)
func (s stuAdmin) check() {
fmt.Println()
for k, _ := range Admin {
fmt.Printf("-->[%d]\t学号:%d\t姓名:%v\t分数:%d\n", k, Admin[k].id, Admin[k].name, Admin[k].score)
}
}
func showMenu() {
fmt.Println("Welcome to student Administration web site !.")
fmt.Println(`
1、查看所有学生
2、添加学生
3、修改学生
4、删除学生
5、退出
`)
}
func (s stuAdmin) add() {
var id int
var stu student
fmt.Print("请输入学生ID:")
fmt.Scanln(&id)
for k, _ := range Admin {
if Admin[k].id == id {
fmt.Println("ID is exist !")
return
}
}
stu.id = id
fmt.Print("请输入学生姓名:")
fmt.Scanln(&(stu.name))
fmt.Print("请输入学生分数:")
fmt.Scanln(&(stu.score))
Admin[id] = stu
}
func (s stuAdmin) modify() {
var id, sc int
var stu student
fmt.Print("请输入要修改的学生ID:")
fmt.Scanln(&id)
_, ok := Admin[id]
if !ok {
fmt.Println("ID is not exist !")
return
}
fmt.Print("请输入学生分数:")
fmt.Scanln(&sc)
stu = student{id, Admin[id].name, uint8(sc)}
Admin[id] = stu
}
func (s stuAdmin) del() {
var id int
fmt.Print("请输入要修改的学生ID:")
fmt.Scanln(&id)
_, ok := Admin[id]
if !ok {
fmt.Println("ID is not exist !")
return
}
delete(Admin, id)
}
func main() {
showMenu()
for {
var id int
fmt.Print("请输入你的选择: ")
fmt.Scanln(&id)
switch id {
case 1:
Admin.check()
case 2:
Admin.add()
case 3:
Admin.modify()
case 4:
Admin.del()
case 5:
fmt.Println("下次再见...")
os.Exit(0)
default:
showMenu()
}
}
}
七、接口
7.1、接口定义
- 数据类型:基本数据类型、结构体
- 接口是一种类型,它约束了变量有哪些方法
- 在编程中会遇到以下场景。我不关心变量是什么类型,我只关心能调用它的什么方法
- 举例:我不管你用银联、支付宝、微信 什么支付。只要能支付就行
- 个人理解:结构体定义了对象的属性信息,方法定义了对象的功能,而接口定义了特定属性的类别
- 接口定义:
type 接口名 interface {
方法名1(arg1,arg2,....) (返回值1,返回值2,...)
方法名2(arg1,arg2,....) (返回值1,返回值2,...)
...
}
- 作用:用来给变量\参数\返回值 等设置类型
- 接口的实现:一个变量,如果实现了规定中所有的方法,那么这个变量就实现了这个接口,可以称为这个接口类型的变量
- 不管 黑猫/白猫/狗 只要能抓老鼠就好。interface就是抽象出来能够抓老鼠的这一类对象
- 抽象出来后,可以进行初始化为特定的实例,在函数入口层面可以统一为一个
//引出接口
type cat struct {}
type dog struct {}
//对象猫(struct)有一个方法(属性) speak
func (c cat) speak() {
fmt.Println("喵喵")
}
//对象狗(struct)有一个方法(属性) speak
func (d dog) speak() {
fmt.Println("汪汪汪")
}
//da函数实现,传递什么就打什么对象,然后改对象执行speak。比如传递dog,就执行dog.speak
func da (x $类型) { //这个x应该是什么类型呢?,类型为dog|cat都只能实现单个类型,显然无法满足需求。
x.speak
}
func main(){
}
``` go
//1、对象定义:定义结构体和结构体对应的方法 2、接口定义:定义接口的方法 3、接口使用:创建函数传参类型为接口
//4、结构体对象实例化 5、调用接口对应的函数
type dog struct {
name string
}
type cat struct {
name string
}
func (d dog) speak() { //狗有方法:speak
fmt.Println("旺财")
}
func (c cat) speak() { //猫有方法:speak
fmt.Println("喵喵")
}
type speaker interface { //对拥有 speak方法的 这一类 进行抽象抽象为speaker interface
