Attention机制
本文主要介绍一下时下很热门的 Attention 机制,从什么是 Attention 机制,到它是如何被运用到 NLP 领域,后来又应用到 CV 领域的。
什么是 Attention 机制?
Attention 机制的思想其实是借鉴了生物在观察和学习行为中的过程,也就是我们人类通常在观察和学习的时候,都是通过快速的获取全局的信息,建立起对事物的观察重点或学习区域,这些需要重点关注的目标区域,就是我们注意力的焦点。就和我们日常生活中处理事情一样,我们没有办法同时处理所有的事情,我们会给他们分出优先级,同样,机器学习中的 Attention 机制就是找这样一个权重值,从而更专注地聚焦在某些关键的信息上。
例如,对图图像,当人们注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上得注意力分布时不一样得,有些特别显眼得场景会率先吸引注意力,那是因为脑袋中对这类东西很敏感。而对于文本,我们大都是带着目的性去阅读的,阅读时是顺序读,但是在理解的过程中,我们时根据我们自带的目的性去理解和关注的。
所以,注意力模型应该与具体的目的或者任务相结合。这就是注意力机制的本质。
而机器学习中的 Attention 机制其实就是一些列注意力分配系数,也就是一些列权重参数罢了,Attention 机制说大了就是一句话:分配权重系数。
Attention 机制发家史与分类
Attention 机制最早从图像领域诞生,于 90 年代被提出。2014 年,Google Mind 团队发表论文《Recurrent Models of Visual Attention》,让注意力机制开始火了起来,这篇论文是在 RNN 模型上使用了 Attention 机制来进行图像分类。随后 2015 年 Bengio 的一篇论文《Neural Machine Translation by Jointly Learning to Align and Translate》首次将 Attention 机制应用到 NLP 领域,采用 seq2seq 加 Attention 的模型架构进行机器翻译任务。然后就是 Attention 机制被广泛应用在基于 RNN、CNN 等神经网络模型的各种 NLP 任务中了。直到 2017 年,Google 机器翻译团队发表《Attention is All You Need》,完全抛弃了 RNN 和 CNN 等网络结构,大量使用 self-attention 机制来学习文本表示,仅采用 attention 机制来进行机器翻译任务,也就是大名鼎鼎的 Transformer 模型,引起了超大的反响。2018 年,谷歌团队提出 BERT 算法,其中最重要的部分也是来自于 Transformer。
Transformer 分类:WIP。
NLP 领域简述
NLP 是 AI 的一个子领域,目前主流使用深度学习的方法,使用基于神经网络的低维稠密向量特征训练模型。通过深度学习,模型可以学习到文本信息的语法特征和语义特征。基于深度学习和神经网络的 NLP 研究经历了 CNN -> RNN -> Transformer 等特征提取器阶段。
狭义的 NLP 是使用计算机来完成以自然语言为载体的非结构化信息的各类信息处理任务,如:文本理解、分类、摘要、信息提取、知识问答、语法语义分析等;广义的 NLP 也包括自然语言的非数字形态(如:语音、图像等)与数字形态之间的双向转换(识别与合成)环节。
