DCNN 发展史
本文主要总结整理一些经典的 DCNN (Deep Convolutional Neural Network)。
前言
本文主要总结从 LeNet-5 往后一些著名的「DCNN」。
纵观 CNN 的发展历程,在 LeNet-5 诞生之前,1962 年,加拿大神经科学家 Hubel 和 Wiesel 通过研究发现了猫的视觉中枢里存在感受野、双目视觉和其他功能结构,标志着神经网络结构首次在大脑视觉系统中被发现,两人在视觉系统中信息处理方面的杰出贡献,后来于 1981 年获得诺贝尔生理学或医学奖。1980 年,受 H&W 的启发,日本科学家福岛邦彦(Kunihiko Fukishima)提出分层人工神经回路模型:神经认知机(Neocognitron),他是 CNN 研究的先驱,他的研究模拟生物视觉系统并提出了一种曾经化的多层人工神经网络。再后来,LeCun 在他的研究基础上,诞生了著名的 LeNet。
在深度学习领域有三位非常著名的人:Geoffrey Hinton, Yann Lecun 和 Yoshua Bengio。

Geoffrey Hinton(1947-):1)1983 年,Hinton 和同伴一起发明了玻尔兹曼机,那是最早能够学习神经元內部表征的网络之一;2)1986 年,在「Learning Internal Representations by Error Propagation」这篇论文里,Hinton 证明了反向传播能让神经网络发现自己內部的数据表征,这样便可以处理以往无法解決的问题;3)2012 年,Hinton 和学生 Alex Krizhevsky 等人用 AlexNet 在 ImageNet 比赛上横扫对手,几乎把物体识别的错误率降到了从前的一半,让计算机视觉领域焕然一新;4)加入了 Google;
Yann LeCun(1960-):1)1985 年,Hinton 还没有成为反向传播之父的时候,LeCun 在巴黎六大读博期间,发表过反向传播雏形的一个早期版本;2)1988 年在多大做了一年 Geoffrey Hinton 的博士后助理;3)1989 年加入 AT&T,在 AT&T 期间以反向传播为基础,发表了一项研究,叫做「Backpropagation applied to handwritten zip code recognition」,这算是 CNN 的第一次实现,也就是传说中的 LeCun1989 网络,所以 LeCun 被称为神经网络之父;4)2013 年加入 Facebook 创建了 FAIR;
Yoshua Bengio(1964-):1)1992 年加入 AT&T,与 Yann LeCun 是同事;2)1993 年后一直在蒙大,创建了 MILA;3)2014 年发表 GAN;
ILSVRC
本文介绍的网络大多数都是 2012-2017 年 ILSVRC 比赛产生的一些经典网络,ILSVRC 全称 ImageNet Large-Scale Visual Recognition Challenge。
ImageNet 是一个数据集:1)一共超过 15 million 图像,大约有 22000 类;2)是由李飞飞团队从 2007 年开始,耗费大量人力,通过各种方式(网络抓取,人工标注,亚马逊众包平台)收集制作而成,它作为论文在 CVPR2009 发布,当时人们还很怀疑通过更多数据就能改进算法的看法。
ILSVRC 是一个比赛:1)使用的数据集是 ImageNet 数据集的一个子集,一般说的 ImageNet 实际上指的是这个子集,总共有 1000 类,每类大约有 1000 张图像。具体地,有大约 1.2 million 的训练集,5 万验证集,15 万测试集;2)ILSVRC 从 2010 年开始举办,到 2017 年是最后一届。
总体来说,DCNN 的发展历史大致如下:

Year | CNN or Team | test top-5 | note ------------------------------------------------------------------- 2012 | AlexNet | 16.42% | 5-layers 2012 | AlexNet * | 15.32% | 7-layers 2013 | OverFeat | 14.2% | 7 fast models 2013 | OverFeat | 13.6% | 赛后,7 fast models 2013 | ZFNet | 13.51% | ZFNet论文上的结果是14.8 2013 | Clarifai | 11.74% | 2013 | Clarifai * | 11.20% | 用了2011年的数据 2014 | VGG | 7.32% | 7 nets, dense eval 2014 | VGG 2nd | 6.8% | 赛后,2 nets 2014 | GoogleNet-v1 * | 6.67% | 7 nets, 144 crops 2014 | GoogleNet-v2 | 4.82% | 赛后,6 nets, 144 crops 2014 | GoogleNet-v3 | 3.58% | 赛后,4 nets, 144 crops 2014 | GoogleNet-v4 | 3.08% | 赛后,v4+Inception-Res-v2 2015 | ResNet * | 3.57% | 6 models 2016 | ResNeXt 2nd | 3.03% | 加州大学圣地亚哥分校 2016 | Trimps-Soushen *| 2.99% | 公安三所 2017 | SENet * | 2.25% | Momenta 与牛津大学
LeNet-5 (1998)
LeNet 系列网络是最早期的神经网络之一,来自于 Yann Lecun 之手,自 1988 年起经过多年的研究和多次成功的迭代,最终于 1998 年诞生了我们熟知的 LeNet-5,虽然它诞生于 90 年代,但是由于当时计算机硬件的限制,可以说直至 2010 年左右一般的计算机还是难以运行此网络。1989 年,LeCun 在 Bell 实验室首次将反向传播算法用于实际应用,也就是 LeNet1989,这个网络当时主要用于手写数字和手写邮编的识别,应用于几乎全美的邮政系统,错误率低于 1%,是第一个产生实际商业价值的卷积神经网络。

LeNet-5 一共有 2 个卷积层、2 个 maxpooling 操作和 2 个 全连接层:
| Layer C1(Conv2d,out_channels=6,kernel_size=5x5,stride=1,padding=0) |
| Layer S2(MaxPool2d,kernel_size=2,stride=2,padding=0) |
| Layer C3(Conv2d,out_channels=16,kernel_size=5x5,stride=1,padding=0) |
| Layer S4(MaxPool2d,kernel_size=2,stride=2,padding=0) |
|
Layer C5(Linear,out_features=120) |
| Layer F6(Linear,out_features=84) |
LeNet-5 定义了 CNN 的基本框架:卷积层(conv)+ 池化层(pool)+ 全连接层(fc)。
AlexNet (2012)
AlexNet 是由当时 Geoffrey Hinton 的弟子 Alex Krizhevsky 设计,凭借这个网络,当时碾压性地拿下了 2012 年的 ILSVRC 的冠军。
---------------------------------
1. 过拟合代表了深度学习的一个派别,DL 可以用一个很大很大的模型,然后通过正则来使模型不要过拟合,这是 DL 界在当时的一个认知,而到现在,大家又认为正则没有这么重要,关键的是网络的设计;
2. ReLU vs Sigmoid:
3. 通道数可以理解为:每一个通道是网络的一种特定的模式,例如一个通道去识别猫腿或者头;
4. CNN & FC 层:Figure 4 表明,DCNN 训练得到的最后那个向量 (最后一个卷积层的输出),在语义空间里面的表示特别好 (也就是相似图片的向量相似度高,余弦相似度),所以说 CNN 能够很好地提取特征,以至于后面用一个很简单的分类器就能分类好,这是 CNN 的一大强项;
5. Dropout 其实等价于一个 L2 的正则项;
---------------------------------
AlexNet 是当时机器学习和计算机视觉领域的重大突破,由于在准确率方面比当时传统的方法高很多,它也成为了大家对深度学习的关注爆发性增长的源头,而在此之前,深度学习已经沉寂了很久。
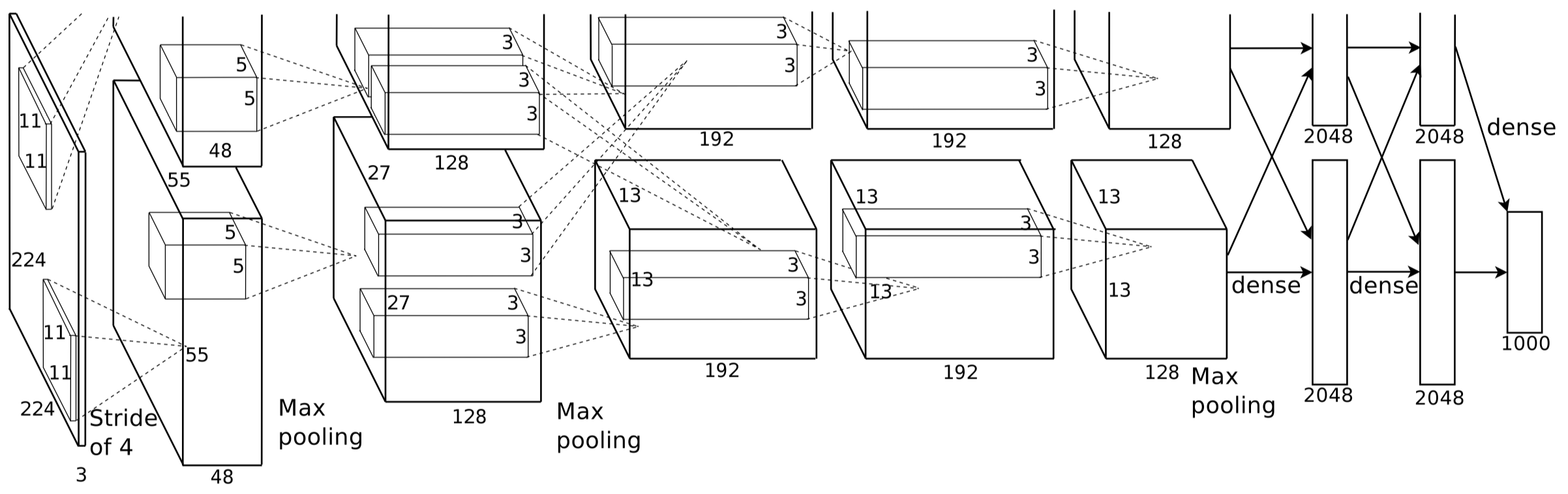
AlexNet 模型一共分为 8 层,其中 5 个卷积层,3 个全连接层。上图网络架构分成并行的两部分 (仅在第 3 个卷积层和后面的 FC 层两个 GPU 之间有通信),是因为当时 GPU 的计算能力不强,作者 Alex Krizhevsky 采用了两个 GPU 来并行计算,也就是 model parallel。
