kubernetes-学习笔记_大魂师
第十三章、Kubernetes网络概念及策略控制
13.1、Kubernetes基本网络模型
kubernetes网段:service网段、pod网段、node网段
13.1.1、k8s网络基本法则:约法三章 + 四大目标
1)Kubernetes对于Pod间的网络没有任何限制,只需满足如下【三个基本条件】:
- 任意两个Pod 之间是可以直接通信的,无需经过显式地使用 NAT;
- node 与 pod 之间是可以直接通信的,无需显式地址转换;
- pod 可见的 IP 地址与其他Pod与其通信时使用的ip,无需显式nat。
pods on a node can communicate with all pods on all nodes without NAT
agents on a node (e.g. system daemons, kubelet) can communicate with all pods on that node; Note: For those platforms that support Pods running in the host network (e.g. Linux):
pods in the host network of a node can communicate with all pods on all nodes without NAT
引自:https://kubernetes.io/docs/concepts/cluster-administration/networking/#the-kubernetes-network-model
2)在设计一个网络方案的时候,需要考虑的【四大目标】:
- 容器与容器间的通信?
- pod 和 pod 之间调用是怎么做到通信的?
- pod 如何与service 通讯?
- 外部世界与Service之间的通信?
13.1.2、基本约束
容器与其宿主存在寄生关系,在实现上,容器网络方案可分为Underlay/Overlay:
- Underlay 的标准是它与 Host 网络是同层的,从外在可见的一个特征就是它是不是使用了 Host 网络同样的网段、输入输出基础设备、容器的 IP 地址是不是需要与 Host 网络取得协同(来自同一个中心分配或统一划分)。这就是 Underlay;
- Overlay 不一样的地方就在于它并不需要从 Host 网络的 IPM 的管理的组件去申请IP,一般来说,它只需要跟 Host 网络不冲突,这个 IP 可以自由分配的。
13.2、netns探秘
1、Netns究竟实现了什么?
Network namespace是实现网络虚拟化的内核基础,创建了网络的namespace:
- 拥有独立的附属网络设备(lo,veth 等虚设备/物理网卡)
- 独立的协议栈,IP地址和路由表
- iptables 规则
- ipvs等

2、Pod与Netns的关系
每个Pod拥有独立的netns空间,Pod内的Container共享该空间,可通过Loopback接口实现通信,或通过共享Pod-IP对外提供服务。宿主机上还有一个Root Netns(host network namespace),可以看做一个特殊的容器空间(或者网络空间),只不过它的pid为1。

13.3、主流网络方案简介
容器网络是kubernetes中最为活跃的一个领域,依照Iaas层的配置、外部物理网络的设备、性能or灵活优先,可以有不同的实现:
- Flannel:最为普遍的实现,提供多种网络backend实现
- Calico: 采用BGP提供网络直连,功能丰富,对底层网络有要求;支持网络策略
- Canal(Flannel for network + Calico for firewalling),Flannel和Calio结合产物
- Cilium: 基于eBPF和XDP的高性能overlay网络方案
- kube-router: 同样采用BGP提供网络直连,集成基于LVS的负载均衡能力
- Romana: 采用BGP or OSPF提供网络直连能力
- WeaveNet:采用UDP封装L2 Overlay,支持用户态(慢,可加密)/内核态(快,不能加密)两种实现
Flannel方案:
Flannel是目前使用最为普遍的方案,通过将backend机制独立,它目前已经支持多种数据路径,也可以适用于overlay/underlay等多种场景,封装可以选用户态udp(纯用户态实现),内核Vxlan(性能好),如集群规模不太,处于同一二层域,也可以选择host-gw方式。
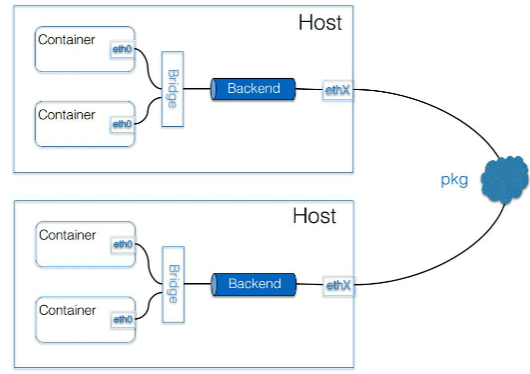
可以看到一个典型的容器网方案,首先要解决的是 container 的包如何到达 Host,这里采用的是加一个 Bridge 的方式。它的 backend 其实是独立的,也就是说这个包如何离开 Host,是采用哪种封装方式,还是不需要封装,都是可选择的。
三种主要的 backend:
- 用户态的 udp,这种是最早期的实现;早期kernel不支持vxlan #
检查:grep -i vxlan "/boot/config-$(uname -r)" - 内核的 Vxlan,这两种都算是 overlay 的方案。Vxlan 的性能会比较好一点,但是它对内核的版本是有要求的,需要内核支持 Vxlan 的特性功能;
- 如果集群规模不够大,又处于同一个二层域,也可以选择采用 host-gw 的方式。这种方式的backend 基本上是由一段广播路由规则来启动的,性能比较高。
其他backend: https://github.com/coreos/flannel/blob/master/Documentation/backends.md
Flannel一般使用方法:
1、使用etcdctl 向etcd写入规划网段信息,参数中包含要使用的backend,例如: ${FLANNEL_ETCD_PREFIX}/config '{"Network":"'172.16.0.0'", "SubnetLen": 21, "Backend": {"Type": "vxlan"}}'
2、配置flannel能够访问etcd,以及访问etcd的路径(-etcd-prefix),mk-docker-opts.sh用于从etcd申请网段等配置信息,并写入配置信息到指定路径
3、配置container runtime去读取配置,并使用配置作为本机container runtime的网络配置
注意:k8s的pod网段由cni负责,service网段由kube-proxy负责
13.4、Network Policy
Network Policy提供了基于策略的网络控制,用于隔离应用并减少攻击面。它使用标签选择器模拟系统的分段网络,并通过策略控制它们之间的流量以及来自外部的流量。
在使用Network Policy之前,需要注意:
- apiserver开启 extensions/v1beta1/networkpolicies
- 网络插件要支持Network Policy,如Calico,Romana,Weave Net和Trireme等
1)、配置示例:

2)、配置实例1说明
功能:通过使用标签选择器(包括namespaceSelector和podSelector来控制Pod之间的流量)
网络策略配置要决定的三件事:
- 控制对象:通过spec字段,podSelector等条件筛选
- 流方向:
- Ingress(入Pod流量) + from:spec.ingress
- Egress(出Pod流量) + to: spec.egress
- 流特征:
- 对端(通过name/pod selector):
- IP 段(ipBlock):
- 协议(protocol),端口(port):
3)、配置实例2说明
- 允许default namespace中带有role-frontend标签的Pod访问default namespace中带有role=db标签Pod的6379端口
- 允许带有project=myprojects标签的namespace中所有Pod访问default namespace中带有role=db标签Pod的6379端口
13.5、小结
- Pod在容器网络中的核心概念是IP,每个Pod必须有内外视角一致性的ip地址
- 影响容器网络性能的关键是拓扑设计,也就是数据包端到端的设计
- 牢记overlay/underlay 下各种网络方案的设计选择,如果不知道,可以这样选:普使性最强-Flannel-Vxlan,2层可直连-Calico/Flannel+HostGW
- Network Policy 是个强大的工具,可以实现Ingress/Exgress的流量精确控制,关键是选择好Pod Selector,定义好流特征
思考:
1、为什么网络接口标准化了CNI,而网络方案没有标准化
2、为什么Network Policy没有交给一个Controller实现,而是交给方案提供方
3、能不能完全不用Net-dev类型的设备,实现一个容器网络?
4、网络问题排查,值不值得做一个开源工具实现?
5、可以使用kube-router同时实现pod和service网络,为啥不用呢?
第十四章、Kubernetes service
14.1、背景
1、为什么需要服务发现:
- Pod 生命周期短暂,IP地址随时变化(被删除或者发版后会变化)
- Deployment等的Pod组需要统一访问入口和做负载均衡
- 应用间在不同环境部署时保持同样的部署拓扑和访问方式
2、应用服务如何暴露到外部访问和负载均衡?