speak() //只要实现了speak方法,都可以是speaker类型interface,方法式一种特殊的函数,函数调用涉及传参,因此要使用speak(),方法签名
}
func test(x speaker) { //抽象出来的speaker class进行测试;传递接口
x.speak()
}
func main() {
var dog1 dog //dog和cat都是一个对象,需要初始化后才可以使用
test(dog1)
var cat1 = cat{ //对象初始化,也可不初始化
name: "波斯猫",
}
test(cat1)
}
package main
import "fmt"
//1、创建父类
type operator struct {
num1 int
num2 int
}
//2、加法子类
type Add struct {
operator
}
func (a Add) result() int { //加法子类-方法
return a.num1 + a.num2
}
//3、减法子类
type Sub struct {
operator
}
func (a Sub) result() int { //减法子类-方法
return a.num1 - a.num2
}
//7、接口,接口规定了要做哪些事情,但是接口本身不做任何事情,类似于k8s的cni规范,USB接口(可以接入键盘/鼠标/U盘等)
//一般接口是先定义,然后根据接口实现功能,这里的顺序有区别
type animal interface {
result() int //接口需要实现的方法
}
func main() {
//4、如果要使用,加法就需要创建一个加法对象,如果要使用减法对应也要创建一个减法对象。
var a Add
a.num1 = 10
a.num2 = 20
v := a.result()
fmt.Println(v)
//5、创建减法对象
tmp := operator{
num1: 10,
num2: 3,
}
s := Sub{tmp}
v = s.result()
fmt.Println(v)
//这样就比较繁琐,如果由前期的减法改为使用后期的加法,改动量就比较大
//6、升级版
var p animal
var p1 = Add{tmp}
var p2 = Sub{tmp}
p = p1
r := p.result()
fmt.Println(r)
p = p2
r := p.result()
fmt.Println(r)
}
7.2、接口的类型
package main
import "fmt"
type animal interface {
move()
eat(string)
}
type cat struct{
name string
feets int8
}
type chicken struct{
feets int8
}
func (m cat) move(){
fmt.Println("走猫步")
}
func (c chicken) move(){
fmt.Println("小鸡动")
}
func (m cat) eat(sm string){
fmt.Printf("猫吃: %s\n",sm)
}
func (c chicken) eat(sm string){
fmt.Printf("鸡吃: %s\n",sm)
}
func main(){
var a1 animal
bc := cat{
name:"鱼",
feets:4,
}
fmt.Printf("a1的类型:%T\n",a1) //a1的类型:<nil>
a1 = bc //可以直接这样传递
fmt.Printf("a1的类型:%T\n",a1) //a1的类型:main.cat
fmt.Println(a1) //{鱼 4} 对象的属性,下面是对象的方法
a1.eat("小虾") //猫吃: 小虾
a1.move() //走猫步
kfc := chicken{
feets:8,
}
a1 = kfc
fmt.Printf("a1的类型:%T\n",a1) //a1的类型:main.chicken
//接口类型的变量存储分为2部分:一部分为动态类型 存储类型(%T),一部分为动态值 存储值(对象的属性),初始值的动态类型和动态值都是nil
}
7.3、值接收者和指针接收者实现接口的区别
- 使用值接收者和指针接收者的区别:
- 使用值接收者实现接口的所有方法可以接收指针和值,但是使用指针接收者实现接口的所有方法只能使用指针
# 使用值接收者实现接口的所有方法
type animal interface {
move()
eat(string)
}
type cat struct{
name string
feets int8
}
//方法使用值接收者实现了接口的所有方法
func (m cat) move(){
fmt.Println("走猫步")
}
func (m cat) eat(sm string){
fmt.Printf("猫吃: %s\n",sm)
}
func main(){
var a1 animal
c1 := cat{name:"tom",feets:2}
c2 := &cat{name:"假老练",feets:2}
a1 = c1
fmt.Println(a1) //{tom 2}
a1 = c2
fmt.Println(a1) //&{假老练 2}
}
# 使用指针接收者实现了接口的所有方法
type animal interface {
move()
eat(string)
}
type cat struct{
name string
feets int8
}