NLP 的发展:规则 -> 传统概率统计模型 -> 神经网络。
NLP 简要发展历程:1)N-gram;2)NNLM;3)NNLM 的优化版本:word2vec;4)CNN;5)CNN 变体:RNN;6)RNN N-M 结构,即 seq2seq 模型,也叫 Encoder-Decoder 模型;7)Attention 机制;8)纯 Attention:Transformer;9)BERT,GPT。
NLP 领域的 Attention
首先我们从 NLP 领域的 Attention 是如何诞生的讲起,Attention 在 NLP 领域的应用需求,是从 RNN 模型的确定开始的。
在 RNN 诞生并用于 NLP 之前,CNN 在 NLP 领域中在上下文窗口中挖掘语义信息非常有效,但 CNN 存在的一个重大问题是,无法对长距离上下文信息进行建模并保存序列信息,而且 CNN 参数量巨大,需要大量数据进行训练,在数据量不足的情况下,CNN 的效果会显著降低。
RNN 可以构建以下多种形式:
1)N-N:输入输出等长,可用于:视频每一帧的分类;
2)N-1:可用于:情感分析、视频分类;
3)1-N:可用于:根据给定类别或图像生成一段文字;
4)N-M:也叫 seq2seq 或 Encoder-Decoder,不要求输入输出等长,可用于:机器翻译、文本摘要、阅读理解、语音识别等;
其中 RNN N-M 结构的工作原理是:在编码层(一个 RNN)将输入词向量信息全部编码到一个上下文向量 $\mathtt{C}$ 里面,然后在解码层(另一个 RNN)将这个 $\mathtt{C}$ 作为输入进行解码,直到输出停止符为止。语义向量 $\mathtt{C}$ 可以有多种表达方法,最简单的方法就是把 Encoder 的最后一个隐状态赋值给 $\mathtt{C}$,拿到 $\mathtt{C}$ 之后就用另一个 RNN 网络对其进行解码,这部分的 RNN 就是 Decoder,这个 Decoder 可以与 Encoder 一样,也可以不一样,其中一种做法就是将 $\mathtt{C}$ 当做之前的初始状态 $\mathtt{h_0}$ 输入到 Decoder 中:
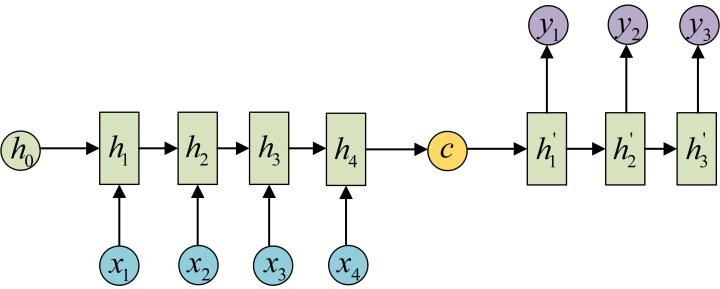
还有一种做法是将 $\mathtt{C}$ 当做每一步的输入:
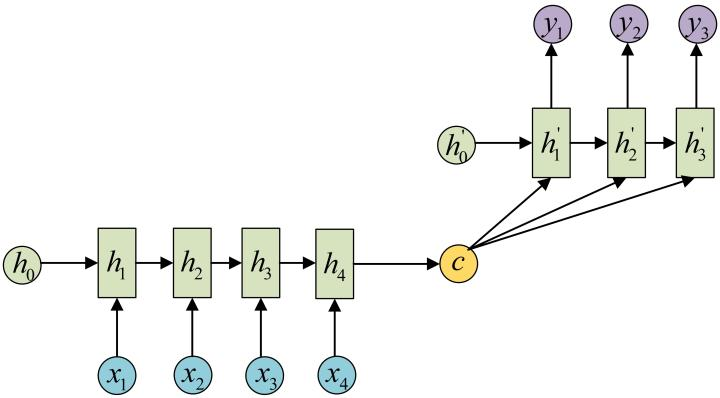
传统 Encoder-Decoder 框架的一个潜在问题是,有时 Encoder 会强制编码可能与目前任务不完全相关的信息,这个问题在输入过长或信息量过大的时候也会出现,选择性编码是不可能的。例如文本摘要任务可以被视为序列到序列的学习问题,其中输入时原始文本,输出时压缩文本,直观上看,让固定大小向量编码长文本中的全部信息是不切实际的。
总结来看,Encoder-Decoder 模型存在以下缺点:1)编码器需要将整个序列信息压缩进一个固定长度语义向量 $\mathtt{C}$ 里,会产生信息丢失,语义向量 $\mathtt{C}$ 无法完整表达整个序列的信息,而编码器和解码器唯一的联系就是 $\mathtt{C}$;2)先输入的内容携带的信息,会被后输入的信息稀释掉,或者被覆盖掉,序列越长这样的现象越严重,所以 $\mathtt{C}$ 的长度就成了限制模型性能的瓶颈。
