kubernetes-学习笔记_魂宗
第二十二章、有状态应用编排-StatefulSet
22.1、需求背景
Deployment:管理所有同版本的Pod都是一摸一样的副本
1.定义一组Pod的期望数量,controller维持pod数量与期望数量一致
2.配置Pod发布方式,cotroller会按照给定策略更新pod,保证更新过程中不可用的pod数量在限定范围内
3.如果发布有问题,支持“一键”回滚
需求分析:Deployment可以满足吗?
1.Pod之间并非相同的副本,每个Pod有一个独立标识
2.Pod独立标识要能够对应到一个固定的网络标识(ip or hostname),并在发布后能持续保持
3.每个Pod有一块独立的存储盘,并在发布升级后还能继续挂载原有的盘(保留数据)
4.应用发布时,按照固定顺序升级Pod
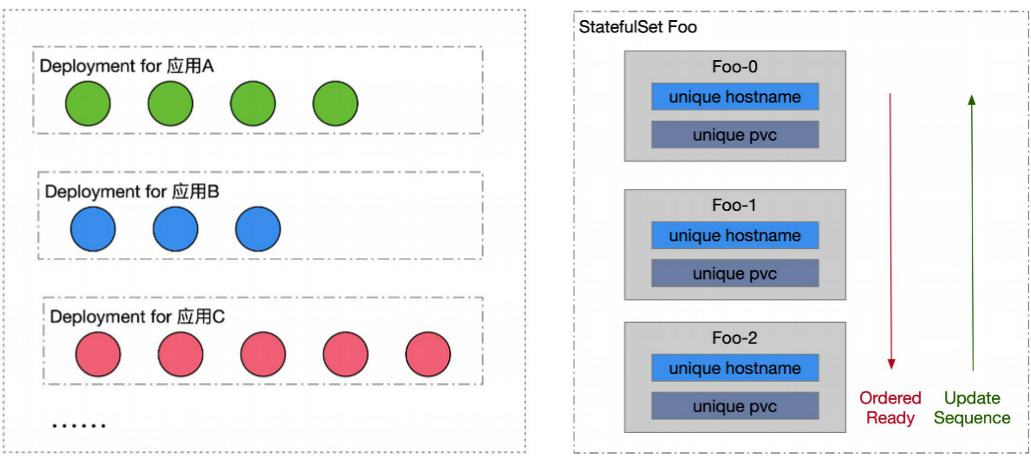
StatefulSet:主要面向有状态应用管理的控制器(当然也可以使用statefulset管理有状态应用)
1.每个Pod有Order序号,会按照序号创建、删除、更新Pod
2.通过配置headless service,使每个Pod有一个唯一的网络标识(hostname)
3.通过配置pvc template,每个pod有一块独享的pv存储盘
4.支持一定数量的灰度发布
22.2、用例解读
# 1、准备存储
[root@master1 nfs-share]# showmount -e master1
Export list for master1:
/nfs-share *
[root@master1 nfs-share]# showmount -e master2
Export list for master2:
/nfs-share *
[root@master1 nfs-share]# showmount -e master3
Export list for master3:
/nfs-share *
[root@master1 sts]# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /nfs-share
server: 192.168.153.132
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv2
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /nfs-share
server: 192.168.153.133
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv3
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /nfs-share
server: 192.168.153.134
---
[root@master1 sts]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfs-pv1 5Gi RWO Recycle Available 6s
nfs-pv2 5Gi RWO Recycle Available 6s
nfs-pv3 5Gi RWO Recycle Available 6s
[root@master1 sts]#
#2、创建StatefulSet
[root@master1 sts]# cat sts.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx" #sts必须要有对应的service
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: reg.mt.com:5000/nginx:v1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www-storage
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 2Gi
[root@master1 sts]# kubectl apply -f sts.yaml
[root@master1 sts]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-storage-nginx-web-0 Bound nfs-pv1 5Gi RWO 2m50s
www-storage-nginx-web-1 Bound nfs-pv2 5Gi RWO 2m38s
www-storage-nginx-web-2 Bound nfs-pv3 5Gi RWO 2m2s
[root@master1 sts]# kubectl get svc/nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 3m3s
[root@master1 sts]# kubectl get endpoints nginx
NAME ENDPOINTS AGE
nginx 172.7.26.2:80,172.7.26.3:80,172.7.67.2:80 3m20s
[root@master1 sts]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-web-0 1/1 Running 0 3m35s #创建顺序仓0->1->2
nginx-web-1 1/1 Running 0 3m23s
nginx-web-2 1/1 Running 0 2m47s
[root@master1 sts]# kubectl get sts/nginx-web -o yaml
...
status:
collisionCount: 0
currentReplicas: 3
currentRevision: nginx-web-749477f8fd
observedGeneration: 1
readyReplicas: 3
replicas: 3
updateRevision: nginx-web-749477f8fd
updatedReplicas: 3
[root@master1 sts]# dig -t A nginx.default.svc.cluster.local
...
;; ANSWER SECTION:
nginx.default.svc.cluster.local. 5 IN A 172.7.26.3
nginx.default.svc.cluster.local. 5 IN A 172.7.26.2
nginx.default.svc.cluster.local. 5 IN A 172.7.67.2
# 3、更新镜像
[root@master1 sts]# kubectl set image sts nginx-web nginx=reg.mt.com:5000/nginx:v2
statefulset.apps/nginx-web image updated
[root@master1 sts]# kubectl get pods //从2->1->0 进行更新
NAME READY STATUS RESTARTS AGE
nginx-web-0 1/1 Running 0 22s
nginx-web-1 1/1 Running 0 26s
nginx-web-2 1/1 Running 0 30s
[root@master1 sts]# kubectl get sts/nginx-web -o yaml
status:
collisionCount: 0
currentReplicas: 3
currentRevision: nginx-web-85846c6f77 #已经变化
observedGeneration: 2
readyReplicas: 3
replicas: 3
updateRevision: nginx-web-85846c6f77
updatedReplicas: 3
[root@master1 sts]# kubectl get pvc #没有变
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-storage-nginx-web-0 Bound nfs-pv1 5Gi RWO 13m
www-storage-nginx-web-1 Bound nfs-pv2 5Gi RWO 12m
