深度学习中分割网络的发展史
本文主要总结整理一些「图像分割」的深度卷积神经网络和我遇到的一些问题。
前言
以下总结按照时间先后顺序来介绍深度卷积神经网络在图像分割领域的发展。其中本人用得最多的是基于 UNet 的框架结构,尤其在医学图像领域,UNet 的一些列衍生变形结构可以取得很不错的效果。关于 UNet 系列的代码以及其效果对比,欢迎参见本人的 Github Repo:UNet Family。
分割网络发展史
(1)传统方法:
- 基于统计;
- 基于几何
(2)基于 CNN:
- 基于候选区域;
- 基于全卷积:
1)基于全卷积的对称语义分割模型:FCN,SegNet,UNet;
2)基于全卷积的扩张卷积语义分割模型:DeepLab,RefineNet;
3)基于全卷积的残差网络语义分割模型:PSPNet;
4)基于全卷积的GAN语义分割模型;
- 弱监督学习
FCN (2014 Nov 14)
用 CNN 来进行图像分割的开山之作是 Jonathan Long 大神发表的 FCN [Arxiv Link],大概思路是把神经网络最后的全连接层换成卷积层,如下图所示:


可以看出,在 16 倍还原和 8 倍还原时,能够看到更好的细节,32 倍还原出来的图,在边缘分割和识别上,虽然大致的意思都出来了,但细节部分真的很粗糙,甚至无法看出物体形状。是因为较浅的卷积层(靠前的)的感受域小,学习感知细节部分的能力强;较深的隐藏层 (靠后的),感受域大,适合学习较为整体的、相对更宏观一些的特征。所以在较深的卷积层上进行反卷积还原,自然会丢失很多细节特征。
FCN 把 CNN 后面的 classifier 换成 decoder,开启了图像分割 encoder-decoder 结构的新纪元。虽然 FCN 提供了一个很牛 x 的思路,但是也是有缺点的。例如:精度不够,对细节不敏感,没有充分考虑像素与像素之间的关系,忽略空间的一致性等。于是更多牛 x 的 ideas 出现了,例如:Dilated Convolution 解决精度和细节问题;CRF 解决像素间关系问题;UNet 等。以下是 FCN 衍生出来的一些网络,截止 22 Apr 2017:
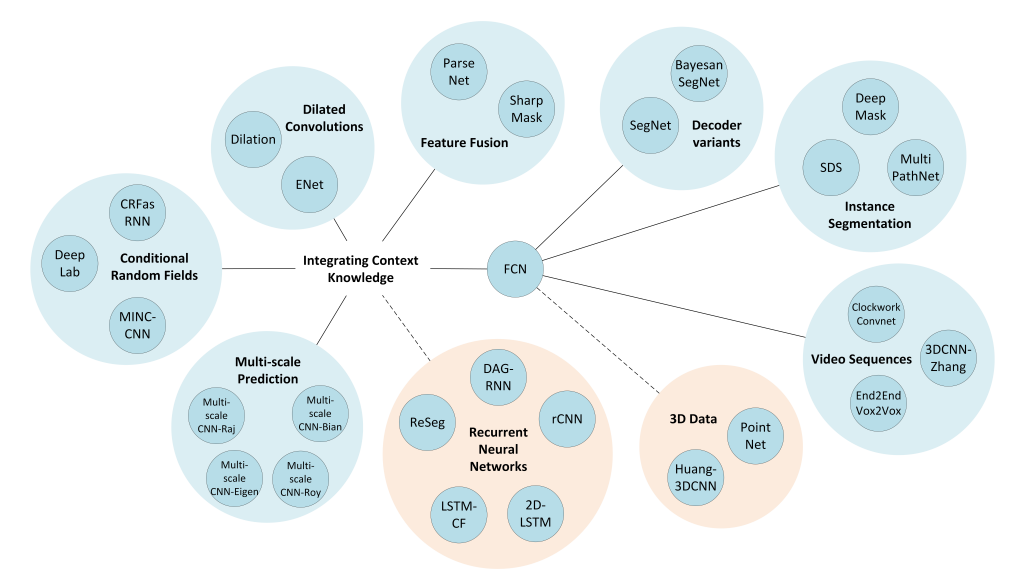
DeepLab (2014 Dec 22)
DeepLab [Arxiv Link] 相比之前的网络,DeepLab v1 加入了 Atrous Algorithm(也就是后来的空洞卷积)和 CRF;随后 v2 加入了 ASPP(Atrous Spatial Pyramid Pooling);v3 引入 Resnet Block 而舍弃 CRF。
UNet (2015 May 18)
UNet [Arxiv Link] 是 FCN 的一种改进和发展,其某种意义上来说算是在一定程度上解决分割中 pooling 所带来的问题,通过扩大网络解码器的容量来改进了全卷积网络结构,并给编码和解码模块添加了收缩路径(contracting path)来实现更精准的像素边界定位。UNet 是医疗图像领域里面的大明星,我觉得这是目前医学图像领域比较简单有效的解决方案。
UNet 是我个人使用得最多的网络结构,我个人是从事医学图像方面的工作,为什么 UNet 适用于医学图像?以下谈谈我对 UNet 这种框架设计的体会和理解:
鉴于现在 UNet 已经被衍生出许多变形,我们可以理解 UNet 为一种网络结构类型的统称,其实这种设计最大的两个特点就是 U 型结构和 skip-connection。
