kubernetes-学习笔记_魂尊
第十八章、kubernetes调度和资源管理
18.1、kubernetes调度过程
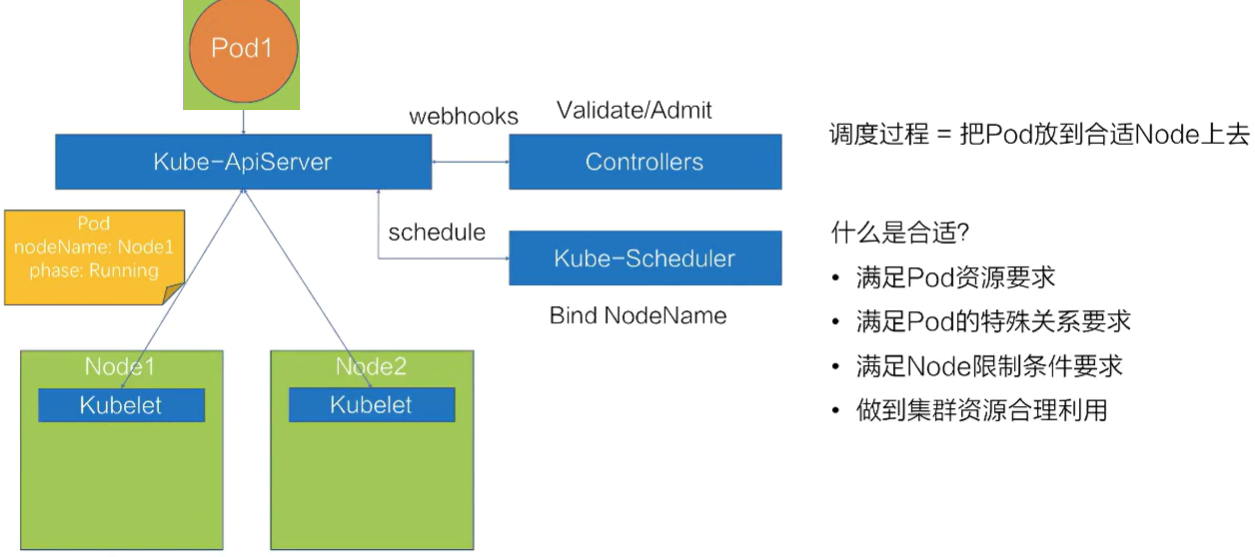
假如要创建一个pod(对应Pod1的定义yaml),对应的调度过程是?
-
ApiServer 会先把这个待创建的请求路由给webhooks的Controlles进行校验
-
通过校验之后,ApiServer 会在集群里面生成一个pod(写入到etcd中),但此时的 pod的nodeName 是空的,并且它的 phase 是 Pending 状态。
-
在生成了 pod 之后,kube-Scheduler 以及kubelet 都能 watch 到这个 pod 的生成事件,kube-Scheduler 发现这个 pod 的 nodeName 是空的之后,会认为这个pod 是处于未调度状态。
-
接下来,它会把这个 pod 拿到自己的队列里面进行调度,通过一系列的调度算法,包括一系列的过滤和打分的算法后,Schedule 会选出一台最合适的节点,并且把这一台节点的名称绑定在这个 pod 的 spec 上(通过apiserver 入库),完成一次调度的过程。此时pod 的 spec 上,nodeName 已经更新成了 Node1 这个 node
-
更新完 nodeName 之后,在 Node1 上的这台 kubelet 会 watch 到这个 pod 是属于自己节点上的一个 pod。
-
然后它会把这个 pod 拿到节点上进行操作,包括创建一些容器 storage 以及 network,最后等所有的资源都准备完成,kubelet 会把pod状态更新为 Running,这样一个完整的调度过程就结束了。
调度过程:它其实就是在做一件事情,就是把 pod 放到合适的 node 上。什么是合适呢?
-
1、首先要满足 pod 的资源要求;
-
2、其次要满足 pod 的一些特殊关系的要求;
-
3、再次要满足 node 的一些限制条件的要求;
-
4、最后还要做到整个集群资源的合理利用。
18.2、Kubernetes基础调度能力-资源调度
-
资源需求 - 满足Pod资源需求
- Resource: CPU/Memory/Storage/GPU/
- Qos: Guaranteed/Burstable/BestEffort
1、如何满足Pod资源要求 ?资源调度用法
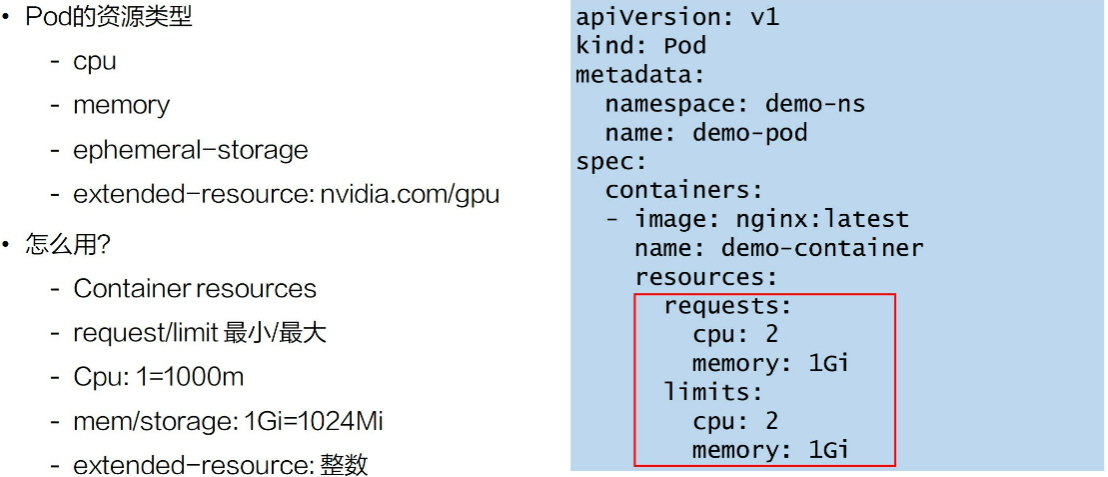
2、如何满足Pod资源需求? - Pod Qos类型

注意:QosClass不能手动指定,只能通过requests和limit 来影响
3、如何满足Pod资源需求, - Pod Qos配置

4、如何满足Pod资源要求?- 不同QoS的区别

不同的 Qos,它其实在调度和底层表现上都有一些不一样:
-
调度表现不同,调度器只会使用 request 进行调度,也就是不管你配了多大的 limit,它只会使用 request 进行调度。
-
在底层上,不同的 Qos 表现也不相同。
- CPU是按 request 来划分权重的,不同的 Qos,它的 request 是完全不一样的,比如说像 Burstable 和 BestEffort,它可能 request 可以填很小的数字或者不填,这样的话,它的权重其实是非常低的。像 BestEffort,它的权重可能是只有 2,而 Burstable 或 Guaranteed,它的权重可以多到几千。另外,如果kubelet 开启了 cpu-manager-policy=static 的时候,Guaranteed Qos,如果request 是一个整数的话,比如说配了 2,它会对 Guaranteed Pod 进行绑核(类似于taskset)
- 非整数的 Guaranteed/Burstable/BestEffort,它们的 CPU 会放在一块,组成一个 CPU share pool,比如说像上面这个例子,这台节点假如说有 8 个核,已经分配了 2 个核给整数的 Guaranteed 绑核,那么剩下的 6 个核 CPU2~CPU7,它会被非整数的 Guaranteed/Burstable/BestEffort 共享,然后它们会根据不同的权重划分时间片来使用 6 个核的 CPU。
- memory 按照不同的 Qos 进行划分:OOMScore。比如说 Guaranteed,它会配置默认的 -998 的 OOMScore;Burstable 的话,它会根据内存设计的大小和节点的关系来分配 2-999 的 OOMScore。BestEffort 会固定分配 1000 的 OOMScore,OOMScore 得分越高的话,在物理机出现 OOM 的时候会优先被 kill 掉。
- 节点上的 eviction (驱逐)动作上,不同的 Qos 也是不一样的,发生 eviction 的时候,会优先考虑驱逐 BestEffort 的 pod。
5、如何满足Pod资源要求? - 资源Quota
 ``` 为node预留资源,可使用kubelet运行参数 --system-reserved=cpu=1,memory=1Gi(系统预留) --kube-reserved=cpu=1,memory=1G(k8s组件预留) 等参数```
``` 为node预留资源,可使用kubelet运行参数 --system-reserved=cpu=1,memory=1Gi(系统预留) --kube-reserved=cpu=1,memory=1G(k8s组件预留) 等参数```
spec 包括了一个 hard 和 scopeSelector。scopeSelector 为这个 Resource 方法定义更丰富的索引能力。比如上面的例子中,索引出非 BestEffort 的 pod,限制的 cpu 是 1000 个,memory 是 200G,Pod 是 10 个,然后 Scope 除了提供 NotBestEffort,它还提供了更丰富的索引范围,包括 Terminating/Not Terminating,BestEffort/NotBestEffort,PriorityClass。
如果用户真的用超过了ResourceQuota限制的资源,表现的行为是:它在提交 Pod spec 时,会收到一个 forbidden 的 403 错误,提示 exceeded quota。这样用户就无法再提交 cpu 或者是 memory,或者是 Pod 数量的资源。假如再提交一个没有包含在这个 ResourceQuota 方案里面的资源,还是能成功的。
18.3、Kubernetes基础调度能力-关系调度
- Pod和其他pod的亲和/互斥关系
- PodAffinity
- PodAntiAffinity
- Pod和Node的亲和关系
- NodeSelector
- NodeAffinity
- Node配置限制标记,给Pods配置容忍标记
- Node - Taints
- Pod - Tolerations

2、如何满足Pod与Node关系要求? NodeAffinity
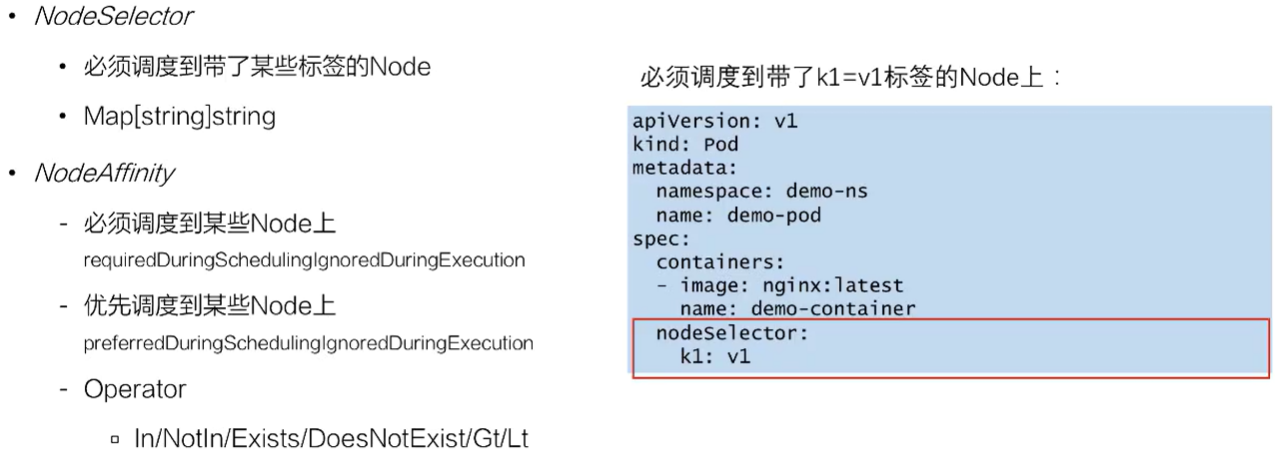
3、限制调度到某些Node?- Node 标记/容忍

NoExecute会对已有的pod进行驱逐。
# 1、下线维护node
kubectl drain <node name> #驱逐pod
kubectl uncordon #设置可调度
# 2、为node设置污点
[root@master1 ~]# kubectl get pods -o wide |grep master3
nginx-7fddbd784f-zrd68 1/1 Running 1 10d 172.7.67.3 master3 <none> <none>
[root@master1 ~]# kubectl taint nodes master3 key1=value1:NoExecute #驱逐没有toleration的Pods
node/master3 tainted
[root@master1 ~]# kubectl get pods -o wide |grep master3 #已经驱逐
[root@master1 ~]# kubectl taint nodes master3 key1=value1:NoExecute- #删除taint
# 3、pod tolerations
[root@master1 yaml]# kubectl taint nodes master2 key1=value1:NoSchedule
node/master2 tainted
[root@master1 yaml]# cat pod2.yaml #虽然master2有taint,但是pod仍然可以调度到master2上
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: reg.mt.com:5000/nginx:latest
name: nginx
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 3
readinessProbe:
successThreshold: 1
periodSeconds: 5
httpGet:
path: /
port: 80
timeoutSeconds: 5
initialDelaySeconds: 3
tolerations:
- key: key1
operator: Equal
value: value1
18.4、Kubernetes高级调度能力-优先级
1、优先级调度配置
优先级调度和抢占: Priority, Preemption
如果集群资源充足,通过基础调能力即可满足实现合理的资源使用。在集群资源不足的情况下如何使用资源?
- 先到先得策略(FIFO) - 简单、相对公平、上手快
- 优先级策略(Priority) - 符合日常业务特点。在高优先级的pod到的时候低优先级的pod让出资源
PodPriority和Preemption在v1.14版本为stable版本,并且默认开启 链接
如何使用呢?