www-storage-nginx-web-2 Bound nfs-pv3 5Gi RWO 12m
[root@master1 sts]# kubectl get pods -o wide #ip有一个变化了
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-web-0 1/1 Running 0 5m30s 172.7.67.2 master3 <none> <none>
nginx-web-1 1/1 Running 0 5m34s 172.7.26.3 master1 <none> <none>
nginx-web-2 1/1 Running 0 5m38s 172.7.67.3 master3 <none> <none>
不同于Deployment使用ReplicaSet来管理版本和维持副本数,StatefulSet controller直接管理下属的Pod。而Pod中用一个Label来标识版本:controller-revision-hash
22.3、架构设计
1、管理模式

当前版本的StatefulSet指挥在ControllerRevision和pod中添加OwnnerReference,并不会在PVC中添加。拥有OwnerReference的资源,在删除的时候会级联删除资源。即默认情况下删除statefulset则ControllerRevision和Pod都会被删除,但是PVC不会被删除
[root@master1 sts]# kubectl get controllerrevisions #statefuleset使用controllerrevisions 管理pod
NAME CONTROLLER REVISION AGE
nginx-web-749477f8fd statefulset.apps/nginx-web 1 17m
nginx-web-85846c6f77 statefulset.apps/nginx-web 2 8m11s
[root@master1 sts]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-web-0 1/1 Running 0 131m app=nginx,controller-revision-hash=nginx-web-85846c6f77,statefulset.kubernetes.io/pod-name=nginx-web-0
nginx-web-1 1/1 Running 0 131m app=nginx,controller-revision-hash=nginx-web-85846c6f77,statefulset.kubernetes.io/pod-name=nginx-web-1
nginx-web-2 1/1 Running 0 131m app=nginx,controller-revision-hash=nginx-web-85846c6f77,statefulset.kubernetes.io/pod-name=nginx-web-2
2、StatefuleSet控制器
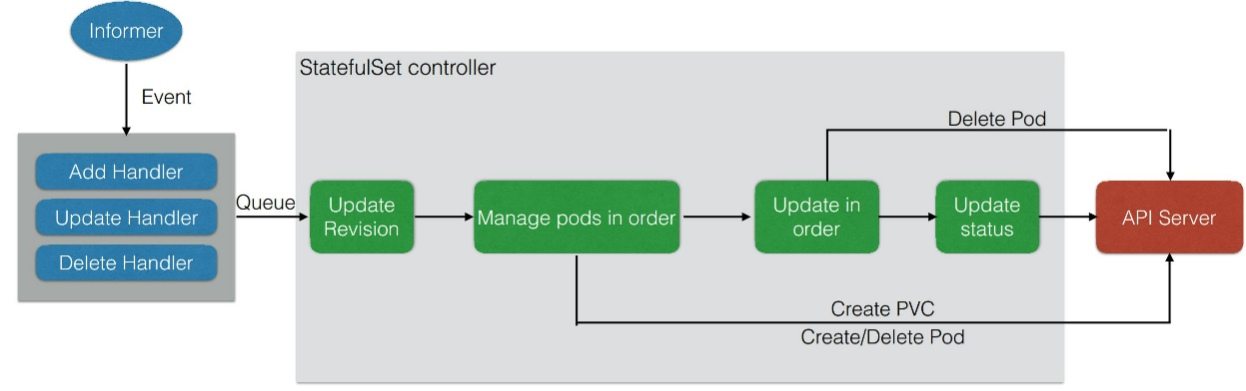
- 首先通过注册 Informer 的 Event Handler(事件处理),来处理 StatefulSet 和 Pod 的变化。在 Controller 逻辑中,每一次收到 StatefulSet 或者是 Pod 的变化,都会找到对应的 StatefulSet 放到队列。紧接着从队列取出来处理后,先做的操作是 Update Revision,也就是先查看当前拿到的 StatefulSet 中的 template,有没有对应的 ControllerRevision。如果没有,说明 template 已经更新过,Controller 就会创建一个新版本的 Revision,也就有了一个新的 ControllerRevision hash 版本号。
- 然后 Controller 会把所有版本号拿出来,并且按照序号整理一遍。这个整理的过程中,如果发现有缺少的 Pod,它就会按照序号去创建,如果发现有多余的 Pod,就会按照序号去删除。当保证了 Pod 数量和 Pod 序号满足 Replica 数量之后,Controller 会去查看是否需要更新 Pod。也就是说这两步的区别在于,Manger pods in order 去查看所有的 Pod 是否满足序号;而后者 Update in order 查看 Pod 期望的版本是否符合要求,并且通过序号来更新。
- Update in order 其更新过程如上图所示,其实这个过程比较简单,就是删除 Pod。删除 Pod 之后,其实是在下一次触发事件,Controller 拿到这个 success 之后会发现缺少 Pod,然后再从前一个步骤 Manger pod in order 中把新的 Pod 创建出来。在这之后 Controller 会做一次 Update status,也就是之前通过命令行看到的 status 信息。
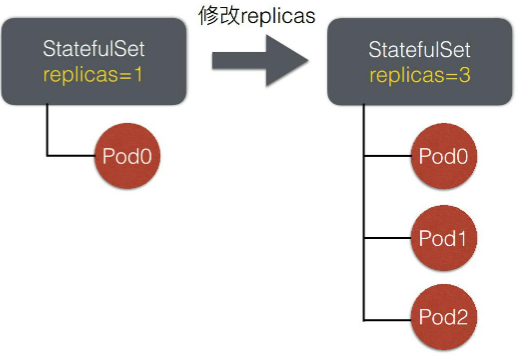
3、扩容模拟
StatefulSet下的pod,从序号0开始创建(从一个Pod扩容到3个Pod,默认是先创建Pod1,Pod1 Ready后,才会创建Pod2)。因此replicas=N的StatefulSet,创建出的Pod序号为[0,N)
4、扩缩容管理策略

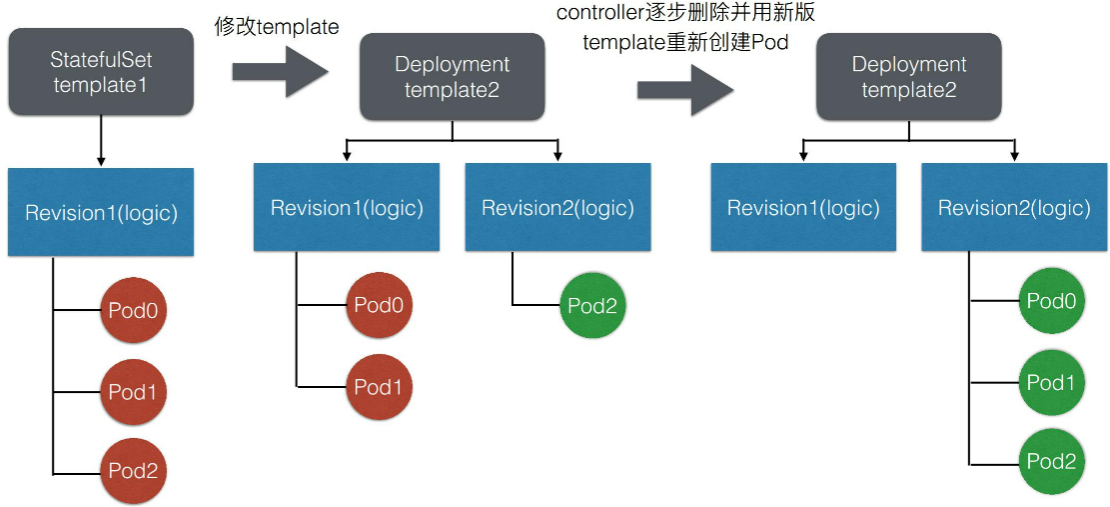
5、发布模拟
6、spec字段解析
- Replicas: 期望数量
- Selector:选择器,必须匹配.spec.template.metadata.labels
- Template: pod模板
- VolumeClaimTemplate: PVC模板列表
- ServiceName: 对应的Headless Service的名字,用于给Pod生成唯一的网络标识
- PodManagementPolicy: Pod管理策略
- OrderedReady:顺序执行
- Parallel:并行
- UpdateStrategy: Pod升级策略
- RollingUpdate: 滚动升级
- OnDelete: 禁止主动升级
- RevisionHisotryLimit: 保留历史ControllerRevision的数量限制(默认为10)
- Partition: 滚动升级时,保留旧版本Pod的数量,假设replicas=N,partition=M(M<=N),则最终旧版本Pod为[0,M) 新版本Pod为[M,N)
第二十三章、Kubernetes API编程范式
23.1、需求背景
Kubernetes Custom resources definition(CRD) 背景问题:
- 用户自定义资源需求比较多
- 希望kubernetes提供聚合各个子资源的功能
- Kubernetes原生资源无法满足需求
- Kubernetes APIServer扩展比较复杂
CRD 介绍:
- 在Kubernetes 1.7 版本被引入
- 可以根据自己的需求添加自定义Kubernetes对象资源
- 自定义资源与Kubernetes原生内置资源一样共用kubectl CLI,安全,RBAC等功能
- 用户同时可以开发自定义控制器感知或者操作自定义资源的变化
23.2、用例解读
1、基础用法
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
# 名称必须与下面的spec字段匹配,格式为: <plural>.<group>
name: crontabs.stable.example.com
spec:
# 用于REST API的组名称: /apis/<group>/<version>
group: stable.example.com
# 此CustomResourceDefinition支持的版本列表
versions:
- name: v1
# 每个版本都可以通过服务标志启用/禁用。
served: true
# 必须将一个且只有一个版本标记为存储版本。
storage: true
# 指定crd资源作用范围在命名空间或集群
scope: Namespaced
names:
# URL中使用的复数名称: /apis/<group>/<version>/<plural>
plural: crontabs
