kubernetes-学习笔记_魂士
一、第一章(快速入门)
1.1、贵圈发展史
- 2004-2007 Google大规模使用容器Cgroups技术
- 2008.1 cgroups合并进入linux内核主干
- 2013.1 docker项目发布,对传统paas产品"降维打击"
- 2014.6 kubernetes项目发布,Google Borg/Omega系统思想借助开源社区”重生“,”容器设计模式“的思想正式成立
- 2015.7 CNCF(云原生基金会)成立,k8s成为第一个CNCF项目
- 2015-2016 ,容器编排”三国争霸“,Docker Swarm(偏生态),Mesos(偏技术),Kubernetes在容器编排领域角逐。解決你懂的
- 2017 Kubernetes项目标准确立,docker公司选举在核心产品内置kubernetes服务,Swarm项目逐渐停止维护
- 2018 云原生技术理念逐步萌芽,kubernetes和容器成为所有云厂商既定标准,以”云“为核心的软件思想逐步行程
1.2、landscape
landscape 云原生全景图
1.3、云原生
1、云原生定义:其实是一条使用户能敏捷的、可复制、可扩展的最大化利用“云”的能力、发挥“云”的价值的最佳路径,官方定义:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach. These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil. The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
2、云原生的愿景:软件就生在云上、长在云上的,全新的软件开发,发布和运维模式、
3、云原生的技术范畴:
- 云应用定义与开发流程:应用定义与镜像制作,CI/CD,消息和Streaming等
- 云应用编排与管理:应用编排和调度、服务发现和治理、远程调用、API网关、Service Mesh
- 监控与可观测性:监控、日志、Tracing、混沌工程
- 云原生底层技术:容器运行时、云原生存储技术、云原生网络技术
- 云原生工具集:流程自动化与配置管理、云原生安全技术、云端密码管理
- Serveless:Faas、Baas、Serveless计费 //Functions as a Service,Backend as a service
4、云原生思想的两个理论基础:
-
不可变基础设施:
- 目前实现:容器镜像 //基础设施不可变,是完全一个自包含,自描述可以随时迁移的一个东西
-
云应用编排理论:
- 目前实现:容器设计模式
5、基础设施向云演进的过程:
- 传统应用基础设施:(可变)
- 举例:部署需要SSH到服务器,逐个调整配置,以及将代码部署到现有服务器上。基础设施是独一无二的宠物,要细心呵护
- 对“云”友好的应用基础设施:(不可变)
- 部署完成后,基础设施不会修改或改变,如果要更新构建新的镜像即可。基础设施是可以替代的牲口,随时替换
6、基础设施向云演进的意义:
-
基础设施一致性和可靠性:
- 容器镜像 //镜像可以在任何地方打开
- 自包含 //镜像包含运行所需要的所有依赖
- 可飘逸 //可以飘逸到任何位置
-
简单可预测的部署与运维:
- 自描述,自运维 //
- 流程自动化 //
- 容易水平扩展 //实例个数调整
- 可快速复制的管控系统与支持组件 //
7、云原生关键技术点
- 自包含、可定制的应用镜像
- 应用快速部署与隔离能力
- 应用基础设施创建和销毁的自动化管理