3、Service的语法:

访问my-service的tcp协议的80端口会负载均衡到label为"app:MyApp"的pod的9376端口
14.2、用例解读
14.2.1、创建和查看service
[root@master1 yaml]# cat pod2.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: centos
name: centos-deployment
spec:
replicas: 1
selector:
matchLabels:
app: centos
template:
metadata:
labels:
app: centos
spec:
containers:
- image: reg.mt.com:5000/centos:latest
name: centos
ports:
command: ["/usr/bin/tail","-f","/etc/hosts"]
---
apiVersion: "v1"
kind: "Service"
metadata:
name: "nginx-svc"
namespace: "default"
labels:
app: nginx-svc
spec:
ports:
- name: "port-80"
port: 8080
targetPort: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: reg.mt.com:5000/nginx:latest
name: nginx
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 3
readinessProbe:
successThreshold: 1
periodSeconds: 5
httpGet:
path: /
port: 80
timeoutSeconds: 5
initialDelaySeconds: 3
[root@master1 yaml]# kubectl describe svc/nginx-svc
Name: nginx-svc
Namespace: default
Labels: app=nginx-svc
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"app":"nginx-svc"},"name":"nginx-svc","namespace":"default"},"s...
Selector: app=nginx
Type: ClusterIP
IP: 192.168.0.6
Port: port-80 8080/TCP
TargetPort: 80/TCP
Endpoints: 172.7.22.2:80
Session Affinity: None
Events: <none>
[root@master1 yaml]# kubectl scale --replicas=2 deployment/nginx
deployment.extensions/nginx scaled
[root@master1 yaml]# kubectl scale --replicas=2 deployment/nginx
deployment.extensions/nginx scaled
[root@master1 yaml]# kubectl describe svc/nginx-svc
Name: nginx-svc
Namespace: default
Labels: app=nginx-svc
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"app":"nginx-svc"},"name":"nginx-svc","namespace":"default"},"s...
Selector: app=nginx
Type: ClusterIP
IP: 192.168.0.6
Port: port-80 8080/TCP
TargetPort: 80/TCP
Endpoints: 172.7.22.2:80,172.7.25.2:80 #会自动添加节点
Session Affinity: None
Events: <none>

14.2.2、集群内访问Service
- 直接访问Service的虚拟ip
- 直接访问服务名,依靠DNS解析,同一个NameSpace直接通过servicename访问,不同namespace加上namespace名访问:${servicename}.${namespace} #curl my-service:80
- 通过环境变量访问: k8s在启动pod的时候会把一些配置信息当作环境变量在pod中加载
# 1、service方式访问
[root@master1 yaml]# kubectl get pods
NAME READY STATUS RESTARTS AGE
centos-deployment-675dc67d9c-pjhks 1/1 Running 0 76s
nginx-7fddbd784f-bh8dm 1/1 Running 0 4h39m
nginx-7fddbd784f-rqf2j 1/1 Running 0 5m29s
[root@master1 yaml]# kubectl exec -it centos-deployment-675dc67d9c-pjhks bash
[root@centos-deployment-675dc67d9c-pjhks /]# ping 192.168.0.16
PING 192.168.0.16 (192.168.0.6) 56(84) bytes of data.
64 bytes from 192.168.0.6: icmp_seq=1 ttl=64 time=0.934 ms
64 bytes from 192.168.0.6: icmp_seq=2 ttl=64 time=0.107 ms
^C
--- 192.168.0.6 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 4ms
rtt min/avg/max/mdev = 0.107/0.520/0.934/0.414 ms
# 2、服务名方式访问
[root@centos-deployment-675dc67d9c-pjhks /]# cat /etc/resolv.conf #在pod启动的时候会被加上nameserver
nameserver 192.168.0.2
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
</html>
[root@centos-deployment-675dc67d9c-pjhks /]# curl -s -I nginx-svc:8080 #可以访问
[root@centos-deployment-675dc67d9c-pjhks /]# curl -s -I nginx-svc.default.svc.cluster.local:8080 #可以访问
# 3、pod内访问
[root@centos-deployment-675dc67d9c-pjhks /]# env |grep NGINX_SVC
NGINX_SVC_SERVICE_PORT=8080
NGINX_SVC_PORT_8080_TCP_PROTO=tcp
NGINX_SVC_SERVICE_PORT_PORT_80=8080
NGINX_SVC_PORT_8080_TCP_PORT=8080
NGINX_SVC_PORT_8080_TCP=tcp://192.168.0.6:8080
NGINX_SVC_SERVICE_HOST=192.168.0.6
NGINX_SVC_PORT=tcp://192.168.0.6:8080
NGINX_SVC_PORT_8080_TCP_ADDR=192.168.0.6
[root@centos-deployment-675dc67d9c-pjhks /]# curl -s -I http://${NGINX_SVC_SERVICE_HOST}:${NGINX_SVC_SERVICE_PORT} #可以访问
注意:如果service发生变化的时候,POD需要删除重建才会被注入新的service信息
# 4、node上使用域名访问service(添加hosts或者添加)
[root@master1 ~]# cat /etc/resolv.conf
# create for k8s
domain cluster.local
search cluster.local
nameserver 192.168.0.2 #注意namesperver一定要写在前面,nameserer为顺序查找
# Generated by NetworkManager
search localdomain
nameserver 192.168.116.2
[root@master1 ~]# dig -t A nginx-svc.default.svc.cluster.local @192.168.0.2
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.3 <<>> -t A nginx-svc.default.svc.cluster.local @192.168.0.2
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37394
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;nginx-svc.default.svc.cluster.local. IN A
;; ANSWER SECTION:
nginx-svc.default.svc.cluster.local. 5 IN A 192.168.0.6
;; Query time: 0 msec
;; SERVER: 192.168.0.2#53(192.168.0.2)
;; WHEN: 四 1月 28 19:35:15 CST 2021
;; MSG SIZE rcvd: 115
[root@master1 ~]# ping nginx-svc.default.svc.cluster.local #返回地址为192.168.0.6
14.2.3、headless Service
Service指定 clusterIP:Node
- Pod通过service_name方式时直接解析到所有后端Pod ip
- 客户端自主选择需要访问的IP
[root@master1 yaml]# cat pod2.yaml #修改service
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
labels:
app: nginx-svc
spec:
ports:
- name: port-80
port: 8080
targetPort: 80
selector:
app: nginx
clusterIP: None
...
[root@master1 yaml]# kubectl apply -f pod2.yaml
deployment.apps/nginx unchanged The Service "nginx-svc" is invalid: spec.clusterIP: Invalid value: "": field is immutable
原因:不能直接修改原有的service,但是可以删除后重新修改
[root@master1 yaml]# kubectl delete -f pod2.yaml
service "nginx-svc" deleted
deployment.apps "nginx" deleted
[root@master1 yaml]# kubectl delete -f pod2.yaml
service "nginx-svc" deleted
deployment.apps "nginx" deleted
[root@master1 yaml]# kubectl describe svc/nginx-svc
Name: nginx-svc
Namespace: default
Labels: app=nginx-svc
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"app":"nginx-svc"},"name":"nginx-svc","namespace":"default"},"s...
Selector: app=nginx
Type: ClusterIP
IP: None
Port: port-80 8080/TCP
TargetPort: 80/TCP
Endpoints: 172.7.22.2:80,172.7.25.3:80
Session Affinity: None
Events: <none>
[root@master1 yaml]# dig -t A nginx-svc.default.svc.cluster.local @192.168.0.2
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.3 <<>> -t A nginx-svc.default.svc.cluster.local @192.168.0.2
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59335
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;nginx-svc.default.svc.cluster.local. IN A
;; ANSWER SECTION:
nginx-svc.default.svc.cluster.local. 5 IN A 172.7.25.3
nginx-svc.default.svc.cluster.local. 5 IN A 172.7.22.2
;; Query time: 1 msec
;; SERVER: 192.168.0.2#53(192.168.0.2)
;; WHEN: 四 1月 28 20:09:00 CST 2021
;; MSG SIZE rcvd: 166
14.2.4、向集群外暴露Servie
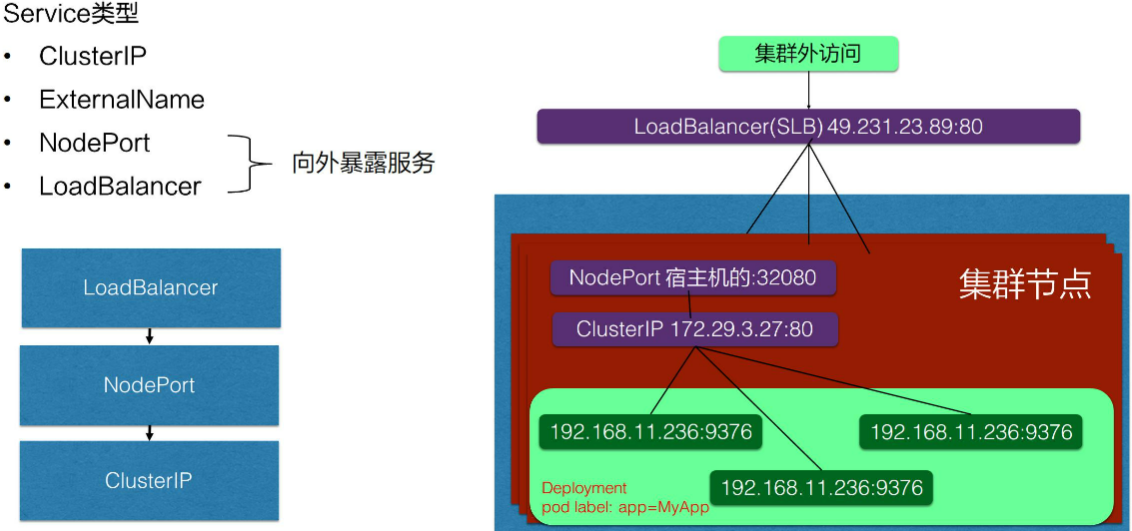
- NodePort: 在集群的node上暴露一个端口,这样相当于在每个节点的一个端口上面访问到之后就会再去做一层转发,转发到service 虚拟 IP 地址(flannel为host-gw模式下为转发到pod的ip)。
- LoadBalancer: 是在 NodePort 上面又做了一层转换。比如在阿里云上挂一个 SLB,这个负载均衡会提供一个统一的入口,并把所有它接触到的流量负载均衡到每一个集群节点的 node pod 上面去。然后 node pod 再转化成 ClusterIP,去访问到实际的 pod 上面。
# 1、nodeport
[root@master1 yaml]# cat pod2.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
labels:
app: nginx-svc
spec:
ports:
- name: port-80
port: 8080
targetPort: 80
nodePort: 3333
selector:
app: nginx
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: reg.mt.com:5000/nginx:latest
name: nginx
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 3
readinessProbe:
successThreshold: 1
periodSeconds: 5
httpGet:
path: /
port: 80
timeoutSeconds: 5
initialDelaySeconds: 3
[root@master1 yaml]# kubectl describe svc/nginx-svc
Name: nginx-svc
Namespace: default
Labels: app=nginx-svc
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"app":"nginx-svc"},"name":"nginx-svc","namespace":"default"},"s...
Selector: app=nginx
Type: NodePort
IP: 192.168.0.164
Port: port-80 8080/TCP
TargetPort: 80/TCP
NodePort: port-80 3333/TCP
Endpoints: 172.7.22.2:80,172.7.25.3:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
14.3、架构设计

