深度学习之目标检测
最近刚刚开始系统了解 Object Detection,欢迎随时 Email 交流。
前言
目标检测网络的任务是要预测出各个物体的边框(Bounding Boxes)和每个物体的分类概率(Confidence Score)。

目前 Object Detection 网络一般可以分为两种:1)基于候选区域的 Two-Stage 的检测框架(比如 R-CNN 系列);2)基于回归的 One-Stage 的检测框架(比如 YOLO,SSD)。总的来说,Two-Stage 精度高,One-Stage 速度快。
One-Stage Methods
Two-stage Methods 往往需要先生成候选框(Region Proposals),然后再对每个候选框进行分类和修正位置,所以需要多次运行检测和分类的流程;而 One-stage Methods 仅仅需要送入网络一次就可以预测出所有的边界框。
Predictions on a grid
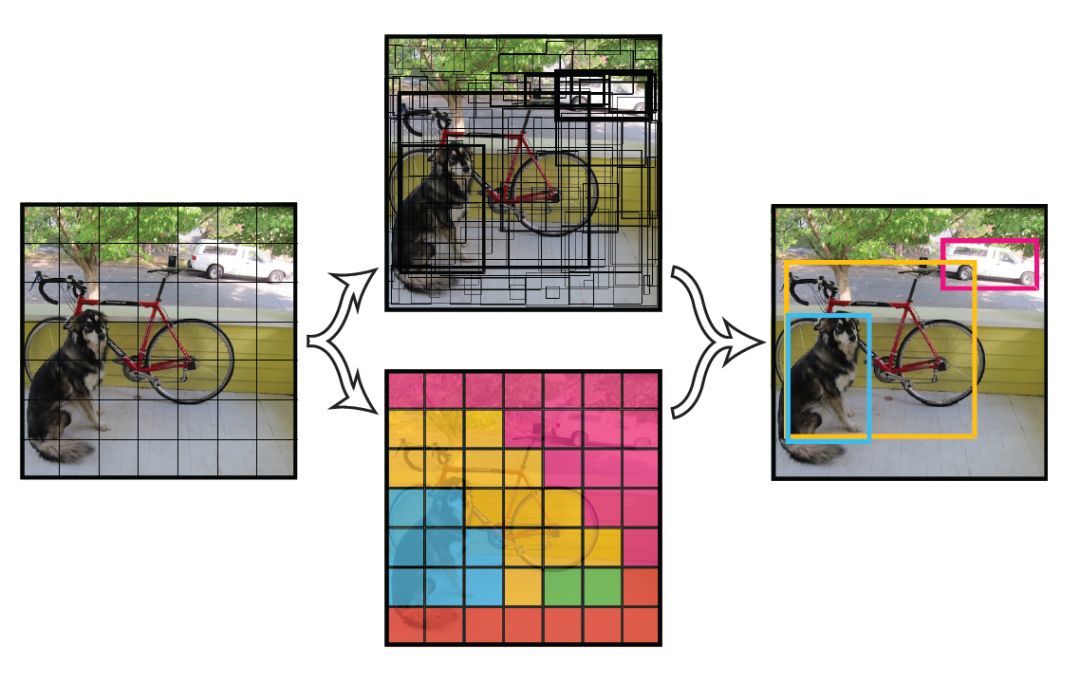
基于网格预测方法的思想就是将输入图像分成例如 $\mathtt{7 \ast 7}$ 个格子,物体的中心落入哪个格子,哪个格子就负责预测该物体的种类,大小,和位置与格子中心的偏移量。
为了理解图像中存在什么事物,我们会将图像输入到一个标准的卷积神经网络以构建出图像的丰富特征表示,通常我们将这个网络称为「Backbone」网络,然后将「Backbone」网络的后几层移除,使其输出多个特征图,这些特征图以更低的空间分辨率描述了原图像的不同特性。
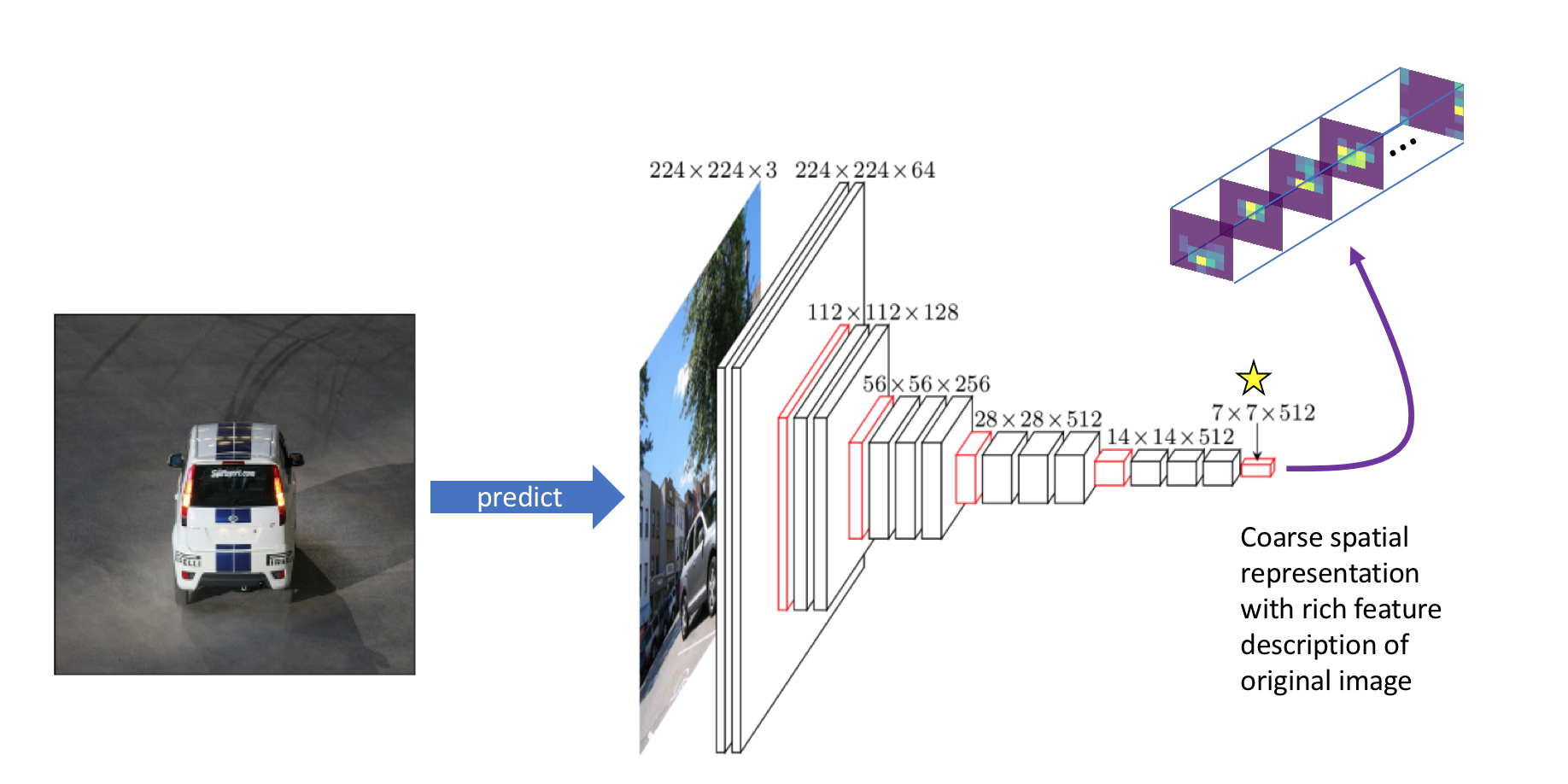
现在我们得到 $\mathtt{512}$ 个大小为 $\mathtt{7 \ast 7}$ 的特征图,现在我们通过卷积操作,将 $\mathtt{512}$ 个特征图融合成一个输出,被激活的部分就是被检测到的物体。

如果输入图像包含多个目标,那么在我们的网格上应该有多个激活,表示每个激活区域中都有一个目标,如下图所示。

然而,通过「Backbone」网络直接输出的激活区域往往不能很完整地把目标包括在内,为此我们需要额外定义以下三项:
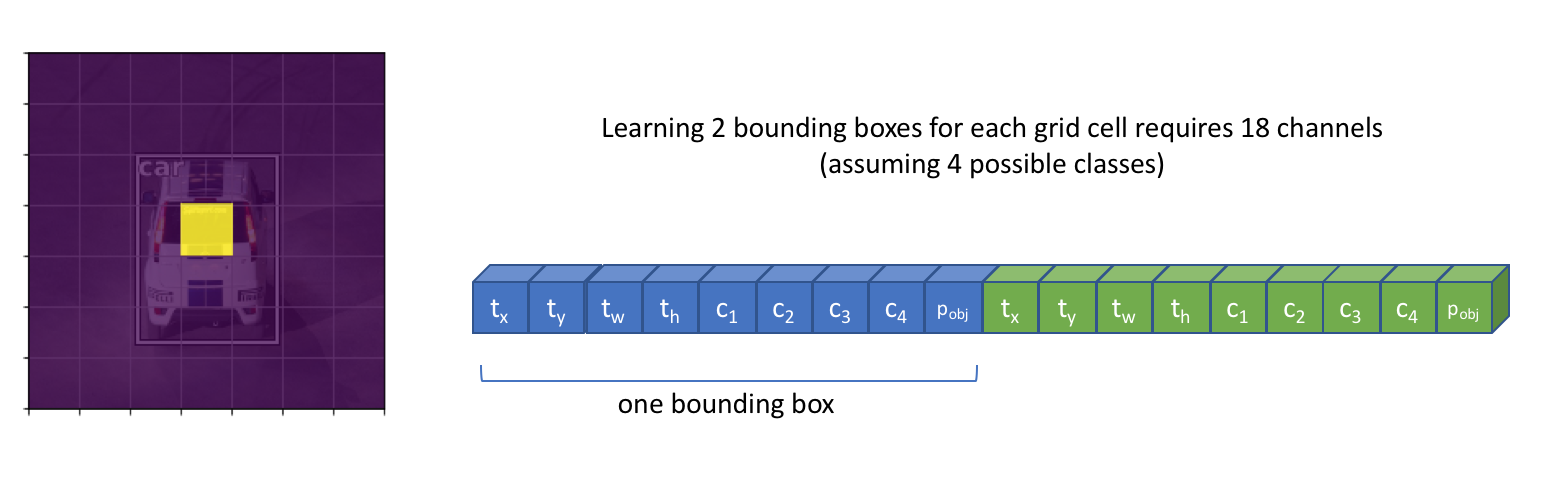
1. $\mathtt{P_{obj}}$: 网格中包含物体的概率;
2. $\mathtt{C_1, C_2,...,C_C}$: 网格中物体类别的分类概率;
3. $\mathtt{t_x, t_y, t_w, t_h}$: Bounding Box 坐标;