//使用指针接收者实现了接口的所有方法
func (m *cat) move(){
fmt.Println("走猫步")
}
func (m *cat) eat(sm string){
fmt.Printf("猫吃: %s\n",sm)
}
func main(){
var a1 animal
c1 := cat{name:"tom",feets:2}
c2 := &cat{name:"假老练",feets:2}
//a1 = c1 //这里报错,实现animal这个接口的是cat的指针类型,因此要用指针
a1 = &c1 //
fmt.Println(a1) //&{tom 2}
a1 = c2
fmt.Println(a1) //&{假老练 2}
}
7.4、接口和类型的关系以及接口嵌套
- 多个类型可以实现一个接口 //cat和dog都可以实现 animal接口
- 一个类型可以实现多个接口 //
- 接口是可以嵌套的
一个类型可以实现多个接口
type eater interface {
eat(string)
}
type mover interface {
move()
}
type cat struct{
name string
feets int8
}
//cat实现了mover接口和eater接口
func (m cat) move(){
fmt.Println("走猫步")
}
func (m cat) eat(sm string){
fmt.Printf("猫吃: %s\n",sm)
}
func main(){
var a1 eater
var a2 mover
c1 := cat{name:"tom",feets:2}
a1 = c1
a2 = c1
fmt.Println(a1,a2) //{tom 2} {tom 2}
a1.eat("狗粮") //猫吃: 狗粮
a2.move() //走猫步
}
type animal interface { //接口嵌套
mover
eater
}
//type animal interface { //效果同上
// move()
// eat(string)
//}
type eater interface {
eat(string)
}
type mover interface {
move()
}
type cat struct{
name string
feets int8
}
//cat实现了mover接口和eater接口
func (m cat) move(){
fmt.Println("走猫步")
}
func (m cat) eat(sm string){
fmt.Printf("猫吃: %s\n",sm)
}
func main(){
var a1 eater
var a2 mover
c1 := cat{name:"tom",feets:2}
a1 = c1
a2 = c1
fmt.Println(a1,a2) //{tom 2} {tom 2}
a1.eat("狗粮") //猫吃: 狗粮
a2.move() //走猫步
}
7.5、空接口
- 接口定义:如果一个变量实现了接口中定义的所有方法,那么这个变量就实现了这个接口。如果这个接口中什么方法都没有。表示任何类型都实现了这个接口
- 空接口,没有必要起名字,通常定义成如下:
interface {} - 所有的类型都实现了空接口,也就是任意类型的变量都能保存到空接口中
- 空接口的类型,可以是任意数据类型,接受任意类型的数据
type xx interfacee {
}
func show(a interface{}) { //空接口主要用法1:作为函数的参数
fmt.Printf("类型: %T\n",a)
}
func main(){
//var m1 map[string]interface 注意:interface是关键字,interface{}才是空接口
var m1 map[string]interface{} //空接口主要用法2:作为map的value的类型
m1 = make(map[string]interface{},16)
m1["age"] = 18
m1["name"] = "小王"
m1["married"] = true
m1["hobby"] = [...]string{"唱歌","跳舞","吹牛逼"} //数组类型
fmt.Println(m1)
fmt.Println(m1) //当不知道要保存什么类型的时候,可以使用空接口
//map[hobby:[唱歌 跳舞 吹牛逼] age:18 married:true name:小王]
//map[married:true name:小王 age:18 hobby:[唱歌 跳舞 吹牛逼]]
show(false) //类型: bool
show(nil) //类型: <nil>
show(m1) //类型: map[string]interface {}
}
func s1(msg string,a ...interface{}){
m := fmt.Sprintf(msg,a...) //方法签名:func Sprintf(format string, a ...interface{}) string {
//第一个是格式,第二个是空接口,可以传递任意类型
fmt.Println(m) //我今年:16岁,我想说fuck you
}
func main(){
s1("我今年:%d岁,我想说%s\n",16,"fuck you")
}
7.6、空接口类型断言(猜)
- 空接口可以存储任意类型的值,那我们如何获取其存储的具体数据呢?