- 可复制的管控系统与支撑组件
二、第二章(K8s核心概念与API原语)
2.1、什么是Kubernetes
Kubernetes 源与希腊语,意为"舵手",或“飞行员”,k8s 是通过将8个字母“ubernete"替换为8而导出的缩写,container意为集装箱,k8s寓意成为运送集装箱的轮船。k8s为一个自动化的容器编排平台:负责应用的部署、弹性、管理
2.2、核心功能
- 服务发现与负载均衡
- 自动发布与回滚
- 容器自动装箱 //容器的自动调度,把一个容器放到集群的某一个机器上
- 存储编排
- 自动恢复 //检测节点状态,在节点异常后自动调度pod
- 配置与密文管理
- 批量执行
- 水平伸缩 //修改副本值即可调整pod个数
2.3、架构

Kubernetes各个组件简介
- apiserver:处理api操作,K8s中所有的组件都会和apiserver进行连接,组件和组件之间不会进行连接,apiserver负责和etcd交互。集群内的所有操作都会经过apiserver
- controller-manager: 负责集群内的资源对象(node,namespace,service,token等) 达到预期的工作状态 //只有一个active,可以进行热备
- scheduler: 用与为提交的container 调度到合适的机器上 //只有一个active,可以进行热备
- etcd:元数据存储
- kubelet: 负责真正去运行这些组件,监听apiserver的pod绑定事件,提交到container runtime中,在os上创建容器真正创建容器所需要运行的环境。
- kub-proxy: 利用了iptables的能力,来进行本地ipvs 规则创建
2.4、pod创建过程
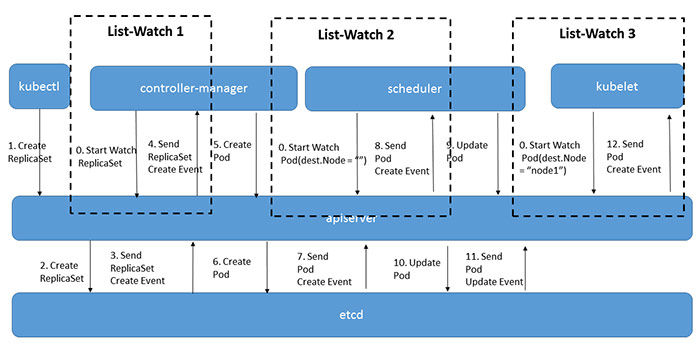
pod 创建过程:
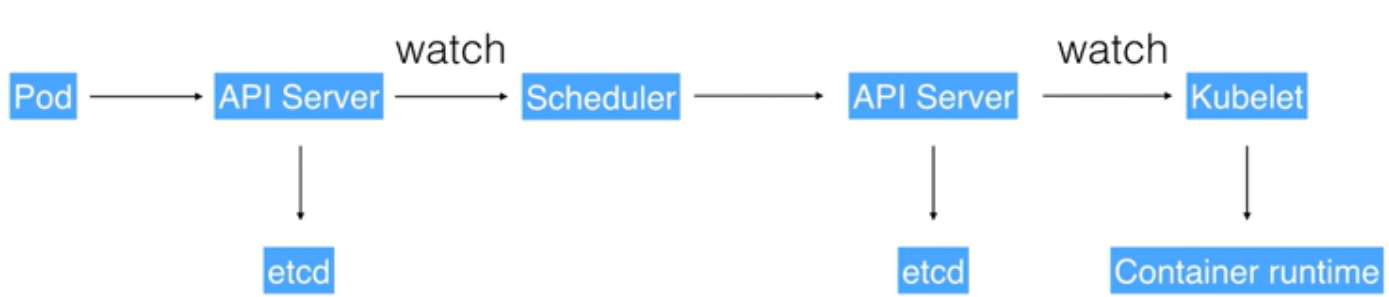
0、各组件启动时向apiserver 发起watch请求进行订阅,告诉apiserver自己需要订阅哪些类型的变化的数据。watch是一个典型的发布-订阅模式可以有条件的(比如kubelet只关心自己节点上的Pod列表)。list是watch失败后,数据过于陈旧后的弥补手段。k8s的watch功能是建立在etcd的watch之上的,etcd key-value发生变化,通知apiserver,apiserver对外提供watch api。
1、用户通过cli或者ui进行pod创建,请求被apiserver接收
2、apiserver收到请求后,不会直接创建pod,而是生成一个包含创建信息的yaml,并将yaml信息存储到etcd
3、scheduler查看k8s api,判断pod.spec.Node == null?决定是否需要创建,并根据一定的算法找到最合适的pod,并将信息存储到etcd(通过apiserver存储)
4、kubelet watch apiserver查询自己是否有新增pod需要创建,如果有,Kubelet调用contianer runtime去创建容器运行环境
2.5、主要概念
-
pod : 是最小的调度以及资源单元、由一个或者多个容器组成、定义容器运行的方式(Command,环境变量等),提供给容器共享的运行环境(网络,进程空间等)
-
Volume:声明在pod中的容器可访问的文件目录,可以被挂载在Pod中一个或多个容器的指定路径下,支持多种后端多种存储的抽象(本地存储、分布式存储、云存储)
-