AlexNet 主要有 4 方面的亮点:1)采用 ReLU 代替 Sigmoid 和 Tanh,稍微减缓了 Gradient Vanishing 问题并加速了网络的收敛;2)提出 LRN (Local Response Normalization),作者声称能减少 top1/top5 error rate 1.4%/1.2%,但此技术后续没有得到广泛使用,因为超参数太多且不具备很好的泛化能力;3)训练时采用 Data Augmentation,具体做法为,先 down-sample 成最短边为 256 的图像,然后剪出中间的 256x256 图像,再减均值做归一化,训练时,对每张图像,随机提取出 224x224 以及水平镜像(Horizontal Reflection)版本的图像,测试时,对每张图像提取出 5 张(四个角落以及中间)以及水平镜像版本,总共 10 张,平均 10 个预测作为最终预测;4)使用 Dropout 来避免网络过拟合。
AlexNet 的训练超参数为:SGD,momentum 0.9,initial lr 0.01,batch size 128,weight decay 0.0005,val loss 不再下降时 lr/10,权重初始化用(0,0.01)的高斯分布,第 2、4、5 卷积层和全连接层的 bias 初始化为 1(给 relu 提供正值利于加速前期训练),其余 bias 初始化为 0。
[Pytorch Codes Link],但是 Pytorch 代码中的 AlexNet 部分卷积层的卷积核个数和原论文有出入,官方解释是他们参考的是这篇论文。
ZFNet (2013)
ZFNet 是 2013 年 ILSVRC 的分类任务冠军,总体而言 ILSVRC2013 是比较平静的一届,ZFNet 网络结构相对于 AlexNet 没有什么改进,只是调整了一下参数,性能相比 AlexNet 提升不少,top-5 error 從 16.4% 提升到 13.5%。
严格意义上来说当时分类冠军是 Clarifai,但是我们通常讨论的 ILSVRC2013 冠军指的是 ZFNet,Z 和 F 指的是 Zeiler 和 Fergus,他们曾是 Hinton 的学生,后在纽约大学读博的 Zeiler,联手纽约大学研究神经网络的 Fergus 提出了 ZFNet,而 Zeiler 又是 Clarifai 的创建者和 CEO。ZFNet 的意义不在于它获得了 ILSVRC2013 的冠军,而是解释了为什么 CNN 有效和如何提高 CNN 的性能。
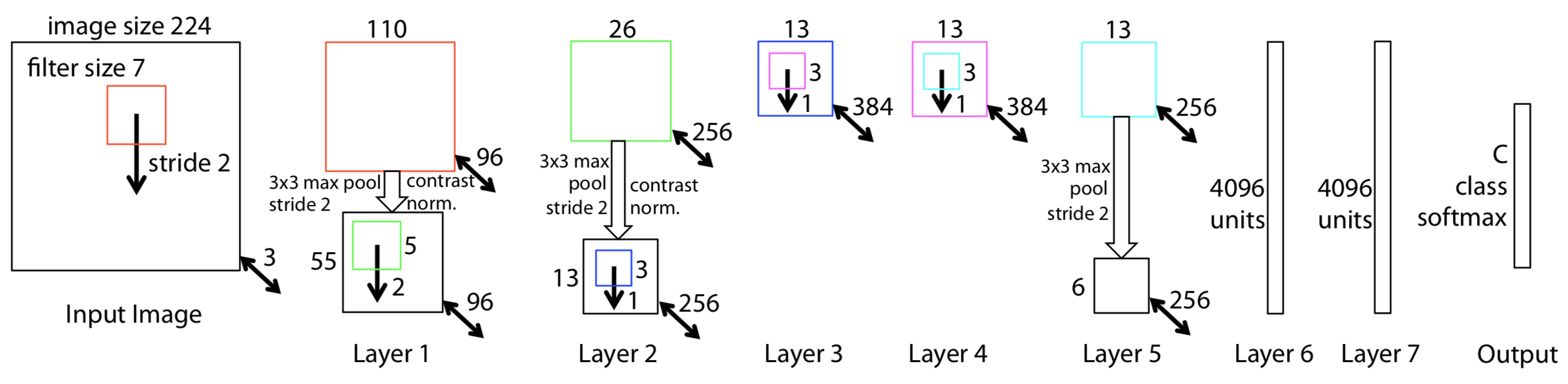
ZFNet 的主要贡献在于:1)利用反卷积,可视化 Feature Maps,可以看出前面的层学习的是物理轮廓、边缘、颜色、纹理等,后面的层学习的是和类别相关的抽象特征;2)与 AlexNet 相比,前面的层使用了更小的卷积核和更小的步长,保留了更多特征;3)通过遮挡,找出了决定图像类别的关键部位;4)通过实验,说明了深度增加时,网络可以学习到更好的特征。
NIN (2013)
NIN 全称 Network in Network。
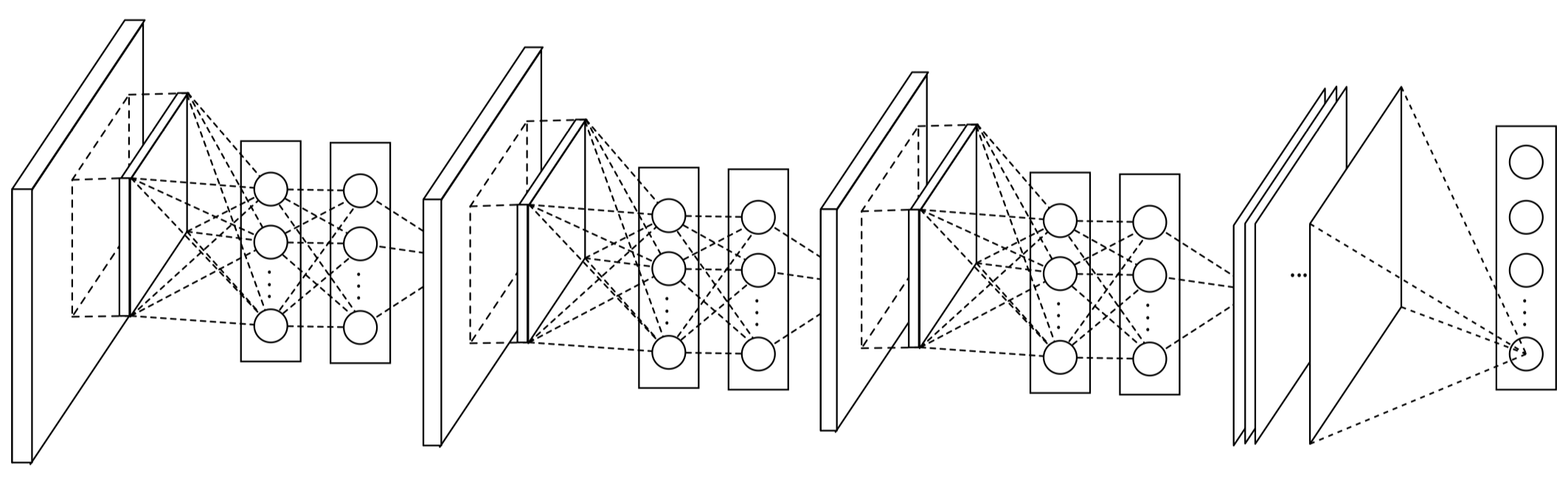
一般 CNN 是由卷积层和池化层交替组成,卷积层通过使用非线性激活函数(ReLU,Sigmoid,etc)的线性组合最终得到 Feature Maps。
实际上 CNN 中的卷积操作是一种广义线性模型(GLM),作者认为 GLM 的抽象层次比较低,如果要提取的特征是线性的或者是低度非线性的,那么这种卷积操作得到的特征是比较符合预期的,但是如果所要提取的特征是高度非线性的,因为同一概念的数据一般是存在于一个非线性流形中,特征和输入之间的关系是一个高度非线性的函数,那这对于 GLM 来说就比较困难了。作者在 NIN 中用一种「micro network」结构代替 GLM,这种「micro network」可看作一种非线性函数模拟器。
作者采用「multilayer perceptron」来作为「micro network」,主要有两点原因:1)MLP 与 CNN 结构兼容,都可以用 BP 来训练;2)MLP 可自行深化网络模型,复合特征复用的思想。
这篇论文的创新点在于两方面:1)MLP Convolution Layers;2)Global Average Pooling。
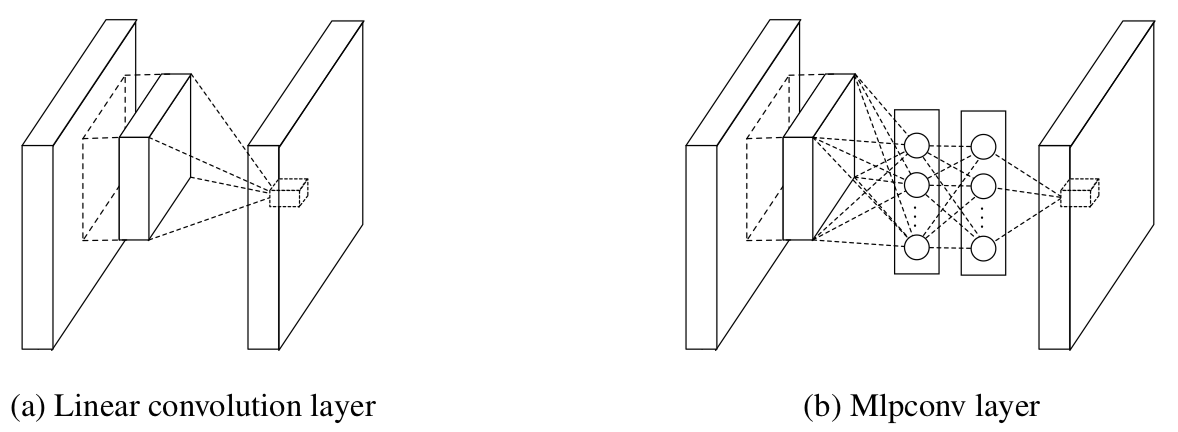