- Cloud Controller Manager:负责去配置Loadbalancer的一个负载均衡的一个负载均衡器给外部访问用
- coreDns: 观测apiserver里面的service后端一些pod的变化,去配置service的DNS解析,实现可以通过service的名字直接访问service的虚拟ip。或者headless的ip列表
- kube-proxy: 每个node上都会有一个,监听service以及pod变化,创建lvs规则
podA->podB的service访问链路(集群内):
- podA首先通过coredns去解析podB的Service ip,podA访问 service ip
- 请求到podA 所在的宿主机网络后,kube-proxy进行拦截(ipvs/iptables),之后负载均衡到一个实际的后端pod ip上去。
对于外部的流量,比如公网访问的一个请求。它是通过外部的一个负载均衡器 Cloud Controller Manager 去监听 service 的变化之后,去配置一个负载均衡器,然后转发到节点上的一个 NodePort 上面去,NodePort 也会经过 kube-proxy 的一个配置的一个 iptables,把 NodePort 的流量转换成 ClusterIP,紧接着转换成后端的一个 pod 的 IP 地址,去做负载均衡以及服务发现。这就是整个 K8s 服务发现以及 K8s Service 整体的结构。
第十五章、深入剖析Linux容器
15.1、简述容器
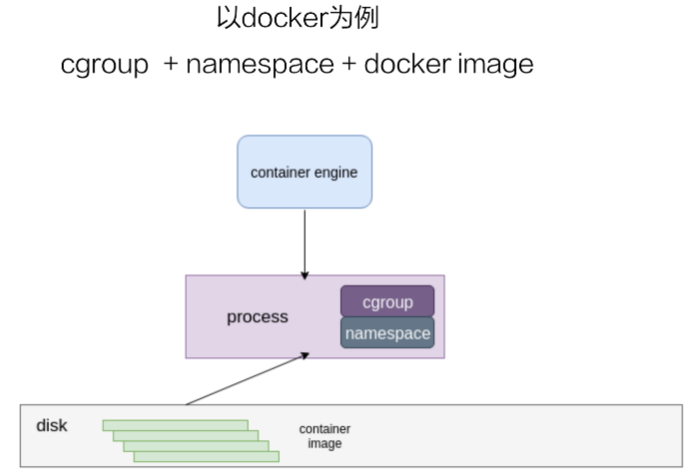
容器的镜像是存储在disk上,上层是一个容器引擎(docker为其中一个),引擎向下发一个请求,比如说创建容器,然后这时候它就把磁盘上面的容器镜像,运行成在宿主机上的一个进程。
对于容器来说,最重要的是怎么保证这个进程所用到的资源是被隔离和被限制住的,在 Linux 内核上面是由 cgroup 和 namespace 这两个技术来保证的。接下来以 docker 为例,来详细介绍一下资源隔离和容器镜像这两部分内容。
15.2、资源隔离和限制
15.2.1、namespace
mount: 保证容器看到的文件系统为容器镜像提供的,即看不到宿主机上的
uts: 隔离hostname和domain name
pid: 保证了容器的进程id
network: 除了容器用 host 网络这种模式之外,其他所有的网络模式都有一个自己的 network namespace 的文件
user: 控制了用户uid,gid和宿主机上的映射
ipc: 进程间通信,比如信号量
cgroup: 使用该namespce后容器中看到的cgroup视图是以根的形式来呈现的,使得cgroup使用更安全
在linux内核中有7种namespace,docker只用了前六种
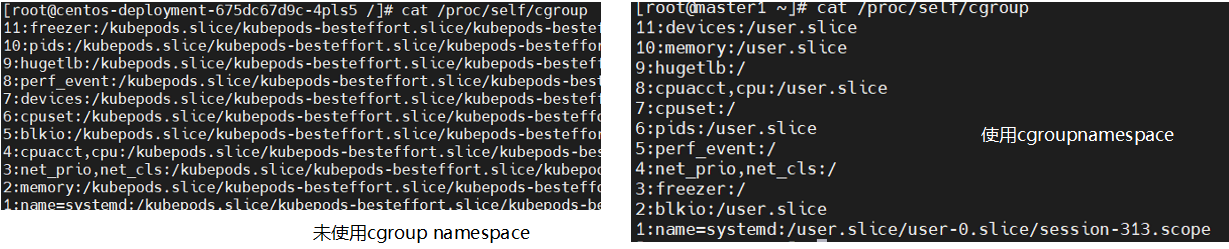
容器中namespace创建使用的是unshare的系统调用来是实现的。

15.2.2、cgroup
- 2种 cgroup驱动:
- systemd cgroup driver #直接通过 #systemd 本身可以提供一个 cgroup 管理方式。所以如果用 systemd 做 cgroup 驱动的话,所有的写 cgroup 操作都必须通过 systemd 的接口来完成,不能手动更改 cgroup 的文件。
- cgroupfs cgroup driver #要限制资源,直接把 pid 写入对应的一个 cgroup 文件,然后把对应需要限制的资源也写入相应的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了。
docker info |grep -i cgroupo 可以查看当前使用的cgroup 驱动
- docker容器中常用的cgroup
- cpu cpuset cpuacct : 控制cpu使用率
- memory: 控制进程内存的使用量
- device: 控制可以在容器中看到的device设备
- freezer: 和device都是为了安全,当容器停止的时候,freezer 会把当前的进程全部都写入 cgroup,然后把所有的进程都冻结掉,这样做的目的是,防止你在停止的时候,有进程会去做 fork。这样的话就相当于防止进程逃逸到宿主机上面去,是为安全考虑。
- blkio: 主要是限制容器用到的磁盘的一些 IOPS 还有 bps 的速率限制,cgroup-v1 场景blkio只能限制同步io,buffer io无法限制
- pid: 限制的是容器里面可以用到的最大进程数量
- docker 容器不可用的cgroup:
- net_cls:
- net_prio
- hugetlb
- perf_event
- rdma
对于runC来说除了rdma所有的cgroup都是支持的
扩展资料:https://www.kernel.org/doc/Documentation/
15.3、容器镜像

docker镜像是基于联合文件系统的,联合文件系统: 允许文件是存放在不同的层级上面的,但是最终是通过一个统一的视图,看到层级上面的所有文件。
docker 镜像的存储,它的底层是基于不同的文件系统的,所以它的存储驱动也是针对不同的文件系统作为定制的,比如 AUFS、btrfs、devicemapper 还有 overlay。docker 对这些文件系统做了一些相对应的一个 graph driver 的驱动,也就是通过这些驱动把镜像存在磁盘上面。
以overlay为例,说明docker镜像在磁盘上是如何存储的:

upper层使用了写时复制的一个机制,对某些文件需要修改的时候才会从lower层copy过来。修改操作都会从uppper层副本进行修改。docker exec到container中看到的是mergedir层
文件操作:
- 读:如果uppper曾没有副本,数据都从lower读上来
- 写:容器创建出来后,upper是空的,只有对文件进行写操作时,才会从lower曾拷贝文件上来,对副本进行操作
- 删:删除操作不影响lower层,删除操作通过对文件进行标记,使文件无法显示。有2种方式,whiteout和设置目录的xattr "thrusted.overlay.opaque"=y
# 1、查看m信息
master1上有一个nginx的pod
[root@master1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
centos-deployment-675dc67d9c-4pls5 1/1 Running 0 18h 172.7.73.3 master2 <none> <none>
nginx-7fddbd784f-q5v4m 1/1 Running 0 17h 172.7.22.2 master1 <none> <none>
nginx-7fddbd784f-zrd68 1/1 Running 0 17h 172.7.25.3 master3 <none> <none>
[root@master1 ~]# docker ps |grep 'reg.mt.com:5000/nginx' |awk '{print $1}'
4c6ac0242a62
[root@master1 ~]# docker inspect 4c6ac0242a62 |grep -i upper
"UpperDir": "/data/docker/overlay2/a9f4757ff571db3486202890732ec7d19857425c0df3eab6ab13bfee55b41081/diff",
[root@master1 ~]#
[root@master1 ~]# docker inspect 4c6ac0242a62 |grep -i merge
"MergedDir": "/data/docker/overlay2/a9f4757ff571db3486202890732ec7d19857425c0df3eab6ab13bfee55b41081/merged",
#2、在ningx内创建文件
[root@master1 ~]# docker exec -it 4c6ac0242a62 bash
root@nginx-7fddbd784f-q5v4m:/# echo "mt_test" > /mt
root@nginx-7fddbd784f-q5v4m:/# exit
[root@master1 ~]# cat /data/docker/overlay2/a9f4757ff571db3486202890732ec7d19857425c0df3eab6ab13bfee55b41081/merged/mt
mt_test
[root@master1 ~]# cat /data/docker/overlay2/a9f4757ff571db3486202890732ec7d19857425c0df3eab6ab13bfee55b41081/diff/mt
mt_test
15.4、容器引擎
15.4.1、containerd容器架构
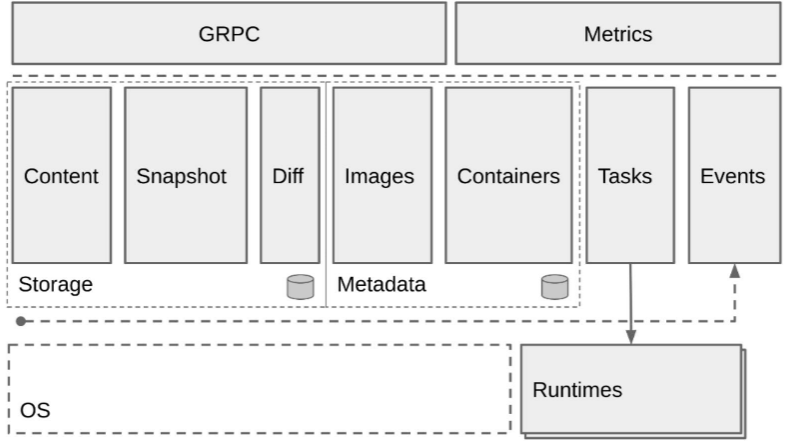
上图如果把它分成左右两边的话,可以认为 containerd 提供了两大功能:1) 左边对于容器生命周期的管理右; 2)右边storage 的部分对一个镜像存储的管理。containerd 会负责进行的拉取、镜像的存储。
按照水平层次来看的话:
- GRPC,containerd 对于上层来说是通过 GRPC server 的形式来对上层提供服务的。Metrics 主要是提供 cgroup Metrics信息
- 中层左边是容器镜像的一个存储,中间images、containers 下面是 Metadata,是通过 存储在磁盘上面的。右边的 Tasks 是管理容器的结构,Events 是对容器的一些操作都会有一个 Event 向上层发出,然后上层可以去订阅这个 Event,由此知道容器状态发生什么变化。
- 最下层是 Runtimes 层,这个 Runtimes 可以从类型区分,比如说 runC 或者是安全容器之类的。
15.4.2、shim v1/v2
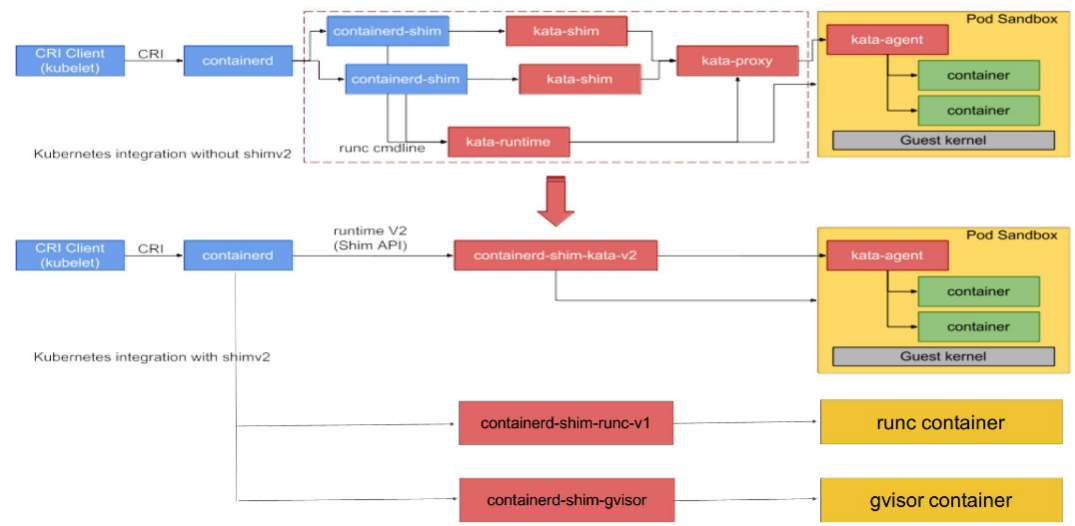
图上半部分是kata官网原图原图,下半部分加了一些扩展示例,基于这张图我们来看一下 containerd 在 runtime 这层的架构。
最左边是一个 CRI Client。一般就是 kubelet 通过 CRI 请求,向 containerd 发送请求。containerd 接收到容器的请求之后,会经过一个 containerd shim。containerd shim 是管理容器生命周期的,它主要负责两方面:
- 第一个是它会对 io 进行转发。
- 第二是它会对信号进行传递。
图的上半部分画的是安全容器,也就是 kata 的一个流程,这里不具体展开了。下半部分,可以看到有各种各样不同的 shim。一开始在 containerd 中只有一个 shim,不管是 kata 容器也好、runc 容器也好、gvisor 容器也好,上面用的 shim 都是 containerd。
后面针对不同类型的 runtime,containerd 去做了一个扩展。这个扩展是通过 shim-v2 这个 interface 去做的,也就是说只要去实现了这个 shim-v2 的 interface,不同的 runtime 就可以定制不同的自己的一个 shim。比如:runC 可以自己做一个 shim,叫 shim-runc;gvisor 可以自己做一个 shim 叫 shim-gvisor;像上面 kata 也可以自己去做一个 shim-kata 的 shim。这些 shim 可以替换掉上面蓝色框的 containerd-shim。
这样做的好处有很多,举一个比较形象的例子。可以看一下 kata 这张图,它上面原先如果用 shim-v1 的话其实有三个组件,之所以有三个组件的原因是因为 kata 自身的一个限制,但是用了 shim-v2 这个架构后,三个组件可以做成一个二进制,也就是原先三个组件,现在可以变成一个 shim-kata 组件,这个可以体现出 shim-v2 的一个好处
15.4.3、容器流程示例
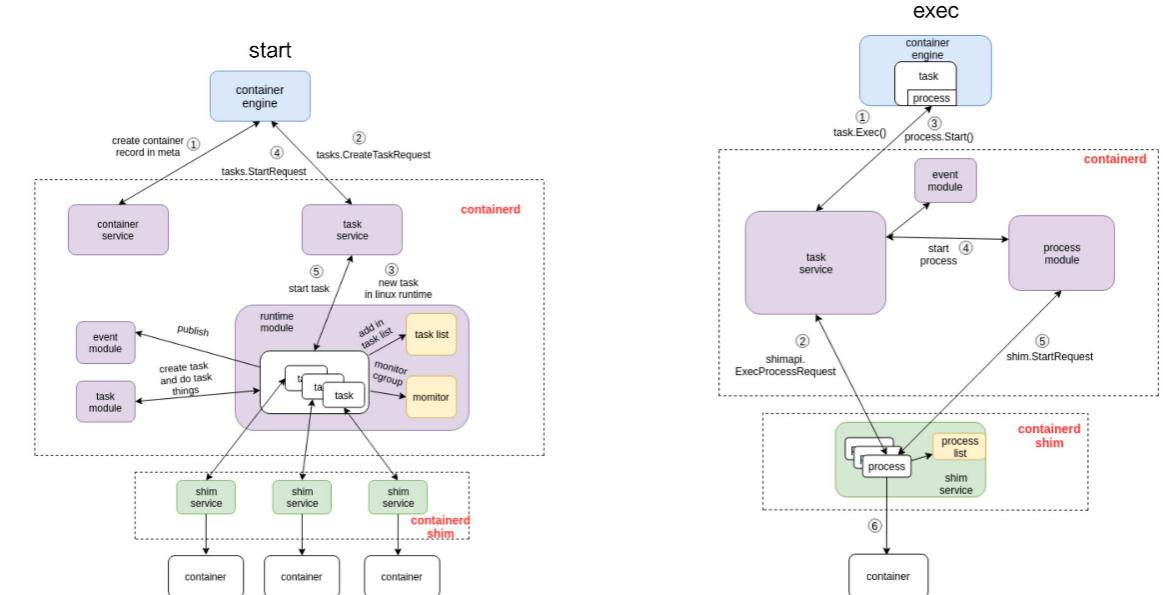
1、这张图由三个部分组成:
- 第一部分是容器引擎部分,容器引擎可以是 docker,也可以是其它的。
- 两个虚线框框起来的 containerd 和 containerd-shim,它们两个是属于 containerd 架构的部分。
- 最下面 container 的部分,这个部分是通过一个 runtime 去拉起的,可以认为是 shim 去操作 runC 命令创建的一个容器。
2、start流程:
图里面也标明了 1、2、3、4。这个 1、2、3、4 就是 containerd 怎么去创建一个容器的流程。首先它会去创建一个 matadata,然后会去发请求给 task service 说要去创建容器。通过中间一系列的组件,最终把请求下发到一个 shim。containerd 和 shim 的交互其实也是通过 GRPC 来做交互的,containerd 把创建请求发给 shim 之后,shim 会去调用 runtime 创建一个容器出来,以上就是容器 start 的一个示例。
3、exec流程:
接下来看下面这张图,是怎么去 exec 一个容器的。和 start 流程非常相似,结构也大概相同,不同的部分其实就是 containerd 怎么去处理这部分流程。和上面的图一样,我也在图中标明了 1、2、3、4,这些步骤就代表了 containerd 去做 exec 的一个先后顺序。 由上图可以看到,exec 的操作还是发给 containerd-shim 的。对容器来说,去 start 一个容器和去 exec 一个容器,其实并没有本质的区别。
最终的一个区别无非就是,是否对容器中跑的进程做一个 namespace 的创建:
- exec 的时候,需要把这个进程加入到一个已有的 namespace 里面;
- start 的时候,容器进程的 namespace 是需要去专门创建。
15.4.4、OCI
An open governance structure for the express purpose of creating open industry standards around container formats and runtime.
- oci runtime标准: https://github.com/opencontainers/runtime-spec
- oci image标准: https://github.com/opencontainers/image-spec
- distribution标准: https://github.com/opencontainers/distribution-spec
第十六章、深入理解etcd-基本原理分析
16.1、发展历程
etcd诞生于CoreOS公司,最初用于解决集群系统中OS升级时的分布式并发控制、配置文件的存储与分发等问题。基于此,etcd被设计为提供高可用、强一致的小型KeyValue数据存储服务。项目当前隶属于CNCF基金,被包括ASW、Google等公司广泛使用。使用golang寓言开发