Deployment: 定义一组Pod的副本数目、版本等,通过Controller-manager维持Pod的数目;通过控制器指定的策略控制版本(滚动升级、重新生成、回滚等)
-
Service:提供访问一个或多个Pod实例的稳定访问地址,支持多种访问方式实现(ClusterIP,NodePort,LoadBalancer)
-
NameSpace:一个集群内部的逻辑隔离机制(鉴权、资源额度),每个资源都属于一个namespace,同一个Namespace中的资源命名唯一,不同Namespace中的资源可重命名
-
API:HTTP+JSON/YAML类型的api,kubectl/UI/curl命令 等发起请求
-
Label:一组key:value,可以被selector所查询,select color=red,资源集合的默认表达形式,例如Service 对应一组Pod
2.6、minikube
本地测试和实验使用
https://kubernetes/io/docs/tasks/tools/install-minikube
三、第三章(容器基本概念)
3.1、容器与镜像
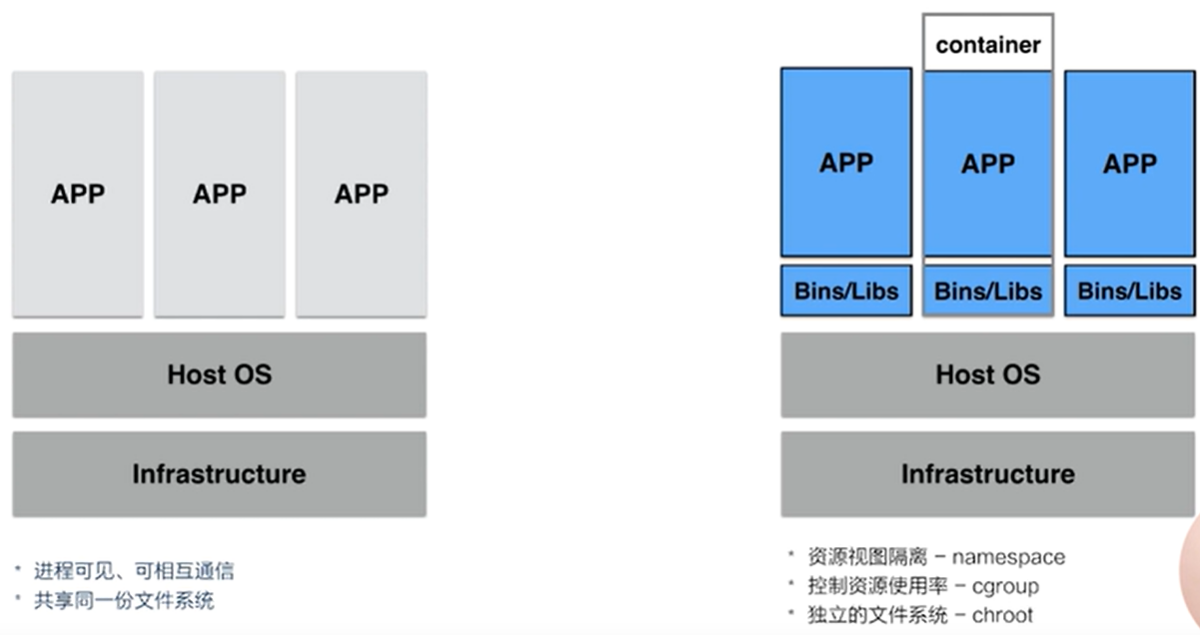
传统物理机上进程特点:APP可以相互“看见“,相互通信,使用同样的文件系统,同样的系统资源。意味着具有privileged权限的进程可以攻击其他进程。使用同一个文件系统,导致APP可以对已有的文件系统进行增删改查,进程间资源依赖会出现冲突,以及系统资源抢占问题。
为了解决上述问题,可以使用以下思路:
-
chroot: 视图级别进行隔离,把一个子目录编程根目录
-
namespace:资源试图隔离。进程在环境内使用独立的环境,但是资源还是使用操作系统的
-
cgroup: 限制APP的资源使用率
什么是容器:
- 容器是一个视图隔离、资源可限制、独立文件系统的进程集合。
- 视图隔离:如能看见部分进程,独立主机名等;
- 控制资源使用率:如2G内存大小;CPU使用个数等等。
什么是镜像:
- 运行容器所需要的文件集合-容器镜像
- DockerFile- 描述镜像构建步骤
- 构建步骤所产出文件系统的变化 - changeset //镜像分层和复用 的理念和作用
- 类似:disk snapshot
- 提高分发效率,减少磁盘压力 #镜像分层带来的好处,各层级镜像复用,基础镜像被上层镜像所共用。#举例,如果本地已经有nginx的基础镜像,针对下载不同版本,只需要下载所需的镜像就可以
DockerFile最佳实践: https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
容器和镜像:
- 容器:和系统其他部分隔开的进程集合,包括网络,进程,文件系统等等
- 镜像:容器所需要的所有文件集合- Build once,Run anywhere
3.2、容器生命周期
容器是一种具有隔离特性的进程集合,在使用doker run的时候可以使用image来提供独立的文件系统,以及指定相应的程序。所指定的这个程序称为init进程。容器的启停和init进程同步:
单进程模型:
- init进程生命周期 = 容器生命周期
- 运行期间可运行exec执行运维操作
数据持久化:
- 独立于容器的生命周期
- 数据卷 - docker volume vs bind
容器的生命周期和init进程是一致的
# bindg host dir into container
docker run -v /tmp:/tmp busybox:1.25 sh -c "date > /tmp/demo.log"