UNet 的工作流程就是:encoder 下采样 4 次,下采样 16 倍,然后 decoder 再将高级语义特征图恢复到原图的分辨率,同时,上采样的时候在同一个 stage 对 encoder 和 decoder 采用 skip-connection,使得最后得到的 feature maps 融合了更多的 low-level features,也使得不同 scale 的 feature 得到了的融合,从而可以进行多尺度预测。所以 UNet 能够结合底层和高层的信息,经过多次下采样后的低分辨率信息。能够提供分割目标在整个图像中上下文语义信息,可理解为目标和它的环境之间关系的特征。这个特征有助于物体的类别判断(所以分类问题通常只需要低分辨率/深层信息,不涉及多尺度融合),经过 concatenate 操作从 encoder 直接传递到同高度 decoder 上的高分辨率信息。能够为分割提供更加精细的特征,如梯度等。
医学图像有什么特点?1)医学图像边界模糊、梯度复杂,需要较多的高分辨率信息,高分辨率用于精准分割;2)人体内部结构相对固定,分割目标在人体图像中的分布很具有规律,语义简单明确,低分辨率信息能够提供这一信息,用于目标物体的识别;
...
为什么 UNet 适用于少量数据的医学图像?因为医学图像数据一般较少,底层的特征其实很重要。
Refer set of UNet:
<https://zhuanlan.zhihu.com/p/53521053>,<https://github.com/ShawnBIT/UNet-family>,<https://github.com/ozan-oktay/Attention-Gated-Networks>,<https://zhuanlan.zhihu.com/p/44958351>,<https://www.zhihu.com/question/269914775>,<https://zhuanlan.zhihu.com/p/50539347>,<https://openreview.net/pdf?id=Skft7cijM>,<https://arxiv.org/pdf/1903.11249.pdf>,<https://arxiv.org/pdf/1902.04049.pdf>,<https://arxiv.org/pdf/1902.08994.pdf>,<https://arxiv.org/pdf/1903.02740.pdf>,<https://arxiv.org/pdf/1803.01207.pdf>,<https://arxiv.org/pdf/1801.05746.pdf>,<https://lmb.informatik.uni-freiburg.de/Publications/2016/CABR16/cicek16miccai.pdf>,<https://arxiv.org/pdf/1904.01169.pdf>;
DeepMask (2015 Sept 1)
DeepMask [Arxiv Link]。
SegNet (2015 Nov 2)
SegNet [Arxiv Link] 和 UNet 大同小异,他们的区别在于,SegNet 没有直接融合不同尺度的层的信息,为了解决为止信息丢失的问题,SegNet 使用了带有坐标(index)的池化,本质上还是为了解决分割网络中的 pooling 灾难。SegNet 在 Max pooling 时,选择最大像素的同时,记录下该像素在 Feature map 的位置。在反池化的时候,根据记录的坐标,把最大值复原到原来对应的位置,其他的位置补零。后面的卷积可以把 0 的元素给填上。这样一来,就解决了由于多次池化造成的位置信息的丢失。
Dilated Convolution (2015 Nov 23)
(1)什么是 Dilated Convolution?我们为什么需要 Dilated Convolution?