# 在CLI(shell界面输入的参数)上用作别名并用于显示的单数名称
singular: crontab
# kind字段使用驼峰命名规则. 资源清单使用如此
kind: CronTab
# 短名称允许短字符串匹配CLI上的资源,意识就是能通过kubectl 在查看资源的时候使用该资源的简名称来获取。
shortNames:
- ct
---
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
#因为crd定义的spec没有定义,这里可以随便定义,但是格式为key:value
cronSpec: "* * * * */5"
image: my-awesome-cron-image
[root@master1 crd]# kubectl get crontab/my-new-cron-object -o yaml
apiVersion: stable.example.com/v1
kind: CronTab
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"stable.example.com/v1","kind":"CronTab","metadata":{"annotations":{},"name":"my-new-cron-object","namespace":"default"},"spec":{"cronSpec":"* * * * */5","image":"my-awesome-cron-image"}}
creationTimestamp: "2021-03-15T12:58:47Z"
generation: 1
name: my-new-cron-object
namespace: default
resourceVersion: "843195"
selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object
uid: 1b839c01-4c34-4ed7-8b31-81879a192b47
spec:
cronSpec: '* * * * */5'
image: my-awesome-cron-image
[root@master1 crd]# kubectl get ct
NAME AGE
my-new-cron-object 9m34s
[root@master1 crd]# kubectl get crontab
NAME AGE
my-new-cron-object 9m53s
2、示例2说明-CRD字段校验&增加状态列
对CRD的内容部分限制。使用OpenAPI v3 模式来验证我们自定义的资源对象:
[root@master1 crd]# cat crd.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
versions:
- name: v1
served: true
storage: true
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
validation:
openAPIV3Schema:
properties:
spec:
properties:
cronSpec: #--必须是字符串,并且必须是正则表达式所描述的形式
type: string
pattern: '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
replicas: #----必须是整数,最小值必须为1,最大值必须为10
type: integer
minimum: 1
maximum: 10
additionalPrinterColumns: #限制状态列
- name: Spec
type: string
description: The cron spec defining the interval a CronJob is run
JSONPath: .spec.cronSpec
- name: Replicas
type: integer
description: The number of jobs launched by the CronJob
JSONPath: .spec.replicas
- name: Age
type: date
JSONPath: .metadata.creationTimestamp
[root@master1 crd]# cat my-crontabl.yaml
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
replicas: 5
[root@master1 crd]# kubectl get crontab
NAME SPEC REPLICAS AGE
my-new-cron-object * * * * */5 5 2m1s
3、添加状态和自动伸缩
[root@master1 crd]# cat crd.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
versions:
- name: v1
served: true
storage: true
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
validation:
openAPIV3Schema:
properties:
spec:
properties:
cronSpec: #--必须是字符串,并且必须是正则表达式所描述的形式
type: string
pattern: '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
replicas: #----必须是整数,最小值必须为1,最大值必须为10
type: integer
minimum: 1
maximum: 10
additionalPrinterColumns: #限制状态列
- name: Spec
type: string
description: The cron spec defining the interval a CronJob is run
JSONPath: .spec.cronSpec
- name: Replicas
type: integer
description: The number of jobs launched by the CronJob
JSONPath: .spec.replicas
- name: Age
type: date
JSONPath: .metadata.creationTimestamp
# 自定义资源的子资源描述
subresources:
# 启用状态子资源。
status: {}
# 启用scale子资源
scale:
specReplicasPath: .spec.replicas
statusReplicasPath: .status.replicas
labelSelectorPath: .status.labelSelector
[root@master1 crd]# cat my-crontabl.yaml
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
replicas: 2
[root@master1 crd]# kubectl apply -f my-crontabl.yaml
crontab.stable.example.com/my-new-cron-object created
[root@master1 crd]# kubectl get ct
NAME SPEC REPLICAS AGE
my-new-cron-object * * * * */5 2 3s
[root@master1 crd]# kubectl scale --replicas=5 crontabs/my-new-cron-object #scale报错失败
The crontabs "my-new-cron-object" is invalid: metadata.resourceVersion: Invalid value: 0x0: must be specified for an update