# check result
cat /tmp/demo.log
# let it handled by docker container engine
docker create volume demo
#demo is volume name
docker run -v demo:/tmp busybox:1.25 sh -c "date > /tmp/demo.log"
#check result
docker run -v demo:/tmp busybox:1.25 sh -c "cat /tmp/demo.log"
3.3、容器项目的架构
moby和docker-ce以及docker-ee说明:
- moby是继承了原先的docker的项目,是社区维护的的开源项目
- docker-ce是docker公司维护的开源项目,是一个基于moby项目的免费的容器产品
- docker-ee是docker公司维护的闭源产品,是docker公司的商业产品
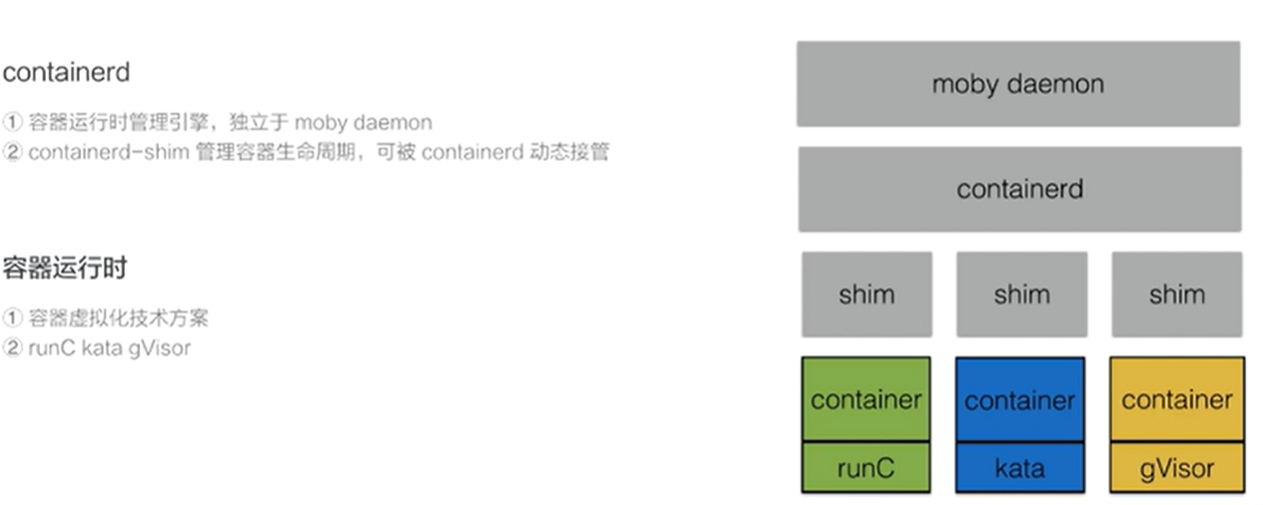
- moby daemon:提供容器镜像,网络,volume等的管理
- containerd:容器运行时管理引擎,独立于moby daemon
- shim:类似于守护进程(单个容器的),shim负责管理容器的生命周期,容器可以有不同的运行时,现在有多种容器运行时的解决方案(runC,kata,gVisor等)。shim是用于针对不同的容器运行时所开发的。适用于多种容器运行时。并且可以被containerd动态接管
shim的另外一个好处:对moby或者containerd升级,因为有了shim,所以可以做到不影响业务
3.4、容器和vm的差异
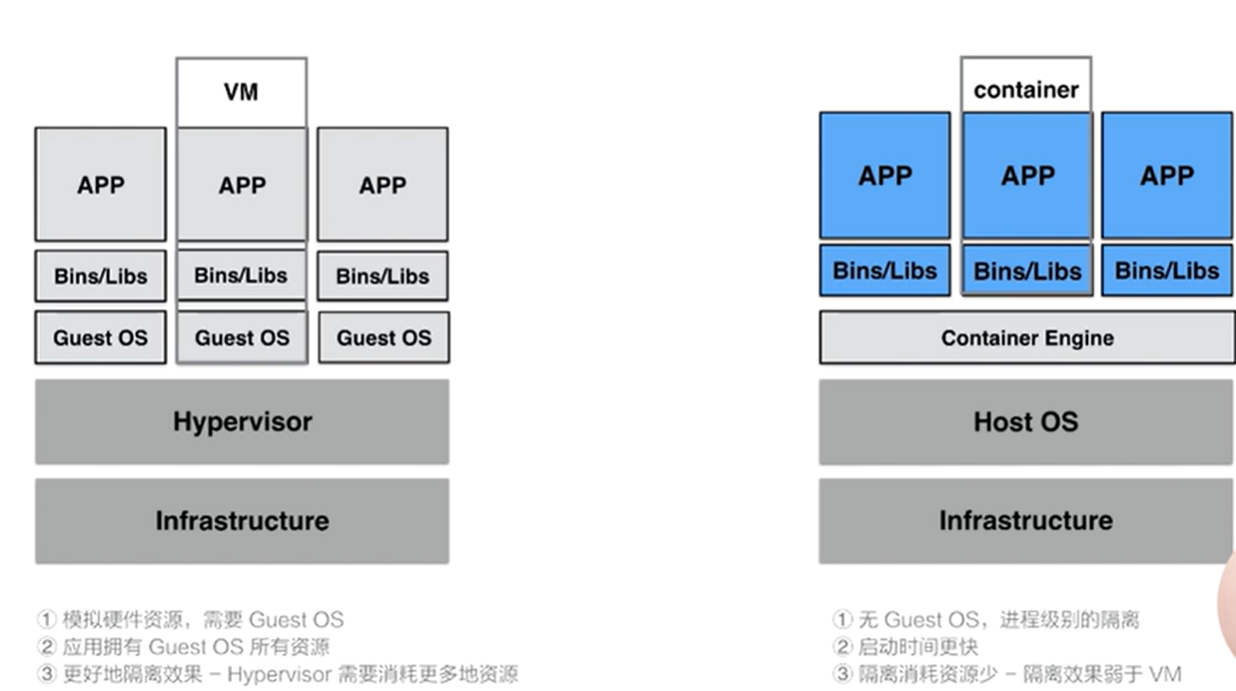
- VM
- 隔离效果好,每个应用都是相互独立的,看不到其他guest os的应用
- 占用更大的磁盘空间和更多的资源
- container:
- 启动时间较快
- 磁盘空间占用较小
- 隔离效果要比vm差很多,所以整体提供的隔离效果要差很多。kata container和gadvisor等强隔离的解决方案因此就火了起来
四、第四章(容器设计模式)
4.1、为什么我们需要pod
4.1.1、容器的本质
-
容器的本质是?
- 一个视图被隔离、资源受限的进程
- 容器中PID = 1 的进程就是应用本身
- 容器里PID = 1的进程就是应用本身
- 管理虚拟机 = 管理基础设施; 管理容器 = 直接管理应用本身
- 容器里PID = 1的进程就是应用本身
- 容器中PID = 1 的进程就是应用本身
- 一个视图被隔离、资源受限的进程
-
kubernetes 是什么?
- kubernetes就是云时代的操作系统
- 以此类推,容器镜像其实就是:这个操作系统的软件安装包
- 容器 = 进程(linux线程)
- Pod = ?
- 进程组(linux线程组)
- kubernetes就是云时代的操作系统
以kubernetes为一个操作系统来说明:(来看一个真是操作系统中的例子)

linux实现 线程为 轻量级的进程
4.1.2、进程组概念提出
- 举例: hello world程序由4个进程组成,这些进程之间共享某些文件
- 问题:helloworld程序如何用容器跑起来呢?
- 解法1: 在一个docker容器中,启动这4个进程
- 疑问:容器 PID =1的进程就是APP本身的main进程,那么”谁“来负责管理剩余的3个进程?