所以,在对应的每一个网格 (例如输出的 Feature Map 的大小为 $\mathtt{7 \ast 7}$,即有 $\mathtt{49}$ 个网格),我们输出 $\mathtt{5+C}$ 个 Channels 来代表**单个**网格的 Bounding Box。

燃鹅,有一些网格可能会同时包含多个物体,此时每个网格输出 $\mathtt{B(5+C)}$ 个 Channels,其中 B 代表一个网格的位置**能够**预测 B 个物体。
所以,对于整个框架,输入一张图像,输出的 Bounding Box 个数是固定的,$\mathtt{N \ast N \ast B}$ 个,而最后我们对 $\mathtt{P_{obj}}$ 做阈值过滤,使得网络最后输出几个置信度大的 Bounding Box,虽然这样可以过滤掉大多数的 Bounding Box,但是仍然可能存在一个物体同时有多个高置信度 Bounding Box 的情况,因此我们需要一个方法来移除冗余的目标预测,以便每个目标都只用一个 Bounding Box 来描述,**Non-maximum suppression** 就是干这个的。
综上,这就是**基于网格预测方法**。
下面介绍的 **YOLO** 和 **SSD** 都是基于 **Prediction on Grid** 这种思想的。
YOLO - YOLO v1
YOLO 模型最早是由 Joseph Redmon 等人在 2015 年发布的。最早的 YOLO 网络使用了一个经过修改的 GoogLeNet 作为骨干网络,之后 Redmond 又创建了一个名为 DarkNet-19 的新模型,而他最新的论文又引入了一个更大的新模型 DarkNet-53,具有更优的性能表现。
YOLO 的检测思想不同于 R-CNN 系列,R-CNN 系列方法需要先用 「Proposal Methods」 来产生许多 Bounding Boxes,然后用一个 「Classifier」 来对这些 Bounding Boxes 进行分类,分类完成后用 「Post-Processing」 来精修微调和删除重复的 Bounding Boxes,而 YOLO 则是将目标检测作为一个简单的回归问题。
YOLO 相比于以往传统的目标检测网络,优势在于: **1) YOLO is extremely fast**;**2) YOLO makes less background errors**;**3) YOLO learns generalizable representations of objects**。