16.2、架构及内部机制

分布式、可靠的key-value存储,被用于存储分布式系统中的关键型数据。boltdb存储kv。client可以请求任意一个节点来完成请求。一般是3个或者5个节点组成集群。多个节点之间通过raft算法实现一致性,算法会选举出一个主节点作为 leader,由 leader 负责数据的同步与数据的分发,当 leader 出现故障后,系统会自动地选取另一个节点成为 leader,并重新完成数据的同步与分发。客户端在众多的 leader 中,仅需要选择其中的一个就可以完成数据的读写。
在 etcd 整个的架构中,有一个非常关键的概念叫做 quorum(法定人数),quorum 的定义是 =(n+1)/2,在raft中超过一半以上的人数就是法定人数。也就是说超过集群中半数节点组成的一个团体,在 3 个节点的集群中,etcd 可以容许 1 个节点故障,也就是只要有任何 2 个节点重合,etcd 就可以继续提供服务。同理,在 5 个节点的集群中,只要有任何 3 个节点重合,etcd 就可以继续提供服务。这也是 etcd 集群高可用的关键。
当我们在允许部分节点故障之后,继续提供服务,这里就需要解决一个非常复杂的问题,即分布式一致性。在 etcd 中,该分布式一致性算法由 Raft 一致性算法完成,这个算法本身是比较复杂的,我们这里就不展开详细介绍了。
但是这里面有一个关键点,它基于一个前提:任意两个 quorum 的成员之间一定会有一个交集,也就是说只要有任意一个 quorum 存活,其中一定存在某一个节点,它包含着集群中最新的数据。正是基于这个假设,这个一致性算法就可以在一个 quorum 之间采用这份最新的数据去完成数据的同步,从而保证整个集群向前衍进的过程中其数据保持一致。
WAL:Write Ahead Log(预写式日志),是etcd的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd就通过WAL进行持久化存储。WAL中,所有的数据提交前都会事先记录日志。Snapshot是为了防止数据过多而进行的状态快照;Entry表示存储的具体日志内容。
snapshot:etcd防止WAL文件过多而设置的快照,存储etcd数据状态
16.2.1、api
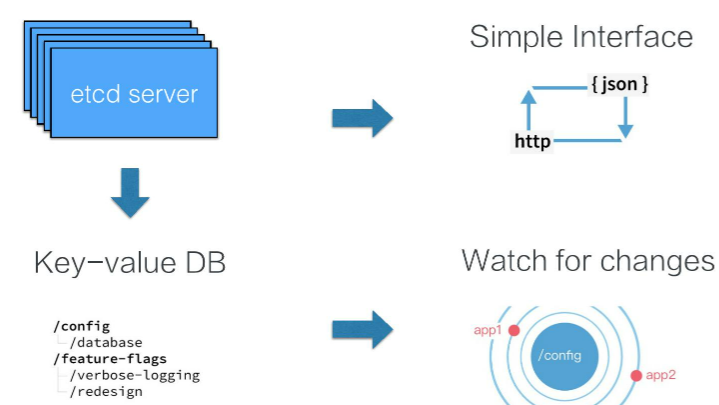
etcd提供的接口比较简单,可以通过 etcd 提供的客户端etcdctl去访问集群的数据,也可以直接通过 http 的方式,类似像 curl 命令直接访问 etcd。在 etcd 内部,其数据表示也是比较简单的,我们可以直接把 etcd 的数据存储理解为一个有序的 map,它存储着 key-value 数据。同时 etcd 为了方便客户端去订阅资料的数据,也支持了一个 watch 机制,也可以通过 watch 实时地拿到 etcd 中数据的增量更新,从而保持与 etcd 中的数据同步。
etcd主要提供了如下APIs:
- Put(key,value) /Delete(key)
- Get(key) /Get(keyFrom,KeyEnd)
- Watch(key/keyPrefix)
- Transactions(if / then /else ops).Commit()
- Leases: Grant /Revoke / KeepAlive
- . . .
- 更多
16.2.2、etcd数据版本号机制