在文本摘要和机器翻译等任务中,输入文本和输出文本之间存在某种对齐,这意味着每个 token 生成步都与输入文本的某个部分高度相关。这启发了注意力机制,该机制尝试用过让解码器回溯到输入序列来缓解上述问题。具体是在解码过程中,除了最后的隐藏状态和生成 token 以外,解码器还需要处理基于输入隐藏状态序列计算出的语境向量。
我们为什么需要注意力机制?简单来说,注意力机制就是给原始数据乘上一个权重,从而使得变换后的数据更利于学习。这个权重就是所谓的注意力系数。我们通过给 RNN 网络引入一个新的注意力模块,即一个新的神经网络,来负责学习怎样分配权重。
NLP 的 RNN 模型中的 Attention 机制通过 Decoder 每个时刻输入不同的 $\mathtt{C}$ 来解决这个问题,每个 $\mathtt{C}$ 会自动去选择与当前输出 y 最适合的上下文信息,其主要原理是通过计算 Encoder 第 $\mathtt{i}$ 阶段隐状态与 Encoder 各个阶段隐状态的相关性,通过 Softmax 归一化后 Decoder 第 $\mathtt{i}$ 阶段得到编码器各个阶段 $\mathtt{j}$ 的相对权重 $\mathtt{w_{ij}}$,然后计算 Encoder 所有阶段的隐状态与对应权重 $\mathtt{w_{ij}}$ 的加权和,即为 Decoder 第 $\mathtt{i}$ 阶段的输入 $\mathtt{C_i}$。
上述 Attention 机制是对基础 Encoder-Decoder 的改良,Attention 机制通过在每个时间输入不同的 $\mathtt{C}$ 来解决问题,如下图所示是一个带有 Attention 的 Decoder:
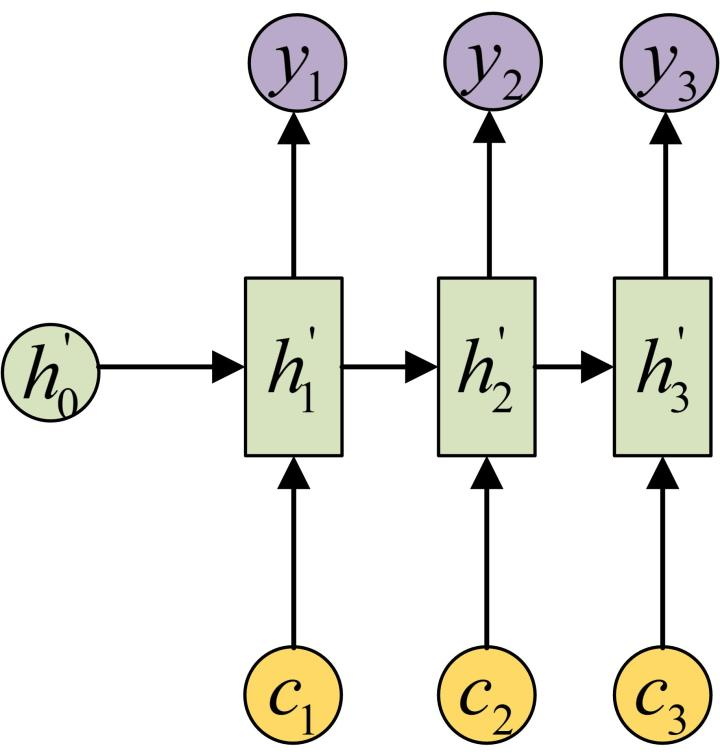
具体的工作机制就是,每个 C 会自动去选取与当前所要输出的 y 最合适的上下文信息。具体来说就是,我们用 $\mathtt{a_{ij}}$ 衡量 Encoder 中第 $\mathtt{j}$ 阶段的 $\mathtt{h_j}$ 和解码时第 $\mathtt{i}$ 阶段的相关性,最终 Decoder 中第 $\mathtt{i}$ 阶段的输入的上下文信息 $\mathtt{C_i}$ 就来自于所有 $\mathtt{h_j}$ 对 $\mathtt{a_{ij}}$ 的加权和。
Self-Attention 和 Attention 的区别在于,传统的 Attention 机制在一般任务的 Encoder-Decoder 模型种,输入 Source 和输出 Target 的内容是不一样的,比如中英机器翻译,Souce 是中文句子,Target 是对应翻译出来的英文句子。Q(Query)是 Target 的一个元素,Attention 机制就发生在 Q 和 Source 中的所有元素之间。简单来说就是 Attention 机制中的权重的计算需要 Target 来参与的。
而 Self-Attention,指的不是 Target 和 Source 之间的 Attention 机制,而是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,也可以理解为 Target=Source 这种特殊情况下的注意力机制。例如在 Transformer 中,在计算权重参数时将文字向量转成对应的 QKV 时,只需要在 Source 处进行对应的矩阵操作,用不到 Target 中的信息。
具体 Self-Attention 是怎样的一个计算过程呢?