- 接口的变量存储分为2部分,动态类型和动态值(初始值都是nil)
- 想要判断空接口的值这个时候可以使用类型断言:
x.(T)x表示类型为interface{}的值,T表示断言 x可能是的类型 - 该语法返回2个参数,第一个是
x转换为T类型后的变量,第二个值是bool值,如果true表示断言成功,false表示失败 - 类型断言:我想指导空接口中接收的具体的值是什么
- 关于接口的注意事项:只有当2个或者2个以上的具体类型必须以相同的方式进行处理时才需要定义接口。不要为了接口而写接口。那样会增加不必要的抽象。导致不必要的运行时损耗
func test(a interface{}) {
fmt.Printf("类型:%T\n",a)
v,ok := a.(string)
if !ok {
fmt.Println("判断错误")
} else {
fmt.Println(v)
}
}
func main(){
test(1000) //判断错误
test("中国") //中国
}
package main
import "fmt"
func test(a interface{}) {
fmt.Printf("类型:%T\n",a)
v,ok := a.(string)
if !ok {
fmt.Println("判断错误")
} else {
fmt.Println(v)
}
}
func test2(a interface{}) {
fmt.Printf("%T\n",a)
switch t := a.(type) { //$接口名.(type)只能用于switch方法
case int:
fmt.Println("整形:",t)
case string:
fmt.Println("字符串:",t)
case bool:
fmt.Println("bool值:",t)
default:
fmt.Println("其他类型",t)
}
}
func main(){
test(1000) //判断错误
test("中国") //中国
test2(int64(1000)) //其他类型 1000
test2(int(1000)) //其他类型 1000
test2("笑傲江湖")
test2(true)
}
7.7、多态
接口的一个好处,主要是实现了多态
package main
import "fmt"
type student struct {
name string
age uint8
score uint8
}
func (s student) speak() {
fmt.Printf("我是%s,我今年%v,我考了%v分\n", s.name, s.age, s.score)
}
type teacher struct {
name string
age uint8
subject string
}
func (t teacher) speak() {
fmt.Printf("我是%s老师,我今年%v,我教%v\n", t.name, t.age, t.subject)
}
type speakerr interface { //接口
speak()
}
func speak(h speakerr) { //多态的实现,使用接口作为函数的入参
h.speak()
}
func main() {
//1、多态前,接口使用: 1)定义一个接口变量;2)为接口变量赋值;3)使用接口变量调用具体的方法
var h speakerr //1)定义一个接口变量
stu := student{"小刚", 18, 120} //初始化信息,仍然是初始化具体的对象,而非接口
tech := teacher{"小英", 22, "自然"}
h = stu //将对象的信息赋值给接口变量,接口是虚的,方法是实的(具体负责实现)
h.speak()
h = tech
h.speak()
//2、多态
speak(stu)
speak(tech)
}
/*
1、创建interface,并定义实现的具体接口
1)创建结构体对象并实现对应的方法
2、创建函数,使用interface作为入参,执行具体的方法
3、创建具体的结构体对象实例
4、把3创建出来的实例,传递给函数2
*/
7.8、接口的继承
package main
import "fmt"
type student struct {
name string
age uint8
score uint8
}
func (s student) speak() {
fmt.Printf("我是%s,我今年%v,我考了%v分\n", s.name, s.age, s.score)
}
func (s student) sing(t string) {
fmt.Printf("我是%s,我会唱%v\n", s.name, t)
}
type teacher struct {
name string
age uint8
subject string
}
func (t teacher) speak() {
fmt.Printf("我是%s老师,我今年%v,我教%v\n", t.name, t.age, t.subject)
}
type speakerr interface {
speak()
}
type speakerrr interface { //接口继承
speakerr //匿名字段,并且实现了继承
sing(string)
}
func speak(h speakerr) {
h.speak()
}