右上角图:在同一个leader任期内,所有的修改操作term都一样,revision保持单调递增
右下角图:重启集群后,term值更新,rev同样保持单调递增。并且rev在重启前后始终保持单调递增
- term: 全局单调递增 64bits //整个集群leader的任期,当整个集群leader发生切换或者集群重新拉起term +1
- revision: 全局单调递增 64bits //全局数据的版本,当发生创建,修改,删除的时候revision+1
- KeyValue: //对于每一个key-value数据,etcd记录了三个版本
- create_revision //创建的版本
- mod_revision //修改的版本
- version //key-value被修改了多少次
16.2.3、mvcc(多版本并发控制)和watch
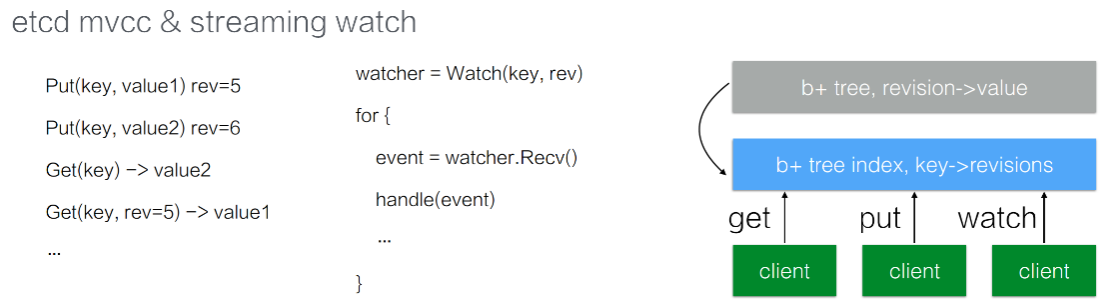
etcd支持对同一个数据进行多次修改,因为每一次修改会对应一个版本号。在进行查询数据的时候,默认查询最新版本,也可以指定版本进行查询。
在 etcd 中所有的数据都存储在一个 b+tree 中。b+tree 是保存在磁盘中,并通过 mmap 的方式映射到内存用来查询操作。
在 b+tree 中(如图所示灰色部分),维护着 revision 到 value 的映射关系。也就是说当指定 revision 查询数据的时候,就可以通过该 b+tree 直接返回数据。当我们通过 watch 来订阅数据的时候,也可以通过这个 b+tree 维护的 revision 到 value 映射关系,从而通过指定的 revision 开始遍历这个 b+tree,拿到所有的数据更新。
同时在 etcd 内部还维护着另外一个 b+tree。它管理着 key 到 revision 的映射关系。当需要查询 Key 对应数据的时候,会通过蓝色方框的 b+tree,将 key 翻译成 revision。再通过灰色框 b+tree 中的 revision 获取到对应的 value。至此就能满足客户端不同的查询场景了。
这里需要提两点:
- 一个数据是有多个版本的;
- 在 etcd 持续运行过程中会不断的发生修改,意味着 etcd 中内存及磁盘的数据都会持续增长。这对资源有限的场景来说是无法接受的。因此在 etcd 中会周期性的运行一个 Compaction 的机制来清理历史数据。对于一个 Key 的历史版本数据,可以选择清理掉。
16.2.4、mini-transactions
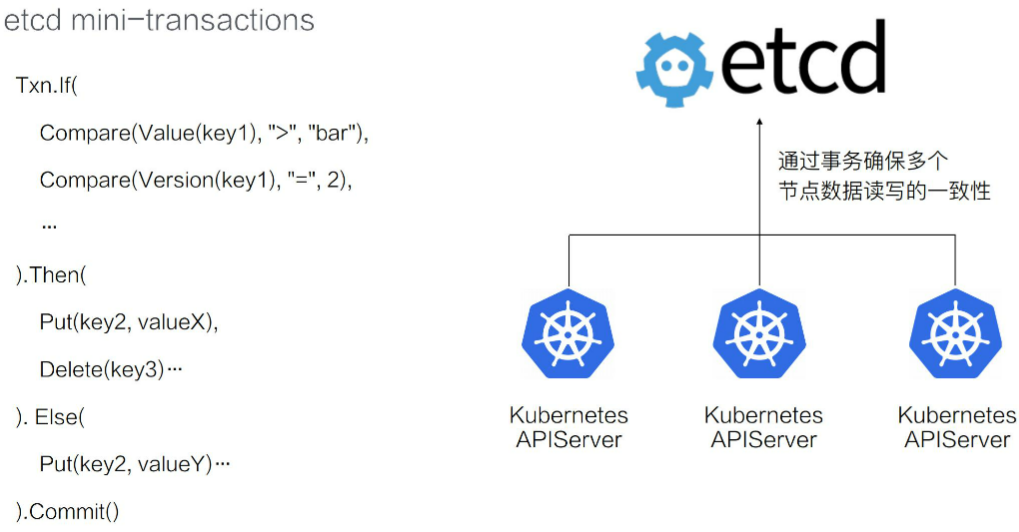
在上图的示例中,if 里面写了两个条件。当 Value(key1) 大于“bar”,并且 Version(key1) 的版本等于 2 的时候,执行 Then 里面指定的操作:修改 Key2 的数据为 valueX,同时删除 Key3 的数据。如果不满足条件,则执行另外一个操作:Key2 修改为 valueY。
在 etcd 内部会保证整个事务操作的原子性。也就是说 If 操作所有的比较条件,其看到的视图,一定是一致的。同时它能够确保在争执条件中,多个操作的原子性不会出现 etc 仅执行了一半的情况。
通过 etcd 提供的事务操作,我们可以在多个竞争中去保证数据读写的一致性,比如说前面已经提到过的 Kubernetes 项目,它正是利用了 etcd 的事务机制,来实现多个 KubernetesAPI server 对同样一个数据修改的一致性。
16.2.5、leases(租约)
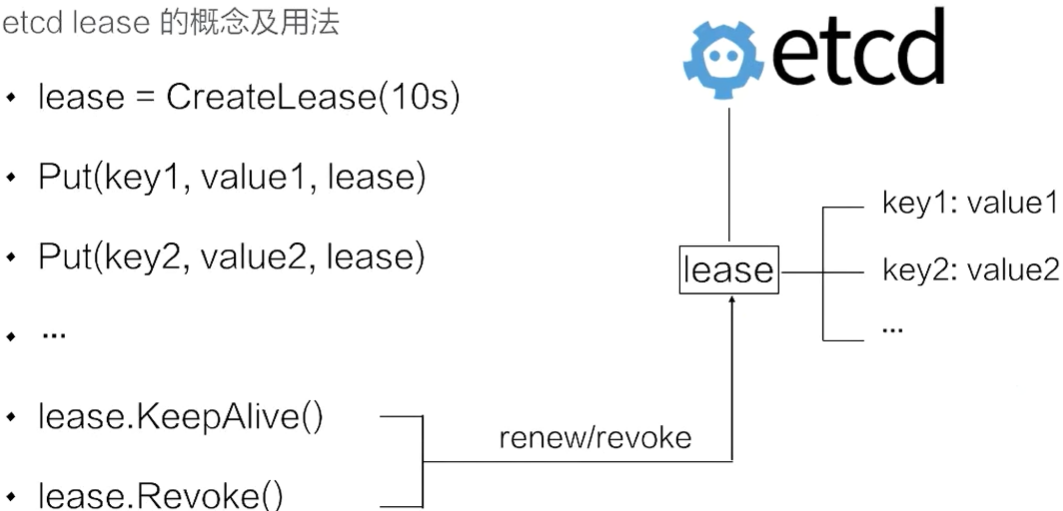
通常情况下,在分布式系统中需要去检测一个节点是否存活的时候,就需要租约机制。上图示例中首先创建了一个 10s 的租约,如果创建租约后不做任何的操作,那么 10s 之后,这个租约就会自动过期。接着将 key1 和 key2 两个 key value 绑定到这个租约之上,这样当租约过期时,etcd 就会自动清理掉 key1 和 key2 对应的数据。
如果希望这个租约永不过期,比如说需要检测分布式系统中一个进程是否存活,那么就会在这个分布式进程中去访问 etcd 并且创建一个租约,同时在该进程中去调用 KeepAlive 的方法,与 etcd 保持一个租约不断的续约。试想一下,如果这个进程挂掉了,这时就没有办法再继续去开发 Alive。租约在进程挂掉的一段时间就会被 etcd 自动清理掉。所以可以通过这个机制来判定节点是否存活。
在 etcd 中,允许将多个 key 关联在统一的 lease 之上,这个设计是非常巧妙的。通过这种方法,将多个 key 绑定在同一个lease对象,可以大幅地减少 lease 对象刷新的时间。试想一下,如果大量的 key 都需要绑定在一个 lease 对象之上,每一个 key 都去更新这个租约的话,这个 etcd 会产生非常大的压力。通过支持加多个 key 绑定在同一个 lease 之上,它既不失灵活性同时能够大幅改进 etcd 整个系统的性能。
16.3、演示
#api v2版本,只做为参考。重点关注v3
[root@master1 ~]# ARG="--endpoints=" https://192.168.153.132:2379,https://192.168.153.133:2379 ,https://192.168.153.134:2379" --cert-file=/opt/etcd/certs/etcd-peer.pem --key-file=/opt/etcd/certs/etcd-peer-key.pem --ca-file=/opt/etcd/certs/ca.pem"
[root@master1 ~]# /opt/etcd/etcdctl $ARG set key1 value1 #api v2版本使用 set,v3版本使用put
value1
[root@master1 ~]# /opt/etcd/etcdctl $ARG get key1
value1
[root@master1 ~]# for k in `seq 1 9`;do /opt/etcd/etcdctl $ARG set key$k value$k ;done 2>1 | grep -v decpre
[root@master1 ~]# /opt/etcd/etcdctl $ARG get key2 key5 #v2版本只会返回key2
value2
[root@master1 etcd]# /opt/etcd/etcdctl -o json get key1 | python -m json.tool
{
"action": "get",
"node": {
"createdIndex": 65,
"key": "/key1",
"modifiedIndex": 65,
"nodes": null,
"value": "value1"
},
"prevNode": null
}
[root@master1 etcd]# /opt/etcd/etcdctl -o extended get key1
Key: /key1
Created-Index: 65
Modified-Index: 65
TTL: 0
Index: 73
value1
[root@master1 etcd]# /opt/etcd/etcdctl ls #查看所有的key
/key5
/key6
/key7
/key8
/key9
/key1
/key2
/key4
/coreos.com
/key3
#api v3版本
[root@master1 ~]# ARG="--endpoints=" https://192.168.153.132:2379,https://192.168.153.133:2379 ,https://192.168.153.134:2379" --cert=/opt/etcd/certs/etcd-peer.pem --key=/opt/etcd/certs/etcd-peer-key.pem --cacert=/opt/etcd/certs/ca.pem"
[root@master1 ~]# for k in `seq 1 9`;do ETCDCTL_API=3 /opt/etcd/etcdctl $ARG put key$k$k value$k$k ;done
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG get key2 key5
key22
value22
key33
value33
key44
value44
[root@master1 ~]# ETCDCTL_API=2 /opt/etcd/etcdctl $ARG get / --prefix --keys-only #查看所有的key
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG get key --prefix #前缀是 Key的数据,得到所有的key*
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG get key11 -w json | python -m json.tool
{
"count": 1,
"header": {
"cluster_id": 8125260309611905335,
"member_id": 5461252244015707284,
"raft_term": 104,
"revision": 498001
},
"kvs": [
{
"create_revision": 496920,
"key": "a2V5MTE=",
"mod_revision": 496920,
"value": "dmFsdWUxMQ==", # echo 'dmFsdWUxMQ==' |base64 -d 可以进行解码
"version": 1
}
]
}
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG get key11 -w fields
"ClusterID" : 8125260309611905335
"MemberID" : 2656791367976377339 #每次查询会有不同,从不同的member查询
"Revision" : 498332 #全局单调递增变化,在本地测试的时候因为没有修改或者删除这个值不会变化,在新增或者修改一个值的是时候才会变化。我这里变化了是因为集群中已经有不断在更新的数据
"RaftTerm" : 104 #集群leader没有变,所以不会变
"Key" : "key11"
"CreateRevision" : 496920
"ModRevision" : 496920
"Version" : 1
"Value" : "value11"
"Lease" : 0
"More" : false
"Count" : 1