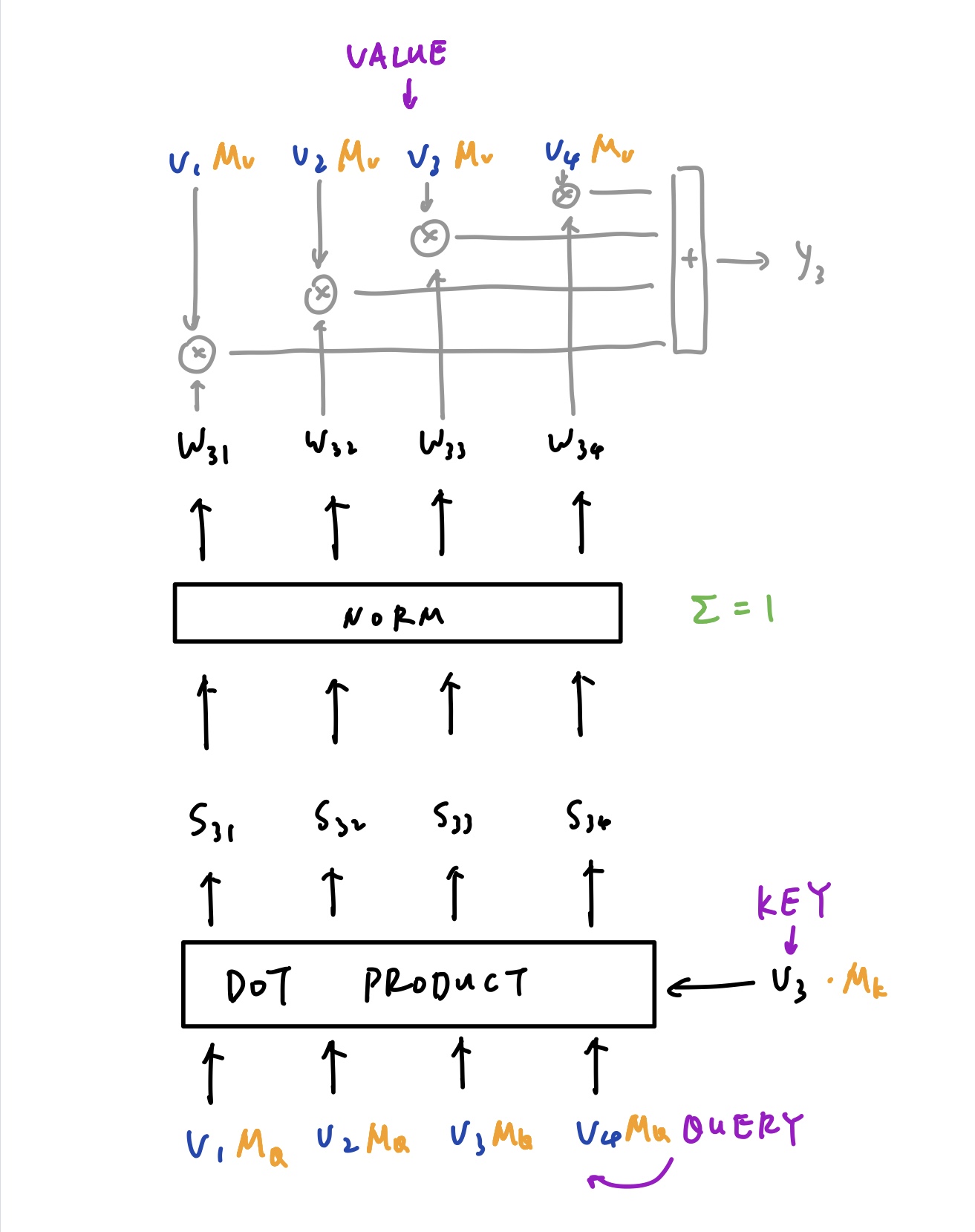
如上图所示, $\mathtt{V_3}$ 分别和所有的向量 $\mathtt{V_1}$ - $\mathtt{V_4}$ 相乘,得到一组 $\mathtt{S}$(Score),这组 $\mathtt{S}$ 经过归一化之后即得到了权重 $\mathtt{W}$,$\mathtt{W}$ 再分别和 $\mathtt{V_1}$ - $\mathtt{V_4}$ 相乘再相加,即得到了 $\mathtt{V_3}$ 所对应的 $\mathtt{Y_3}$。
$\mathtt{V_3}$ 被称为 K,上下两组 $\mathtt{V_1}$ - $\mathtt{V_4}$ 被称为 Q 和 V。
但是很明显这样的过程是没有”学习“的,因此需要引入矩阵 $\mathtt{M_q}$,$\mathtt{M_k}$ 以及 $\mathtt{M_v}$ 分别来与 $\mathtt{Q}$,$\mathtt{K}$ 和 $\mathtt{V}$ 相乘,其实就是三个 Linear 层,这样这些参数就可以随着训练更新了。
当 Q、K、V 相同时,即为 Self-Attention。
Transformer&BERT&GPT
WIP
CV 领域的 Attention:ViT
Transformer 结构目前已经是 NLP 领域大部分模型所会采用的结构,得益于其在 NLP 领域的成功,这种 Self-Attention 结构也越来越多地被尝试应用于 CV 领域,主要有两种形式:1)Self-Attention 和 CNN 相结合;2)完全取代卷积操作。后者从理论上是高效的,但目前还没有和现在的 GPU 硬件等做很好的优化,所以在大图像的 CV 任务里面,像 ResNet 架构的网络目前还是 SOTA。
ViT 模型是先将 Image 拆分成 Patches,然后进行 Patch Embedding,每个 Patch 的处理其实就是相当于 NLP 中的一个 token。
论文表示,当 ViT 用“中等大小的数据集”(中等指的是数据集中的数据量)训练时,准确率比相同规模的 ResNet 模型稍低,作者认为是因为 Transformer 缺乏 CNN 固有的 inductive biases(不懂),例如 平移不变性 translation equivariance(不懂)和局部性,因此无法很好地归纳数据量较小的数据集。然而当 ViT 在数据量充足(14M-300M images)的数据集上 Pretrained,然后迁移到较小的数据集上时,效果 SOTA。Transformer 的核心 Self-attention 的优势不像卷积那样有固定且有限的感受野,但它可以获得 Long-range 信息,但训练的难度就比 CNN 要稍大一些。Why?