Kubernetes 内置的默认优先级。DefaultpriorityWhenNoDefaultClassExistis,如果集群中没有配置 DefaultpriorityWhenNoDefaultClassExistis,那所有的 Pod 关于此项数值都会被设置成 0。
[root@master1 yaml]# kubectl get priorityclass #k8s初始化的时候默认提供内置的系统级别的PriorityClass,主要用来确保 Kubernetes 系统的关键组件或者关键插件总是能够优先被调度,比如 coredns 等。
NAME VALUE GLOBAL-DEFAULT AGE
system-cluster-critical 2000000000 false 15d
system-node-critical 2000001000 false 15d
另一个内置优先级是用户可配置最大优先级限制:HighestUserDefinablePriority = (10 亿) 系统级别优先级:SystemCriticalPriority = (20 亿)
2、优先级调度过程
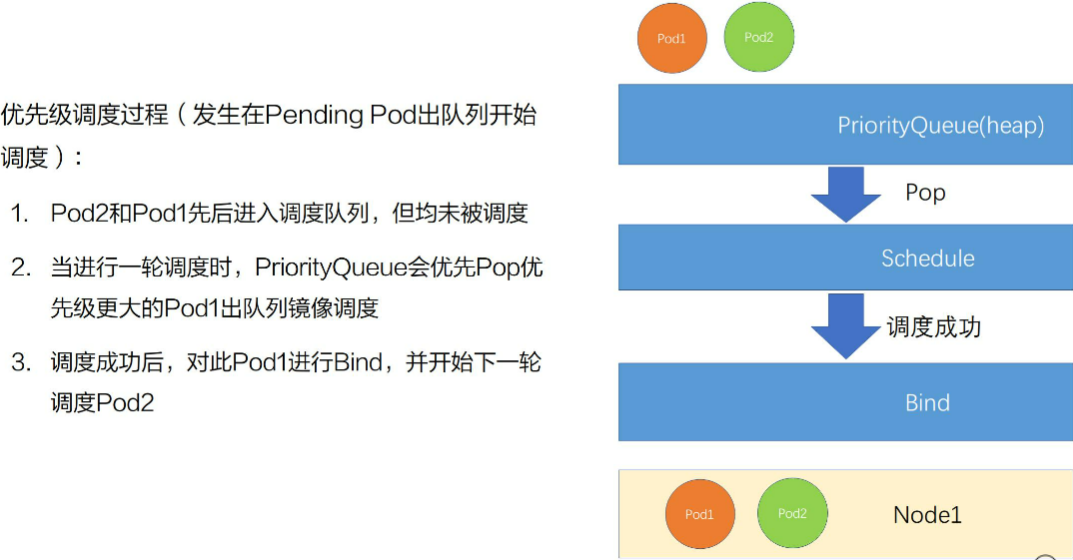
只开启优先级调度,没有开启抢占模式的调度过程。pod1优先级高,pod2优先级低。先调度pod1,后调度pod2
3、优先级抢占过程

pod0在node1上已经占用了部分资源。优先级: Pod0 > Pod1 >Pod2 。假如先进行了Pod2的调度(pod2先到),调度到了Node1上,在Pod1进行调度的时候进行资源抢占,让Pod2作为Pod1的让渡者。
4、优先级抢占策略

- 1、上图右侧是整个优先级抢占的调度流程,也就是 kube-scheduler 的工作流程。首先一个 Pod 进入抢占的时候,会判断 Pod 是否拥有抢占的资格(Eligible),有可能上次已经抢占过一次。
- 2、如果符合抢占资格,它会先对所有的节点进行一次过滤,过滤出符合这次抢占要求的节点,如果不符合就过滤掉这批节点。
- 3、接着从过滤剩下的节点中,挑选出合适的节点进行抢占。这次抢占的过程会模拟一次调度,也就是把上面优先级低的 Pod 先移除出去,再把待抢占的 Pod 尝试能否放置到此节点上。然后通过这个过程选出一批节点
- 4、进入下一个过程叫 ProcessPreemptionWithExtenders。这是一个扩展的钩子,用户可以在这里加一些自己抢占节点的策略,如果没有扩展的钩子,这里面是不做任何动作的。
- 5、接下来的流程叫做 PickOneNodeForPreemption,就是从上面 selectNodeForPreemption list 里面挑选出最合适的一个节点,这是有一定的策略的。上图左侧简单介绍了一下策略:串行过滤
- 优先选择打破 PDB 最少的节点;挑选的节点对服务的影响最小
- 其次选择待抢占 Pods 中最大优先级最小的节点;
- 再次选择待抢占 Pods 优先级加和最小的节点;
- 接下来选择待抢占 Pods 数目最小的节点;
- 最后选择拥有最晚启动 Pod 的节点;
通过这五步串行策略过滤之后,会选出一个最合适的节点。然后对这个节点上待抢占的 Pod 进行 delete,这样就完成了一次待抢占的过程。
PDB: 在Kubernetes 中,为了保证业务不中断或业务SLA不降级,需要将应用进行集群化部署。通过PodDisruptionBudget(PDB) 控制器可以设置应用POD集群处于运行状态最低个数,也可以设置应用POD集群处于运行状态的最低百分比,这样可以保证在主动销毁(node异常导致的pod异常不再此范围内)应用POD的时候,不会一次性销毁太多的应用POD,从而保证业务不中断或业务SLA不降级。删除一个pod对应需要创建一个新pod
第十九章、调度器的调度流程和算法介绍
19.1、调度器架构
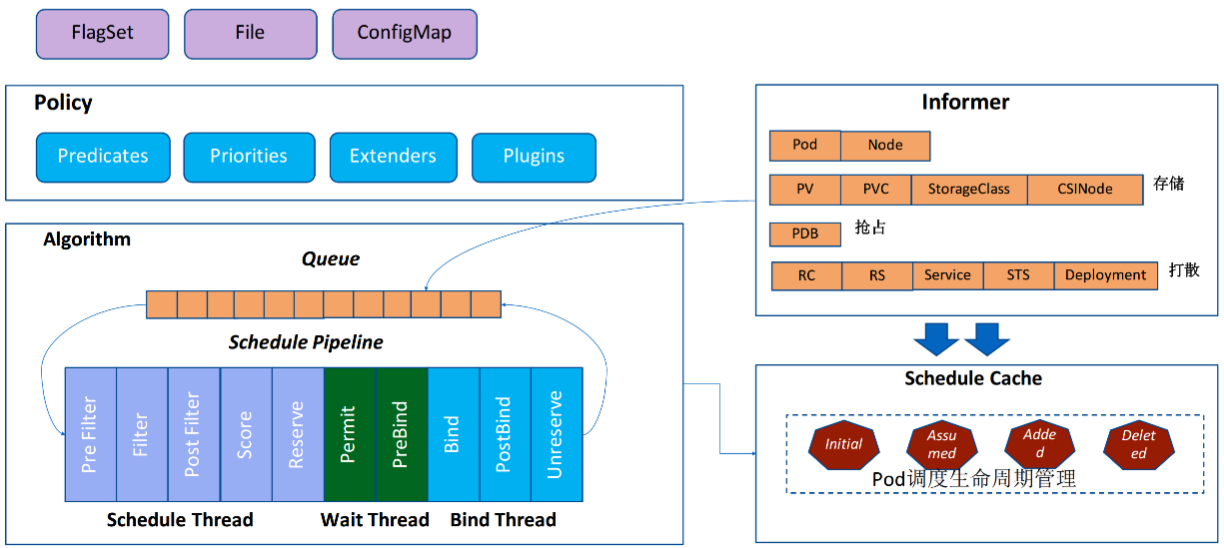
调度器架构:
 ![]
![]
- Policy
调度器启动时会通过配置文件 File、命令行参数、或者是配置好的 ConfigMap,来指定调度策略。调度策略主要包含:过滤器 (Predicates)、打分器 (Priorities) 、外部扩展的调度器 (Extenders)、以及最新支持的schedulerFramework的扩展点 (Plugins)。
- Informer
scheduler启动的时候会通过 kube-apiserver 去 watch 相关的数据,通过 Informer 机制将调度需要的数据如:Pod 、Node 、pv、pvc、在抢占流程中需要的 PDB 数据和打散算法需要的 Controller-Workload 数据,放入到调度队列中。并将这些数据做一定的预处理作为调度器的的 Cache。
- Algorithm 调度算法流程
通过 Informer 去 watch 到需要调度的 Pod 数据,放到Queue里面后。Schedule Pipeline 会一直循环从队列里面拿数据,然后经过调度流水线进行调度。调度流水线 (Schedule Pipeline) 循环主要有三个流程部分: 1、调度流程;2、Wait 流程;3、Bind 流程
调度流程: Schduler Thread 会经历 Pre Filter -> Filter -> Post Filter-> Score -> Reserve,可以简单理解为 Filter -> Score -> Reserve。Filter 阶段用于选择符合 Pod Spec 描述的 Nodes;Score 阶段用于从 Filter 后的 Nodes 进行打分和排序;Reserve 阶段将 Pod 跟排序后的最优 Node 的 NodeCache 中(预占用),表示这个 Pod 已经分配到这个 Node 上, 让下一个等待调度的 Pod 对这个 Node 进行 Filter 和 Score 的时候能看到刚才分配的 Pod。Schedule Thread为串行执行
wait流程: 这个阶段可以用来等待 Pod 关联的资源的 Ready 等待,例如等待 PVC 的 PV 创建成功,或者等待关联的 Pod 调度成功等;
Bind流程:用于将 Pod 和 Node 的关联持久化 Kube APIServer。整个调度流水线只有在 Scheduler Thread 阶段是串行的一个 Pod 一个 Pod 的进行调度,在 Wait 和 Bind 阶段 Pod 都是异步并行执行。
调度完成后,会去更新调度缓存 (Schedule Cache),如更新 Pod 数据的缓存,也会更新 Node 数据。
19.2、调度算法
注: kube-scheduler为每一个pod调度选择包含两个步骤过滤(Filter)和打分(Score),有的文献中也说预先(Predicates)和优选(Priorities)原理一样,这里以官方说法为准
参考: 官网链接 和 《Kubernetes权威指南-第四版》
19.2.1、调度的详细流程
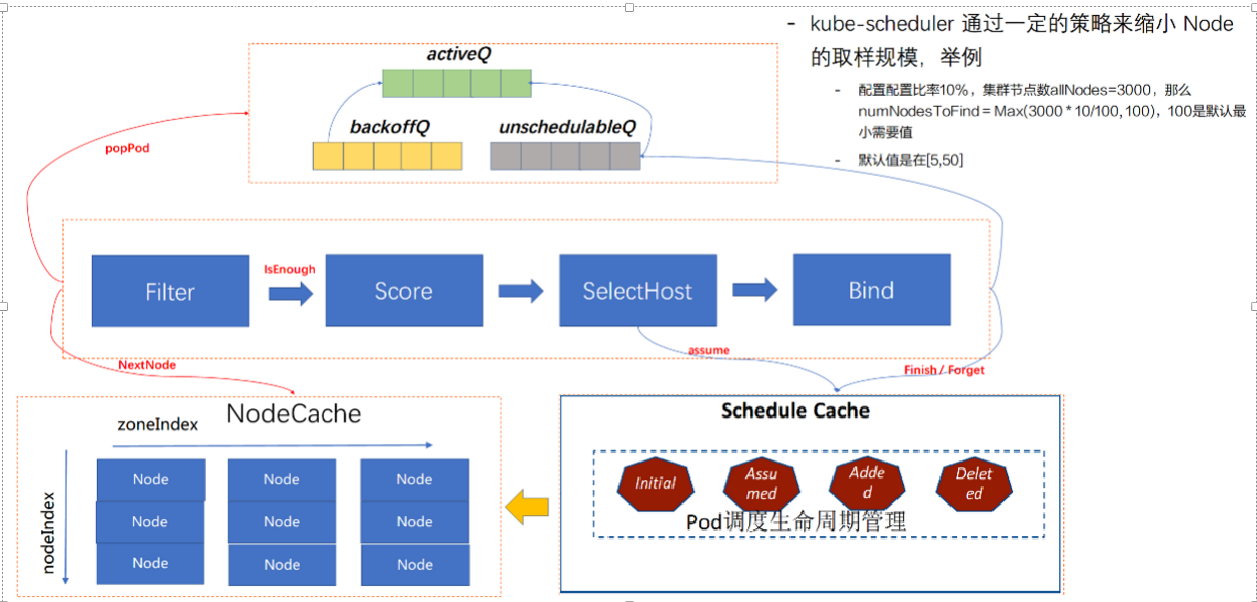
调度的详细流程中,调度队列分成三个队列:activeQ、backoffQ、unschedulableQ。
首先会从 activeQ 里面 pop 一个 Pod 出来,然后经过调度流水线去调度。拿到一个等待调度的 Pod后,从 NodeCache 里面拿到相关的 Node 数据进行过滤和打分,这里有一个非常有意思的算法,就是 NodeCache 部分,在过滤阶段,调度器提供一种能力,可以不用过滤所有节点,取到最优节点。可通过调度器提供的取样能力,通过配置比例来拿到部分节点进行过滤及打分,然后选中节点进行 bind 流程。提供这种能力需要在 NodeCache 里面注意一点,NodeCache 选中的节点需要足够分散,也就意味着容灾能力的增强。
- NodeCache
在 NodeCache 中,Node 是按照 zone 进行分堆。在 filter 阶段的时候,会为NodeCache 维护一个 zondeIndex和一个nodeIndex,每 Pop 一个 Node 进行(一个zone中选取一个node),zoneIndex 往后挪一个位置,然后从该 zone 的 node 列表中取一个 node 出来。可以看到上图纵轴有一个 nodeIndex,每次也会自增。如果当前 zone 的节点无数据,那就会从下一个 zone 中拿数据。大概的流程就是 zoneIndex 从左向右,nodeIndex 从上到下,从而保证拿到的 Node 节点是按照 zone 打散的。选出取样所需的节点数量后,就会进入下一个阶段,进入Score(打分器),打分排序后选择最优节点(进行预占,pod状态为Assume,并更新pod cache)然后进行bind,bind完成后,确定已经分配到node上后,才会更新pod状态为Added。如果bind失败pod状态会更新为initial并从node上清理pod数据。pod会被重新放入unSchedulableQ。
- isEnough
如果取样的规模已经达到了我们设置的取样比例,那 Filter 就会结束(isEnough),不会再去过滤下一个节点。 然后过滤到的节点会经过打分器(Score),打完分后会选择最优节点(SelectHost)作为 pod 的分配位置。
- pod状态转换:
Scheduler 启动的时候所有等待被调度的 Pod 都会进入 activieQ,activeQ 会按照 Pod 的 priority 进行排序,Scheduler Pipepline 会从 activeQ 获取一个 Pod 进行 Pipeline 执行调度流程,当调度失败之后会直接根据情况选择进入 unschedulableQ 或者 backoffQ,如果在当前 Pod 调度期间 Node Cache、Pod Cache 等 Scheduler Cache 有变化就进入 backoffQ,否则进入 unschedulableQ。
分配 Pod 到 Node 的时候,需要对 Node 的内存做处理,将这个 Pod 分配到这个 Node 上,这个过程可以称呼为账本预占。 预占的过程会把 Pod 的状态标记为 Assumed 的状态(处于内存态),紧接着就进入 bind 阶段,调用 kube-apiserver 将 Pod 的 NodeName 持久化到 etcd,这个时候 Pod 的状态还是 Assumed。只有在通过 Informer watch 到 Pod 数据已经确定分配到这个节点的时候,才会把状态变成 Added,
如果Bind 失败会做回退,会把预占用的账本做 Assumed 的数据退回 Initial,也就是把 Assumed 状态擦除,从 Node 里面把 Pod 数据账本擦除掉。并把 Pod 重新丢回到 unschedulableQ 队列里面。一般在一个调度周期里面,Cache 发生了变化才会把 Pod 放到 backoffQ 里面。在 backoffQ 里面等待的时间会比在 unschedulableQ 里面时间更短,backoffQ 里有一个降级策略,是 2 的指数次幂降级。假设重试第一次为 1s,那第二次就是 2s,第三次就是 4s,第四次就是 8s,最大到 10s,大概是这么一个机制。
unschedulableQ 里面的机制是:如果这个 Pod 一分钟没调度过,到一分钟的时候,它会把这个 Pod 重新丢回 activeQ。它的轮训周期是 30s。
- 取样规模:
它是怎么判断调度器的节点是足够的呢?按照默认值来说,默认的是在 [5%-50%] 之间,公式为 Max (5,50 - 集群的 node 数 / 125)。为什么公式是这样的呢?大家有兴趣的可以自己查一下。
这里举个例子:假如配置比率是 10%,节点规模为 3000 个节点,需要待选的节点数 Max(3000 * 10/100,100),最后得到的值是 300,跟 100 进行比较,100 默认是得到节点最小需要值。300 大于 100,那就按照 300 节点。在调度流水线里面,Filter 只要过滤到 300 个候选节点,就可以停止 Filter 流程了。
支持以下两种方式配置调度器的过滤和打分行为:
1、Scheduling Policies allow you to configure Predicates for filtering and Priorities for scoring.
2、Scheduling Profiles allow you to configure Plugins that implement different scheduling stages, including: QueueSort, Filter, Score, Bind, Reserve, Permit, and others. You can also configure the kube-scheduler to run different profiles.
19.2.2、调度器的算法实现-过滤Predicates
过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。 例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下, 这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
1、过滤器 (Predicates) 按照功能分为四类
- 存储相关
- NoVolumeZoneConflict,校验 pvc 上要求的 zone 是否和 Node 的 zone 匹配;
- MaxCSIVolumeCountPred,由于服务提供方对每个节点的单机最大挂载磁盘数是有限制的,所有这个是用来校验 pvc 上指定的 Provision 在 CSI plugin 上报的单机最大挂盘数;
- CheckVolumeBindingPred,在 pvc 和 pv 的 binding 过程中对其进行逻辑校验;
- NoDiskConfict,SCSI 存储不会被重复的 volume。
- Pod和Node匹配相关
- CheckNodeCondition,在 node 节点上有一个 Condition 的 type 值是不是 true,如果是 true 这个节点才会允许被调度;
- CheckNodeUnschedulable,在 node 节点上有一个 NodeUnschedulable 的标记,我们可以通过 kube-controller 对这个节点直接标记为不可调度,那这个节点就不会被调度了。在 1.16 的版本里,这个 Unschedulable 已经变成了一个 Taints。也就是说需要校验一下 Pod 上打上的 Tolerates 是不是可以容忍这个 Taints;
- PodToleratesNodeTaints,就是 Pod Tolerates 和 Node Taints 是否匹配;
- PodFitsHost,其实就是 Host 校验;
- MatchNodeSelector
- Pod和Pod匹配相关
- MatchinterPodAffinity:主要是 PodAffinity 和 PodAntiAffinity 的校验逻辑。
- Pod打散相关
- EvenPodsSpread;
- CheckServiceAffinity。
2、针对pod打散EventPodsSpread重点说明
spec描述:
- 描述符合条件的一组pod在指定的Topo上的打散要求
spec:
# 多个之间是and的关系
topologySpreadConstraint:
# maxSkew最大允许不均衡的数量
- maxSkew: 1
# 应用在哪个topo上,zone或者node,或者...
topologyKey: k8s.io/zone
# ScheduleAnyway | DoNotSchedule
# 当不满足maxSkew的策略,不调度,或者随便调度,在过滤阶段只关注DoNotSchedule
whenUnsatisfiable: DoNotSchedule
# 符合描述的一组pod
selector:
matchLabels:
app: foo
matchExpressions:
- key: app
operator: In
values: ['foo','foo2']
pod.Spec.TopologySpreadContraints新增了一组Pod按照指定TopologKey进行打散的描述
如下: 'app=foo'这个应用,在zone级别必须是被打散的,最大的不均衡数是1;actualSkew为当前不均衡数。
spec:
topologySpreadConstraint:
- maxSkew: 1
topologyKey: k8s.io/zone
whenUnsatisfiable: DoNotSchedule
selector:
matchLabels:
app: foo
假设pod都带有app=foo(当前zone1和zone2的pod都带有app:foo),集群有三个zone
+-------+-------+-------+
| zone1 | zone2 | zone3 |
+-------+-------+-------+
| pod | pod | |
+-------+-------+-------+
计算ActualSkew = count[topo] - min(count[topo])
ActualSkew的值为(1/1/0)
假设maxSkew=1
如果分配到zone1/zone2的话,skew的值为2 > maxSkew(1),因此只能分配到zone3
假设maxSkew=2
如果分配到zone1/zone2,skew的值为2/1/0,满足<=maxSkey,分配到zone3的话,skew的值(1/1/1),满足<=maxSkew,因此zone1/zone2/zone3都可以被选择
通过这种描述,它最大的用处就是当我们对自己的应用有容灾要求的,必须在每一个 zone 上是均衡部署的,这时就可以用这个规则去限定。比如所有的app为foo的应用maxSkew数量为1,那它在每个 zone 上都是均衡的。
扩展链接:
https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/
https://kubernetes.io/docs/reference/scheduling/policies/
19.2.3、调度器的算法实现-打分Priorities
打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。打分算法主要解决的问题就是集群的碎片、容灾、水位、亲和、反亲和等。
1、按照类别可以分为四大类:
- Node 水位
- Pod 打散 (topo,service,controller)
- Node 亲和&反亲和
- Pod 亲和&反亲和
2、资源水位