而 YOLO 的缺点在于**定位精度不高**,尤其是**小物体**。
YOLO 把检测任务作为 **Regression Problem** 来考虑,模型把一张输入图像最终分成了 $\mathtt{7 \times 7}$ 个 「Grid」,每个 「Grid」 只能预测 B 个 Bounding Boxes,所以网络的输出是一个大小为 $\mathtt{7 \times 7 \times (B \ast 5 + C)}$ 的 Tensor。

YOLO 的设计简单,是基于 **Prediction on Grid** 思想搭建的,但是这种 「Grid Design」 的网络设计方式在某些方面限制了 YOLO 的性能,因为 YOLO v1 中一个 「Grid」 最多只能预测**两个 Bounding Boxes** 和**一个类**,所以使得距离相近物体的识别能力比较差。
**YOLO v1 网络设计:**
YOLO v1 的输入固定为 $\mathtt{448 \times 448}$,输出是一个 $\mathtt{7 \times 7 \times 30}$ 的 Tensor。
其中 $\mathtt{30}$ 包含 $\mathtt{2}$ 个 Bounding Boxes 的位置共 $\mathtt{8}$ 个数,$\mathtt{2}$ 个 Bounding Boxes 的置信度和 $\mathtt{20}$ 个类别的分类概率。
其中 $\mathtt{20}$ 个类别的分类概率为条件概率,记为 $\mathtt{P(C_i \mid object)}$,表示如果存在一个物体的情况下,这个物体是 $\mathtt{C_i}$ 类的概率。
其中 $\mathtt{2}$ 个 Bounding Boxes 的置信度等于 Bounding Box 内**存在对象的概率(区别于之前的条件概率)**乘以预测 Bounding Box 和真实 Bounding Box 的 IoU:$\mathtt{confidence = P(object) \ast IOU_{pred}^{truth}}$
**YOLO v1 训练细节:**
YOLO - YOLO v2:
**Refers**
<https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088>
<https://pjreddie.com/darknet/yolov2/>
SSD
SSD 模型也发表于 2015 年 (Wei Liu et al.),就在 YOLO 模型发表后不久,并且也在后续论文中得到了改进。
RetinaNet
WIP