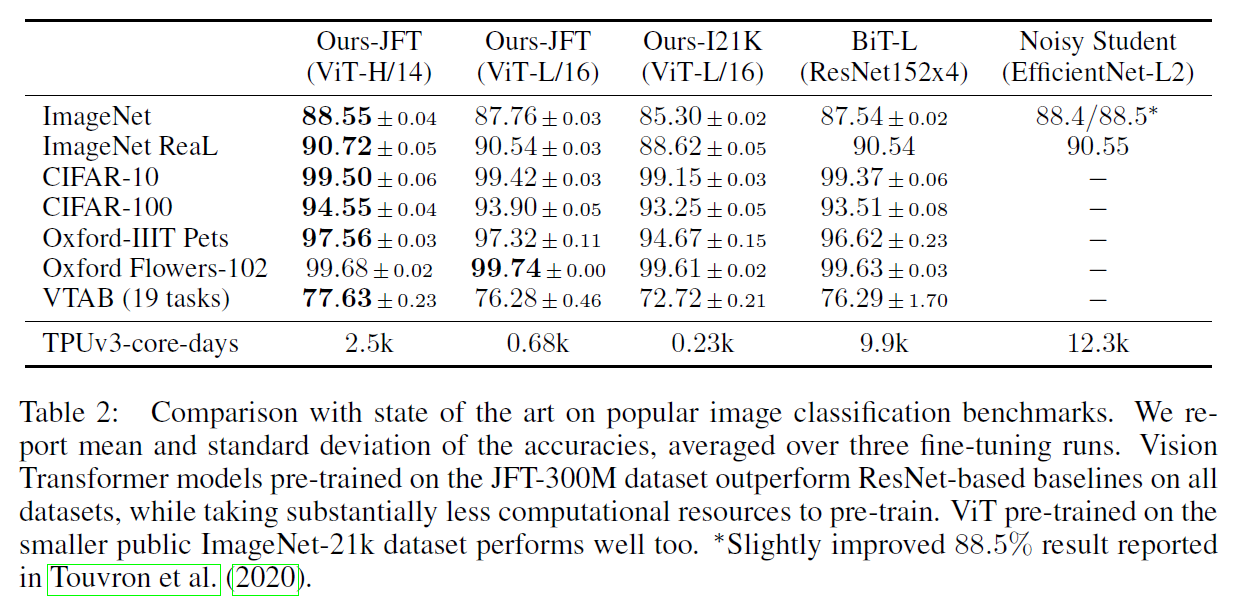
如上图,比如 ViT 在 Google 私有的 300M JFT 数据集上 Pretrain 后,在 ImageNet 上的最好 Top-1 Acc 可以达到 88.75%,达到 SOTA 水平。那 ViT 至少需要多大的数据量来 Pretrain 才能和 CNN 旗鼓相当呢?论文通过实验给出的结论是 Pretrain 数据量达到 100M 时才能显示 ViT 的优势,可见Transformer 的一个重要特性就是 Scalability,也就是当模型参数和数据量提升时,性能会持续提升:

JFT-300 这个数据集是私有的,即外部研究者无法复现实验,而且,更搞笑的是,ViT 作者明确表示:that transformers do not generalize well when trained on insufficient amounts of data,一下子为自己撇清了所有责任,所以后来 DeiT 的研究就是想提出一个训练方案,使其只在 ImageNet 上进行 Pretrain,就能产生一个有竞争力的无卷积 transformer。
那为什么 Transformer 可以用来做 CV?将图片切割成 Patch 后,不会将特征也切开而影响判断吗?论文给出的解释是,他们认为 Self-Attention 让 ViT 能够整合不同 Patch 之间的信息。为了分析这个结论,他们基于 Transformer 过程中产生的 Attention Weight 计算了每一个 Head 对于其他 Head 的 Attention Distance,这个 Attention Distance 类似于 CNN 中的 Receptive Field,“感受野”简单来说就是每一张 Feature Map 在原始图片上能够被启动的区域,并给出了下图:
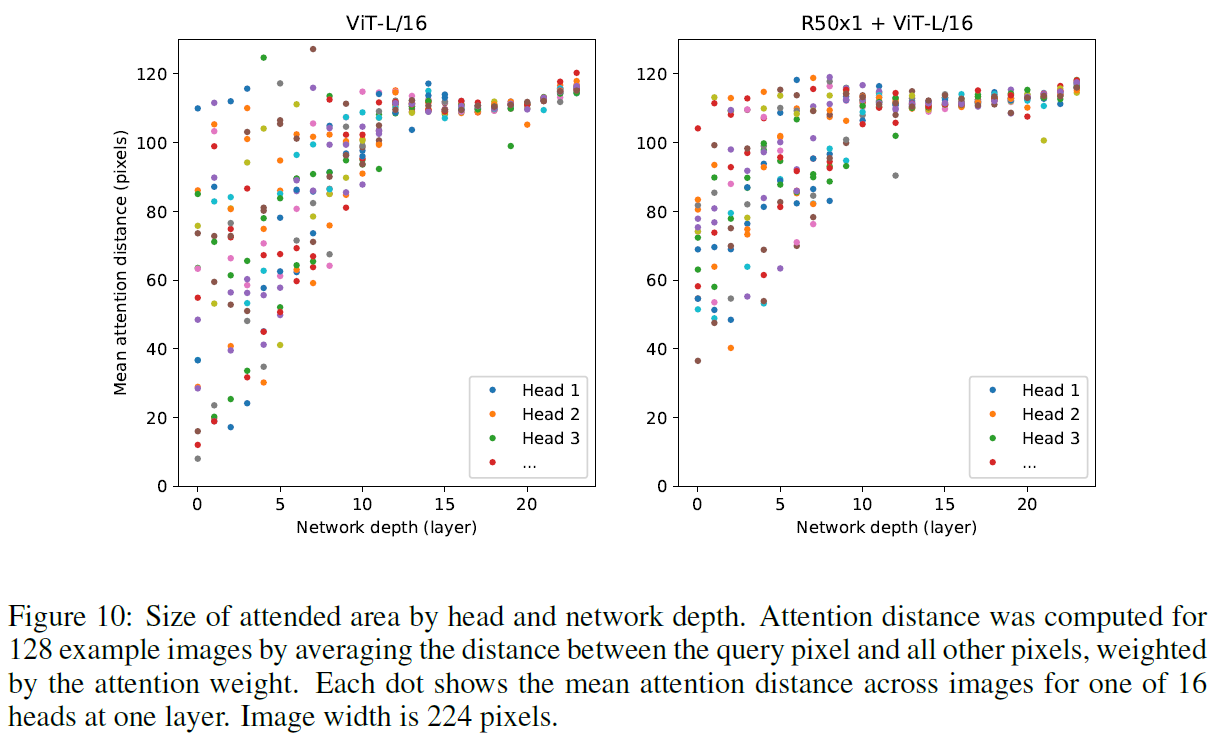