关于 MLP Convolution Layers,其结构如下图,主要有三方面好处:1)相比 Linear Convolutional Layers,MLP 将 Feature Map 由多通道的线性组合变为非线性组合,提高特征抽象能力;2)使得模型能够学习到通道之间的关系;3)可以实现卷积核通道数的降维和升维,实现参数的减小化。
关于 Global Average Pooling,作者提出用 GAP 来代替原来的全连接层,即对每个特征图一整张图进行 GAP,每张特征图得到一个输出。使用 GAP 主要有三方面的好处:1)使用 FC 很难解释各类别的概率信息是怎么反向传播回前面的卷积层的,而 GAP 相对来说更能将 Feature Maps 和类别对应起来;2)可以有效地避免过拟合,因为 GAP 没有可优化的参数;3)GAP 整合了空间信息,对输入的空间理解能力更强。
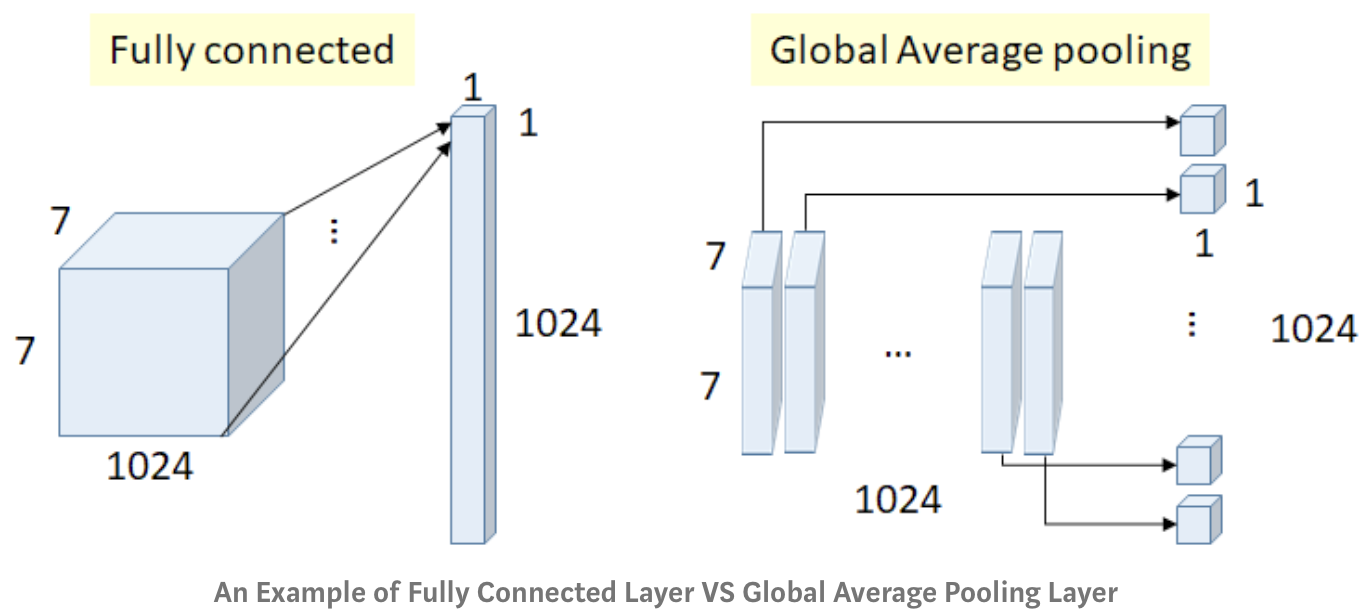
总的来说,NIN 主要有以下优点:1)更好的局部抽象能力;2)更小的参数空间;3)更小的全局过拟合。
VGG (2014)
VGG 是由牛津大学 Visual Geometry Group 提出,是 2014 年 ILSVRC 竞赛定位任务的第一名和分类任务的第二名。
相比 AlexNet,VGG 的一个改进是采用连续的几个 3x3 的卷积核代替 AlexNet 中的较大卷积核,也是卷积神经网络越走越深的开端。对于当时而言,VGG 可以算是非常深的网络了,最深的可以达到 19 层(尽管同年的 GoogLeNet 有 22 层)。
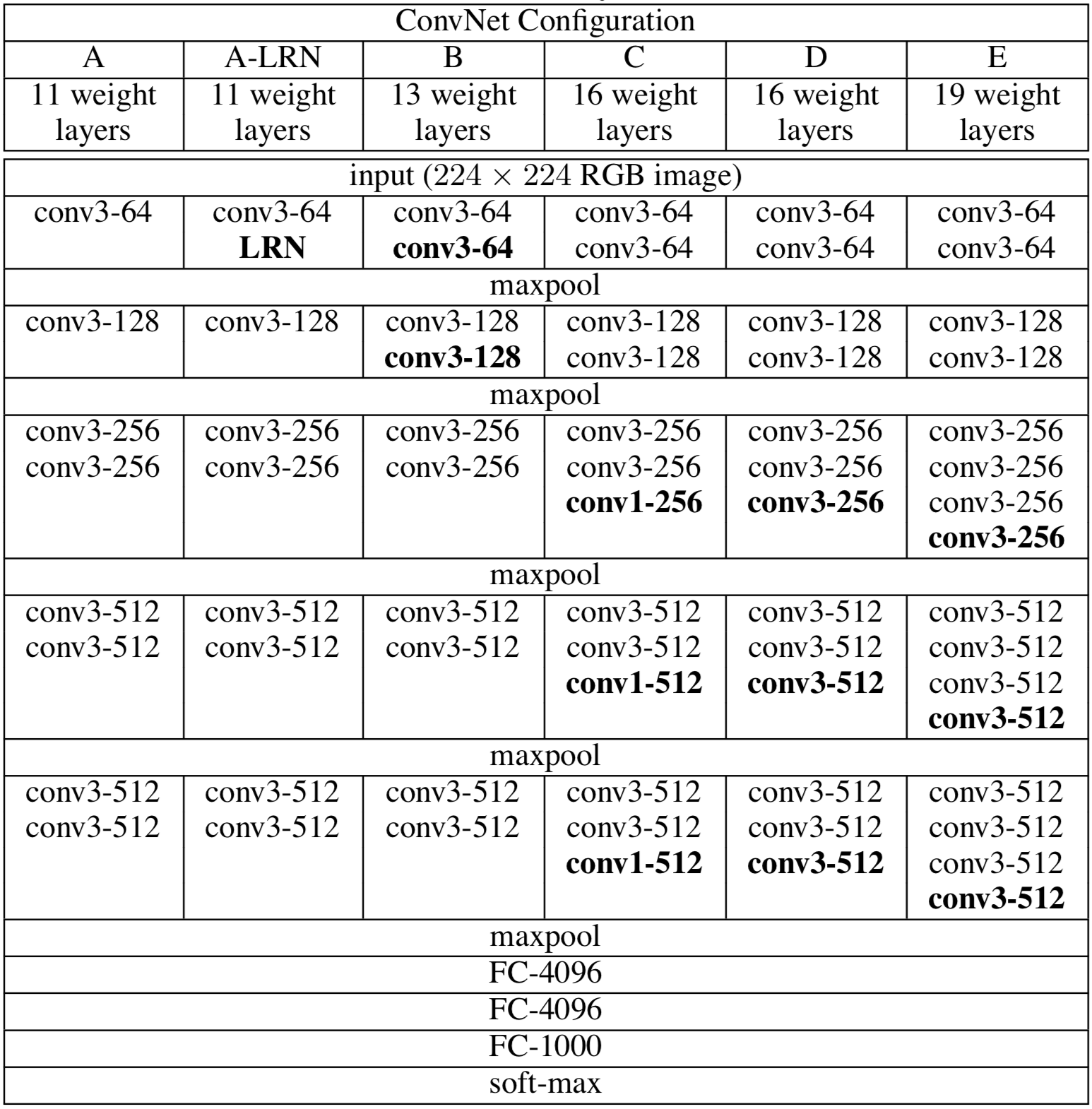
如上图所示,VGG 其实和 AlexNet 有很多相似之处,都是由 5 个卷基层和 3 个全连接曾组成,但这里 VGG 的「卷积层」有所不同,并不是单个卷积层加激活函数,而是多个这样的组合成为一个「Conv Layer Group」,每个 Group 之间才进行池化操作。
VGG 网络研究的主要贡献为:1)不采用感受野大的卷积核,例如 5x5 和 7x7,全部使用 3x3,好处有两点:保证相同的感受野同时减少网络参数(假设卷积层的输入和输出特征图大小均为 C,3个 3x3 的参数量为 3x3x3xC2=27C2,一个 7x7 的参数量为 7x7xC2=49C2)和增加网络非线性表达能力(因为每个卷积层后都带有一个激活函数);2)从 VGG16开始尝试使用 1x1 NIN,但实验发现效果不如 3x3;3)通过实验证明 AlexNet 研究中提到的 LRN 无性能增益,反而增加内存的使用和计算时间;4)实验证明随着网络深度的增加(11->19),分类性能逐渐提高。
手撕代码:VGG 的 Pytorch 代码相对简单,可以理解成分两部分来构建 VGG 网络:1)features;2)classifier。
首先通过 make_layers 函数来构建 features :
def make_layers(cfg, batch_norm=False): layers = [] in_channels = 3 for v in cfg: if v == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) if batch_norm: layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers)
通过传入不同的 cfg ,可以构造出不同层数的 VGG。然后把构造好的 features 传入 VGG 类中,结合 classifier 构造出完整的 VGG 网络:
class VGG(nn.Module): def __init__(self, features, num_classes=1000, init_weights=True): super(VGG, self).__init__() self.features = features self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) self.classifier = nn.Sequential( nn.Linear(512 * 7 * 7, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, num_classes), ) if init_weights: self._initialize_weights() def forward(self, x): x = self.features(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.classifier(x) return x def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0)