Dilated Convolution,a.k.a.「atrous convolution」,「algorithme à trous」,「hole algorithm」,字面理解就是普通的卷积中注入空洞。空洞卷积诞生于图像分割领域,图像分割有两个关键步骤:池化操作降低图像尺度增大感受野,upsampling 或 deconvolution 操作扩大还原图像尺寸。这当中的问题在于,虽然图像经过 upsampling 操作恢复了原有的大小,但是很多细节还是因为池化操作而丢失了。理论上来讲,如果一个网络有四个 pooling layers,则任何小于 2^4=16 pixels 的信息将无法重建。显然池化操作下的 Segmentation Networks 会非常不利于涉及密集预测和细小物体的图像场景解析任务,而且会影响目标之间关系的理解。其实一直很多人都认为池化这个操作很愚蠢,存在明显的缺陷,但是貌似又离不开,这也是一直以来 Semantic Segmentation 问题的瓶颈所在。So,Dilated Convolution 横空出世。
我最初开始关注了解 Dilated Convolution,是因为自己也遇到了类似的问题。在 X 光胸片上用 Segmentation 来做病灶的定位,在定位结节的时候明显感觉网络力不从心。结节在 X 光胸片中通常是一个非常小的圆形病灶,然后我就开始怀疑是不是因为网络下采样太多次从而丢失了很多小的细节,影响模型对小目标的识别。我试了很多 encoder-decoder 分割网络,都是出现同样的短板,哪怕是像 UNet 这样的网络设计,在 decoding 上采样的时候融合了 encoder 那边的信息,甚至是 encoder 也改成能更加有效兼顾浅层和深层语义的 ResNet skip-connection 短路连接,提升的效果也只是有限,其最大的根源还是在于池化上。
所以,我们可以用空洞卷积来代替原来的池化。其优点是:
The presented module uses dilated convolutions to systematically aggregate multiscale contextual information without losing resolution.
- Fisher Yu, Multi-scale context aggregation by dilated convolutions
也就是使模型能够很好地聚合上下文信息,使模型具备更加强大的多尺度特征提取能力。
关于更多 Dilated Convolution 的详细信息,可以看看以下的论文:
[Multi-Scale Context Aggregation by Dilated Convolutions]、
[Dilated Residual Networks]、
[Rethinking Atrous Convolution for Semantic Image Segmentation]、
[Understanding Convolution for Semantic Segmentation]
(2)那 Dilated Convolution 就没有缺点吗?
Dilated Convolution 有两个主要的缺陷:
1)Gridding Effect,也就是 checker-board artifacts:
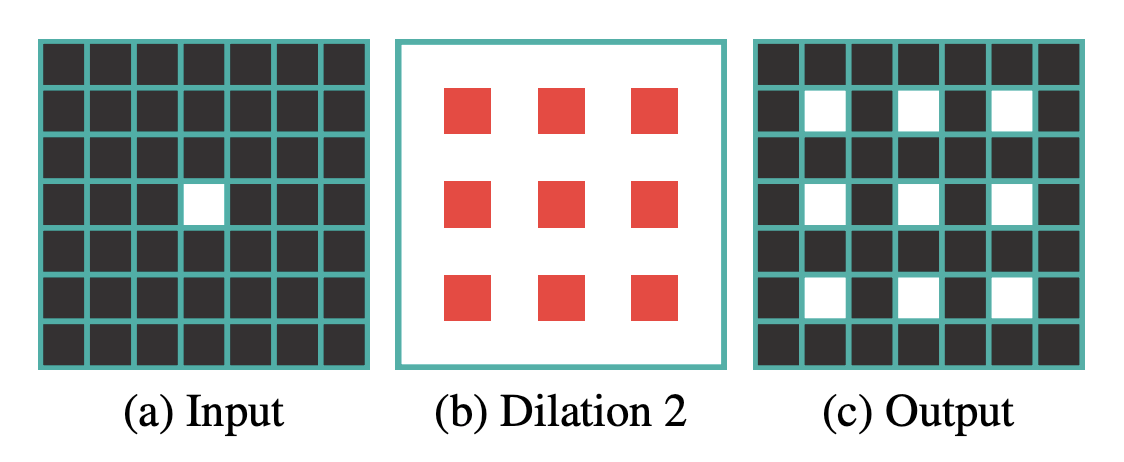
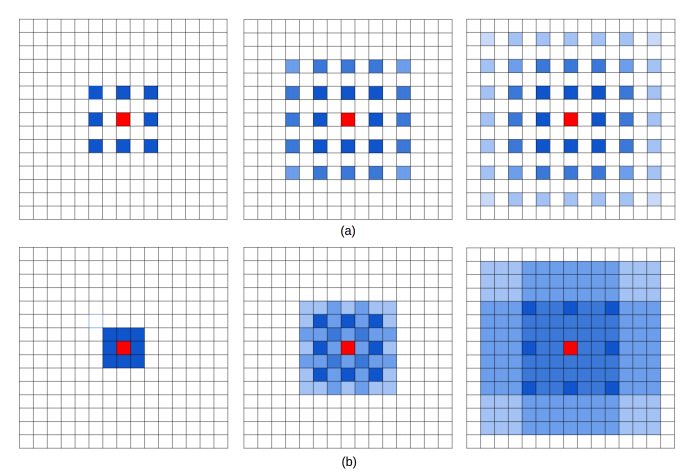
2)Long-ranged information might be not relevant,也就是远距离获取的信息没有相关性,由于空洞卷积稀疏地采样输入信号,使得远距离卷积得到的信息之间没有相关性,影响分类结果。
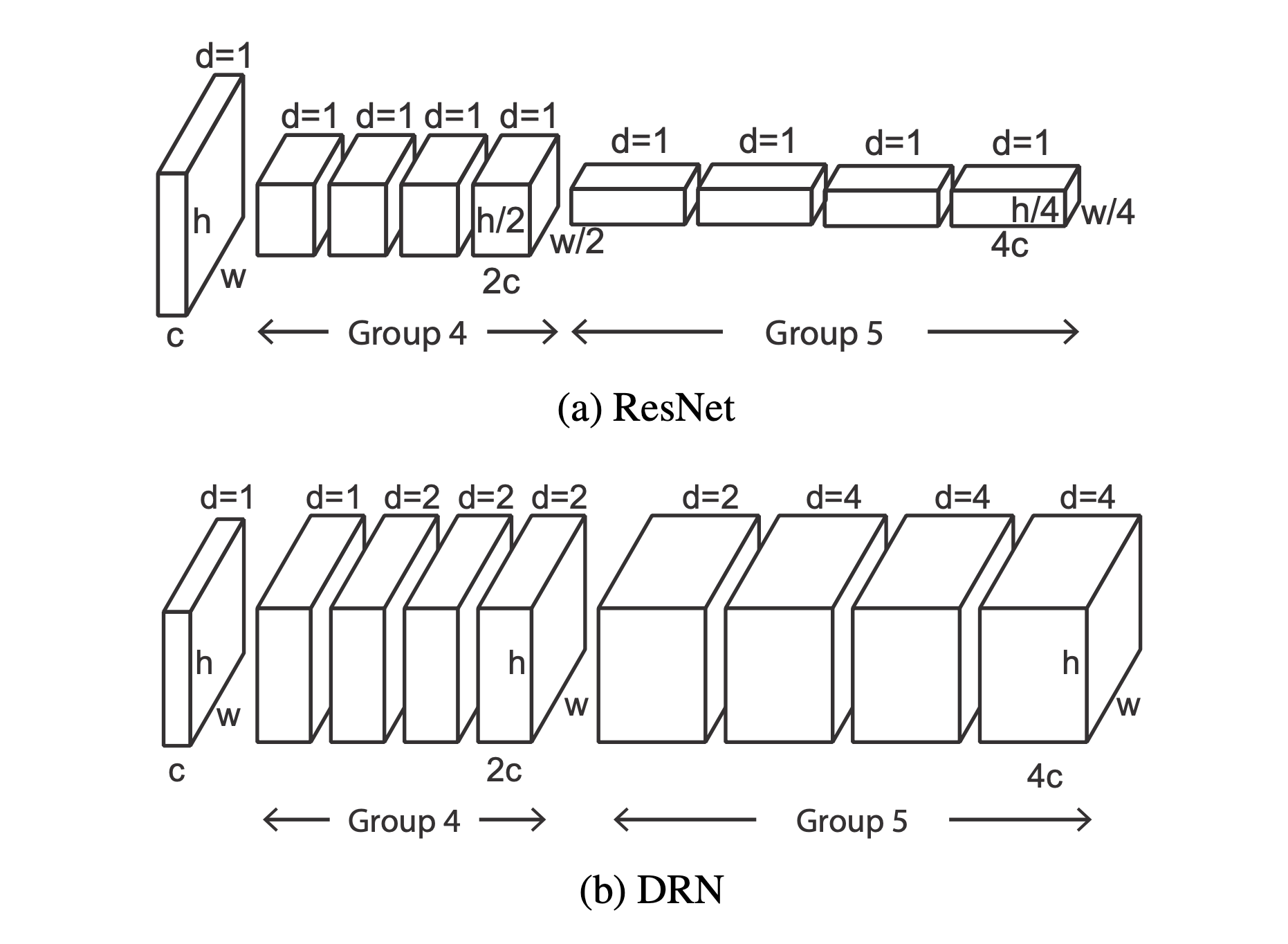
(3)那如何将 ResNet 改成 DRN 呢?