上图表示 Mean attention distance between 16 heads,如果将 Attention Distance 理解成 Receptive Field,可以看到有些 Head 在训练一开始就能 Attend 到原始图片中大多的区块,而且随着 Layer 越深,越多的 Head 就能 Attend 到更多的区域,证明了 Transformer 所产生的信息确实是有考虑到其他许多的 Patch,是 Global 的。
所以,既然这样,按道理说如果把 Patch Size 切得更小,Patch 之间就能考虑到更细节的信息,但是 Patch 越小,Input 的 shape 就会越大,就会花费更多的 pretrain 时间。论文中提到的的结果表明,Patch Size 也不是越小性能越好。
在 ViT 之前,Self-Attention 应用到图像领域有几种方式:1)全局的,也就是每个像素都需要参与当前像素 Attention 的计算;2)局部的,也就是仅一定邻域的像素需要参与当前像素 Attention 的计算;3)Sparse Transformers(不懂);4)在不同大小的 blocks 上使用 Attention(不懂);5)和 CNN 相结合。而 ViT 主要是尝试将 Global Self-Attention 应用到整幅图像中。
ViT 架构
以下详细解剖 ViT 模型的细节,首先,原版的 Transformer 架构如下:
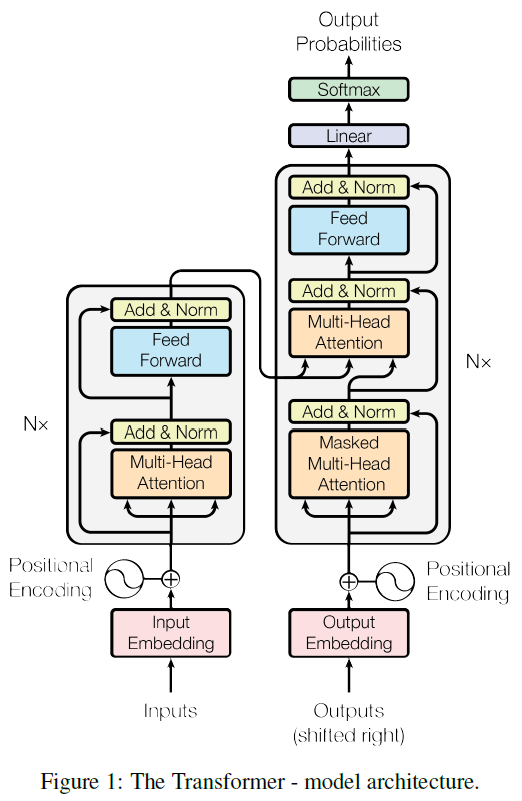
ViT 在设计时也尽可能保持了原版 Transformer 的样子:
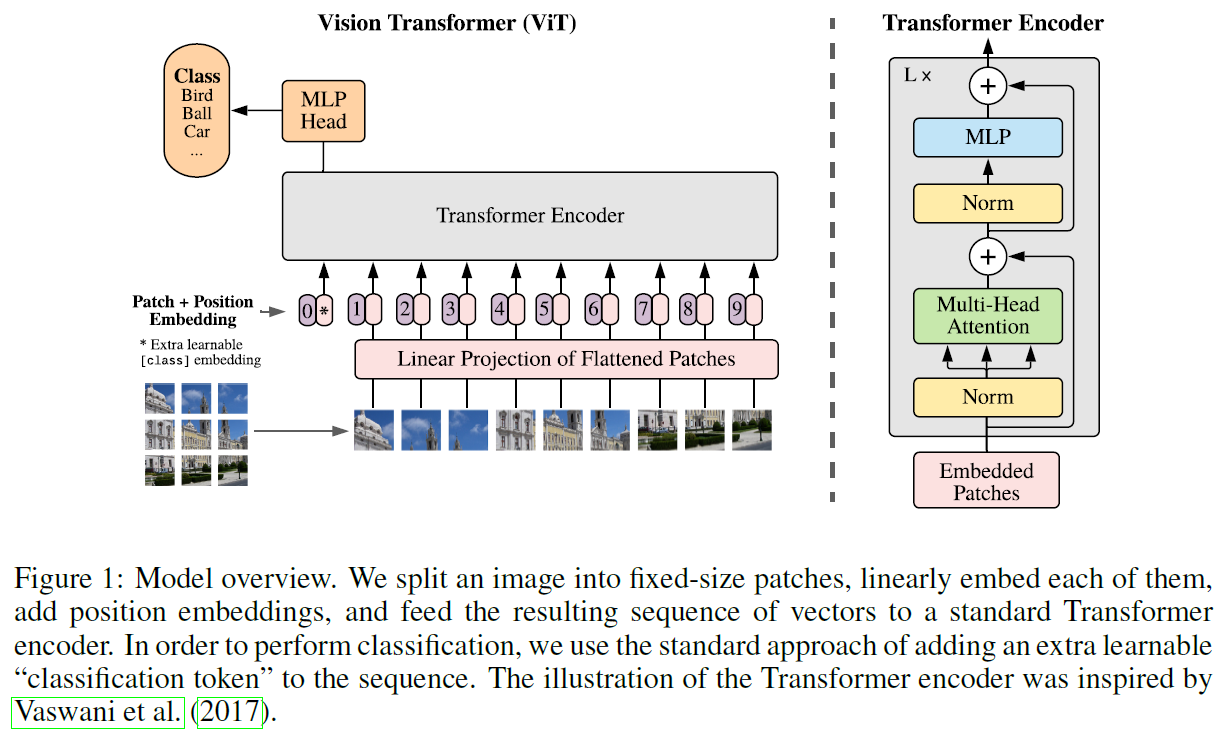