GoogLeNet (2014)
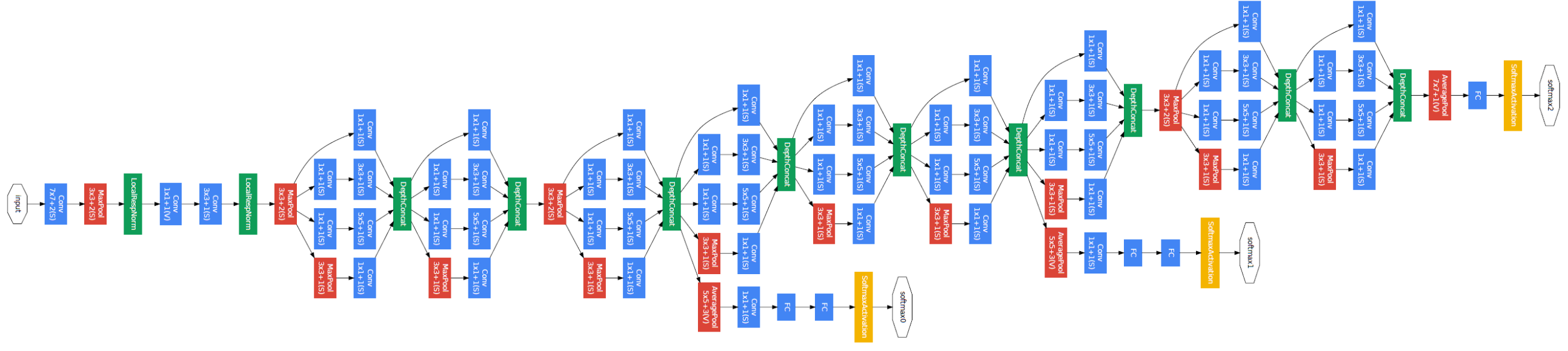
GoogLeNet,又称 Inception v1,在 ILSVRC2014 的分类任务上击败 VGG 夺得冠军。GoogLeNet 从名字上就很容易看出它来自 Google,从另外一个角度,GoogLeNet 也是在向 LeNet 致敬。GoogLeNet 只是一个名字,它的核心内容是发明了 Inception Module,作者称 Inception Module 的灵感来自于 2013 年的一篇论文。
GoogLeNet 与 AlexNet,VGG 等网络通过增大网络深度来提升网络性能的思想不同,单纯层数的增加会带来很多负作用,比如过拟合、梯度消失、梯度爆炸等。所以 GoogLeNet 另辟幽径,能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。对比之下,Inception v1(22 层)参数量為 5 million,VGG16 参数量為 138 million,AlexNet 参数量為 60 million。
Inception v1(top5 error 6.67%)后又经 3 次迭代,分别经历了 v2(top5 error 4.82%)、v3(top5 error 3.58%)、v4(top5 error 3.08%)。
Inception v1 在不同的层增加了一些 Auxiliary Classifiers,所以 Inception v1 一共有 3 个梯度供应商。搞深度学习的都知道,梯度消失几乎是所有深层网络的通病,往往训练到最后,网络最开始的几层就训不动了。于是作者 Szegedy 加入了 Auxiliary Classifiers,用于辅助训练,加速网络收敛。
Inception v1 的主要贡献有三点:1)提出 Inception Module 并对其优化;2)用 GAP 代替全连接层;3)运用 Auxiliary Classifiers 来加速网络收敛。
关于 Inception Module,作者认为,相比传统的提高网络精度的方法,例如单纯扩大网络规模或者增大数据集,如果想要从本质上提高网络性能,就得用 Sparsely Connected Architectures,也就是稀疏连接结构,实现稀疏连接有两种方法,一种是空间上的稀疏连接,也就是传统的 CNN 卷积结构,具体来说就是只对输入图像的某一部分 patch 进行卷积,而不是对整个图像进行卷积,共享参数降低了总参数的数目减少了计算量;另一种方法是在特征维度进行稀疏连接,也就是在多个尺寸上进行卷积再聚合,把相关性强的特征聚集到一起,每一种尺寸的卷积只输出 256 个特征中的一部分,这也是一种稀疏连接,具体来说就是尽可能用「小」、「分散」的可堆叠的网络去学习复杂的分类任务,Inception Module 正是体现了这种「小」和「分散」的思想。
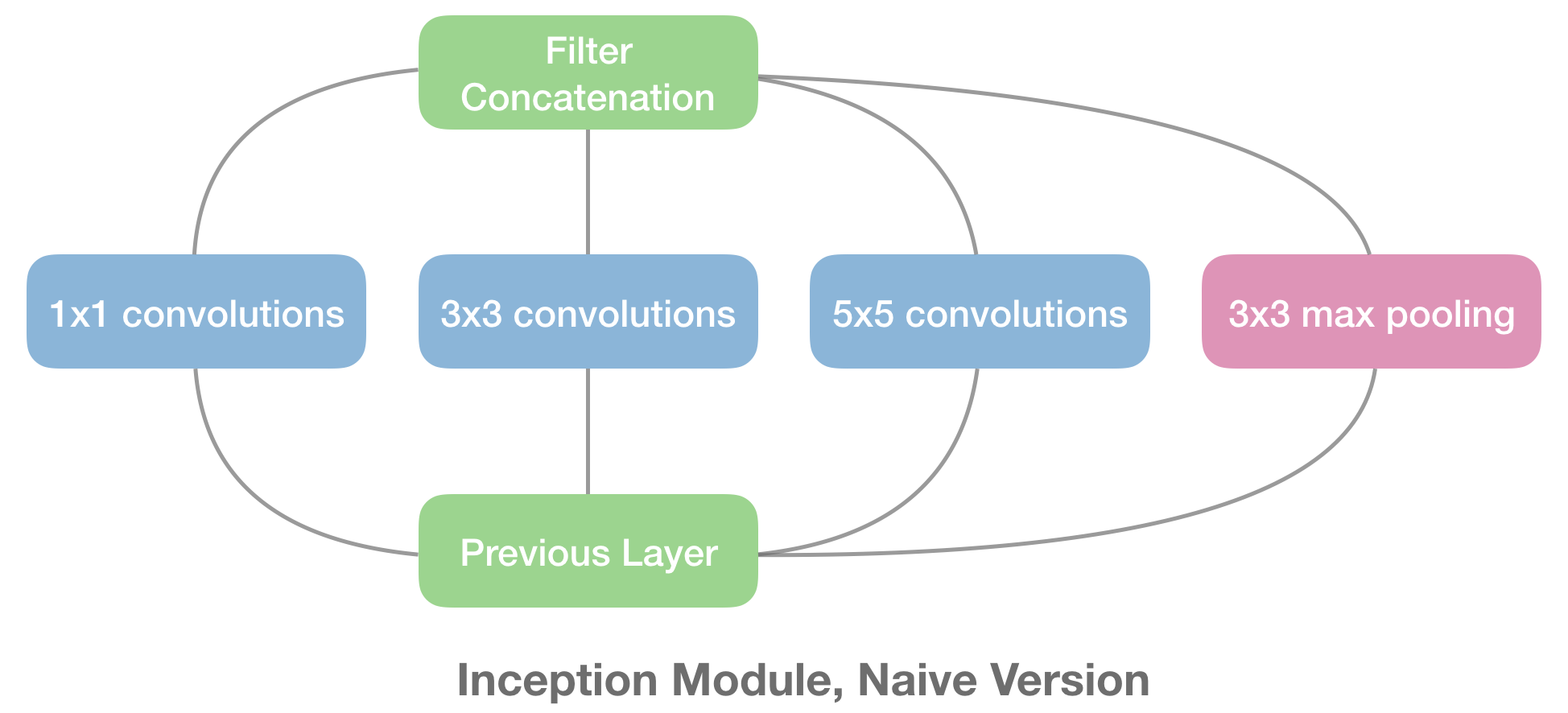
由上图可见,Inception Module 是「分叉-汇聚」结构,也就是在同一层网络中存在多个不同尺度的 Kernels,分别卷积完后再汇聚 Concatenate 到一起,但是假如四个分支都有 256 个卷积核,那 concat 之后就是 1024 个卷积核,显然这是没法接受的,于是作者 Szegedy 采用 NIN 的思想对 Inception Module 改进了一下,如下图所示。
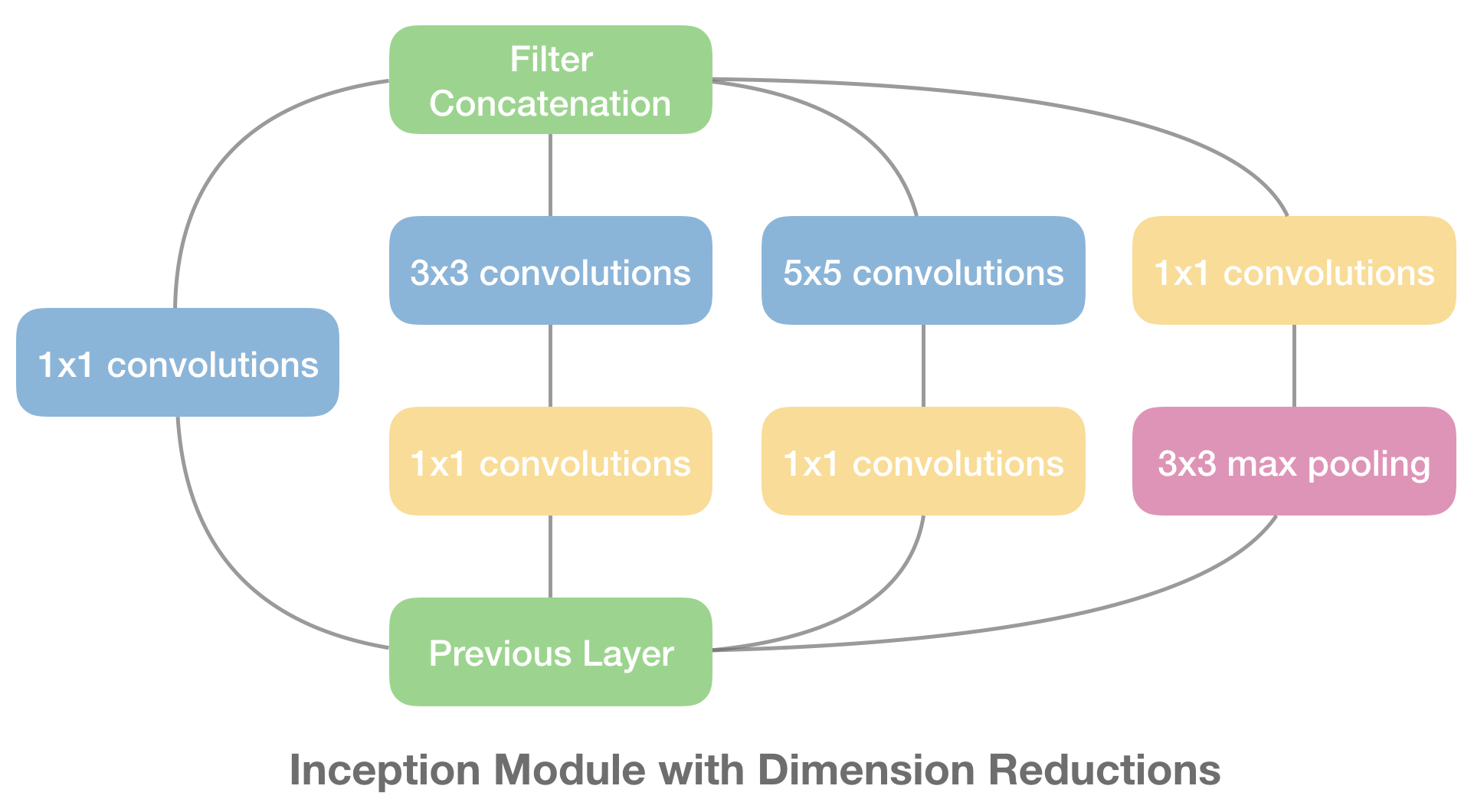
通过利用 1x1 卷积来降维,具体来说就是每个 1x1 卷积的输出通道数都会比上一层要少。另外,这些 1x1 卷积操作还增加了网络的非线性。
关于用 GAP 代替全连接层,这样做的好处是:1)对数据在整个 Feature 上做正则化,防止过拟合;2)大大减少网络参数;3)不用再关注输入图像的尺寸,因为不管是怎样的输入都是一样的平均方法,传统的全连接层要根据尺寸来选择参数数目,不具有通用性。
关于 Auxiliary Classifiers,作者在某些层级上加了分支分类器,输出的 loss 乘以个系数再加到总的 loss 上,作者认为可以防止梯度消失问题,事实上在较低的层级上这样处理基本没作用,作者在后来的 inception v3 论文中做了澄清。
以下是手撕代码部分:
构建 GoogLeNet 的代码可以分为五部分:1)函数 googlenet ;2)类 GoogLeNet ;3)类 Inception ;4)类 InceptionAux ;5)类 BasicConv2d ;
第一部分,函数 googlenet 提供给用户直接调用此函数来构成 googlenet。此函数共提供用户 4 个参数:1)pretrained(bool)如果是 True,返回用户一个在 ImageNet 上预训练好的模型,默认是 False;2)progress(bool)如果是 True,下载预训练模型时显示进度条;3)aux_logits(bool)如果是 True,增加两个 auxiliary branch 来辅助训练,需要注意的是,当 pretrained=True 时,aux_logits 默认是 False,当 pretrained=False 时,aux_logits 默认是 True,也就是说 pytorch 的预训练 googlenet 在训练中并没有使用论文的 aux_logits;4)transform_input(bool)如果是 True,则对输入的图像进行和在 ImageNet 上预训练时一样的预处理,默认是 False。
def googlenet(pretrained=False, progress=True, **kwargs): if pretrained: if 'transform_input' not in kwargs: kwargs['transform_input'] = True if 'aux_logits' not in kwargs: kwargs['aux_logits'] = False if kwargs['aux_logits']: warnings.warn('auxiliary heads in the pretrained googlenet model are NOT pretrained, ' 'so make sure to train them') original_aux_logits = kwargs['aux_logits'] kwargs['aux_logits'] = True kwargs['init_weights'] = False model = GoogLeNet(**kwargs) state_dict = load_state_dict_from_url(model_urls['googlenet'], progress=progress) model.load_state_dict(state_dict) if not original_aux_logits: model.aux_logits = False del model.aux1, model.aux2 return model return GoogLeNet(**kwargs)
第二部分,类 GoogLeNet 负责具体构建 googlenet 网络模型。如论文中的网络结构图所示,网络由一些正常的卷积层和 Inception Modules 构成。所以代码中 GoogLeNet 类主要是通过 BasicConv2d 、 Inception 和 InceptionAux 这三个类来构造网络。注意,代码中的 self.training 来自 nn.Module ,默认是 True 。
第三部分,类 Inception 负责构建 Inception Module。如论文中 Inception module with dimension reductions 所示,Inception Module 主要分为 4 个 branch,其中 branch 1 和 branch 4 只有一个卷积层,而 branch 2 和 branch 3 有两个卷积层。
代码中 Inception 类共有 7 个参数:参数 in_channels 是每个 branch 第一个卷积层的输入通道数;参数 ch1x1 、 ch3x3 、 ch5x5 和 pool_proj 分别为这四个 branch 最后一个卷积层的输出通道数;4 个 branch 中只有中间两个 branch 有两个卷积层,参数 ch3x3red 和 ch5x5red 分别是这两个通道第一个卷积层 (1x1 conv layer) 的输出通道数。