用户可使用资源水位比例进行score。资源水位主要有2个概念Request和Allocatable。
- 优先打散:我们应该把 Pod 分到可用资源最大比例的节点上。可用资源最大的公式就是 (Allocatable - Request) / Allocatable * Score。这个比例就是表示如果这个 Pod 分配到这个 Node 上,还剩余的资源比例越大的话,越优先分配到这个节点上,从而达到打散的要求。
- 优先堆叠:Request / Allocatable * Score。考虑的是如果 Pod 分配到 Request 的节点上,使用的资源比例越大,它应该越优先。
- 碎片率:{ 1 - Abs[CPU(Request / Allocatable) - Mem(Request / Allocatable)] } * Score。是用来考虑 CPU 的使用比例和内存使用比例的差值,这个差值就叫做碎片率。如果这个差值越大,就表示碎片越大,优先不分配到这个节点上。如果这个差值越小,就表示这个碎片率越小,那应该优先分配到这个节点上。
- 指定比率:我们可以通过打分器,当资源使用的比率达到某个值时,用户指定配置参数可以指定不同比率的分数,从而达到控制集群上每个节点 node 的分布。
3、Pod打散
Pod 打散为了解决的问题:支持符合条件的一组 Pod 在不同 topology 上部署的 spread 需求。
-
SelectorSpreadPriority:
- 在Node上计数
- TopoPods = Exists Pod匹配Income Pod的controller的workload的slector条件
- (sum(TopoPods) - TopoPods) / Sum(TopoPods)
它是为了满足 Pod 所属的 Controller 上所有的 Pod 在 Node 上打散的要求。
实现方式:它会依据待分配的 Pod 所属的 controller,计算该 controller 下的所有 Pod,假设总数为 T,对这些 Pod 按照所在的 Node 分组统计;假设为 N (表示为某个 Node 上的统计值),那么对 Node上的分数统计为 (T-N)/T 的分数,值越大表示这个节点的 controller 部署的越少,分数越高,从而达到 workload 的 pod 打散需求。
-
ServiceSpreadingPriority
- 官方注释上说大概率会用来替换 SelectorSpreadPriority
- 在Node上计数,在每个node上进行计算
- TopoPods : 满足Pod所在的service的selector条件
- (sum(TopoPods) - TopoPods) / Sum(TopoPods)
-
EvenPodsSpreadPriority
- spec指定的topologyKey
- Topopods = 满足spec的labelSelector
- 算分公式:
- Node = 按照Node级别累计TopoPods
- MaxDif = Total - Min(Node)
- (Total - Node) / MaxDif
用来指定一组符合条件的 Pod 在某个拓扑结构上的打散需求,这样是比较灵活、比较定制化的一种方式,使用起来也是比较复杂的一种方式。因为这个使用方式可能会一直变化,我们假设这个拓扑结构是这样的:Spec 是要求在 node 上进行分布的,我们就可以按照上图中的计算公式,计算一下在这个 node 上满足 Spec 指定 labelSelector 条件的 pod 数量,然后计算一下最大的差值,接着计算一下 Node 分配的权重,如果说这个值越大,表示这个值越优先。
4、Node亲和和反亲和
-
NodeAffinityPriority,这个是为了满足 Pod 和 Node 的亲和 & 反亲和;
- TopoPods: 累计满足affinity次数
- TopoPods /Max(TopoPods) * MaxPriority
-
ServiceAntiAffinity,是为了支持 Service 下的 Pod 的分布要按照 Node 的某个 label 的值进行均衡。比如:集群的节点有云上也有云下两组节点,我们要求服务在云上云下均衡去分布,假设 Node 上有某个 label,那我们就可以用这个 ServiceAntiAffinity 进行打散分布;
-
NodeLabelPrioritizer,主要是为了实现对某些特定 label 的 Node 优先分配,算法很简单,启动时候依据调度策略 (SchedulerPolicy)配置的 label 值,判断 Node 上是否满足这个label条件,如果满足条件的节点优先分配;
-
ImageLocalityPriority,节点亲和主要考虑的是镜像下载的速度。如果节点里面存在镜像的话,优先把 Pod 调度到这个节点上,这里还会去考虑镜像的大小,比如这个 Pod 有好几个镜像,镜像越大下载速度越慢,它会按照节点上已经存在的镜像大小优先级亲和。
5、Pod亲和和反亲和
- InterPodAffinityPriority
- 先介绍一下使用场景:
- 第一个例子,比如说应用 A 提供数据,应用 B 提供服务,A 和 B 部署在一起可以走本地网络,优化网络传输;
- 第二个例子,如果应用 A 和应用 B 之间都是 CPU 密集型应用,而且证明它们之间是会互相干扰的,那么可以通过这个规则设置尽量让它们不在一个节点上。
- 先介绍一下使用场景:
- NodePreferAvoidPodsPriority
- 用于针对RC(Replicas Controller)和RS(Replica set) 在node 上加 annotation 声明哪些 controller 不要分配到 Node 上来实现RC/RS的反亲和
19.2.4、配置调度policies
配置kube-scheduler --policy-config-file <filename> or kube-scheduler --policy-configmap <ConfigMap> 来配置Policies
方式1-policy-config-file:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "EqualPriority", "weight" : 1}
]
}
方式2-独立自主使用插件,并指定kube-scheduler运行不同的配置文件
参考:https://kubernetes.io/docs/reference/scheduling/config/#profiles
19.3、如何配置调度器
- 如何启动一个调度器:
- 默认启动的调度器,什么参数都不指定。查看默认配置:
--write-config-to - 指定调度器配置文件:
--config
- 默认启动的调度器,什么参数都不指定。查看默认配置:
- 配置文件解析:
- schedulerName: 该调度器负责哪些pod的调度,默认为 default-scheduler
- algorithmSource: 配置算法提供者,目前提供三种方式:Provider、file、configMap
- hardPodAffinitySymnetricweight,配置 PodAffinity 和 NodeAffinity 的权重是多少
- percentageOfNodesToscore,filter到的节点占总节点数的比率,用于减少 Node 节点的取样规模
- bindTimeoutSeconds,指定 bind 阶段的操作时间,单位是秒
- disablePreemption,关闭抢占协议;
- ClientConnection,是用来配置跟 kube-apiserver 交互的一些参数配置。比如 contentType,是用来跟 kube-apiserver 交互的序列化协议,这里指定为 protobuf;
配置文件Profiles和plugins格式说明: https://kubernetes.io/docs/reference/scheduling/config/
19.4、如何扩展调度器
举例:GPU share。在扩展调度器里面会记录每个卡上分配的内存大小,官方调度器只负责 Node 节点上总的显卡内存是否足够。这里扩展资源叫 example/gpu-men: 200g,假设有个 Pod 要调度,通过 kube-scheduler 会看到我们的扩展资源,这个扩展资源配置要走扩展调度器,在调度阶段就会通过配置的 url 地址来调用扩展调度器,从而能够达到调度器能够实现 gpu-share 的能力。
1、扩展点用途:
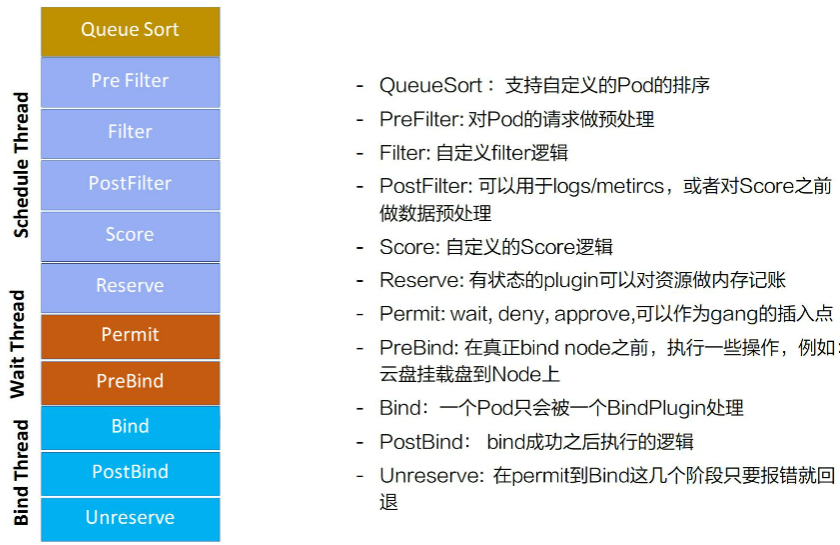
Scheduling happens in a series of stages that are exposed through the following extension points:
1、QueueSort: These plugins provide an ordering function that is used to sort pending Pods in the scheduling queue. Exactly one queue sort plugin may be enabled at a time.
2、PreFilter: These plugins are used to pre-process or check information about a Pod or the cluster before filtering. They can mark a pod as unschedulable.
3、Filter: These plugins are the equivalent of Predicates in a scheduling Policy and are used to filter out nodes that can not run the Pod. Filters are called in the configured order. A pod is marked as unschedulable if no nodes pass all the filters.
4、PreScore: This is an informational extension point that can be used for doing pre-scoring work.
5、Score: These plugins provide a score to each node that has passed the filtering phase. The scheduler will then select the node with the highest weighted scores sum.
6、Reserve: This is an informational extension point that notifies plugins when resources have been reserved for a given Pod. Plugins also implement an Unreserve call that gets called in the case of failure during or after Reserve.
7、Permit: These plugins can prevent or delay the binding of a Pod.
8、PreBind: These plugins perform any work required before a Pod is bound.
9、Bind: The plugins bind a Pod to a Node. Bind plugins are called in order and once one has done the binding, the remaining plugins are skipped. At least one bind plugin is required.
10、PostBind: This is an informational extension point that is called after a Pod has been bound.
11、UnReserve: This is an informational extension point that is called if a Pod is rejected after being reserved and put on hold by a Permit plugin
For each extension point, you could disable specific default plugins or enable your own. For example:
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- plugins:
score:
disabled:
- name: NodeResourcesLeastAllocated
enabled:
- name: MyCustomPluginA
weight: 2
- name: MyCustomPluginB
weight: 1
For each extension point, you could disable specific default plugins or enable your own. For example:
- QueueSort:用来支持自定义 Pod 的排序。如果指定 QueueSort 的排序算法,在调度队列里面就会按照指定的排序算法来进行排序;
- Prefilter:对 Pod 的请求做预处理,比如 Pod 的缓存,可以在这个阶段设置;
- Filter:就是对 Filter 做扩展,可以加一些自己想要的 Filter,比如说刚才提到的 gpu-shared 可以在这里面实现;
- PostFilter:可以用于 logs/metircs,或者是对 Score 之前做数据预处理。比如说自定义的缓存插件,可以在这里面做;
- Score:就是打分插件,通过这个接口来实现增强;
- Reserver:对有状态的 plugin 可以对资源做内存记账;
- Permit:wait、deny、approve,可以作为 gang 的插入点。这个可以对每个 pod 做等待,等所有 Pod 都调度成功、都达到可用状态时再去做通行,假如一个 pod 失败了,这里可以 deny 掉;
- PreBind:在真正 bind node 之前,执行一些操作,例如:云盘挂载盘到 Node 上;
- Bind:一个 Pod 只会被一个 BindPlugin 处理;
- PostBind:bind 成功之后执行的逻辑,比如可以用于 logs/metircs;
- Unreserve:在 Permit 到 Bind 这几个阶段只要报错就回退。比如说在前面的阶段 Permit 失败、PreBind 失败, 都会去做资源回退。
2、并发模型
并发模型意思是主调度流程是在 Pre Filter 到 Reserve,如上图浅蓝色部分所示。从 Queue 拿到一个 Pod 调度完到 Reserve 就结束了,接着会把这个 Pod 异步交给 Wait Thread,Wait Thread 如果等待成功了,就会交给 Bind Thread,就是这样一个线程模型。
参考链接:https://kubernetes.io/docs/reference/scheduling/config/#extension-points
暂不做深入了解,用到的时候再进行详细了解
第二十章、GPU管理和Device Plugin工作机制
20.1、需求背景
2016 年,随着 AlphaGo 的走红和 TensorFlow 项目的异军突起,一场名为 AI 的技术革命迅速从学术圈蔓延到了工业界,所谓 AI 革命从此拉开了帷幕。
经过三年的发展,AI 有了许许多多的落地场景,包括智能客服、人脸识别、机器翻译、以图搜图等功能。其实机器学习或者说是人工智能,并不是什么新鲜的概念。而这次热潮的背后,云计算的普及以及算力的巨大提升,才是真正将人工智能从象牙塔带到工业界的一个重要推手。
与之相对应的,从 2016 年开始,Kubernetes 社区就不断收到来自不同渠道的大量诉求。希望能在 Kubernetes 集群上运行 TensorFlow 等机器学习框架。这些诉求中,除了前面课程所介绍的,像 Job 这些离线任务的管理之外,还有一个巨大的挑战:深度学习所依赖的异构设备及英伟达的 GPU 支持。
我们不禁好奇起来:Kubernetes 管理 GPU 能带来什么好处呢?本质上是成本和效率的考虑。由于相对 CPU 来说,GPU 的成本偏高。在云上单 CPU 通常是一小时几毛钱,而 GPU 的花费则是从单 GPU 每小时 10 元 ~ 30 元不等,这就要想方设法的提高 GPU 的使用率。
为什么要用 Kubernetes 管理以 GPU 为代表的异构资源?
具体来说是三个方面:
- 加速部署:通过容器构想避免重复部署机器学习复杂环境;
- 提升集群资源使用率:统一调度和分配集群资源;
- 保障资源独享:利用容器隔离异构设备,避免互相影响。
首先是加速部署,避免把时间浪费在环境准备的环节中。通过容器镜像技术,将整个部署过程进行固化和复用,如果同学们关注机器学习领域,可以发现许许多多的框架都提供了容器镜像。我们可以借此提升 GPU 的使用效率。
通过分时复用,来提升 GPU 的使用效率。当 GPU 的卡数达到一定数量后,就需要用到 Kubernetes 的统一调度能力,使得资源使用方能够做到用即申请、完即释放,从而盘活整个 GPU 的资源池。
而此时还需要通过 Docker 自带的设备隔离能力,避免不同应用的进程运行同一个设备上,造成互相影响。在高效低成本的同时,也保障了系统的稳定性。
20.2、GPU的容器化
如何利用容器运行GPU:
- 构建支持GPU的容器镜像: 可以使用官方容器镜像(NVIDIA/CUDA,Tensorflow/tensorflow),或者基于官方镜像构建自己的镜像
- 利用Docker将该容器run 起来,并把GPU设备
--dev和依赖库--volume映射到容器中
1、如何在宿主机上安装GPU应用
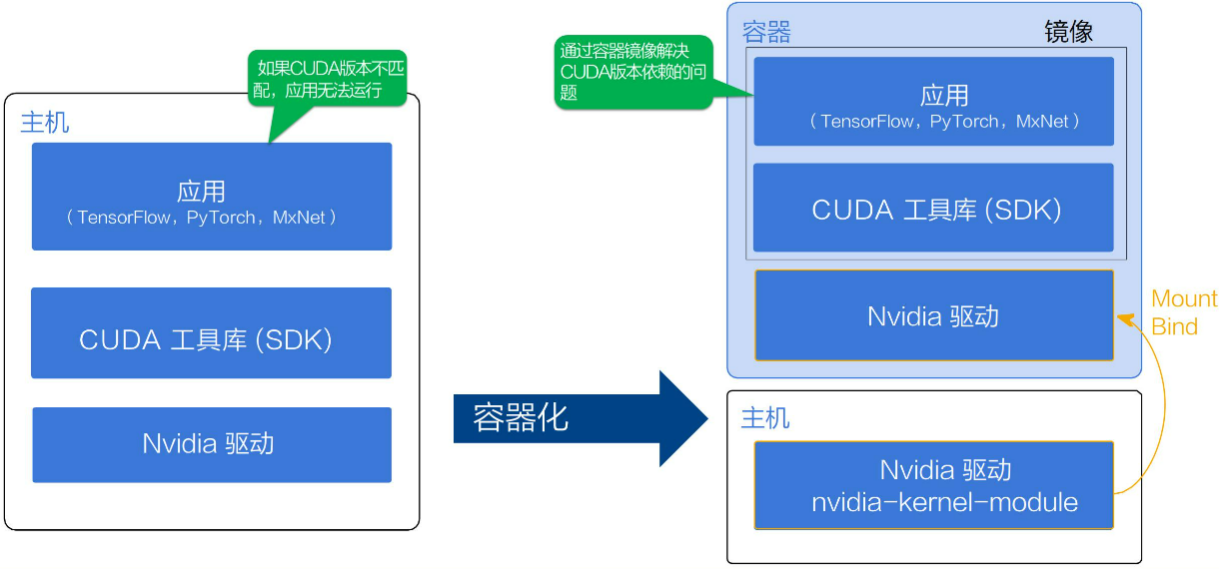
底层是安装驱动,中间是CUDA库,最上层是机器学习框架。容器镜像构建一般驱动和CUDA分开,这样的好处后可以使用不同版本的CUDA镜像。
2、利用容器运行GPU程序
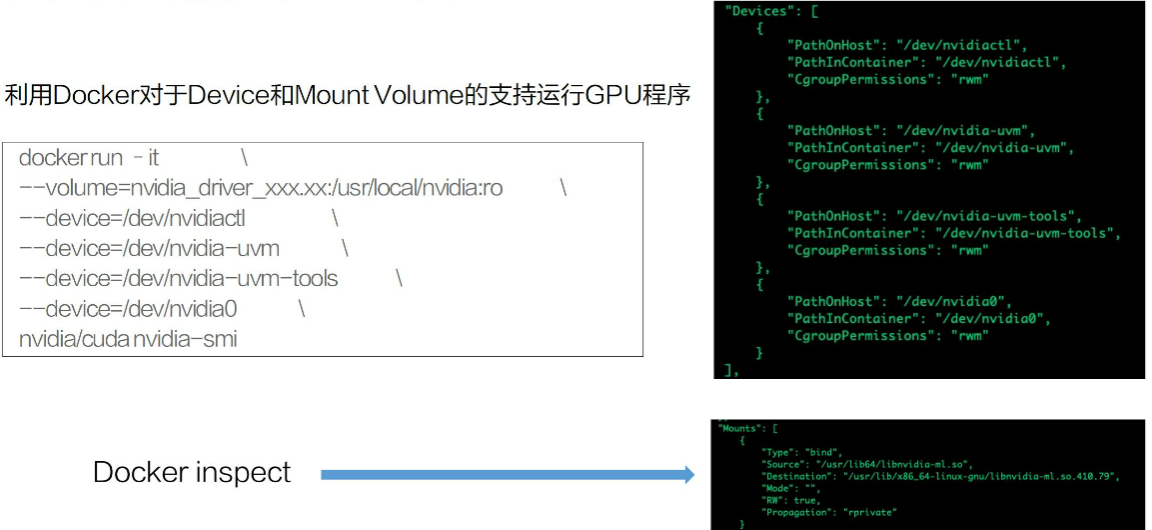
这里比较复杂的是GPU 应用依赖的驱动库。对于深度学习,视频处理等不同场景,所使用的一些驱动库并不相同。这又需要依赖 Nvidia 的领域知识,而这些领域知识就被贯穿到了 Nvidia 的容器之中。
注意,新版docker,可以支持 docker --gpu 方式直接使用 gpu资源 链接
20.3、k8s的GPU管理
参考:https://github.com/NVIDIA/k8s-device-plugin
-
1、安装NVIDIA驱动
- yum install gcc kerbel-devel-$(uname -r) #驱动需要编译内核
- sh ./NVIDIA-linux-x86_64*.run
-
2、安装NVIDIA Docker2
- yum install nvidia-docker2
- 重新加载docker daemon,查看daemon.json是否docker runtime已经替换。也可以通过docker info确认
-
3、部署NVIDIA Device Plugin
- kubectl apply -f nvidia-device-plugin.yml 链接 //K8s版本后要求,
- kubectl describe node/${GPU_NODENAME} |grep -i nvidia 查看
- kubectl exec -it ${gpu_podname} -- nvidia-smi 查看隔离效果
创建示例Pod: apiVersion: v1 kind: Pod metadata: name: gpu-pod spec: containers: - name: cuda-container image: nvcr.io/nvidia/cuda:9.0-devel resources: limits: nvidia.com/gpu: 2 # requesting 2 GPUs - name: digits-container image: nvcr.io/nvidia/digits:20.12-tensorflow-py3 resources: limits: nvidia.com/gpu: 2 # requesting 2 GPUs
20.4、工作机制
Kubernetes 本身是通过插件扩展的机制来管理 GPU 资源的,具体来说这里有两个独立的内部机制。
- Extended Resource
- 允许用户自定义资源名称。而该资源的度量是整数级别,这样做的目的在于通过一个通用的模式支持不同的异构设备,包括 RDMA、FPGA、AMD GPU 等等,而不仅仅是为 Nvidia GPU 设计的;
- Device Plugin Framework
- 允许第三方设备提供商以插件的方式对设备进行全生命周期的管理,而 Device Plugin Framework 建立 Kubernetes 和 Device Plugin 模块之间的桥梁。它一方面负责设备信息的上报到 Kubernetes,另一方面负责设备的调度选择。
20.4.1、Extended Resource的上报
Extend Resources 属于 Node-level 的 api,完全可以独立于 Device Plugin 使用。而上报 Extend Resources,只需要通过一个 PACTH API 对 Node 对象进行 status 部分更新即可,而这个 PACTH 操作可以通过一个简单的 curl 命令来完成。这样,在 Kubernetes 调度器中就能够记录这个节点的 GPU 类型,和对应的资源数量。当然如果使用的是 Device Plugin,就不需要做这个 PACTH 操作,只需要遵从 Device Plugin 的编程模型,在设备上报的工作中 Device Plugin 就会完成这个操作。