原版的 Transformer 的输入是一个被 Embedded 之后的 1D 序列,序列的长度就是句子的单词(token)个数。所以要想应用于图像,那就可以先将整幅图像(3x256x256)拆分成 64 个 Patch,每个 Patch(3x32x32)就相当于 NLP 中语句的一个 token,然后将每个 Patch 进行 Flatten 操作变成 1x3072,由于 3072 还是太大,于是再进行 Linear Projection 操作将其变成 1024。至此,ViT 的第一步操作”Patch Embedding + Flatten + Linear Projection“的整个数据 shape 变化过程为:
[BatchSize, 3, 256, 256] -> [BatchSize, 64, (3, 32, 32)] -> [BatchSize, 64, 3072] -> [BatchSize, 64, 1024]
为了进行分类任务,在上述结果的基础上,ViT 还 Concat 了一个 CLS token,也就是原来有 64 个 token(因为将原图拆分成了 64 个 Patch,一个 Patch 被视为一个 token),现在 Concat 一个 CLS token 变成 65 个 token:[BatchSize, 65, 1024]。这个 CLS token 代表的是原始图片的整张信息,就像 BERT 中的 CLS token 一样,当它和其它 Embedding 一起被丢进 Transformer Encoder 后,它自身对应的 Output 就代表了整个句子的表示,所以 ViT 也可以用这个方法来进行图像分类任务。
另外,在输入 Transformer Encoder 之前,还需要进行 Position Embedding。是因为在 RNN 中,对句子的处理是一个个 word 按顺序输入的,但在 Transformer 中,输入句子的所有 word 是同时处理的,没有考虑词的排序和位置信息,Position Embedding 就是为了让每个 Patch 都能带有其在原图的位置信息,具体操作就是让每个 token 加上一个随机数,也就是将 Patch Embeddings 和 Positional Embedding 相加,输出 shape:[BatchSize, 65, 1024]。