Refers:
<https://www.jiqizhixin.com/articles/2018-08-06-2>
<https://www.jeremyjordan.me/object-detection-one-stage/>
<https://wyf0912.github.io/2018/04/04/YOLO-v1-v3/>
<https://cloud.tencent.com/developer/article/1161951>
<https://shenxiaohai.me/2018/12/05/paper-yolo-v1/>
<https://zhuanlan.zhihu.com/p/46691043>
Two-Stage Methods
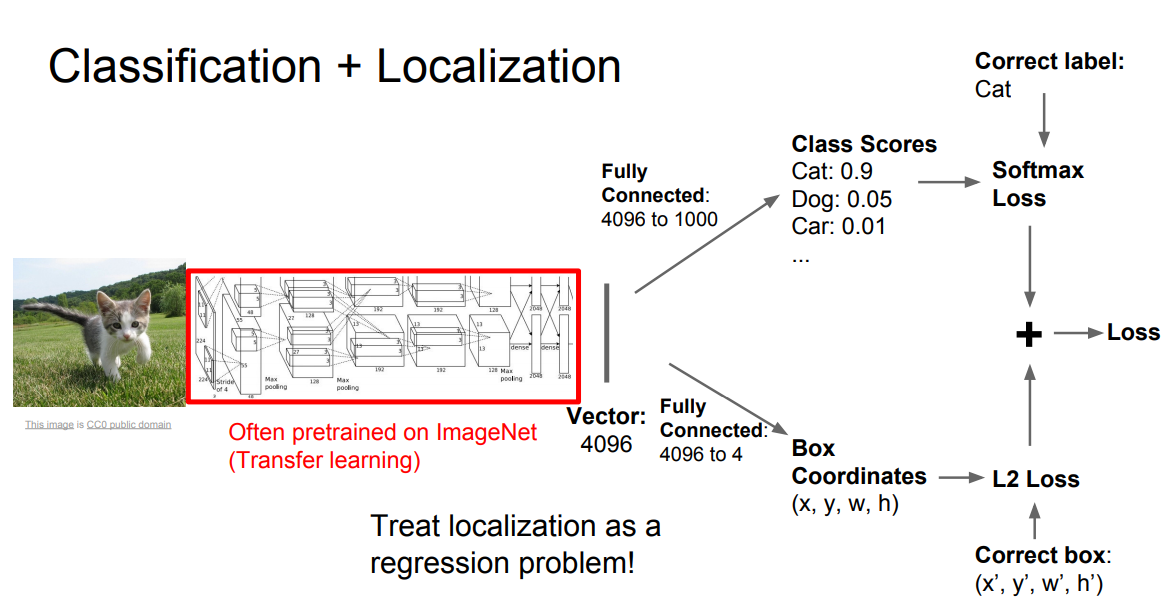
物体识别网络诞生的初衷是既要把图中的物体识别出来,又要用方框框出它的位置,其实就是图像分类加定位。
RCNN
wip
SppNet
wip
Fast-RCNN
wip
Faster-RCNN
wip
Mask-RCNN
wip
Refers
<https://imlogm.github.io/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/rcnn/>
<https://www.cnblogs.com/skyfsm/p/6806246.html>
<https://zhuanlan.zhihu.com/p/23006190>
<http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf>
Miscellaneous
<http://zoey4ai.com/2018/05/12/deep-learning-object-detection/>
<https://arxiv.org/pdf/1809.02165v1.pdf>
<https://arxiv.org/pdf/1807.05511.pdf>
<https://zhuanlan.zhihu.com/p/33277354>
<https://www.jiqizhixin.com/articles/2018-08-06-2>
<https://medium.com/@nikasa1889/the-modern-history-of-object-recognition-infographic-aea18517c318>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号