20.4.2、Device Plugin的工作机制
整个 Device Plugin 的工作流程可以分成两个部分:
- 一个是启动时刻的资源上报;
- 另一个是用户使用时刻的调度和运行。
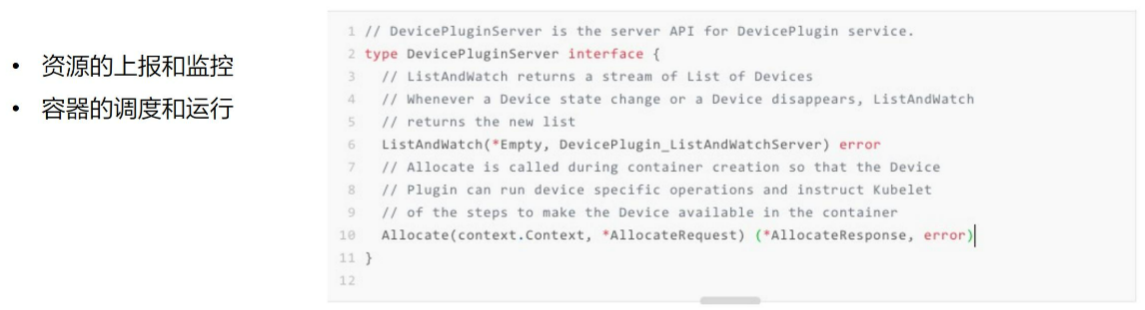
Device Plugin 的开发非常简单。主要包括最关注与最核心的两个事件方法:
-
其中 ListAndWatch 对应资源的上报,同时还提供健康检查的机制。当设备不健康的时候,可以上报给 Kubernetes 不健康设备的 ID,让 Device Plugin Framework 将这个设备从可调度设备中移除;
-
而 Allocate 会被 Device Plugin 在部署容器时调用,传入的参数核心就是容器会使用的设备 ID,返回的参数是容器启动时,需要的设备、数据卷以及环境变量。
20.4.3、Device Plugin整个资源上报和监控流程
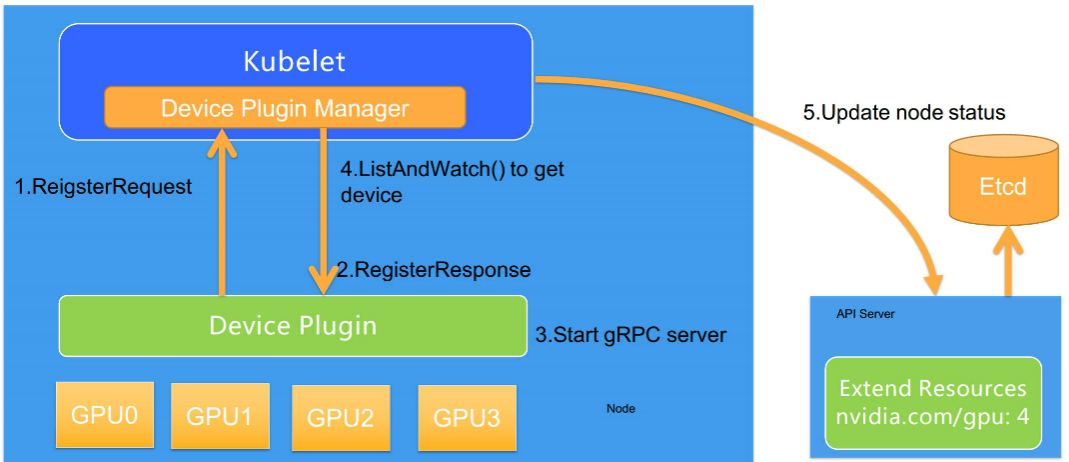
对于每一个硬件设备,都需要它所对应的 Device Plugin 进行管理,这些 Device Plugin 以客户端的身份通过 GRPC 的方式对 kubelet 中的 Device Plugin Manager 进行连接,并且将自己监听的 Unis socket api 的版本号和设备名称比如 GPU,上报给 kubelet。
整个 Device Plugin 资源上报的整个流程。总的来说,整个过程分为四步,其中前三步在节点上,第四步是 kubelet 和 api-server 的交互。
- 第一步是 Device Plugin 的注册,需要 Kubernetes 知道要跟哪个 Device Plugin 进行交互。这是因为一个节点上可能有多个设备,需要 Device Plugin 以客户端的身份向 Kubelet 汇报三件事情。
- 我是谁?就是 Device Plugin 所管理的设备名称,是 GPU 还是 RDMA;
- 我在哪?就是插件自身监听的 unis socket 所在的文件位置,让 kubelet 能够调用自己;
- 交互协议,即 API 的版本号。
- 第二步是服务启动,Device Plugin 会启动一个 GRPC 的 server。在此之后 Device Plugin 一直以这个服务器的身份提供服务让 kubelet 来访问,而监听地址和提供 API 的版本就已经在第一步完成了;
- 第三步,当该 GRPC server 启动之后,kubelet 会建立一个到 Device Plugin 的 ListAndWatch 的长连接, 用来发现设备 ID 以及设备的健康状态。当 Device Plugin 检测到某个设备不健康的时候,就会主动通知 kubelet。而此时如果这个设备处于空闲状态,kubelet 会将其移除可分配的列表。但是当这个设备已经被某个 Pod 所使用的时候,kubelet 就不会做任何事情
- 第四步,kubelet 会将这些设备暴露到 Node 节点的状态中,把设备数量发送到 Kubernetes 的 api-server 中。后续调度器可以根据这些信息进行调度。
需要注意的是 kubelet 在向 api-server 进行汇报的时候,只会汇报该 GPU 对应的数量。而 kubelet 自身的 Device Plugin Manager 会对这个 GPU 的 ID 列表进行保存,并用来具体的设备分配。而这个对于 Kubernetes 全局调度器来说,它不掌握这个 GPU 的 ID 列表,它只知道 GPU 的数量。这就意味着在现有的 Device Plugin 工作机制下,Kubernetes 的全局调度器无法进行更复杂的调度。比如说想做两个 GPU 的亲和性调度,同一个节点两个 GPU 可能需要进行通过 NVLINK 通讯而不是 PCIe 通讯,才能达到更好的数据传输效果。在这种需求下,目前的 Device Plugin 调度机制中是无法实现的。
20.4.4、pod额调度和运行
Pod 想使用一个 GPU 的时候,它只需要像之前的例子一样,在 Pod 的 Resource 下 limits 字段中声明 GPU 资源和对应的数量 (比如nvidia.com/gpu: 1)。Kubernetes 会找到满足数量条件的节点,然后将该节点的 GPU 数量减 1,并且完成 Pod 与 Node 的绑定。
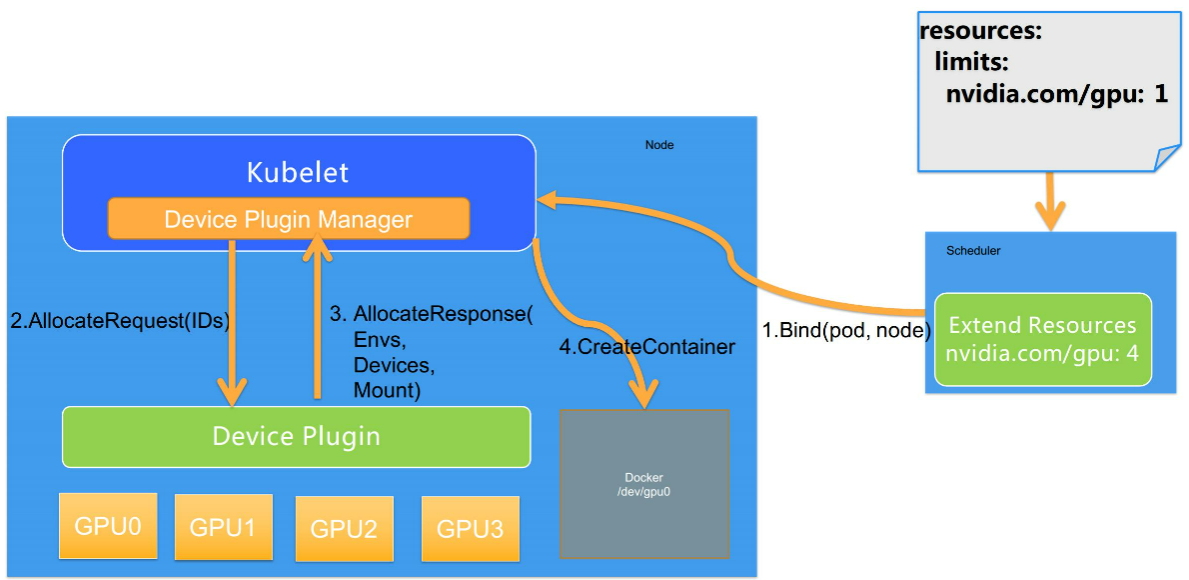
绑定成功后,自然就会被对应节点的 kubelet 拿来创建容器。而当 kubelet 发现这个 Pod 的容器请求的资源是一个 GPU 的时候,kubelet 就会委托自己内部的 Device Plugin Manager 模块,从自己持有的 GPU 的 ID 列表中选择一个可用的 GPU 分配给该容器。此时 kubelet 就会向本机的 Device Plugin 发起一个 Allocate 请求,这个请求所携带的参数,正是即将分配给该容器的设备 ID 列表。
Device Plugin 收到 AllocateRequest 请求之后,它就会根据 kubelet 传过来的设备 ID,去寻找这个设备 ID 对应的设备路径、驱动目录以及环境变量,并且以 AllocateResponse 的形式返还给 kubelet。
AllocateResponse 中所携带的设备路径和驱动目录信息,一旦返回给 kubelet 之后,kubelet 就会根据这些信息执行为容器分配 GPU 的操作,这样 Docker 会根据 kubelet 的指令去创建容器,而这个容器中就会出现 GPU 设备。并且把它所需要的驱动目录给挂载进来,至此 Kubernetes 为 Pod 分配一个 GPU 的流程就结束了。
20.5、扩展
1、Devie Plugin机制的缺陷
- 设备资源调度发生在kubelet层面,缺乏全局调度视角
- 资源上报信息有限导致精细度不足,单纯以数字描述,如果想要指定不同类型的GPU呢?
- 调度策略简单,并且无法配置,无法应对复杂场景
2、社区的异构资源调度方案
- Nvidia GPU Device Plugin:
https://github.com/NVIDIA/k8s-device-plugin - GPU Share Device Plugin:
https://github.com/AliyunContainerService/gpushare-device-plugin - DRMA Device Plugin:
https://github.com/Mellanox/k8s-rdma-sriov-dev-plugin - FPGA Device Plugin: ...
参考链接: https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/
第二十一章、kubernetes存储架构及插件使用