func main() {
//1、接口-多态
stu := student{"小刚", 18, 120}
tech := teacher{"小英", 22, "自然"}
speak(stu)
speak(tech)
//2、接口-继承
var h speakerrr //超集
h = stu
h.sing("精忠报国")
h.speak()
var h1 speakerr //子集
// h = h1 报错, (missing sing method) 子集不能赋值给超集合,因为方法缺失
h1 = h //超集可以赋值给子集,但是只保留子集中的方法
h1.speak() //只有speak方法,
}
7.9、error接口
package main
import (
"errors"
// "errors"
"fmt"
)
type Customerror struct {
infoa string
infob string
Err error
}
func t1(a, b int) (result int, err error) {
// func t1(a, b int) (result int, err Customerror) { //对方方法3
if b == 0 {
// 方法1:采用error.New的方法
err = errors.New("this is a new error")
//方法2:采用fmt.Errorf
// err = fmt.Errorf("this is a new error")
//方法3:采用自定义的方式实现一个error的duck类型
// err = Customerror{
// infoa: "test error a",
// infob: "test error b",
// Err: errors.New("test custom error"),
// }
} else {
result = a / b
}
fmt.Println("test")
return
}
func main() {
v, err := t1(10, 0)
if err != nil {
// if err.Err != nil { //对应方法3
fmt.Println(err)
} else {
fmt.Println(v)
}
}
7.10、panic/recover
- go语言中目前没有(Go 1.12)是没有异常处理机制,
- 作用:在程序出现panic的时候,尝试恢复
- recover()必须搭配defer使用
- defer一定要在可能引发panic的语句之前定义
- panic
error返回的是一般错误信息,panic返回的是让系统崩溃的错误。一般不直接使用panic函数,当发生致命错误的时候i,系统内置了panic函数触发异常。当程序遇到panic时会自动终止
package main
import (
"fmt"
)
func testPanic(i int) {
if i < 0 {
panic("below zero")
}
var arr [3]int
arr[i] = 9
fmt.Println(arr)
}
func main() {
// testPanic(4) //如果这里传递的值,大于4就会报错“panic: runtime error: index out of range [4] with length 3”
testPanic(-1) //panic: below zero ,手动定义的异常
}
- recover
func funcA(){
fmt.Println("A")
}
func funcB(){
//刚刚打开数据库连接
defer func() { //defer func要放在panic之前注册,否则不会被执行
err := recover()
fmt.Println(err) //出现了严重的错误...! recover会提取panic的错误
fmt.Println("释放数据库连接")
}()
panic("出现了严重的错误...!") //程序崩溃然后退出,之前会执行defer语句
fmt.Println("B")
}
func funcC(){
fmt.Println("C")
}
func main(){
funcA()
funcB()
funcC()
//输出结果如下:B由于崩溃了,不会执行
//A
//出现了严重的错误...!
// 释放数据库连接
//C
}
package main
import (
"fmt"
)
func testA() {
fmt.Println("test A")
}
func testB(x int) {
defer func() { //recover要和defer结合才有用
if err := recover(); err != nil { //只有在错误的时候才输出错误信息
fmt.Println(err)
}
}() //()这里要调用才有用
var a [3]int
a[x] = 99
fmt.Println(a)
}
func testC() {
fmt.Println("test C")
}
func main() {
testA()
testB(4) //会触发 index out of range 错误
testC()
/*
test A
[0 0 99] 或者 runtime error: index out of range [4] with length 3
test C
*/
}