可以使用:ETCDCTL_API=3 /opt/etcd/etcdctl $ARG watch key --prefix监听多个
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG txn -i
compares:
value("key15") = "whatever"
success requests (get, put, delete):
get key15
failure requests (get, put, delete):
put key15 value15
put key14 valueX
FAILURE
OK
OK
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG get key15
key15
value15
[root@master1 ~]# ETCDCTL_API=3 /opt/etcd/etcdctl $ARG get key14
key14
valueX
16.4、典型场景介绍
16.4.1、元数据存储
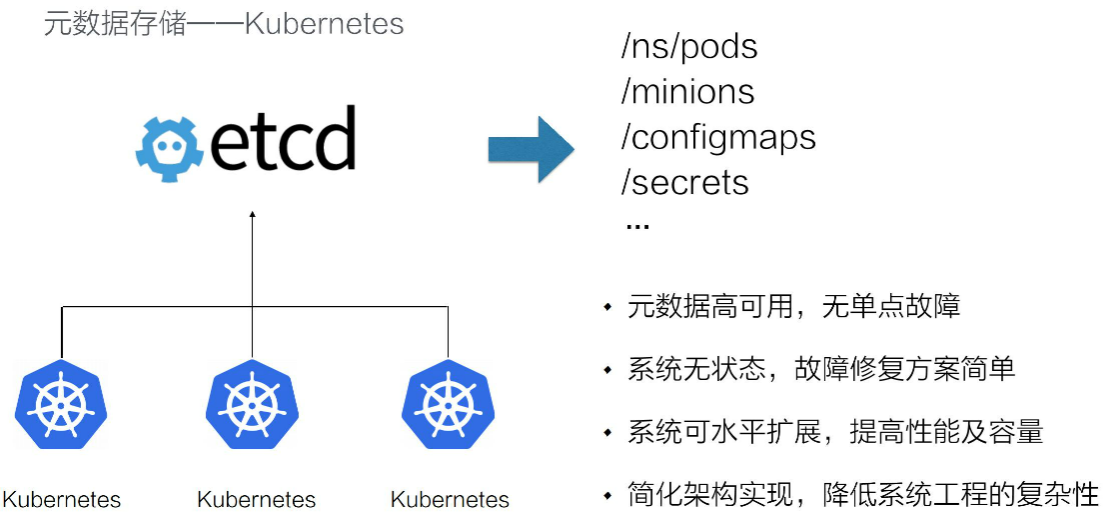
k8s将自己的状态数据也存储在etcd中。其状态数据的存储的复杂性将 etcd 给 cover 掉之后,Kubernetes 系统自身不需要再树立复杂的状态流转,因此自身的系统设立架构也得到了大幅的简化。
16.4.2、服务发现
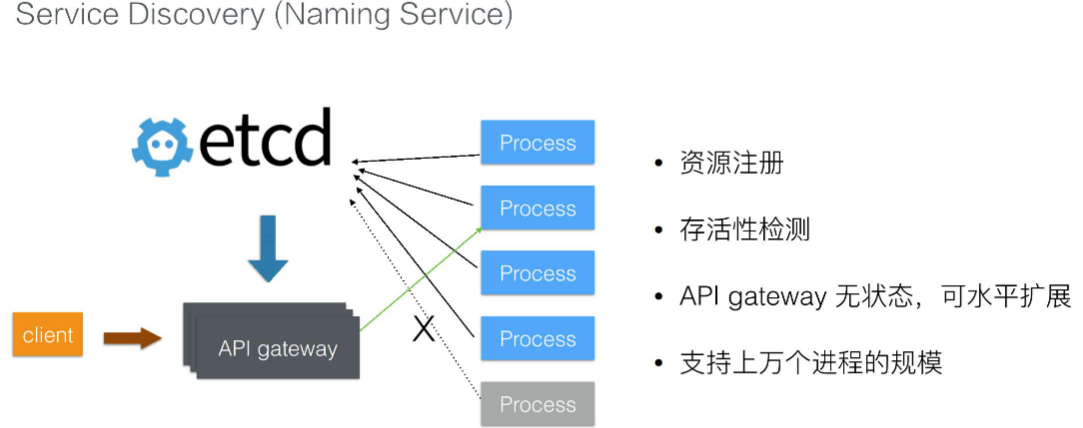
在分布式系统中,通常会出现的一个模式就是需要后端多个,可能是成百上千个进程来提供一组对等的服务,比如说检索服务、推荐服务。也就是说,我们事先无法知道这一组进程分布在哪里。为了解决这个问题,可以利用 etcd来解决资源注册的问题,当这一组后端进程被调度,在进程内部启动之后,可以将自身所在的地址注册到 etcd。
从而使得 API 网关能够通过 etcd 及时感知到后端进程的地址,这样当后端进程发生故障迁移的时候,会重新注册到 etcd 中,使得 API 网关能够及时地感知到新的集群地址。同时,因为 etcd 提供的 Lease 操作,可以及时感知到进程状态的变化,如果进程运行过程中死掉了,那么网关可以及时感知到进程状态的变化,从而将流量自动地切到其他的进程。
通过这种方式,整个状态数据被 etcd 接管,那么 API 网关本身也是无状态的,它可以水平地扩展来服务更多的客户。同时得益于 etcd 的良好性能,可以支持上万个后端进程的节点,基本上这种架构可以服务于非常大型的企业。
16.4.3、leader election
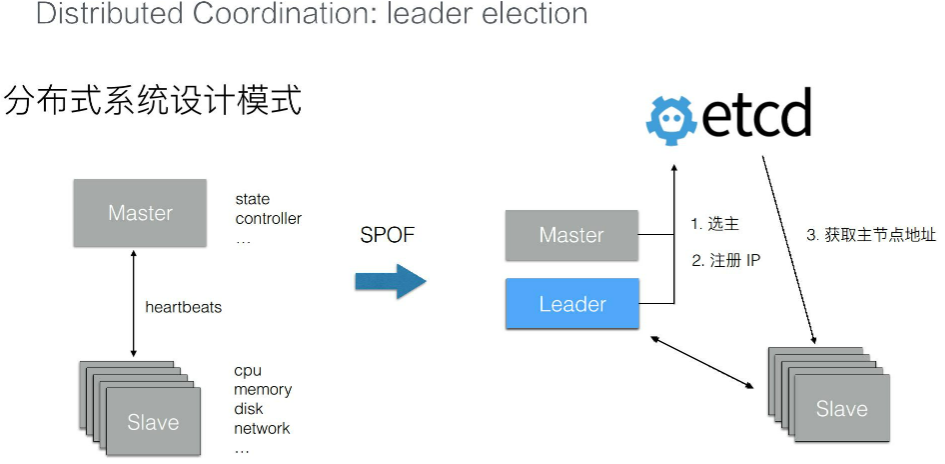
在分布式系统中,有一种典型的设计模式就是 Master+Slave。通常情况下,Slave 提供了 CPU 内存磁盘以及网络的各种资源 ,而 Master 用来控制这些资源的协同,Master 内部会存储一些状态数据,以及实现一组和业务逻辑相关的控制器,而 Slave 之间会和 Master 保持一个心跳的交互。
典型的分布式存储服务以及分布式计算服务,比如说 Hadoop,HDFS 等等,它们都是采用了类似这样的设计模式。这样的设计模式会有一个典型的问题:Master 节点的可用性。当 Master 故障以后,整个集群的服务就被停掉了,没有办法再服务用户的请求。
为了解决这个问题,需要去启动多个 Master。那么多个 Master 就会面临一个问题:谁来提供这个服务?因为通常情况下分布式系统和 Master 都是有状态逻辑的,无法允许多个 Master 同时运行。
可以通过 etcd 来实现选主,将其中的一个 Master 选主成 Leader,负责控制整个集群中所有 Slave 的状态。被选主的 Leader 可以将自己的 IP 注册到 etcd 中,使得 Slave 节点能够及时获取到当前组件的地址,从而使得系统按照之前单个 Master 节点的方式继续工作。当 Leader 节点发生异常之后,通过 etcd 能够选取出一个新的节点成为主节点,并且注册新的 IP 之后,Slave 又能够拉取新的主节点的 IP,从而会继续恢复服务。这一架构,在分布式系统中,被广泛使用。
16.4.4、分布式系统并发控制
Distrubuted Coordination:
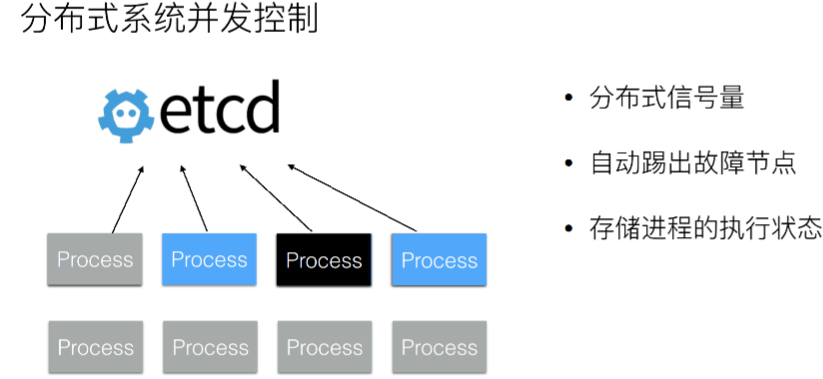
在分布式系统中,当我们去执行一些任务,比如说去升级 OS、或者说升级 OS 上的软件的时候、又或者去执行一些计算任务的时候,通常情况下需要控制任务的并发度。因为任务到了后端服务,通常是有容量瓶颈的。无法在同一个时刻,同时拉起成千上万的任务。这样后端的存储系统或者是网络资源都是吃不消的。
因此需要控制任务执行的并发度。在这个设计模式的进程中通过 etcd 提供的一些基本 API 操作来完成分布式的协同。这样当第一个进程执行完毕以后,第二个进程就可以开始执行。同时利用 etcd 的进程存活性检测机制可以做到:当将任务分发给一个进程,但这个进程没有执行完就已经死掉之后,可以继续换下一个进程继续工作。
也就是说,在这个模式中通过 etcd 去实现一个分布式的信号量,并且它支持能够自动地剔除掉故障节点。同时在进程执行过程中,如果进程的运行周期比较长,我们可以将进程运行过程中的一些状态数据存储到 etcd,从而使得当进程故障之后且需要恢复到其他地方时,能够从 etcd 中去恢复一些执行状态,而不需要重新去完成整个的计算逻辑,以此来加速整个任务的执行效率。
第十七章、深入理解etcd-etcd性能优化实践
17.1、理解etcd性能