21.1、Kubernetes挂载Volume过程
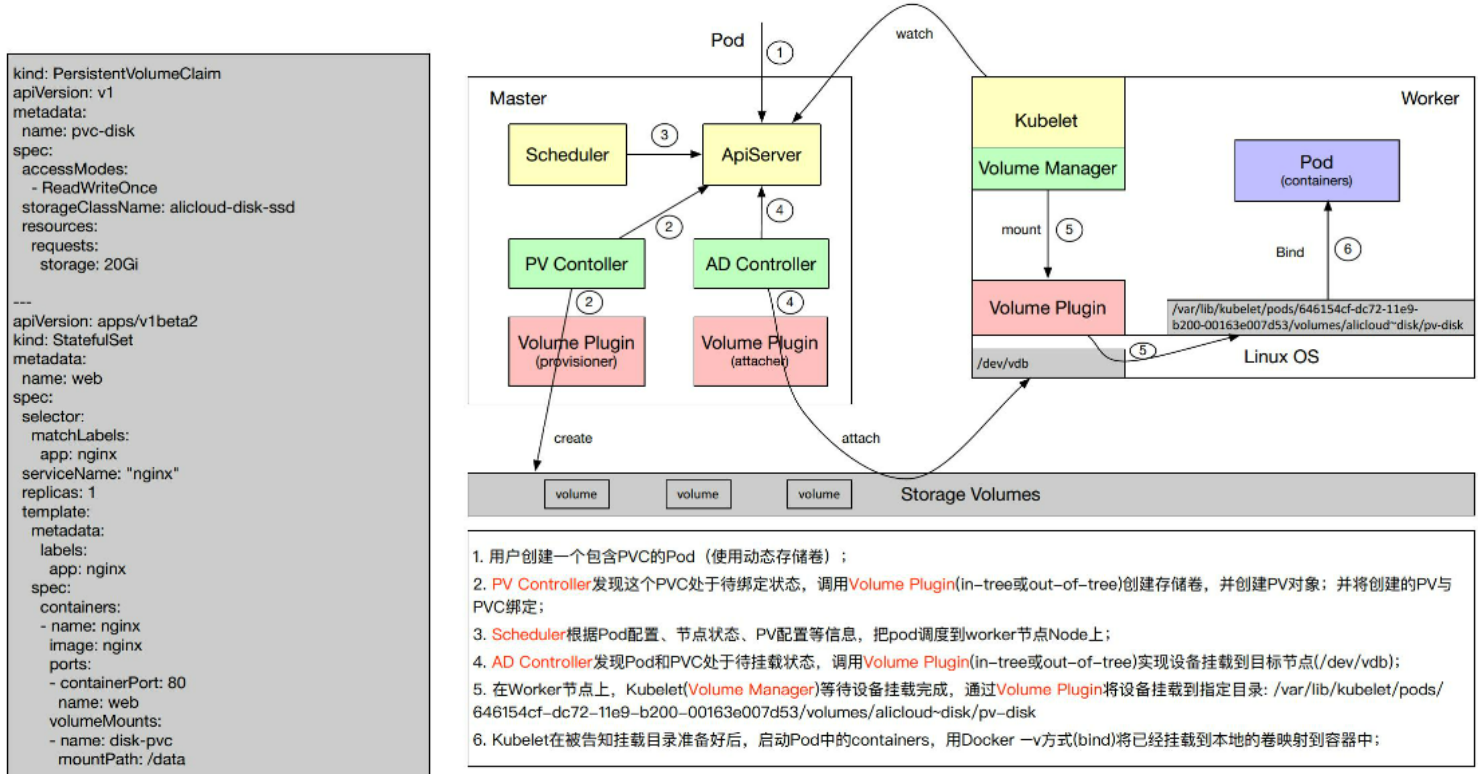
1、用户创建pvc和pod后
2、pv controller会watch到api-server获取PVC状态,发现PVC处于unbind状态,pv controller尝试调用将pv和pvc绑定,从集群中找到一个合适的pv进行绑定。如果发现集群中没有合适的pv,就调用Volume Plugin去做provisioner(去具体的一个Storage volume上去创建一个volume,并且创建一个pv对象),然后将pv和pvc绑定。
3、Scheduler根据一定的规则选择合适的worker node进行pod的调度
4、AD Controller发现Pod调度到某一个node上后,这个pod定义的pv还没有挂载。就调用Volume plugin将volume设备挂载到目标节点的设备上去
5、kubelet的volume manger组件,发现一个pod挂载到自己所在的worker上后,并且pod的volume已完成了挂载(步骤4),调用volume plugin将设备挂载到pod的工作目录中去,volume manager也会做一些格式化等操作
6、最后一步把本地的一个pod的目录映射到容器中
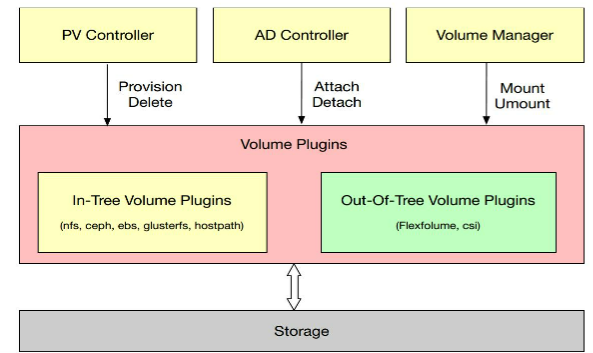
21.2、Kubernetes存储架构
(D:\PERSON_BOOK\k8s\魂尊.assets\image-20210223110644875.png)
Provison => Attach => Mount;Umount=> Detach => Delete;
- PV Controller: 负责PV/PVC的绑定、生命周期管理,并根据需求进行数据卷的Provision/Delete操作
- AD Controller: 负责存储设备的Attach/Detach操作,将设备挂载到目标节点;
- Volume Manager: 管理卷的Mount/Unmount操作、卷设备的格式化等
- Volume Plugins: 扩展各种存储类型的卷管理能力,实现第三方存储的各种操作能力与Kubernetes存储系统结合;
- Scheduler: 实现Pod调度能力,存储相关的调度器实现了对存储卷配置进行调度;
21.2.1、PV Controller介绍
1、主要概念:
- PersistentVolume: 持久存储卷,详细定义预挂载存储空间的各项参数;无NameSpace限制,一般由Admin创建维护PV;
- PersistentVolumeClaim:持久化存储卷定义,用户使用的存储接口,对存储细节无感知,属于某NameSpace内;
- StorageClasss: 存储类,创建PV存储的模板类,即系统会按照StorageClass定义的存储模板创建存储卷(包括真实存储空间和PV对象)
2、主要任务:
- PV、PVC生命周期管理:创建、删除PV对象;负责pv、pvc的状态转换
- 绑定PVC、PV对象:一个PVC必须与一个PV绑定后才能被应用使用,pv-controller会根据绑定条件和对象状态对PV、PVC进行Bound、Unbound操作
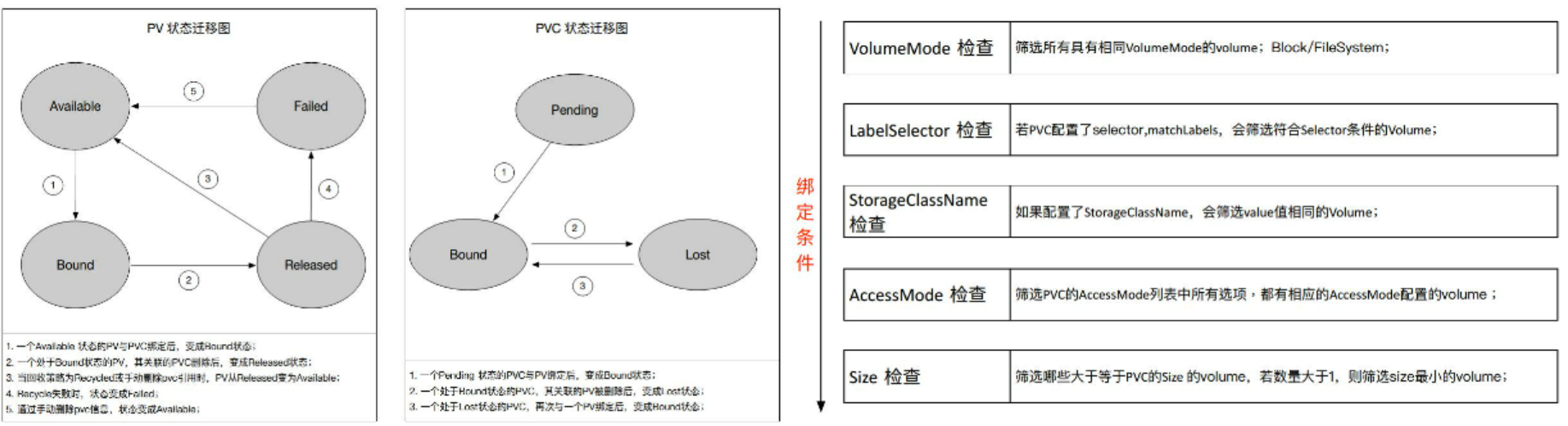
# PV状态迁移图
pv创建好后,处于Availeable状态,
一个pv和一个pvc绑定后pv处于Bound状态。
一个处于Bound状态的pv,其关联的PVC删除后,变成Released状态
当ReclaimPolicy为Recycle或手动删除pvc引用时,pv从Released状态变为available,如果policy为delete,则pv被删除(还有一个policy为retain保留)
recycle失败时,pv状态变为failed
# PVC状态前意图
pvc创建后处于pending状态
pvc和pv绑定后pvc处于bound状态
bound状态的pvc对应的pv被删除后,pvc处于lost状态
lost状态在pvc和pv重新绑定后重新处于bound状态
#绑定条件 //pvc和pv需要绑定的时候,会进行一些条件检查
VolumeMode检查:pv和pvc的volumemode必须匹配,是Block类型还是FileSystem类型
LabelSelector检查:pvc可以定义selector标签筛选pv
StorageClassName检查:pv必须有相同的storageclassname才会被筛选到。
AccessMode检查:ReadWriteOnce,ReadWriteMany等标签。pv必须有匹配的accessmode才可以
Size检查:pv的size大于pvc声明的size
3、PV Controller实现
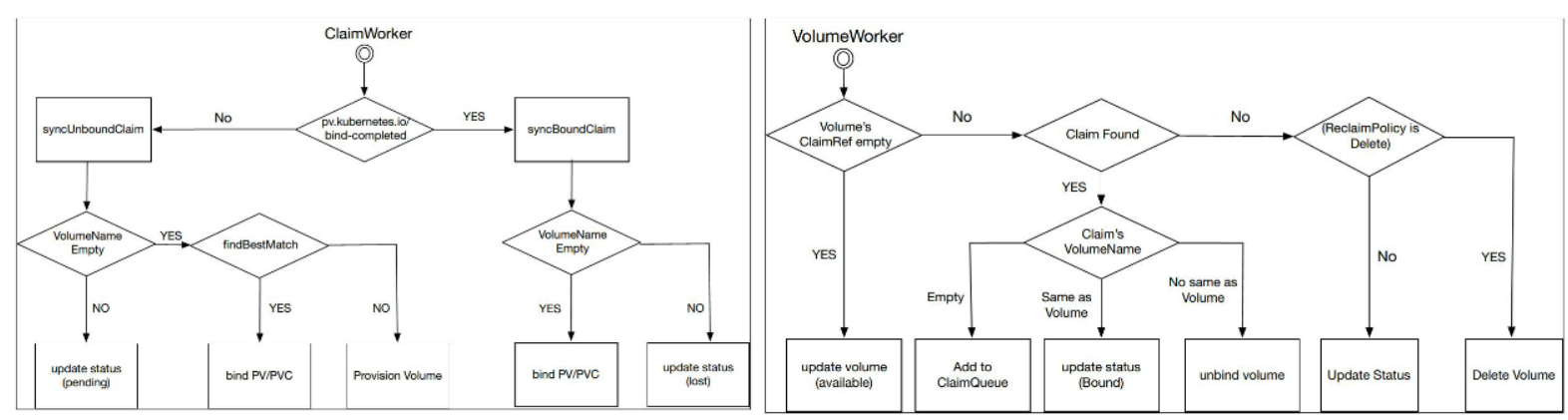
Pv Controller实现主要有两个实现逻辑,一个是ClaimWorker,另一个是VolumeWorker
ClaimWorker:
- 实现PVC的状态迁移;
- 通过系统标签 "pv.kubernetes.io/bind-completed"来标识pvc是为Bound状态
- 当pvc为Unbound时,触发PV筛选逻辑(上一个图的“绑定条件”),如果找到合适的PV则Bound,如果找不到则触发Provision(自己去创建一个pv,若不是In-Tree Provisioner则等待)
VolumeWorker:
- 实现PV的状态迁移
- 通过ClaimRef来判断PV是Bound还是Released;PV状态为Released时,若Reclaim为Delete,则执行删除逻辑;
- 如果ClaimRef有值(是一个pvc的值)。就在集群中查找该pvc ,如果找到就说明pv处于Bound状态,说明pv是ok的,会进行相应的状态同步。如果找不到对应的pvc则说明pod处于绑定过的状态(但是pvc已经被删除),根据ReclaimPolicy执行一些操作,如果policy为delete则删除volume,如果不是delete则进行状态的同步即可
21.2.2、AD Controller介绍
AD Controller(Addact/Detach)负责将数据卷挂载/卸载到特定节点上;
核心对象:DesiredStateOfWorld,ActualStateOfWorld;
核心逻辑:Reconcile,desiredStateOfWorldPopulator;
DesiredStateOfWorld:集群中预期要达到的数据卷挂载状态;
ActualStateOfWorld:集群中实际存在的数据卷挂载状态;
desiredStateOfWorldPopulator: 根据卷挂载状态,更新DSW、ASW数据;
reconcile: 根据DSW、ASW对象状态,轮询执行Attach、Detach操作;