- 容器是”单进程“模型
- 除非:
- 应用进程本身具备”进程管理“能力(这意味着:helloworld程序需要具备systemd的能力)
- 或者,容器的PID=1进程改为systemd
- 这会导致:管理容器 = 管理systemd != 直接管理应用本身
- 解法1: 在一个docker容器中,启动这4个进程
注意:除非程序具有systemd的功能,否则他是没有管理多个进程的能力:
- 如果在容器中启动了多个进程,只有一个能成为pid为1的进程。如果pid为1的进程挂了,那么其他的进程就成为了孤儿,没人能够回收容器内其他进程的资源。
- 如果在程序中run systemd程序,那么就会存在第二个问题:没办法直接管理应用,因为应用的生命周期被systemd接管,应用状态的生命周期就不等于容器的生命周期。并且无法及时获知应用程序状态
4.1.3、pod是什么
Pod为K8s提出的类似于一个进程组的概念:
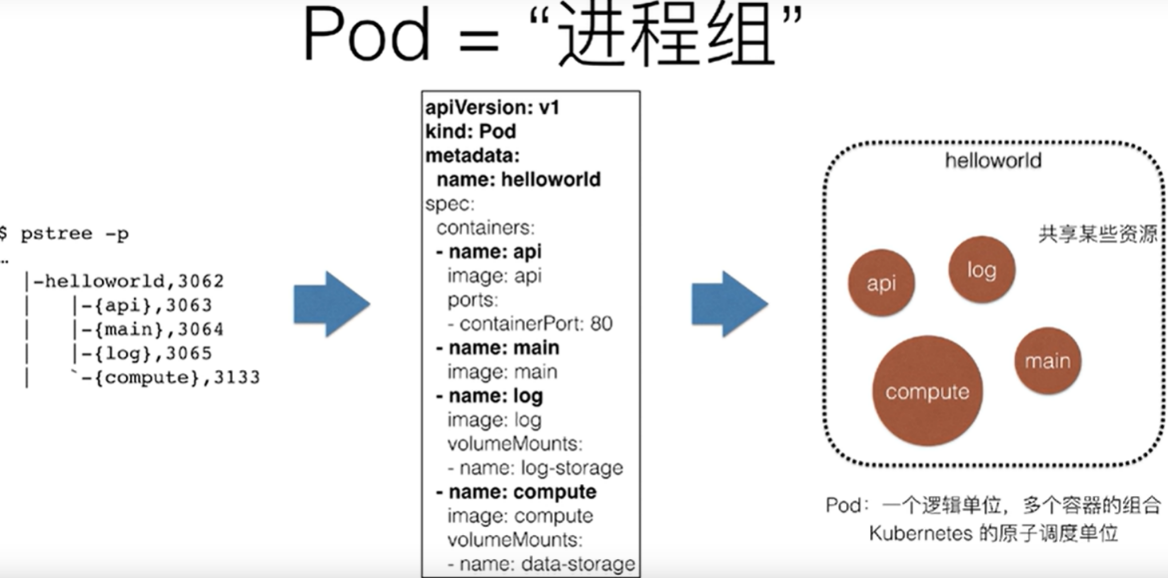
四个进程共同组成的一个应用hello workld,实际上会被定义为拥有四个容器的pod。pod是一个逻辑概念,真实启动的是4个容器。pod是k8s分配资源的一个单位。pod是k8s分配资源的一个单位
4.1.5、来自Google Borg的思考
Google的工程师么们发现,在Borg项目部署的应用,往往都粗壮乃着类似于”进程和进程组“的关系,更具体的说,就是这些应用之间有着密切的协作关系,使得他们必须部署在同一台机器上并且分享某些信息。
思考:为什么Pod必须是原子调度单位,为何不可以通过调度让容器实现调度在同一台机器上?
- 举例:两个容器紧密协作
- App:业务容器,写日志文件
- LogCollector: 转发日志文件到ElasticSearch中
- 内存要求:
- App:1G
- LogCollector:0.5G
- 当前可用内存:
- Node_A: 1.25G
- Node_B: 2G
- 如果APP 调度到了Node A上,会怎么样?
- Task co-scheduling 问题
- Mesos:资源推挤(resource hoarding):
- 所有设置了Affinity约束的任务到达时,才开始统一进行调度 #两个容器都提交了,才会进行调度
- 问题:调度效率损失和死锁
- Google Omega: 乐观调度处理冲突 #omega为borg的后代,目的是为了改善基于borg的软件生态
- 先不管这些冲突,而是通过精心设计的调度机制在出现了冲突之后解决问题,通过回滚机制解决问题
- 较为复杂
- kubernetes: pod
- Mesos:资源推挤(resource hoarding):
- Task co-scheduling 问题
Pod解决了这两个问题:1、怎么去描述超亲密关系;2、怎么对超亲密关系的容器或者业务进行调度
- 亲密关系 - 调度解决
- 两个应用需要运行在同一台宿主机上
- 超亲密关系 - Pod解决
- 会发生直接的文件交换
- 使用localhost或者socket进行本地通信
- 会发生非常频繁的RPC调用
- 会共享某些Linux namespace(比如一个容器要加入另外一个容器的netowrk namespace)
4.2、pod的实现机制
Pod要解决的问题:如何让一个pod中的多个容器之间最高效的共享某些资源和数据?容器之间原本是被Linux Namespace和cgroups隔离开的
解决方法分为两个部分:共享网络和共享存储
4.2.1、共享网络
-
容器A和B
- 通过infra container的方式共享同一个 Network NameSpace #pause还提供PID,network,IPC,UTS等命名空间
- 镜像: k8s.gcr.io/pause;汇编语言编写的、永久处于”暂停“,puase:3.1 大小为743KB非常小
- 直接使用localhost进行通信
- 看到的网络设备跟infra容器看到 的完全一样
- 一个pod只有一个ip地址,也就是这个pod的network Namespace对应的IP地址
- 所有网络资源,都是一个pod一份,并且被该pod中的所有容器共享
- 整个Pod的生命周期和infra 容器一致,而与容器A和B无关
- 通过infra container的方式共享同一个 Network NameSpace #pause还提供PID,network,IPC,UTS等命名空间
-
通过infra container的方式共享network namespace
-
一个pod中的所有容器看到的网络试图是一样的,整个pod的生命周期一定是等于infra pod的生命周期,并且infra pod一定是第一个启动的
4.2.2、pod如何去共享存储
apiVersion: "apps/v1"
kind: "Pod"
metadata:
name: "name01"
spec:
restartPolicy: "Always"
volumes:
- name: shared-data
hostPath:
path: /data
containers:
- name: nginx-controller
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c","echo Hello from the debian container ! > /pod-data/index.html"]
shared-data 对应在宿主机上的目录会被同时绑定挂载进了两个容器当中
4.3、详解容器设计模式
所有设计模式的本质都是: 解耦和重用
案例: WAR包 + Tomcat的容器化