class Inception(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj): super(Inception, self).__init__() self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) ) self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch5x5red, kernel_size=1), BasicConv2d(ch5x5red, ch5x5, kernel_size=3, padding=1) ) self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1)
第四部分,类 InceptionAux 负责构建 Auxiliary Classifier。论文中的两个 Auxiliary Classifier 分别加在 inception4a 和 inception4d 后面。其实就是带有全连接层的分类器。
class InceptionAux(nn.Module): def __init__(self, in_channels, num_classes): super(InceptionAux, self).__init__() self.conv = BasicConv2d(in_channels, 128, kernel_size=1) self.fc1 = nn.Linear(2048, 1024) self.fc2 = nn.Linear(1024, num_classes) def forward(self, x): # aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14 x = F.adaptive_avg_pool2d(x, (4, 4)) # aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4 x = self.conv(x) # N x 128 x 4 x 4 x = x.view(x.size(0), -1) # N x 2048 x = F.relu(self.fc1(x), inplace=True) # N x 2048 x = F.dropout(x, 0.7, training=self.training) # N x 2048 x = self.fc2(x) # N x 1024 return x
第五部分,类 BasicConv2d 负责构建简单的卷积层,包括网络中的 3x3 conv layer 和 1x1 conv layer。
class BasicConv2d(nn.Module): def __init__(self, in_channels, out_channels, **kwargs): super(BasicConv2d, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs) self.bn = nn.BatchNorm2d(out_channels, eps=0.001) def forward(self, x): x = self.conv(x) x = self.bn(x) return F.relu(x, inplace=True)
以上是 GoogLeNet 也就是 Inception v1 的详细情况,下面详细介绍 Inception v2 和 v3 的情况,对于 v2 和 v3,这两个版本非常容易混淆,看论文也是看得一脸懵,很多人在很多博客中都认为这两个版本是几乎一样的,所以作者也最终在 v4 的论文中明确指明这两个版本的区别:
The Inception deep convolutional architecture was introduced in (Szegedy et al. 2015a) and was called GoogLeNet or Inception-v1 in our exposition. Later the Inception architecture was refined in various ways, first by the introduction of batch normalization (Ioffe and Szegedy 2015) (Inception-v2) by Ioffe et al. Later the architecture was improved by additional factorization ideas in the third iteration (Szegedy et al. 2015b) which will be referred to as Inception-v3 in this report.