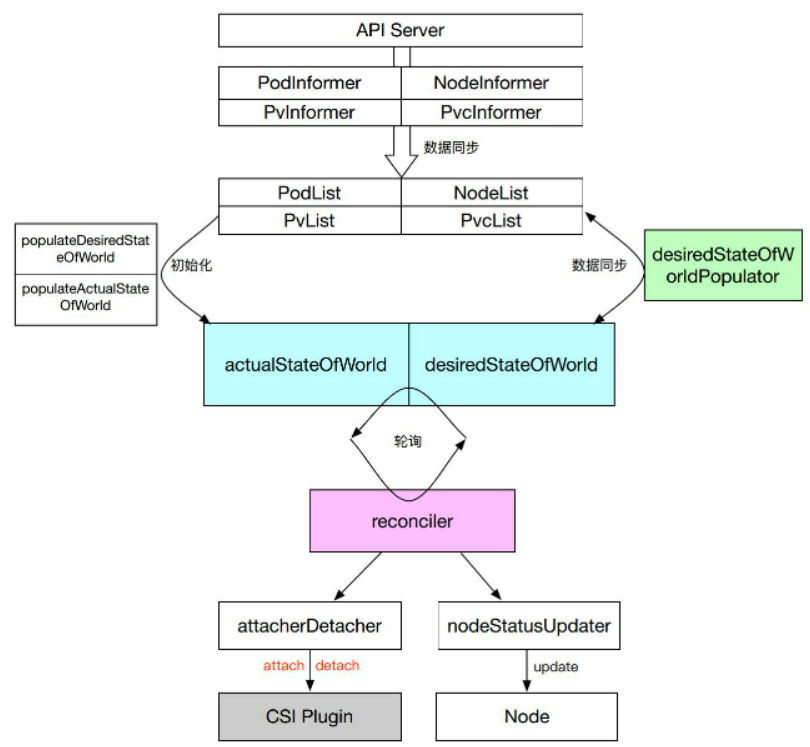
1、*Informer负责从apiserver watch到集群中的pod、pv等状态同步到本地
2、在初始化的时候调用populateDesiredStateOfWorld和populateActualStateOfWorld对ASW和DSW进行初始化
3、desiredStateOfWorldPopulator负责将本地的数据状态同步到集群中
4、reconclier通过轮询的方式,把ASW和DSW的数据进行同步,同步的时候会调用volume plugin进行attach/deatch操作,同时也会调用nodeStatusUpdater进行node状态的更新
21.2.3、Volume Manager介绍
1、概念
- 是kubelet中的众多manager中的一个manager,调用本节点Volume的Attach/Detach/Mount/Unmount操作;
- VolumeManager实时扫描本结点的Pod状态,对需要更新状态的Volume通过调用volume Plugin执行相应操作
2、数据结构
- volumePluginMgr:管理本节点上In-Tree/Out-Of-Tree插件列表;
- desiredStateOfWorld: 记录节点上数据卷的期望状态;
- actualStateOfWorld:记录节点上数据卷的实际挂载状态;
3、核心逻辑
- desiredStateOfWorldPopulator: 同步包含数据卷的pod状态;
- Reconciler: 循环执行Attach、Detach、Mount、Unmount具体操作通过调用volume plugin实现的接口完成
4、AD Controller还是 Volume Manager做Attach/Detch操作? (volume manager和AD Controller都有attach和detach的功能)
- 通过 --enable-controller-attach-detach来控制,kubelet的一个参数如果为true则使用AD Controller来进行,如果false则使用volume manager来机型。不同节点可以设置不同的方式
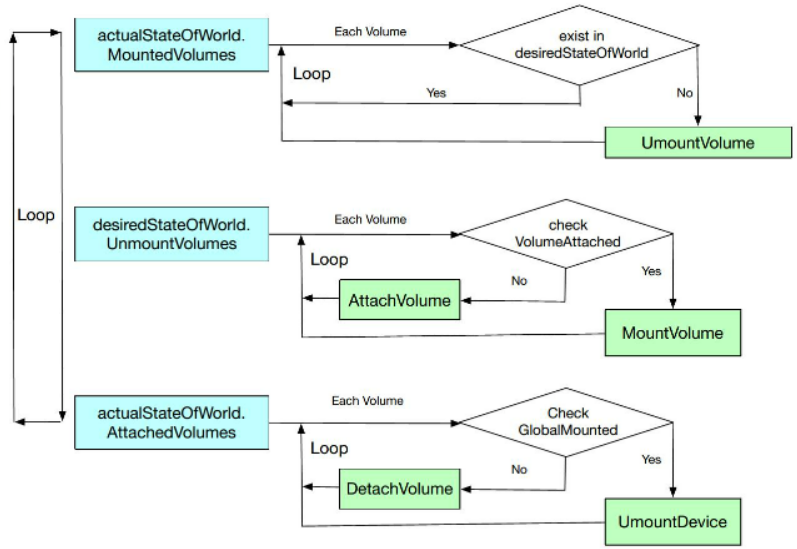
actualStateOfWorldMountedVolumes: 如果一个volume的状态ASW和DSW一样,则说明是正常的,期望和实际一致,不做任何处理,如果ASW不在DSW(期望状态)中,则umountVolume。其他同理
21.2.4、Volume Plugins介绍
1、Volume Plugins介绍
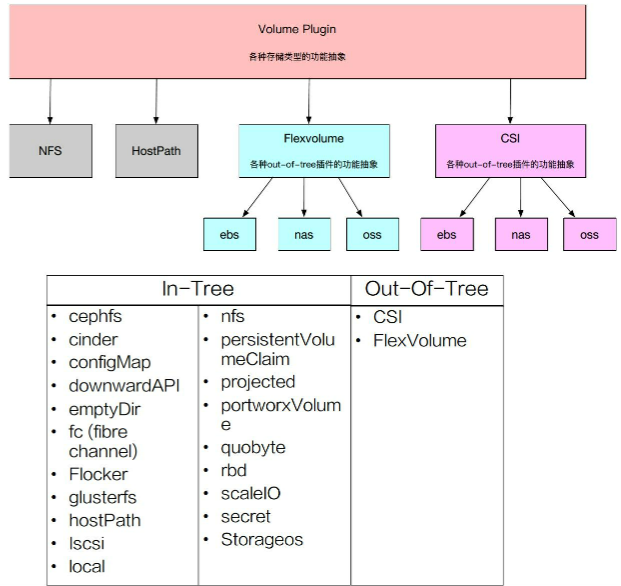
AD Controller,PV Controller是调用不同的接口实现pv和pvc的管理,这些接口由Volume Plugins实现;volume plugins根据不同的Provison,Delete,Attach,Detach,Mount,Unmount具体操作实现,是多种具体存储类型的功能抽象接口。
根据源码的位置可分为In-Tree和Out-Of-Tree两类:
- In-Tree: 在Kubernetes源码内部实现,和Kubernetes一起发布、管理、更新迭代慢、灵活性差
- Out-Of-Tree: 代码独立于Kubernetes,由存储尝试实现;CSI/Flexvolume是两种机制,可以根据存储类型实现为不同的存储插件;
Volumes Plugins实际是PV Controller、AD Controller、Volume Manager调用的一个库。
FlexVolume和CSI是对Volume Plugin的扩展。
2、Volume Plugins插件管理
VolumePluginMgr: 管理存储插件的对象,kubelet、PV Controller、AD Controller初始化时创建,负责插件列表的维护(添加/删除);
可管理Kubernetes原生自带的插件和动态添加、删除硬件;
数据结构:
- Plugin VolumePluginMgr管理的插件列表、随着插件的变化而更新;
- Prober:探针,用来发现新的Plugin,实现插件的添加、删除;
运行时:
- initPlugins: 初始化各个Plugin,并初始化Probe,使其watcher目标目录
- refreshProbedPlugins: 通过探针收集的Events,刷新当时Plugins列表;
Probe探针:
- 每次刷新Plugin返回ProbeEvent,Event类型包括: ProbeAddOrUpdate/ProbeRemove
- ProbeAddOrUpdate事件触发添加、初始化新Plugin;
- ProbeRemove事件触发从Plugins中删除硬件;
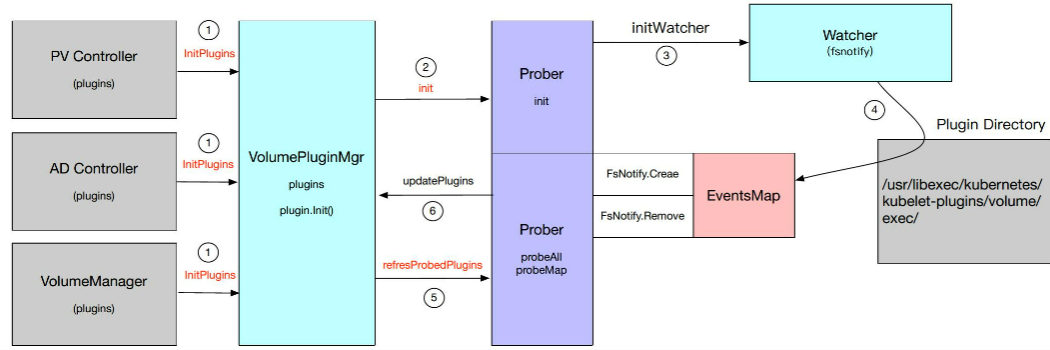
PV Controller,AD Controller,VolumeManager启动的时候会执行initPlugins的这样一个方法;
对VolumePluginMgr尽心一个初始化,首先会把intree的plugin加入到plugins列表中,
同时会调用Prober的init方法初始化一个watcher去监听一个目录(当目录内生成一个文件的时候即新增一个plugin[FsNotify.Create事件]加入到EventsMap中,删除一个文件及删除一个plugin[FsNotify.Remove]事件加入到EventsMap中);
当调用refreshProbedPlugins的时候会进行事件的更新。
21.3、Kubernetes存储卷调度
- Kubernetes在调度Pod额时候会通过不同调度器对节点进行筛选,其中部分调度器是Volume相关的调度器:
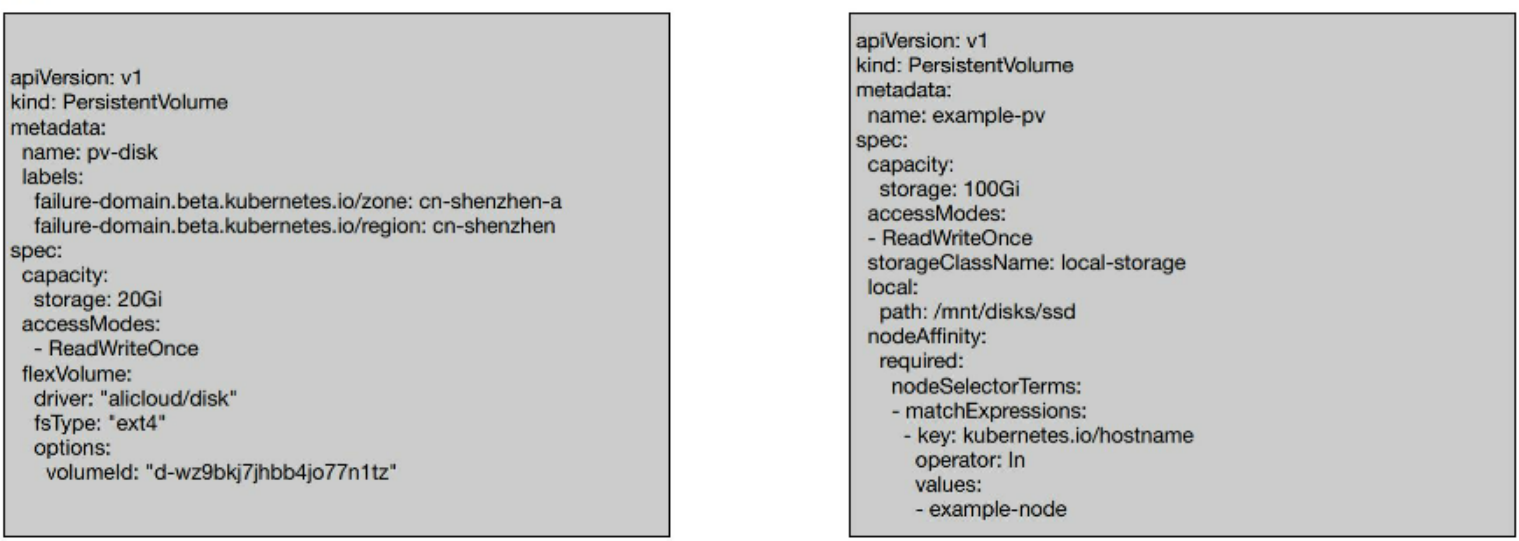
- VolumeZonePredicate: 会检查PV的Label标签,如果PV的Label中存在failure-domain.beta.kubernetes.io/zone标签,则会对Node进行筛选,只有Node的Label中有failure-doamin.beta.kubernetes.io/zone标签,且值相同的node才被选中;
- VolumeBindingPredicate: 检查PV的nodeAffinity配置,使用matchExpressions定义的参数与Node的Label进行匹配对比,符合条件的node会被选中;
- CSIMaxVolumeLimitPredicate:节点的某个插件类型已经挂载的卷个数小于的限额的才会选中;