改后的 DRN 和其原来对应的 ResNet 有相同的卷积层数和参数。我们只需要把 group4 的第一层 stride 变为 1,group4 中剩余卷积层和 group5 的第一层 dilation 变为 2,group5 中剩余卷积层 dilation 变为 4。具体来说,对于 ResNet 来说可分为 5 组卷积,DRN 改进了后两组卷积: G4 和 G5。这两组卷积开始的卷积层都是下采样,DRN 做了以下改进:
- 去除了开始的下采样,者保持了 feature 的分辨率,注意到无论是 G4 还是 G5 的第一层卷积感受野是不受影响的,但是 G4 的后续层感受野下降了 2 倍,G5 的后续层感受野下降了 4 倍;
- 对 G4 的后续层使用 dilation=2 的 dilated convolution,G5 的后续层使用 dilation=4 的 dilated convolution;
- 后续就是平均池化,输出预测。在用于语义分割的时候,只需要在后面接一个 1x1 的卷积即可。
总结来说就是,原来 ResNet 在 G4 和 G5 上都有下采样,由输入的 224x224 最终输出 7x7,下采样因子为 32,而 DRN 使用了 dilated convolution 替换了这两个下采样,最终输出为 28x28,下采样因子为 8。相比之下增加了 16 倍的值,空间信息量增大了许多。至于为什么不全部替换池化层,硬件问题,你懂得,呵呵呵...
一句话总结,Dilated Convolution 直接而优雅。
(4)手撕 DRN 代码:
根据论文,作者把 ResNet 改成了 DRN-A、DRN-B 和 DRN-C 三个版本:

1)Both DRN-A、DRN-B and DRN-C:
- BasicBlock 类:增加两个参数 dilation 和 residual。在做 dilated convolution 时,dilation 和 padding 要相等;设置参数 residual 的原因是 DRN-C 后两个 block 没有 residual connection。
- Bottleneck 类:增加两个参数 dilation 和 residual。在做 dilated convolution 时,dilation 和 padding 要相等;设置参数 residual 的原因是?
2)对于 DRN-A:
- 只有 group 5, 6 和 ResNet 不同,其余都一样。group 5, 6 的 stride=2 -> 1,dilation 分别设为 2 和 4。
3)对于 DRN-B:
- Removing max Pooling:去掉了 group 3 前面的 pooling 层 (kernel size=3x3, stride=2),取而代之的是 group 2 的第一个卷积 stride=2 实现下采样;
- 第一个 7x7 的卷积层 stride=2 -> 1、out_planes=64 -> 16;
- Adding layers:add a 2-dilated residual block followed by a 1-dilated block. 对于所有层数的 DRN,group 1, 2, 7, 8 都是 BasicBlock;
4)对于 DRN-C:
- 因为 group 7, 8 没有 residual connection,其余都和 DRN-B 一样。所以 _make_layer 函数增加一个参数 residual=True;
MNC (2015 Dec 14)
Multi-task Network Cascades (MNC) [Arxiv Link]。
RefineNet (2016 Nov 20)
RefineNet [Arxiv Link] 重新设计了 decoder 部分和整体框架采用了 residual connections 的设计方式。
PSPNet (2016 Dec 4)
PSPNet [Arxiv Link]。
DRN (2017 May 28)
Dilated Residual Networks (DRN) [Arxiv Link]。
Segmentation with Adversarial Training
SegAN [Arxiv Link]
Segmentation with RNN
[ReSeg [Arxiv Link]
Refers:<http://www.ijicic.org/ijicic-140104.pdf>,<http://www.cs.sfu.ca/~hamarneh/ecopy/isbi2018b.pdf>,<https://arxiv.org/pdf/1706.09318.pdf>,<https://arxiv.org/pdf/1703.08770.pdf>,<https://www.jianshu.com/p/04b789dc2699>
Others
条件随机场 (Conditional Random Field, CRF):条件随机场方法通常在后期处理中用于改进分割效果。
Loss Function and Evaluation Method in Segmenation
(1)损失函数:
- pixel-wise cross entropy loss;
- dice coefficient loss:Dice Coefficient Loss VS Cross-Entropy;
- soft dice coefficient loss;
- focal loss: 为专门解决 class imbalance 而生;
- Adversarial Training:加入 GAN loss,例如:SegAN;
- Others:Lovasz-Softmax loss;
- Hausdorff Distance: It is a shape similarity metric compared to Jaccard and Dice coefficients as segmentation metrics;
(2)评价标准:
- Mean Intersection over Union;
- Pixel Accuracy;
- Mean Pixel Accuracy (mPA) 是 PA 的一种简单提升,计算每个类内被正确分类像素的比例,之后求所有类的平均;
- Frequency Weighted IoU 是 mIoU 的一种提升,这种方法根据每个类出现的频率为其设置权重;
- Others:Link;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号