- 方法一: 把WAR包和Tomcat大包进一个镜像
- 无论是WAR包和Tomcat更新都需要重新制作镜像
- 方法二:镜像里只打包Tomcat。使用数据卷(hostPath)从宿主机上将WAR包挂载进tomcat容器
- 需要维护一套分布式存储系统
- 有没有其他更通用的方法?initContainer
InitContainer:
apiVersion: "apps/v1"
kind: "Pod"
metadata:
name: "javaweb-2"
spec:
initContainers:
- image: resouer/sample:v2
name: war
command: ["cp","/sample.war","/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- name: tomcat
image: tomcat7:latest
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- name: app-volume
mountPath: /root/apache-tomcat-7.0.42-v2/webapps
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
- init Container会比spec.Containers定义的用户容器先启动,并且严格按照定义的用户容器先启动;如果定义了多个initContainer,initContainer会严格按照定义顺序依次执行
- /app是一个Volume
- Tomcat容器,同样声明了挂载该Volume到自己的webapp目录下
- 故当Tomcat容器启动时,它的webapps目录下就一定会存在sample.war
- 在需要升级的时候,可以只更新sample镜像或者只更新tomcat镜像
这样的一种设计方式, 就是k8s中一个比较经典的设计模式:称为sidecar : 通过在pod内定义专门容器,来执行业务容器所需要的辅助工作
Sidecar的使用场景:
- 应用与日志收集,Fluentd等作为日志收集
- 代理容器:代理容器对业务容器屏蔽被大力的服务集群,简化业务代码的实现逻辑。
- 适配器容器:将业务容器暴漏出来的接口转换为另一种格式(yaml转为json,/metric转为/healthz等)
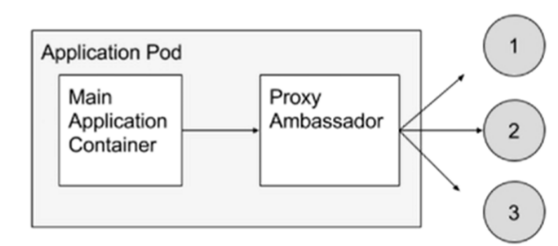
代理容器场景:一个container 需要访问外部系统或者服务,但是外部的服务或系统为集群状态,业务pod只需要访问一个ip地址,一种方法,改业务代码记录外部服务地址,还有一种方式就是解耦通过sidecar代理容器。单独写一个proxy专门用来对接外部的服务集群,但是对外只要暴漏一个ip地址就可以了。通过proxy代为连接集群。这里面该pod和proxy之间通信使用localhost无性能损耗。
五、第五章(应用编排与管理)
5.1、资源元信息
kubernetes资源对象
- Spec: 期望的状态
- Status:观测到的状态
- Kind: 资源类型,Deployment,StatefulSet等
- Metadata:
- Labels:
- Annotations:
- OwnerReference: 描述多个资源之间的关系
5.1.1、Label
- 标识性的Key: Value元数据
- 作用:
- 用于筛选资源
- 唯一的组合资源的方法
- 可以使用selector来查询
- 类似于:SQL ' select * from ..wher ...'
| 资源 | 标签1 | 标签2 |
|---|---|---|
| R1 | Tie:front | Env:dev |
| R2 | Tie:back | Env:prod |
| R3 | Tie:front | Env:test |
| R4 | Tie:back | Env:gray |
常见的selector:
- 相等型Selector: Tie=front 筛选结果为R1和R3
- 相等型的selector多个selector: Tie=front,Env=dev筛选结果为R1
- 集合型selector:Env in (test,gray) 筛选结果为R3和R4
- 其他集合selector:
- Tie notin (front,back)
- Tie notin release
- Tie = !release
5.1.2、annotations
- 作用:
- 存储资源的非标识性信息
- 扩展资源的spec/status
- 特点:
- 一般比label大
- 格式为 key:value格式
- 可以包含特殊字符
- value可以结构化也可以非结构化
- 可以用来存储证书id等
5.1.3、ownerReferences
- ”所有者“即集合类资源
- Pod的集合:Replicaset,statefulset
- 集合类资源的控制器创建了归属资源
- Replicaset控制器创建Pod
- 作用:
- 方便反向查找创建资源的对象
- 方便进行级联删除
5.1.4、实践
[root@master1 yaml]# kubectl run nginx1 --image=reg.mt.com:5000/nginx:latest -l env=dev,tie=front --dry-run=true -o yaml > pod1.yaml
[root@master1 yaml]# kubectl run nginx2 --image=reg.mt.com:5000/nginx:latest -l env=dev,tie=front --dry-run=true -o yaml > pod2.yaml