大体可以分为两层:raft层和storage层。storage层又分为treeIndex和boltdb层 存储key/value数据
- raft层:需要通过网络传输数据,网络IO节点之间的RTT((Round-Trip Time 往返时延)和 / 带宽会影响,wal也受到磁盘IO写入速度影响
- storage层:磁盘 IO fdatasync(刷盘) 延迟会影响 etcd 性能,索引层锁的 block 也会影响 etcd 的性能。除此之外,boltdb Tx 的锁以及 boltdb 本身的性能也将大大影响 etcd 的性能。
- 其它:内核参数优化和grpc api的延迟也将影响etcd的性能
17.2、etcd性能优化-server端
- 硬件优化:参考
- 升级CPU/Memory
- 选取性能优秀的ssd
- 网络带宽优先级
- 独占部署,减少其他程序的运行时干扰
- 软件优化:
- etcd性能优化 - 软件
下由阿里贡献的一个性能优化。这个性能优化极大地提升了 etcd 内部存储的性能,它的名字叫做:**基于 segregated hashmap 的 etcd 内部存储 freelist 分配回收新算法。 cncf链接

上图是 etcd 的一个单节点架构,内部使用 boltdb 作为持久化存储所有的 key/value,因此 boltdb 的性能好坏对于 etcd 的性能好坏起着非常重要的作用。在阿里内部大量使用 etcd 作为内部存储元数据,在使用过程中我们发现了 boltdb 的性能问题,这里分享给大家。
上图中为 etcd 内部存储分配回收的一个核心算法,这里先给大家介绍一下背景知识。首先,etcd 内部使用默认为 4KB 的页面大小来存储数据。如图中数字表示页面 ID,红色的表示该页面正在使用,白色的表示未使用。
当用户想要删除数据的时候,etcd 并不会把这个存储空间立即还给系统,而是内部先留存起来,维护一个页面的池子,以提升下次使用的性能。这个页面池子叫做 freelist,如图所示,freelist 页面 ID 为 43、45、 46、50、53 正在被使用,页面 ID 为 42、44、47、48、49、51、52 处于空闲状态。
当新的数据存储需要一个连续页面为 3 的配置时,旧的算法需要从 freelist 头开始扫描,最后返回页面起始 ID 为 47,以此可以看到普通的 etcd 线性扫描内部 freelist 的算法,在数据量较大或者是内部碎片严重的情况下,性能就会急速的下降。
针对这一问题,我们设计并实现了一个基于 segregated hashmap 新的 freelist 分配回收算法。该算法将连续的页面大小作为 hashmap 的 key,value 是起始 ID 的配置集合。当需要新的页面存储时,我们只需要 O(1) 的时间复杂度来查询这个 hashmap 值,快速得到页面的起始 ID。
再去看上面例子,当需要 size 为 3 的连续页面的时候,通过查询这个 hashmap 很快就能找到起始页面 ID 为 47。
同样在释放页面时,我们也用了 hashmap 做优化。例如上图当页面 ID 为 45、46 释放的时候,它可以通过向前向后做合并,形成一个大的连续页面,也就是形成一个起始页面 ID 为 44、大小为 6 的连续页面。
综上所述:新的算法将分配的时间复杂度从 O(n) 优化到了 O(1),回收从 O(nlogn) 优化到了 O(1),etcd 内部存储不再限制其读写的性能,在真实的场景下,它的性能优化了几十倍。从单集群推荐存储 2GB 可以扩大到 100GB。该优化目前在阿里内部使用,并输出到了开源社区。
这里再提一点,本次说的多个软件的优化,在新版本中的 etcd 中都会有发布,大家可以关注使用一下。
17.3、etcd性能优化-client端

针对于以上的客户端操作,我们总结了几个最佳实践调用:
- 针对于 Put 操作避免使用大 value,精简精简再精简,例如 K8s 下的 crd 使用;
- 其次,etcd 本身适用及存储一些不频繁变动的 key/value 元数据信息。因此客户端在使用上需要避免创建频繁变化的 key/value。这一点例如 K8s下对于新的 node 节点的心跳数据上传就遵循了这一实践;
- 最后,我们需要避免创建大量的 lease,尽量选择复用。例如在 K8s下,event 数据管理:相同 TTL 失效时间的 event 同样会选择类似的 lease 进行复用,而不是创建新的 lease。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号