在 Transformer 原文中提供了两种方法来实现具有位置信息的 Encoding:1)通过训练来学习 Positional Encoding 向量;2)使用公式来计算 Positional Encoding 向量。原版 Transformer 中使用的是第二种方法,因为作者对比发现两种方法效果差不多,但是第二种不需要训练参数,而 ViT 种使用的是第一种?
对于 Transformer Encoder 部分,ViT 的原文没有作详细介绍,但从 ViT 结构图中可见,Transformer Encoder
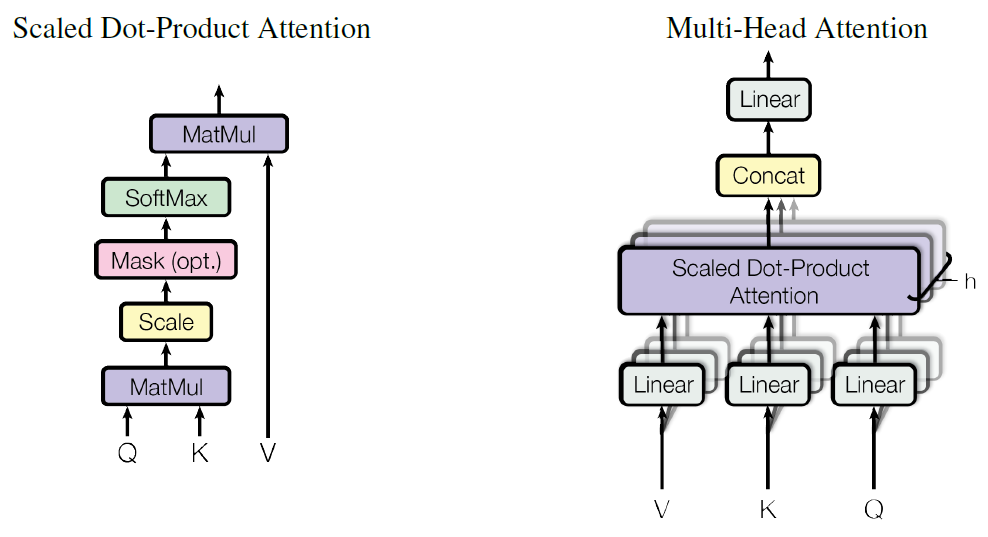
所谓的 Multi-Head,就是定义 h 个 Attention Heads,也就是采用 h 个Self-Attention 应用在输入 Sequence 上。具体操作就是将 Sequence 拆分成 h 个 size 为 Nxd 的 Sequence,这里 D=hd,h 个不同的 Heads 得到的输出 Concat 在一起,然后通过线性变换得到最终的输出,size 也是 NxD ,在 transformer 中,MSA 后跟一个 FFN(Feed-Forward Network),这个 FFN 包含两个 FC 层,第一个 FC 层将特征从维度 D 变换成 4D,后一个 FC 层将特征从 4D 恢复成 D,中间的非线性激活函数采用 GeLU,其实这就是一个 MLP。
Refer:
[1] http://blog.wangluyuan.cc/2021/03/06/intro-to-vit/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号