[root@master1 crd]# kubectl edit ct/my-new-cron-object #修改replicas为5成功,待后续详细了解原因
crontab.stable.example.com/my-new-cron-object edited
[root@master1 crd]# kubectl get ct
NAME SPEC REPLICAS AGE
my-new-cron-object * * * * */5 5 28s
更多用法,参考:https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/
23.3、架构设计
Controller 控制器概览:
- Kubernetes提供一种可插拔式的方法来扩展或者控制声明式Kubernetes资源
- 控制器是Kubernetes的大脑,负责控制大部分资源的操作
- Deployment等就是通过Kube-controller-manager来部署对应的Pod并维护Pod指定的数量和状态
- 用户声明完成CRD后,需要创建一个控制器来操作自定义资源完成目标
Controller工作概览:
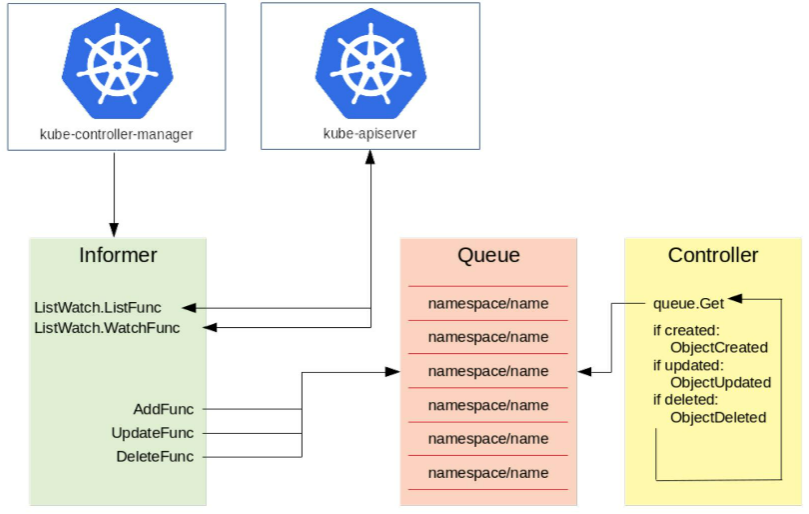
- Informer 负责watch和list apiserver
- Informer收到信息后,调用对应的函数把对应的事件放到Queue中。
- Controller 从Queue中获取到对象后,会去做相应的操作
工作流程:
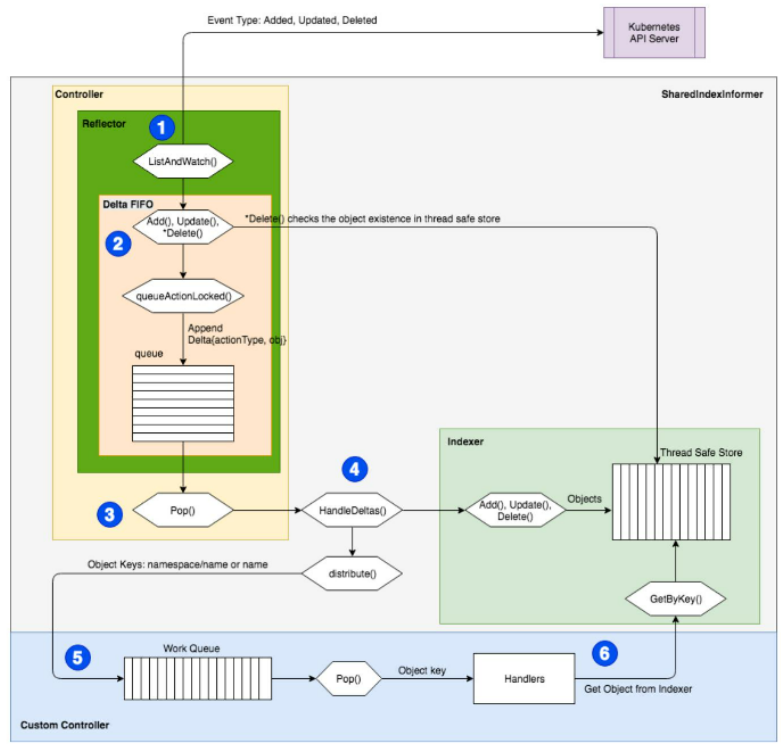
首先,通过 kube-apiserver 来推送事件,比如 Added, Updated, Deleted;然后进入到 Controller 的 ListAndWatch() 循环中;ListAndWatch 中有一个先入先出的队列,在操作的时候就将其 Pop() 出来;然后去找对应的 Handler。Handler 会将其交给对应的函数(比如 Add(), Update(), Delete())。
一个函数一般会有多个 Worker。多个 Worker 的意思是说比如同时有好几个对象进来,那么这个 Controller 可能会同时启动五个、十个这样的 Worker 来并行地执行,每个 Worker 可以处理不同的对象实例。
工作完成之后,即把对应的对象创建出来之后,就把这个 key 丢掉,代表已经处理完成。如果处理过程中有什么问题,就直接报错,打出一个事件来,再把这个 key 重新放回到队列中,下一个 Worker 就可以接收过来继续进行相同的处理。
第二十四章、Kubernetes API编程利器(待补充)
备注:本章节,待后续补充和完善
24.1、Operator概述
An Operator represents human operational knowledge in software, to reliably manage an application. They are methods of packaging, deploying, and managing a Kubernetes application.
The goal of an Operator is to put operational knowledge into software. Previously this knowledge only resided in the minds of administrators, various combinations of shell scripts or automation software like Ansible. It was outside of your Kubernetes cluster and hard to integrate. With Operators, CoreOS changed that.
通俗的讲:就是运维和部署的操作交给Operator实现,比如备份、扩容、故障恢复、声明式部署、版本升级等
1、基本概念:
- CRD:Custom Resource Definition,允许用户自定义kubernetes资源
- CR:Custom Resource,CRD的具体实例
- webhook: webhook关联在apiserver上,是一种HTTP回调,一个基于web应用实现的webhook会在特定事件发生时把消息发送给特定的URL。用户一般可以定义两类webhook:
- mutating webhook(变更传入对象)
- validating webhook(传入对象校验)
- 工作队列:controller核心组件,controller会监控集群内关注资源对象的变化,并把相关对象的事件(动作和key),存储入工作队列中
- controller: controller是检测集群状态变化,并据此做出相应处理的控制循环。它关联一个工作队列,循环处理队列内容。每一个controller都试图把集群状态向预期状态推动,只是关注的对象不同,如replicaset controller和endpoint controller
- operator: operator是描述、部署和管理kubernetes应用的一套机制,从实现上来说,operator = CRD + webhook + controller
- Operator和K8s controller的关系:
- 所有的Operator都是用了Controller模式,但并不是所有Controller都是Operator,只有当它满足: controller模式 + API扩展 + 专注于某个App/中间件时,才是一个Operator。
- Operator就是使用CRD实现的定制化的Controller. 它与内置K8S Controller遵循同样的运行模式(比如 watch, diff, action)
- Operator是特定领域的Controller实现
示例:mysql-operator是如何进行定时备份的:

2、常见operator工作模式
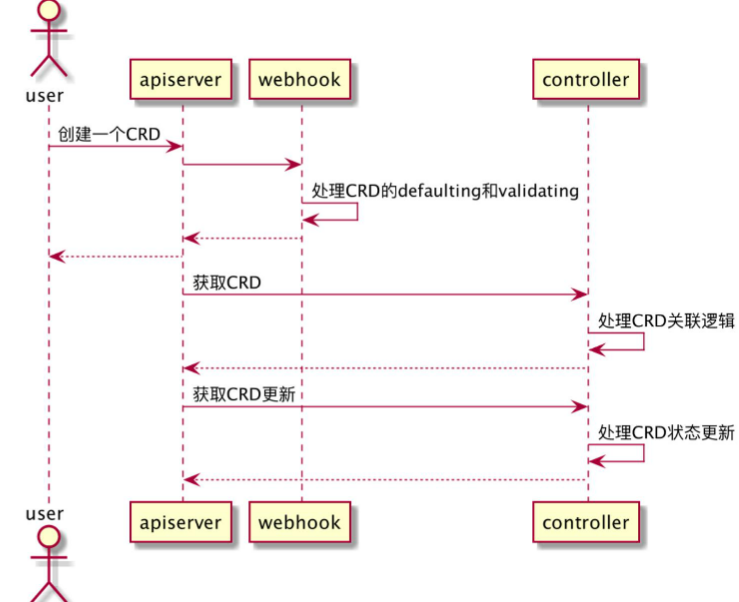
- 用户创建一个CRD
- apiserver转发请求给webhook
- webhook负责CRD的缺省值配置和配置项校验
- controller获取到新建的CRD,处理“创建副本”等关联逻辑
- controller实时监测CRD相关集群信息并反馈到CRD状态
24.2、Operator Framework
CoreOS提供了Operator Framework加速Operator的开发。主要包含组件:Operator SDK,Operator Lifecycle Manager,Operator registry
1、Operator Framework概述:
- Operator framework给用户提供了webhook和controller框架,包括消息通知、失败重新入队列等等,开发人员仅需关系被管理应用的运维逻辑实现
- 主流Operator framework项目:
- kubebuilder:
https://github.com/kubernetes-sigs/kubebuilder - operator-sdk:
https://github.com/operator-framework/operator-sdk - 两者没有本质上的区别,都是使用controller-tools和controller-runtime。细节上kubebuilder相应的策略、部署、代码生成脚手架更完善,如Makefile和Kustomsize等工具的集成;operator sdk则支持与ansible operator、Operator Lifecycle Manager的集成
- kubebuilder:
2、Operator capability levels
Operators come in different maturity levels in regards to their lifecycle management capabilities for the application or workload they deliver. The capability models aims to provide guidance in terminology to express what features users can expect from an Operator.