[root@master1 yaml]# cat pod1.yaml #pod2的只有pod的名称和label不一样
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
env: dev
tie: front
name: nginx1
spec:
replicas: 1
selector:
matchLabels:
env: dev
tie: front
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
env: dev
tie: front
spec:
containers:
- image: reg.mt.com:5000/nginx:latest
name: nginx1
resources: {}
status: {}
[root@master1 yaml]# kubectl apply -f pod1.yaml -f pod2.yaml
deployment.apps/nginx1 created
deployment.apps/nginx2 created
#1、获取pod的label
[root@master1 yaml]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx1-fb5497587-gdj9k 1/1 Running 0 3m15s env=dev,pod-template-hash=fb5497587,tie=front
nginx2-6d5c4f84fb-qzr9q 1/1 Running 0 3m15s env=dev,pod-template-hash=6d5c4f84fb,tie=front
#2、为pod打标签/删除标签
[root@master1 ~]# kubectl label pods nginx1-fb5497587-gdj9k env=test --overwrite
pod/nginx1-fb5497587-gdj9k labeled
[root@master1 ~]# kubectl get pods --show-labels #因为deployment,所以直接打pod会自动创建一个新的pod
NAME READY STATUS RESTARTS AGE LABELS
nginx1-fb5497587-54x29 1/1 Running 0 14s env=dev,pod-template-hash=fb5497587,tie=front
nginx1-fb5497587-gdj9k 1/1 Running 0 3h9m env=test,pod-template-hash=fb5497587,tie=front
nginx2-6d5c4f84fb-qzr9q 1/1 Running 0 3h9m env=dev,pod-template-hash=6d5c4f84fb,tie=front
[root@master1 ~]# kubectl label pods nginx1-fb5497587-gdj9k env- #删除标签
#3、label查找
[root@master1 ~]# kubectl get pods --show-labels -l 'env in (dev,prod)'
NAME READY STATUS RESTARTS AGE LABELS
nginx1-fb5497587-54x29 1/1 Running 0 36m env=dev,pod-template-hash=fb5497587,tie=front
nginx2-6d5c4f84fb-qzr9q 1/1 Running 0 3h45m env=dev,pod-template-hash=6d5c4f84fb,tie=front
[root@master1 ~]# kubectl get pods --show-labels -l 'env notin (dev,prod)'
NAME READY STATUS RESTARTS AGE LABELS
nginx1-fb5497587-gdj9k 1/1 Running 0 3h45m pod-template-hash=fb5497587,tie=front
#4、anotate
[root@master1 ~]# kubectl annotate pods nginx1-fb5497587-dxl7k desc='author by MT'
pod/nginx1-fb5497587-dxl7k annotated
[root@master1 ~]# kubectl get pods nginx1-fb5497587-dxl7k -o yaml |grep annotations -A3
annotations:
desc: author by MT
creationTimestamp: "2021-01-20T13:24:51Z"
generateName: nginx1-fb5497587-
#5、ownerReference
[root@master1 ~]# kubectl get pods nginx1-fb5497587-dxl7k -o yaml |grep ownerReferences -A5
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet #被ReplicaSet控制的pod