21.4、Flexvolume介绍
21.4.1、FlexVolume介绍
- 对volume实现了扩展,Flexvolume实现了Volumeplugin的
Attach/Detach/Mount/Unmount接口定义,这些接口由第三方实现,并按照一定规则调用接口 - Flexvolume是一个由kubelet驱动的可执行文件,每一次接口调用均为一次可执行文件的命令行调用;不是常驻内存的守护进程
- 调用Flexvolume的Stdout作为kubelet调用的返回结果,要求JSON格式
- 默认存放(安装)位置:
/usr/libexec/kubenernetes/kubelet-plugins/volume/exec/alicloud~disk/disk - 所有挂载均先将远程设备挂载到本地主机,然后从主机通过bind映射到容器内部;

21.4.2、FlexVolume接口介绍
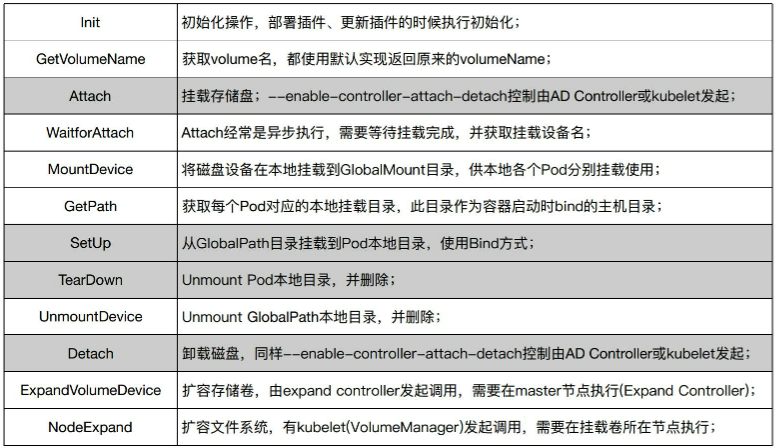
-
init接口通过DriverCapabilities信息告诉kubelet插件是否支持挂载、监控数据采集、文件系统扩容等信息
-
Flexvolume不需要对所有接口提供支持,不支持的接口返回NotSupport。这时VolumePlugin的in-tree部分Flexvolume默认实现会被调用。
{ "status": "", "messages": "error messages" } -
对应需要使用用户名密码信息的接口,可以通过Secret方式输入
apiVersion: v1 kind: PersistentVolume metadata: name: pv-oss spec: flexVolume: driver: "alicloud/oss" secretRef: name: "osssecret" options: bucket: ""
21.4.3、FlexVolume挂载分析
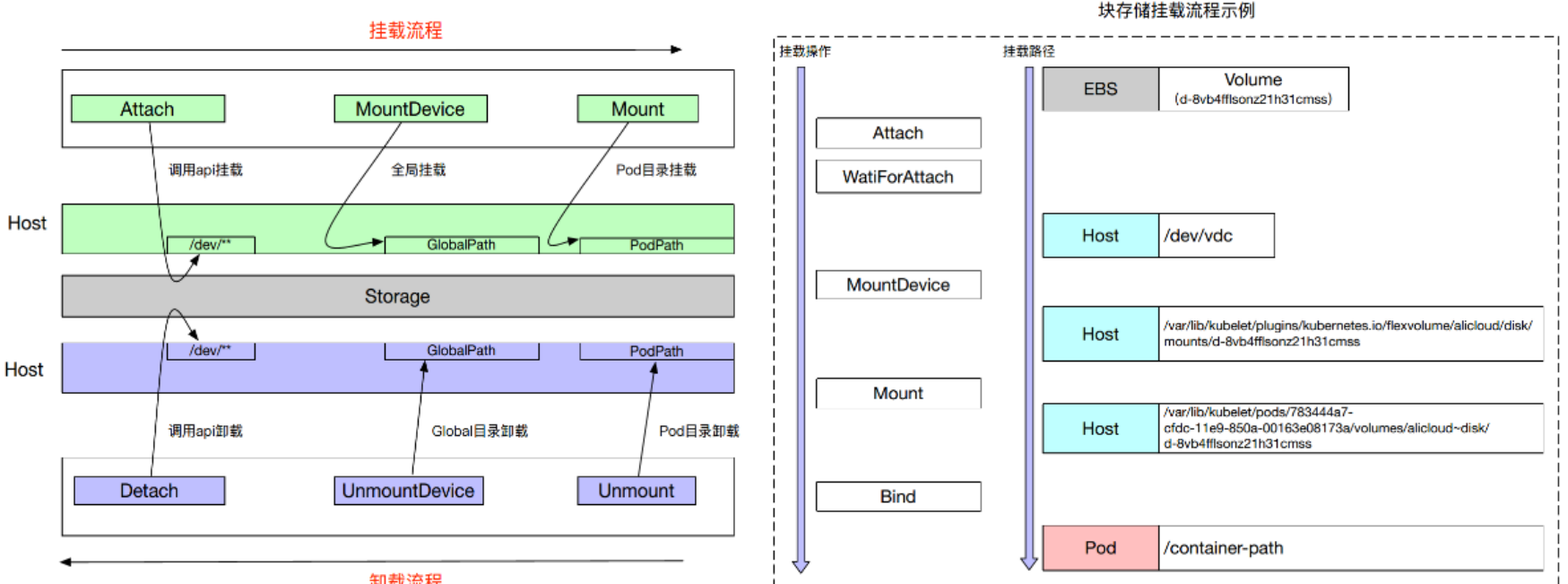
- 块存储需要Attach、格式化、Mount等操作,所以流程较长,步骤多;
- MountDevice是mount的一部分,执行一些公共操作;格式化、挂载device到GlobalPath等;
- 文件存储无需Attach操作,只需从远端mount到主机,流程要简单;
- 开发Flexvolume驱动的过程即为实现FlexVolume接口的过程,实现中通过调用OpenApi等方式挂载第三方存储设备
1、挂载流程:
调用api把sotrage挂载到worker的/dev/下,然后通过MountDevice把设备挂载到GlobalPath(flexvolume工作目录)上去,会做一些格式化等操作。mount把globalpath mount到pod 中(到pod的工作目录),bind(映射到pod内的路径中)2、卸载流程:
挂载流程的反向过程,针对块设备如此, 对于文件存储类型,就无需 Attach、MountDevice操作,只需要 Mount 操作,因此文件系统的 Flexvolume 实现较为简单,只需要 Mount 和 Unmount 过程即可。
21.4.4、Flexvolume示例
1、代码示例
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/aclicloud-cifs/cifs mount /var/lib/kubelet/plugins/kubernetes.io/flexvolume/alicloud/cifs/mounts/pv-cifs "{*******}"
项目地址: https://github.com/AliyunContainerService/flexvolume
2、使用示例

.png)
Flexvolume存储卷的定义格式和其他In-Tree存储类型格式一致,区别在于存储类型为Flexvolume;
Flexvolume参数定义:
- driver: 定义插件类型,会根据这个参数值到某个目录下面找到插件的可执行文件
- fsType: 定义存储卷文件系统类型
- options: 为一个map参数类型,可以定义所有与存储类型、挂载相关的具体参数
可以通过Selector、Label的方式,定向配置PV、PVC绑定关系;PV可以通过Label或者NodeAffinity配置调度信息
Flexvolume存储卷可以使用静态存储或者动态存储方式,动态存储卷需要在集群中部署Provisioner插件;
如上图例可以看出:
- EBS存储卷(ID d-wz***)先挂载到主机上,设备名为/dev/xdb设备名;
- 然后/dev/vdb挂载到同一个全局目录;
- 然后再挂载到Pod所在目录;
- 最后从Pod目录映射到Pod(容器)内部的/data目录
参考: https://help.aliyun.com/document_detail/86784.html
21.5、CSI
21.5.1、CSI介绍
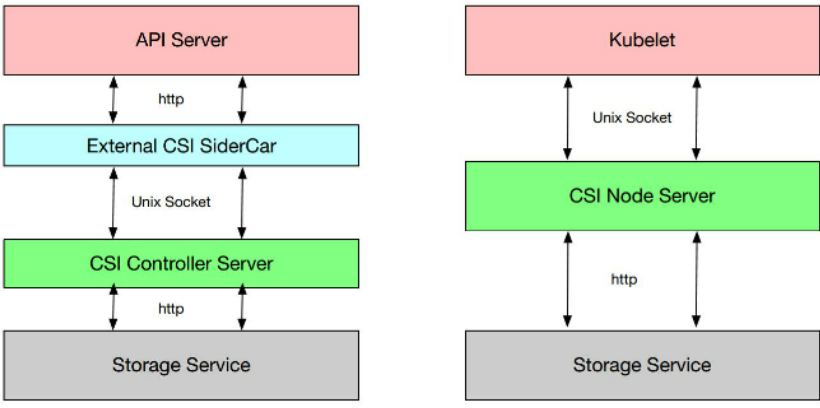
同Flexvolume一样,为第三方存储实现数据卷挂载实现的抽象接口
有了Flexvolume,为何还要CSI?
- 提供容器存储统一接口,实现编排系统与存储类型解耦,在多平台运行(k8s,Mesos,Swarm);Flexvolume只适用于k8s
- 容器化部署,减少环境依赖,增强安全性,丰富插件功能;
CSI包含两个部分:
- CSI Controller Server: 实现控制端的创建、删除、挂载、卸载功能;
- CSI Node Server: 实现节点上的mount、Unmount功能;
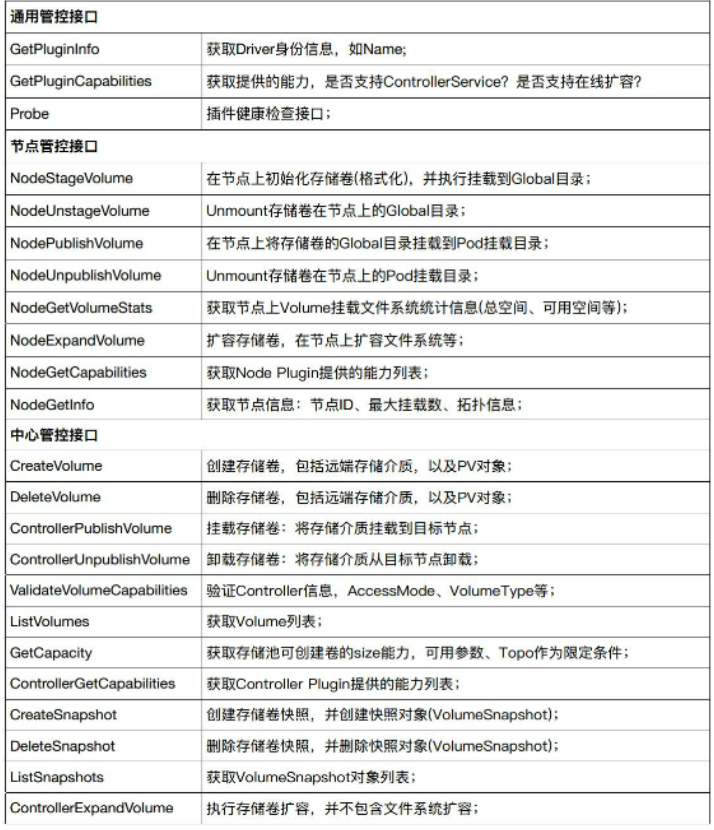
21.5.2、CSI拓扑结构
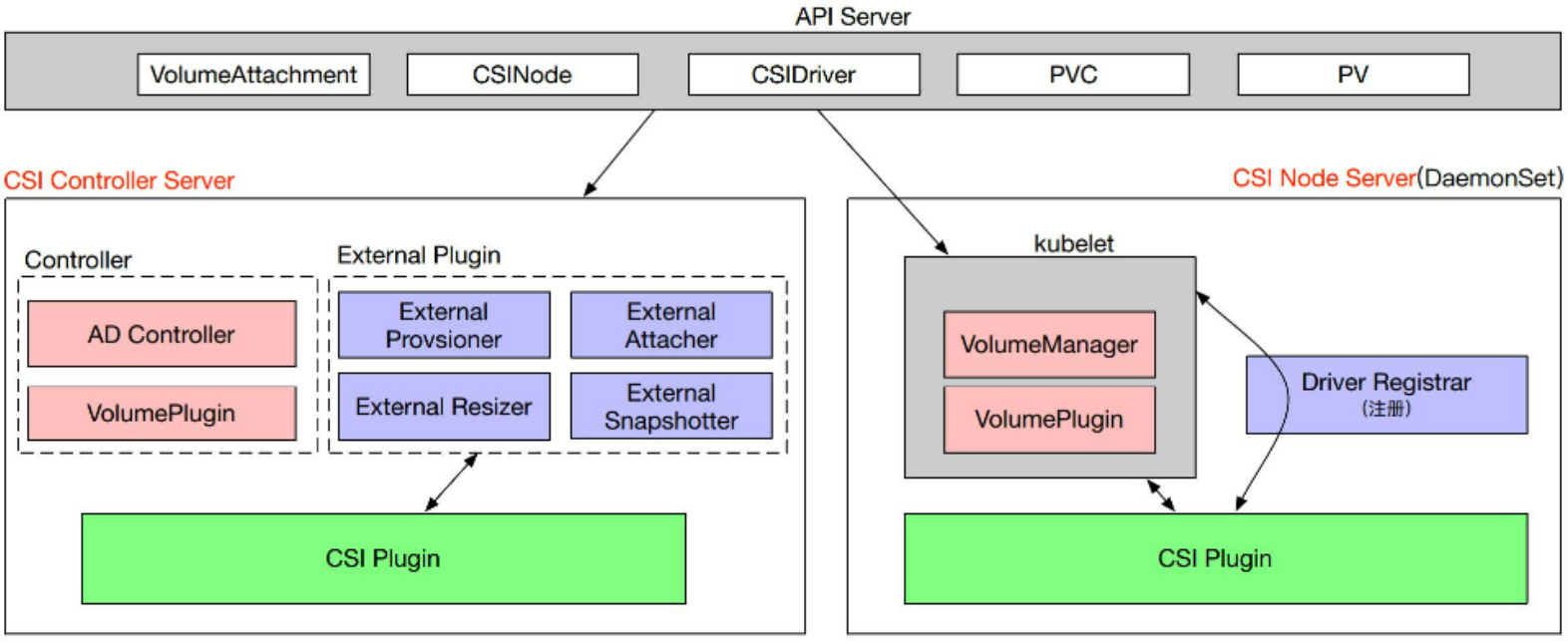

CSI 是通过 CRD 的形式实现的,所以 CSI 引入了这么几个对象类型:VolumeAttachment、CSINode、CSIDriver 以及 CSI Controller Server 与 CSI Node Server 的一个实现。
在 CSI Controller Server 中,有传统的类似 Kubernetes 中的 AD Controller 和 Volume Plugins,VolumeAttachment 对象就是由它们所创建的。
此外,还包含多个 External Plugin组件,每个组件和 CSI Plugin 组合的时候会完成某种功能。比如:
- External Provisioner 和 Controller Server 组合的时候就会完成数据卷的创建与删除功能;
- External Attacher 和 Controller Server 组合起来可以执行数据卷的挂载和操作;
- External Resizer 和 Controller Server 组合起来可以执行数据卷的扩容操作;
- External Snapshotter 和 Controller Server 组合则可以完成快照的创建和删除。
CSI Node Server 中主要包含 Kubelet 组件,包括 VolumeManager 和 VolumePlugin,会调用 CSI Plugin 去做 mount 和 unmount 操作;另外一个组件 Driver Registrar 主要实现的是 CSI Plugin 注册的功能。
21.5.3、CSI对象