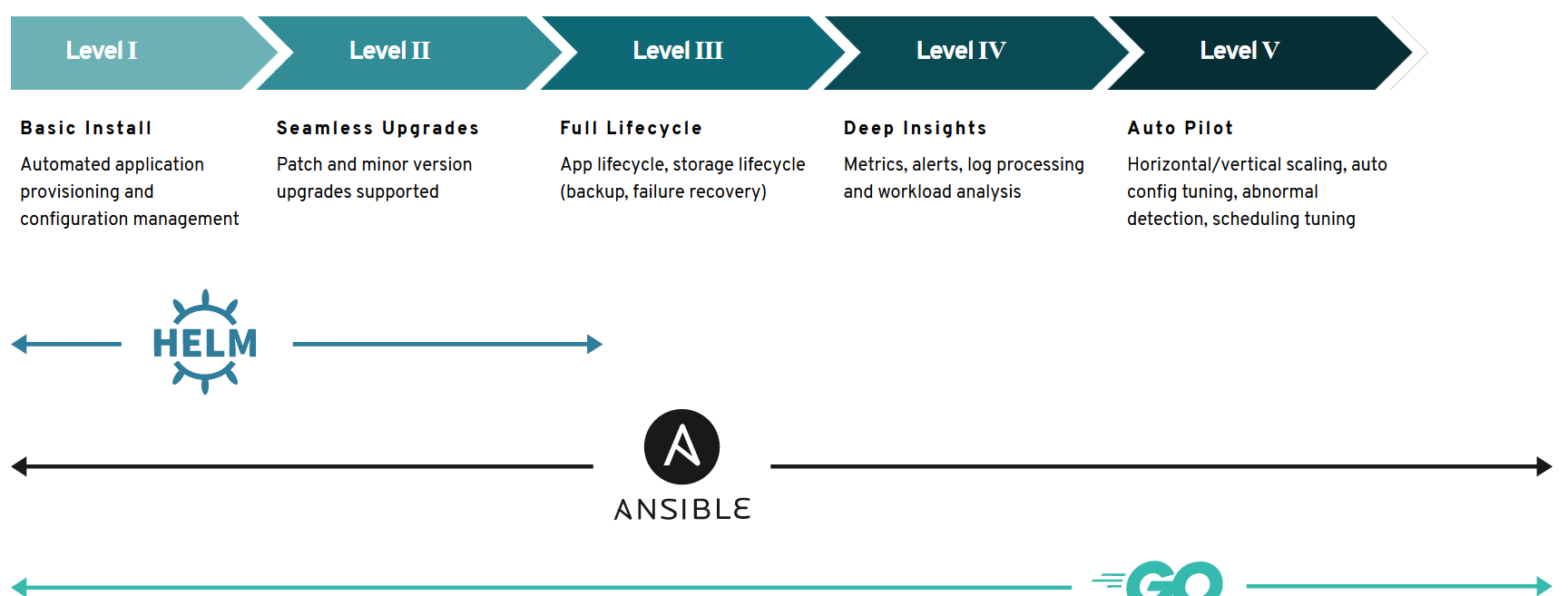
- Level I: 常见的Deployment,ConfigMap,PV,PVC创建等
- Level II: 版本或配置更新
- Level III: 整个生命周期管理,备份,故障恢复
- Level IV: 监控,告警,计量
- Level V: 自动扩容、自愈、预警、调优、异常检测
3、最佳实践
https://sdk.operatorframework.io/docs/
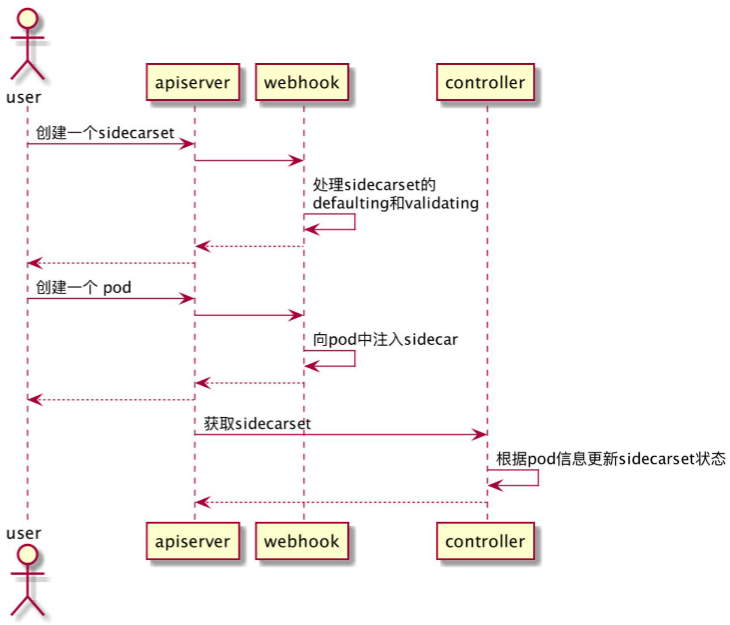
24.3、工作流程
- 用户创建sidecarset
- webhook负责siecars的缺省值配置和配置项校验
- 用户创建pod
- webhook负责向pod注入sidecar容器
- controller实时监测pod信息,并更新到sidecarset状态
第二十五章、Kubernetes网络模型进阶
25.1、Kubernetes网络模型来龙去脉
前人挖坑:早期Docker网络的由来与弊端
凡是用过Docker的,都见过Docker0 Bridge 和172.XX:
- 最好的便利设计是与外部世界解耦,使用私网地址+ 内部Bridge
- 出宿主机,采用SNAT借IP,进宿主机用DNAT借端口
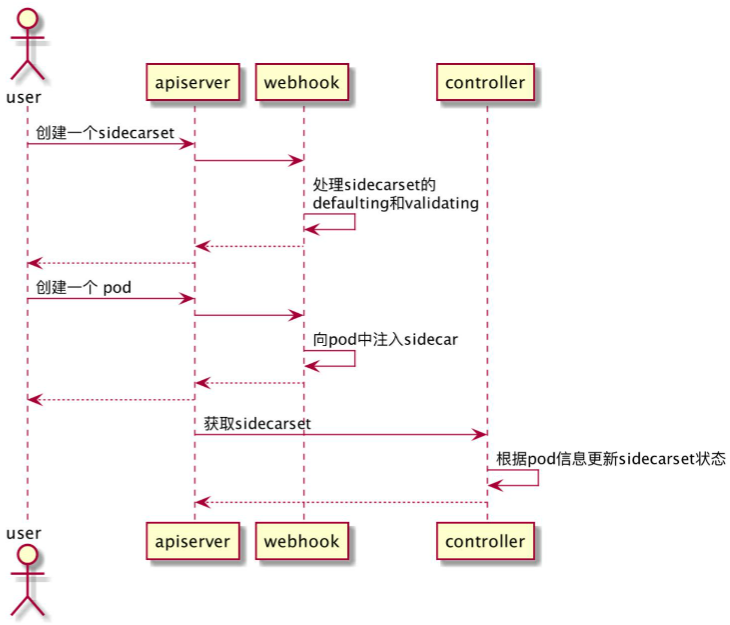
- 问题就是一堆NAT包在跑,难以区分宿主机和容器的流量。假如相同容器不同node组成group对外访问服务的时候。难以实现
后人填坑:Kubernetes新人新气象
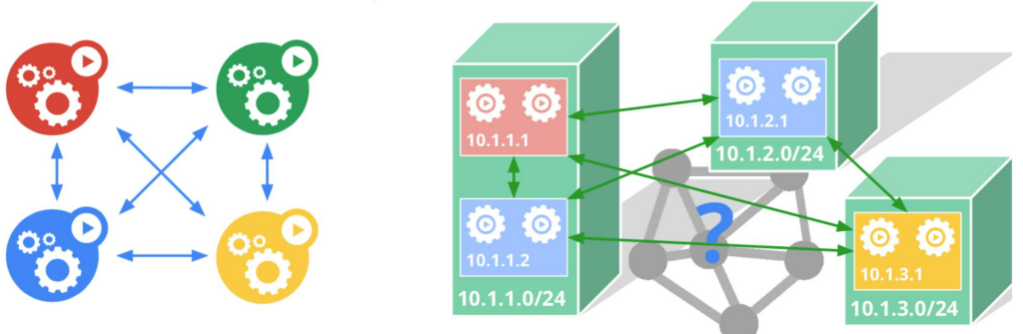
一句话,让一个功能聚集小团队(Pod)正大光明的拥有自己的身份证 --- IP:
- Pod的IP是真身份证,通信全球就这一个号,拒绝任何变造(NAT)
- Pod内的容器共享这个身份
- 实现手段不限,可以让外部路由器帮你加条目,也可以自己创建Overlay网络穿越
官方说明:https://github.com/containernetworking/cni
25.2、Pod如何上网
网络包不会自己非:只能一步一步爬
我们从两个维度来看:
-
1)协议层次,需要从L2层(MAC)To L3层(IP寻址) To L4(4层协议+端口)
-
2)网络拓扑,需要从容器空间To宿主机空间To远端
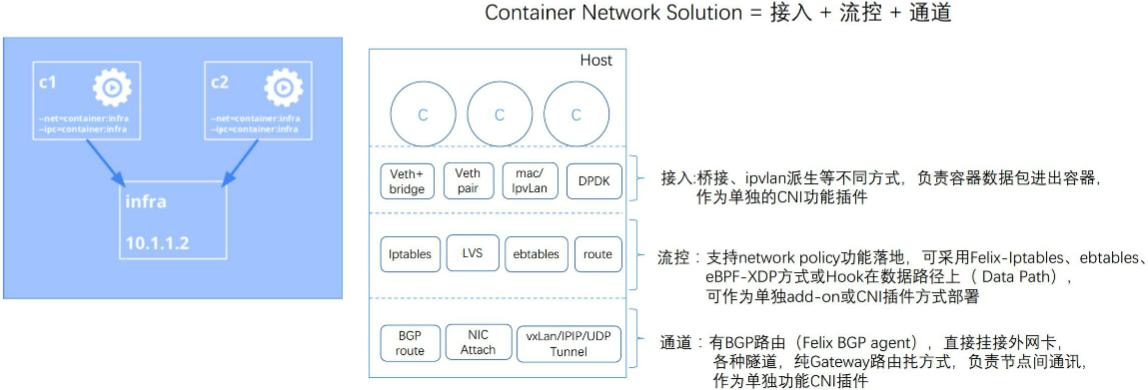
接入:容器和宿主机空间之间链接方式;流控:网络策略;通道:两个host之间的通信方式
一个简单的路由方案:Flannel-host-gw
IPAM方案:
- 每个Node独占网段,Gateway放在本地,好处是管理简单,坏处pod ip是无法跨Node飘逸
网络包勇往直前的一生:
- 1、Pod-netns 内出生:容器应用产生高层数据,比如从左边10.244.0.2发送到10.244.1.3,根据路由决定目的Mac,如属于同一subnet内直接发送给本机另一个容器,如另一网段,则填写Gw-mac(cni0桥),通过pod-netns内veth pair发送到cni0桥;
- 2、mac-桥转发:Bridge的默认行为是按照mac转发数据,如目的mac为本桥上某port(另一容器)就直接转发;如目的为cni0 mac,则数据上送到Host协议栈处理;
- 3、ip-主机路由转发:此时包剥离mac层,进入IP寻址层,如目的IP为本机Gw(cni0)则上送到本地用户进程,如目的为其他网段,则查询本地路由表(见图ip route块),找到该网段对应的远端Gw-ip(其实是远端主机IP),通过neigh系统查询出远端Gw-ip的mac地址,作为数据的目的mac,通过主机eth0送食醋胡;
- 4、IP-远端路由转发:由于mac地址的指引,数据包准确送到远端节点,通过eth0进入主机协议栈,再查询一次路由表,正常的话目的网段的对应设备为自己的cni0 iP,数据发送给了cni0;
- 5、mac-远程桥转发:cni0作为host inernal port on Bridge,收到数据包后,继续推送,IP层的处理末端填写目的ip(10.244.1.3)的mac,此时通过bridge fdb表查出mac(否则发arp广播),经过bridge mac转发,包终于到了目的容器netns。
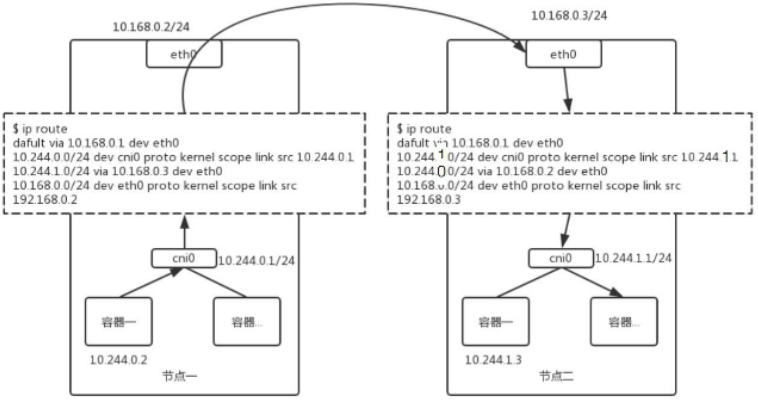
发送方向主要有三个方向:1.同pod内同container,2.同node上不同pod,3.不同node上不同pod;
#创建两个pod,nginx-web-0和nginx-web-1互访。
#1、信息查看
[root@master1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-web-0 1/1 Running 1 2d4h 172.7.61.3 master1 <none> <none>
nginx-web-1 1/1 Running 1 2d4h 172.7.34.2 master3 <none> <none>
nginx-web-0(172.7.61.3)访问 nginx-web-1(172.7.34.2)
步骤1:查看nginx-web-0的路由信息
[root@master1 sts]# kubectl exec -it nginx-web-0 -- ip route list #nginx-web-0的路由