name: nginx1-fb5497587 #这个ReplicaSet的名称是 nginx1-fb5497587
[root@master1 ~]# kubectl get ReplicaSet nginx1-fb5497587 -o yaml |grep ownerReferences -A5
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: Deployment
name: nginx1
5.2、控制器模式
5.2.1、控制循环
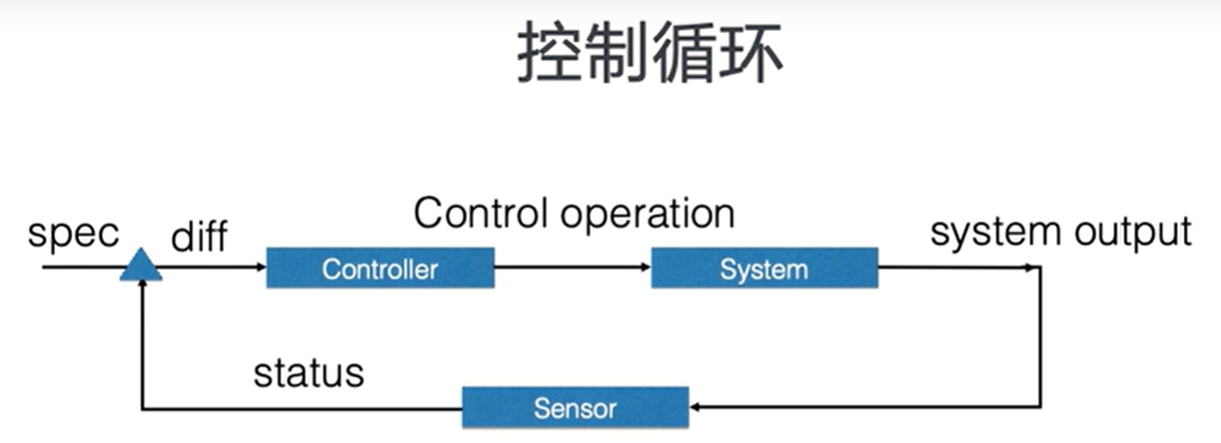
控制器模式,最核心的就是控制循环
- 组件包含:控制器、被控制的系统、能够观测系统的传感器Sensor #三个逻辑组件
- 各组件独立自主地运行
- 不断使系统向终态趋近 status-> spec
外界通过修改资源的spec控制资源,控制器比较被控制资源的spec和status,计算一个diff。diff用来决定对系统执行什么样的操作。控制操作会使得系统产生新的输出。并被传感器以资源status的形式上报。控制器的各个组件都是独立自主的运行。
1、传感器sensor:
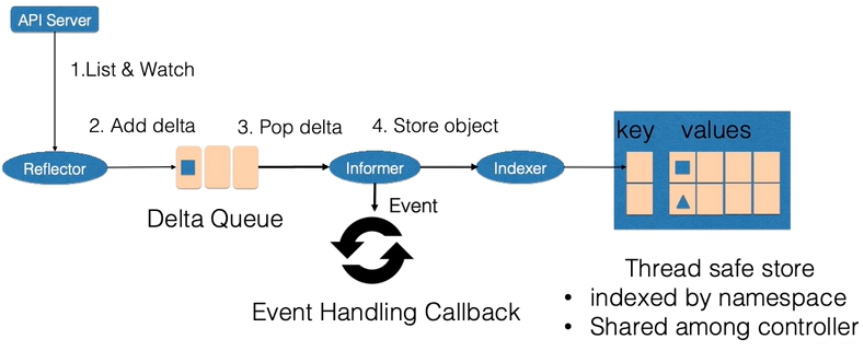
控制循环中逻辑的传感器主要有 Reflector,Informer,Indexer 三个组件构成。
- Reflector: 通过list和watch apiserver来获取资源的数据
- list用来在controller重启以及连接中断的情况下进行系统资源的全量分析
- watch在多次list之间进行增量的资源更新
- Reflector在获取新的资源数据后,会在一个delta队列中插入一个(包括资源本身信息以及资源事件(event)类型)的记录;delta队列保证同一个对象在queue中只有一条记录
- Informer: 不断从delta队列中pop出记录, 一方便把资源事件交给event回调函数,一方面把资源对象交给Indexer
- Indexer:把资源记录到缓存中。缓存默认情况下是以资源的namespace进行索引,并且被多个controller-manager共享
2、控制器循环中的控制器组件
- 主要由event handling 函数,以及worker组成
- 事件处理函数:监听informer中的新增、更新、删除的事件。并根据控制器的逻辑决定是否需要处理。对于需要被处理的event,会把事件关联资源的namespace以及name信息放入到一个工作queue中。并且由worker池中的一个worker处理
- 工作队列:对资源对象进行去重,从而避免多个worker处理同一个资源。worker在处理资源时,一般需要worker的名字,来重新获取最新的资源数据,用来创建或者更新资源对象,或者调用其他的外部服务。如果worker处理失败,一般会把资源重新加入到工作队列中,方便后续重试
5.2.2、控制器循环例子
举例:ReplicaSet(name=rsA,namespace=nsA)资源的replicas(pod个数)使用kubectl edit由2改为3的场景
先更新replicaset.spec,后更新pod,最后更新replicaset.status
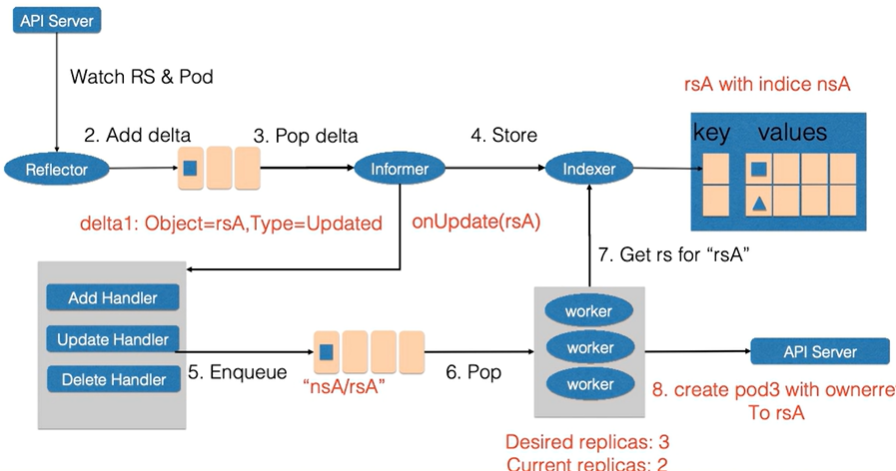
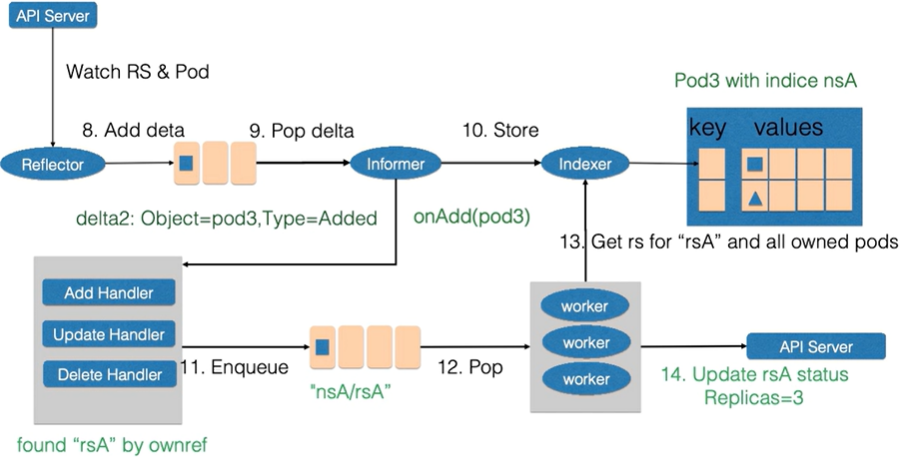
-
1、Reflector会watch Replicaset和Pod两种资源的变化,发现变化后在delta队列中新增记录
-
2、Informer从delta queue中pop记录,把新的replicaset更新到缓存中(交给indexer)并以namespace和rsa作为索引,另一方面调用update的回调函数
-
3、Replicaset控制器发现replicaset发生变化后,会把nsA/rsA字符串放入到工作队列中
-
4、工作队列中的一个worker获取 nsA/rsA 这个字符串的key,并且从缓存中获取最新的replicaset数据
-
5、worker通过比较replicaset中的status和spec中的replicas数据,发现需要对replicaset进行扩容。因此通知apiserver replicaset创建了一个pod,这个pod的ownereference取自 rsA,
-
6、Reflector watch到了新增事件,在delta中添加记录
-
7、informer从delta中获取新的记录,一方面通过indexer放入缓存中,另一方面调用repliset的控制器的add回调函数,add函数通过ownereference为rsA找到对应的replicaset,并把包括replicaset和namespace字符串放到 工作队列中
-
8、replicaset的worker从工作队列中获取数据,从缓存中获取最新的replicaset记录。并得到所有创建的pod
-
9、因为replicaset状态不是最新的,也就是所有创建的pod的数量已经不是最新的。因此更新rsA的status和spec一致。replicaset中的sepc和status达到了一致
5.3、控制器模式总结
API有两种声明方式:
- 声明式API:市场占用率达到90%,副本个数为3个 //家长和孩子交流
- 命令式API:吃饭,删除一个pod //领导和员工交流

kubernetes控制器模式:
- 由声明式的API驱动 - k8s 资源对象
- 由控制器异步地控制系统向终态驱近
- 使系统的自动化和无人值守成为可能
- 便于扩展- 自定义资源和控制器(特别的,operator)