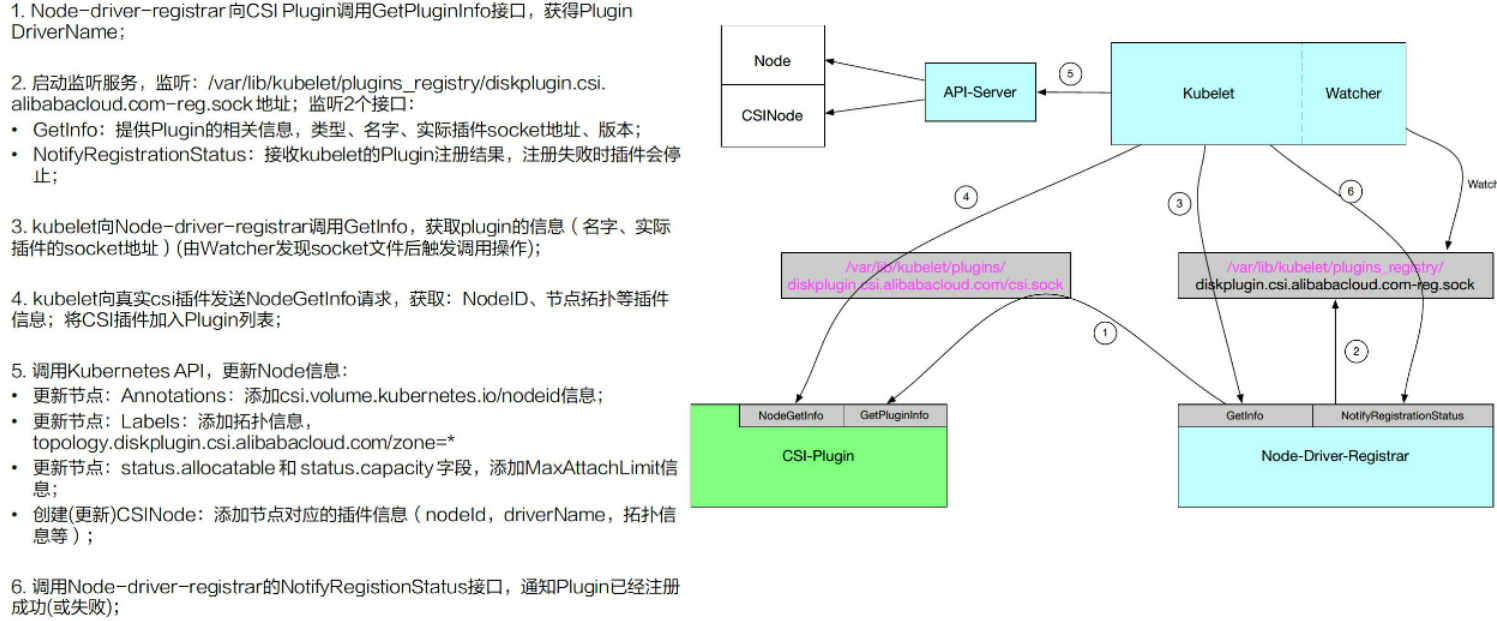
21.5.4、CSI组件-Node-Driver-Registrar
负责与Kubernetes配合实现CSI插件的注册功能:
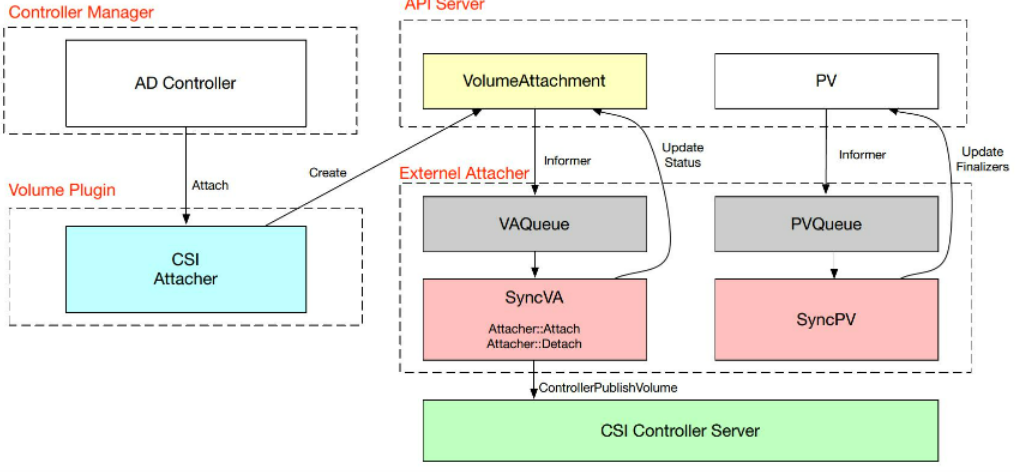
21.5.5、CSI组件-Externel-Attacher
- 调用CSI Plugin接口实现数据卷的挂载、卸载
- 通过Watcher VolumeAttachment对象,根据其状态调用ControllerPublishVolume接口;AD Controller调用volume plugin的CSI Attacher(in-tree部分)去创建VolumeAttachment。由kube-controller实现;而Externel-Attacher通过watch VolumeAttacher;
- 如果在CSIDriver对象中对一个驱动的attachedRequired参数定义为false,则上述Attach流程不会执行,定义为true时,(AD Controller)才会进行Attach操作;同时也会同步一些pv信息到apiserver
- 像文件存储这类存储类型,不需要进行attach、格式化操作存储类型,一般会跳过上述流程;
21.5.6、CSI 部署
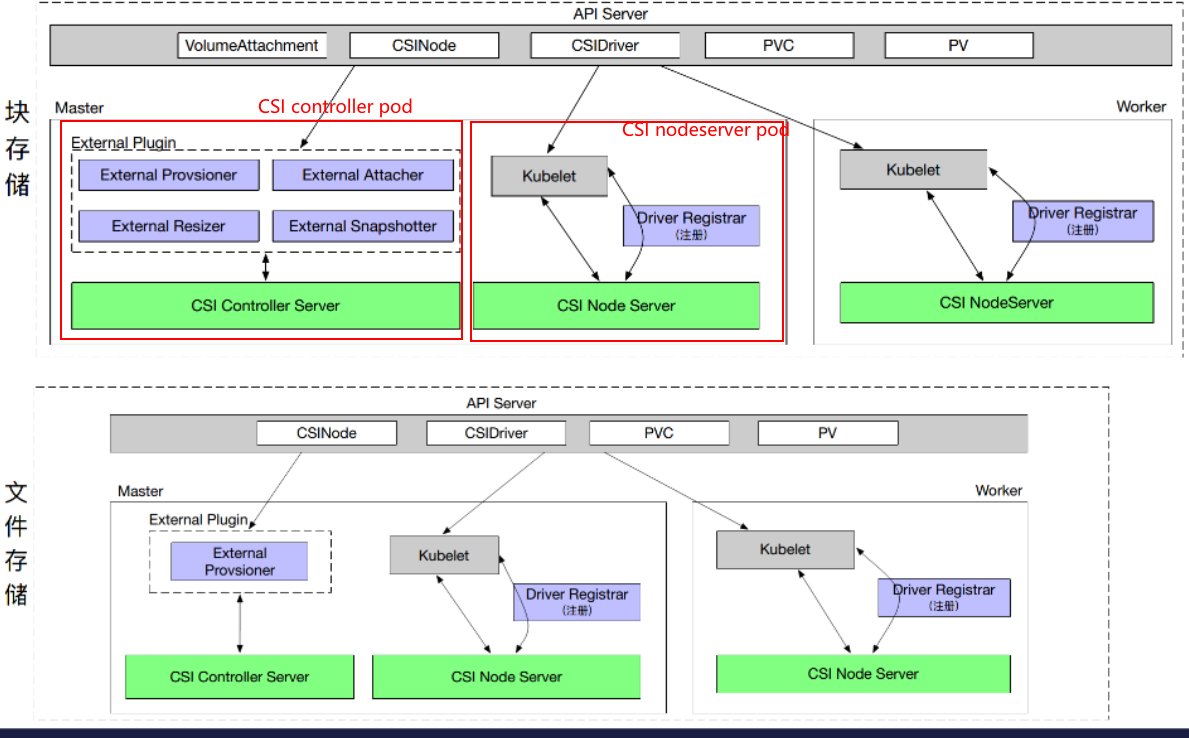
1、块存储:
左半部分master:Controller-server pod,右半部分node:node-server pod
CSI 的 Controller 分为两部分,一个是 Controller Server Pod,一个是 Node Server Pod。如果是多备份的,可以部署两个。Controller Server 主要是通过多个外部插件来实现的,比如说一个 Pod 中可以定义多个 External 的 Container 和一个包含 CSI Controller Server 的 Container,这时候不同的 External 组件会和 Controller Server 组成不同的功能。
而 Node Server Pod 是个 DaemonSet,它会在每个节点上进行注册。Kubelet 会直接通过 Socket 的方式直接和 CSI Node Server 进行通信、调用 Attach/Detach/Mount/Unmount 等。
Driver Registrar 只是做一个注册的功能,会在每个节点上进行部署。
2、文件存储:
文件存储和块存储的部署情况是类似的。只不过它会把 Attacher 去掉,也没有 VolumeAttachment 对象。
21.5.7、CSI使用示例

CSI存储卷的定义格式和其他In-Tree存储类型格式一致,区别在存储类型为CSI;
CSI存储卷可以使用静态存储或者动态存储方式;
CSI参数定义:
- driver:定义插件
- volumeHandle: 定义CSI卷的唯一标志
- nodeAffinity: 可选,定义CSI卷的拓扑信息;
- volumeAttributes: 可选,定义附加参数;
可以通过Selector、Label的方式,定向配置PV、PVC绑定关系;
例子中可以看到:
- EBS存储卷(磁盘ID d-wz9bk*** ) 先挂载到主机上,设备名为/dev/vdb设备名;
- 然后/dev/vdb挂载到一个全局(globalpath)目录(/var/lib/kubelet/plugins/kuberntes.io/csi/pv/csi-pv/globalmount);
- 然后再挂载到Pod所在的目录(podpath):/var/lib/kubelet/pods/34---*****/volumes/kubernetes.io-csi/csi-pv/mount);
挂载流程上跟Flexvolume类似:
21.5.8、CSI其他功能:

21.5.9、CSI 近期 Features
ExpandCSIVolumes:
- 实现数据卷的扩容,包括文件系统扩容;
- 需要部署Sidecar; csi-resizer;
- 实现:ControllerExpandVolume,NodeExpandVolume;
- 1.14 Alpha,1.16 Beta;
VolumeSnapshotDataSource:
- 实现数据卷的快照功能;
- 需要部署SideCar:csi-snapshotter;
- 实现:CreateSnapShot,DeleteSnapshot接口;
- 1.12 Alpha;
VolumePVCDataSource:
- 创建PVC的时候,以其它Volume作为数据源进行拷贝创建
- 需要在PVC中定义dataSource参数;
- 功能启动: --feature--gates=VolumePVCDataSource=true
- 1.15 Alpha,1.16 Beta;
CSIInline Volume:
- 运行CSI Volume直接在Pod中定义,而不需通过PVC、PV的方式定义;链接
- 功能开启:--feature-gates=CSIInlineVolume=true
- 1.15 Alpha,1.16 Beta
项目示例: https://github.com/kuberntes-sigs/alibaba-cloud-csi-driver
21.6、实验
实验1:使用21.3示例,进行pv本地ext4实验操作
1)步骤1:nfs安装
[root@master1 ~]# yum install nfs-utils rpcbind -y
[root@master1 ~]# mkdir /nfs-share
[root@master1 ~]# systemctl start nfs
[root@master1 ~]# echo "/nfs-share *(rw,async,no_root_squash)" >> /etc/exports
[root@master1 ~]# exportfs -r
[root@master2 ~]# showmount -e master1
Export list for master1:
/nfs-share *
2)步骤2使用nfs作为volume
[root@master1 yaml]# cat a.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-ds
annotations:
environment: "product"
projectName: "hello world"
labels:
dp: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx-ds
template:
metadata:
labels:
app: nginx-ds
spec:
containers:
- name: my-nginx
image: reg2.mt.com:5000/nginx:latest
ports:
- containerPort: 80
imagePullSecrets:
- name: reg2
[root@master1 yaml]# kubectl apply -f centos-ds.yaml
[root@master1 ~]# kubectl exec -it my-ds-7cb5657467-28gtt bash
[root@my-ds-7cb5657467-28gtt /]# df -h /data
Filesystem Size Used Avail Use% Mounted on
192.168.153.132:/nfs-share 37G 11G 27G 30% /data
3)步骤3-nfs作为PersistentVolume-静态存储
[root@master1 yaml]# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /nfs-share
server: 192.168.153.132
[root@master1 yaml]# cat pv2.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv2
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs: #也可以使用hostPath,直接使用本地盘创建pv
path: /nfs-share
server: 192.168.153.132
[root@master1 yaml]# kubectl apply -f pv.yaml
[root@master1 yaml]# kubectl apply -f pv2.yaml
[root@master1 yaml]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfs-pv 5Gi RWO Recycle Available slow 2m16s
nfs-pv2 5Gi RWO Recycle Available slow 111s
4)步骤4-创建pvc-静态存储
[root@master1 yaml]# cat pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
[root@master1 yaml]# kubectl get pvc/nfs-pvc -o yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"PersistentVolumeClaim","metadata":{"annotations":{},"name":"nfs-pvc","namespace":"default"},"spec":{"accessModes":["ReadWriteOnce"],"resources":{"requests":{"storage":"2Gi"}}}}
pv.kubernetes.io/bind-completed: "yes"
pv.kubernetes.io/bound-by-controller: "yes"
creationTimestamp: "2021-03-08T08:56:46Z"
finalizers:
- kubernetes.io/pvc-protection
name: nfs-pvc
namespace: default
resourceVersion: "795207"
selfLink: /api/v1/namespaces/default/persistentvolumeclaims/nfs-pvc
uid: 2b33e2af-5669-436f-a502-890496a72f4e
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi #需要2Gi,但是实际分配了5Gi
volumeMode: Filesystem
volumeName: nfs-pv
status:
accessModes:
- ReadWriteOnce
capacity:
storage: 5Gi
phase: Bound
5)步骤5-创建pod使用pvc-静态存储
[root@master1 yaml]# cat centos-ds.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-ds
spec:
selector:
matchLabels:
app: centos-ds
template:
metadata:
labels:
app: centos-ds
spec:
containers:
- name: my-centos
image: reg.mt.com:5000/centos:latest
command: ["/usr/bin/tail","-f","/etc/hosts"]
volumeMounts:
- mountPath: /data
name: nfs-volume
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: nfs-pvc
6)步骤6-清理静态存储数据
清理pod,pvc和pv内容,在pv回收的时候会启动一个pod执行,报错
[root@master1 yaml]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
recycler-for-nfs-pv 0/1 Pending 0 0s
报错:
Warning FailedMount 27s kubelet, master3 MountVolume.SetUp failed for volume "vol" : mount failed: exit status 32
Mounting command: systemd-run
Mounting arguments: --description=Kubernetes transient mount for /data/kubelet/pods/9ce47145-b410-41d4-8aef-560aa5a2a5bf/volumes/kubernetes.io~nfs/vol --scope -- mount -t nfs 192.168.153.132:/nfs-share /data/kubelet/pods/9ce47145-b410-41d4-8aef-560aa5a2a5bf/volumes/kubernetes.io~nfs/vol
Output: Running scope as unit run-18935.scope.
mount: 文件系统类型错误、选项错误、192.168.153.132:/nfs-share 上有坏超级块、
缺少代码页或助手程序,或其他错误
(对某些文件系统(如 nfs、cifs) 您可能需要
一款 /sbin/mount.<类型> 助手程序)
有些情况下在 syslog 中可以找到一些有用信息- 请尝试
dmesg | tail 这样的命令看看。
Warning FailedMount 25s kubelet, master3 MountVolume.SetUp failed for volume "vol" : mount failed: exit status 32
因为,在master3上缺少安装nfs-utils。安装后即可完成操作
7)步骤7-动态存储
参考:https://www.kubernetes.org.cn/4022.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号