default via 172.7.61.1 dev eth0 #默认路由,61.1为nginx-web-0所在node(master1)pod从etcd获取到的网
172.7.61.0/24 dev eth0 proto kernel scope link src 172.7.61.3
步骤2:查看master1 docker0配置信息
[root@master1 sts]# ifconfig docker0
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.7.61.1 netmask 255.255.255.0 broadcast 172.7.61.255
inet6 fe80::42:3eff:fe01:437d prefixlen 64 scopeid 0x20<link>
ether 02:42:3e:01:43:7d txqueuelen 0 (Ethernet)
RX packets 5156 bytes 424166 (414.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5246 bytes 464075 (453.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
步骤3:查看master1的路由信息
[root@master1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.116.2 0.0.0.0 UG 100 0 0 ens33
172.7.34.0 192.168.153.134 255.255.255.0 UG 0 0 0 ens34 #访问34.0网段的GW为153.134
172.7.61.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.116.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.153.0 0.0.0.0 255.255.255.0 U 101 0 0 ens34
步骤4:查看192.168.153.134(master3)的路由信息
[root@master3 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.116.2 0.0.0.0 UG 100 0 0 ens33
172.7.34.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0 #本机pod网段
172.7.61.0 192.168.153.132 255.255.255.0 UG 0 0 0 ens34 #master1的pod网段
192.168.116.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.153.0 0.0.0.0 255.255.255.0 U 101 0 0 ens34
[root@master1 sts]# kubectl exec -it nginx-web-1 -- ip route list #nginx-web-1的路由
default via 172.7.34.1 dev eth0
172.7.34.0/24 dev eth0 proto kernel scope link src 172.7.34.2
步骤5:抓包分析 #在nginx-web-0中ping 172.7.34.2 -c 1,在master3上抓包
[root@master3 ~]# tcpdump -i veth95c84ba
19:37:41.998341 ARP, Request who-has 172-7-34-2.lightspeed.livnmi.sbcglobal.net tell 172-7-34-1.lightspeed.livnmi.sbcglobal.net, length 28
//谁拥有34.2的ip,请告诉34.1(master3所在pod网段的GW)
19:37:41.998388 ARP, Reply 172-7-34-2.lightspeed.livnmi.sbcglobal.net is-at 02:42:ac:07:22:02 (oui Unknown), length 28
//34.2的mac地址为 02:42:ac:07:22:02
19:37:41.998395 IP 172-7-61-3.lightspeed.rcsntx.sbcglobal.net > 172-7-34-2.lightspeed.livnmi.sbcglobal.net: ICMP echo request, id 65, seq 1, length 64
//61.3 发送ICMP 请求 到34.2
19:37:41.998421 IP 172-7-34-2.lightspeed.livnmi.sbcglobal.net > 172-7-61-3.lightspeed.rcsntx.sbcglobal.net: ICMP echo reply, id 65, seq 1, length 64
//34.2回复 61.3 ICMP请求
19:37:47.014048 ARP, Request who-has 172-7-34-1.lightspeed.livnmi.sbcglobal.net tell 172-7-34-2.lightspeed.livnmi.sbcglobal.net, length 28
//谁拥有34.1的ip,请告诉34.2
19:37:47.014177 ARP, Reply 172-7-34-1.lightspeed.livnmi.sbcglobal.net is-at 02:42:62:e5:d2:da (oui Unknown), length 28
//34.1的mac为 02:42:62:e5:d2:da
25.3、Service究竟如何工作
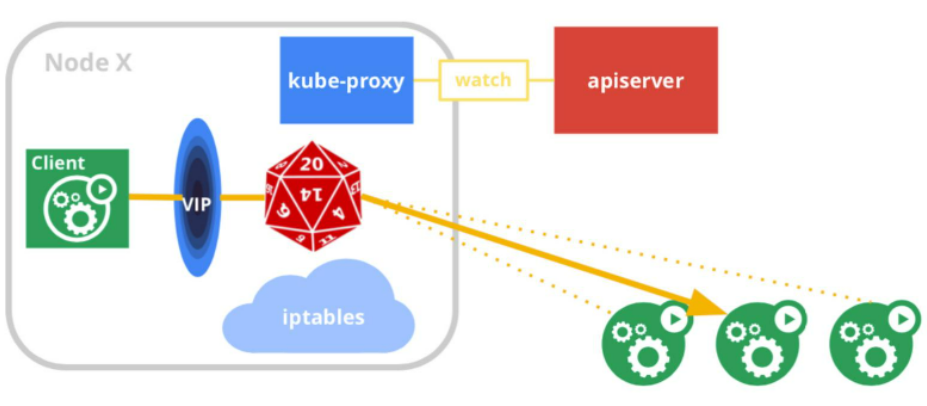
Service = Internal Load Balance @Client side //service为客户端的负载均衡
1)一群Pod组成一组功能后端
2)定义一个稳定的虚IP作为访问前端,一般还附赠一个DNS域名,Client无需感知Pod的细节;
3)kube-proxy是实现核心,隐藏了大量复杂性,通过apisrever监控Pod/Service的变化,反馈到LB配置中。
4)LB的实现机制与目标解耦,可以是用户态进程,也可以是一堆精心设计的Rules(iptables/ipvs)
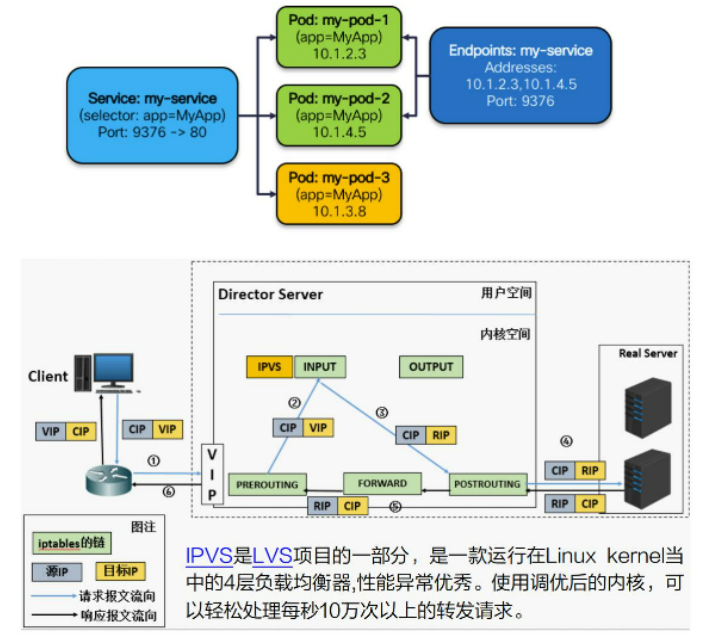
三步 ! 写一个高端大气的LVS 版Service
背景知识:一定要让kernel认为vip是本地地址,这样4层LVS才能开始干活
- 第一步:绑定VIP到本地(欺骗内核)
ip route add to local 192.168.60.200/32 dev eth0 proto kernel
- 第二步:为这个虚IP创建一个IPVS的Virtual server
ipvsadm -A -t 192.168.60.200:9376 -s rr -p 600
- 第三步:为这个IPVS service创建相应的real server
- ipvsadm -a -t 192.168.60.200:9376 -r 10.1.2.3:80 -m
- ipvsadm -a -t 192.168.60.200:9376 -r 10.1.4.5:80 -m
- ipvsadm -a -t 192.168.60.200:9376 -r 10.1.3.8:80 -m
[root@master1 ~]# kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP 192.168.0.82 <none> 22/TCP 2d5h
[root@master1 ~]# ipvsadm -Ln -t 192.168.0.82:22
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.82:22 nq
-> 172.7.34.2:22 Masq 1 0 0
-> 172.7.61.3:22 Masq 1 0 0
[root@master3 ~]# ipvsadm -Ln -t 192.168.0.82:22
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.82:22 nq
-> 172.7.34.2:22 Masq 1 0 0
-> 172.7.61.3:22 Masq 1 0 0
25.4、负载均衡
Service类型:
- ClusterIP: Node内部使用,将Service 承载在一个内部ClusterIP上,注意该服务只能保证集群内可达,这也是默认的服务类型
- NodePort:供集群外部调用,将Service承载在Node的静态端口,其实服务创建的时候也会自动创建一个CLusterIP,这样依赖,服务就暴露在Node的端口上,集群外的用户通过
$NODE_IP:$NODE_PORT的方式访问Service。 - LoadBalancer: 给云厂商预留的扩展接口,将Service通过外部云厂商的负载均衡端口承载,其实为方便云厂商的插件编写,NodePor和ClusterIP两种机制也会自动创建,云厂商可以有选择将外部LB挂载到这两种机制上去。
- ExternalName:去外面自由的飞翔,将Servie的服务完全映射到外部的名称(如域名),这种机制完全依赖外部实现,Service与CNAME挂钩,内部不会自动创建任何机制
一个真正能工作云上的、从0搭建的负载均衡系统
[root@master1 ~]# kubectl port-forward --address 192.168.153.132 pod/nginx-web-1 8888:2222
Forwarding from 192.168.153.132:8888 -> 2222
[root@master1 ~]# netstat -tunlp |grep 88
tcp 0 0 192.168.153.132:8888 0.0.0.0:* LISTEN 40196/kubectl
25.5、思考一下
- 容器层的网络就就那个如何与宿主机网络共存,overlay or underlay?
- Service还可以有怎么样的实现?
- 为什么一个容器编排系统要大力搞服务发现和负载均衡?
第二十六章、理解CNI和CNI插件
26.1、CNI概述
CNI是啥?
- Container Network Interface,容器网络的API接口
- Kubelet通过这个标准的API调用不同的网络插件实现配置网络
- CNI插件:一系列实现了CNI API接口的网络插件

Kubernetes中如何使用?
- 1、配置CNI配置文件(/etc/cni/net.d/xxnet.conf)
- 2、安装CNI二进制插件(/opt/cni/bin/xxnet)
- 3、在这个节点上创建Pod
- 4、Kubelet会根据CNI配置文件执行CNI插件
- 5、Pod的网络就配置完成了
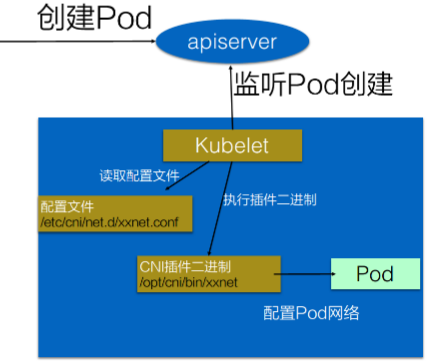
如果只是使用CNI插件的话,大部分CNI插件的提供者都可以一键安装:kubectl apply -f XXXX/flannel.yml,Flannel会通过Daemonset自动把配置和二进制拷贝到Node的配置文件夹中
26.2、CNI挑选
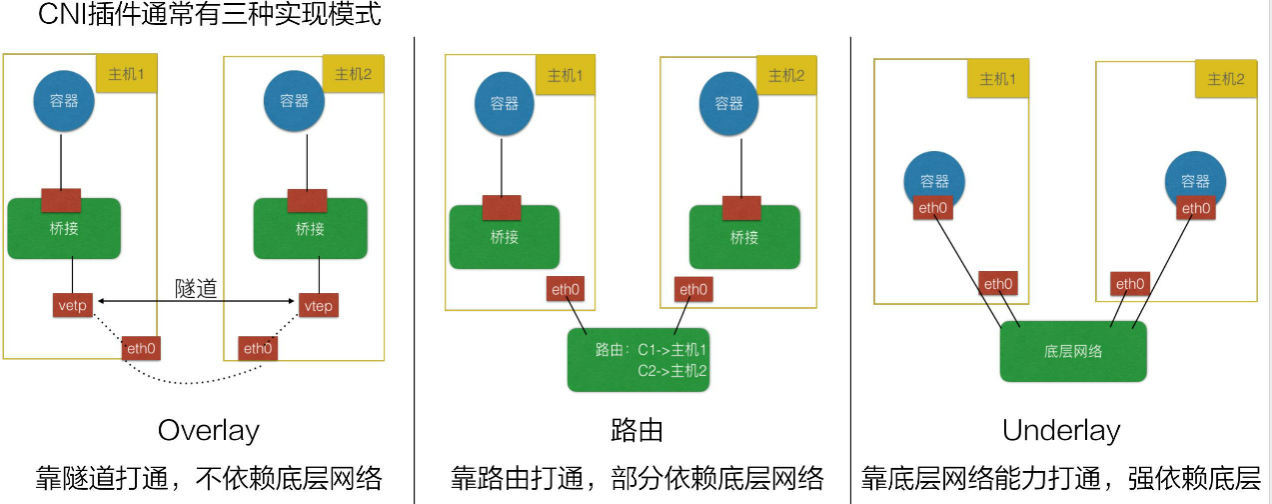
路由:要求底层网络二层可达的能力,Underlay 容器和宿主机在同一个网络
挑选建议:
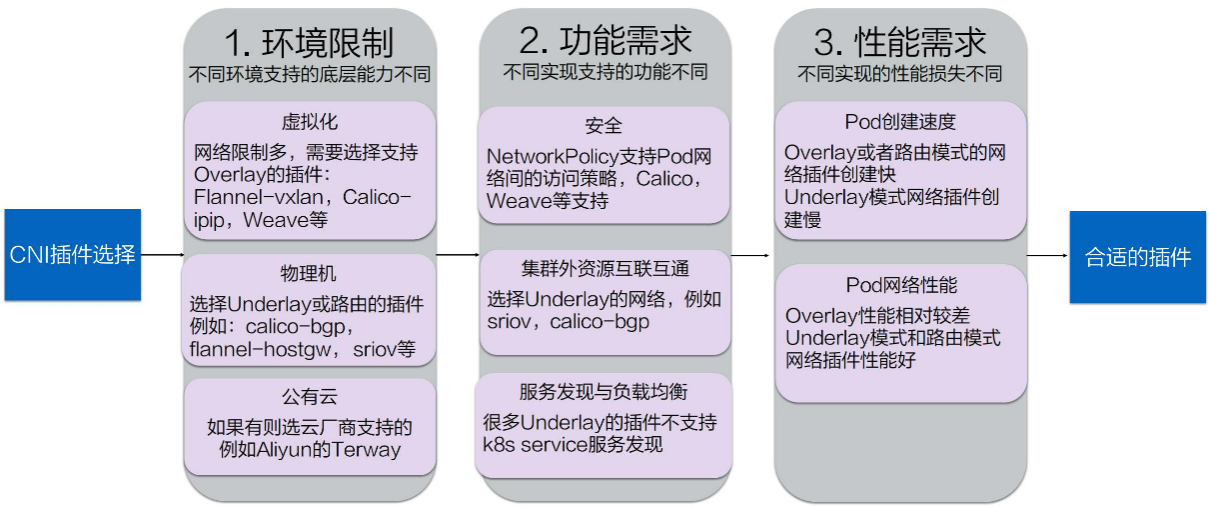
26.3、如何开发自己的CNI插件
CNI插件实现通常需要两个阶段:
- 一个二进制的CNI插件去配置Pod的网卡和IP等 ==> 给Pod插上网线
- 一个Daemon 进程去管理Pod之间的网络打通 ==> 给Pod连上网络
阶段1、给Pod插上网线
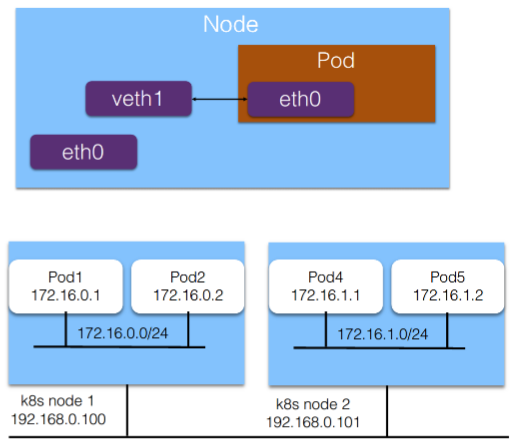
- 1、给Pod准备虚拟网卡
- 创建“veth“虚拟网卡对
- 将一端的网卡挪到Pod中,另外一段放在主机的网络空间中
- 2、给Pod分配IP地址
- 给Pod分配集群中唯一的IP地址
- 一般会把Pod网段按Node分段
- 每个Pod再从Node段中分配IP
- 3、配置Pod的IP和路由
- 给Pod的虚拟网卡(pod内)配置分配到的IP
- 给Pod的网卡(pod内)上配置集群网段的路由
- 在宿主机上配置到Pod的IP地址的路由到对端虚拟网卡上(pod外)
阶段2、给Pod连上网络:让每一个Pod的IP在集群中都能被访问到
- 1、CNI Daemon进程学习到集群所有Pod的IP和其所在节点
- 通常通过请求K8s APIServer拿到现有Pod的IP地址和节点
- 监听K8s APIServer新的Node和Pod的创建自动配置
- 2、CNI Daemon配置网络来打通Pod的IP的访问
- 创建到所有Node 的通道:Overlay隧道,VPC路由表,BGP路由等
- 将所有Pod的IP地址跟其所在Node的通道关联起来:Linux路由,Fdb路由表,OVS流表等
26.4、课后思考实践
- 在自己公司的网络环境中,选择哪一种网络插件最合适?
- 尝试自己实现一个CNI插件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号