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
所以,一般我们就认为 Inception v2 的主要贡献就是加入了 Batch Normalization,也就是 v3 论文中的 BN-Inception,所以在此就不作详细的讨论。
Inception v3 来自论文「Rethinking the Inception Architecture for Computer Vision」,在这篇文章上,作者提出了一系列能增加准确度和减少计算复杂度的修正方法。v3 中涉及的改进,主要是基于这篇论文开头提到的四个网络设计原则:
原则 1: 要防止出现特征描述的瓶颈,尤其是网络的前面部分。所谓特征描述的瓶颈就是中间某层对特征在空间维度进行较大比例的压缩,比如使用 Pooling 时,会导致很多特征丢失。虽然 Pooling 是 CNN 结构中必须的功能,但我们可以通过一些优化方法来减少 Pooling 造成的损失。总的来说,特征图从输入到输出应该缓慢减小。
原则 2: 高维度的特征表达能使网络处理能力更强。所以增加网络的非线性,令网络能表达更高维度的特征,可以让网络训练得更快。另外一篇博文的理解为,相互独立的特征越多,输入的信息就被分解的越彻底,分解的子特征间相关性低,子特征内部相关性高,把相关性强的聚集在了一起会更容易收敛。这点就是 Hebbin 原理:fire together, wire together。原则 2 和原则 1 可以组合在一起理解,特征越多能加快收敛速度,但是无法弥补 Pooling 造成的特征损失,Pooling 造成的 representational bottleneck 要靠其他方法来解决。
原则 3: 可以压缩特征维度数,来减少计算量而不影响特征的表达能力。在进行大尺度卷积之前,先对输入进行降维,Inception v1 中提出的用 1x1 卷积先降维再作特征提取就是利用这点。不同维度的信息有相关性,降维可以理解成一种无损或低损压缩,即使维度降低了,仍然可以利用相关性恢复出原有的信息。
原则 4: 整个网络结构的深度和宽度要做到平衡。只有等比例的增大深度和维度才能最大限度的提升网络的性能。
Inception v3 的网络结构框架如下:

Inception v4 是基于 v3 的基础,引入残差结构,使训练加速,性能提升。WIP
Xception 是在 v3 的基础上提出,基本思想是通道分离式卷积,但是又有区别。WIP
ResNet (2015)
ResNet 是由何凯明在 2015 年推出,横扫当年的 ILSVRC2015(分類、檢測和定位) 和 COCO。
---------------------------------
沐神解释 ResNet 的精髓:
网络越深,效果越好,但是也不是绝对,当网络变深的时候,梯度要么 vanishing,要么 exploding。除了梯度爆炸和消失,随着层数变深,还有另外一个问题,就是:模型退化。
深的 CNN 很难训练,作者提出用残差连接的方法,使得训练更加容易,什么叫 “很难训练”?“难训练”,也就是文章中 Figure 1 描绘的:The deeper network has higher training error, and thus test error。这个现象叫 “模型退化”,注意模型退化不是过拟合,残差结构就是用于解决由于 “模型退化” 造成的 “难训练” 问题的。
假设已有一个效果还不错的浅层网络,如果再多加一些层,理论上效果是不应该变差的,因为新加的层最差的情况你可以将它们变成 identity mapping,但实际上做不到,SDG 找不到这个解(SGD 的精髓在于你得一直跑得动,也就是梯度不能太小)。所以残差连接想做的是:显式地构造出 identity mapping,使得深的网络不会比浅的网络效果差。这其实就是属于归纳偏置的思想。
对于 ResNet,后面新加上的那些层,如果新加了一些层后不能使模型变好,那此时因为有残差连接的存在,所以新加的层应该不会学习到任何东西,也就是等于 0。
其实 ResNet 的核心就是一句话:shortcut connection。
对于一个浅层的网络,新加一层,使得模型变深,对于新加的层,输入是 x(假设 x=0.1),要学的东西是 h(x),或者说想要这一层的输出逼近 h(x),例如 h(x)=1。而残差连接的核心思想是,不要让新加的层直接学习 h(x),而是在这一层的输出通过 shortcut connection 加上输入 x,使得输出变成 f(x)+x,此时,要想让输出逼近 h(x)=1,也就是 1=h(x)=f(x)+x,f(x)=h(x)-x,此时这一层要学习的是 h(x)-x,叫残差。
其实 shortcut connection 就是直接相加,其效果其实就是 identity mapping,也就是输入是 x,输出也是 x。
为什么 ResNet 训练起来比较快?主要是因为它在梯度上保持得比较好,从梯度上解释残差连接的优势:https://space.bilibili.com/353445939/dynamic
---------------------------------
本小节主要介绍 ResNet 系列包括其一些重要变体,例如:ResNet-V2、WRN、ResNeXt、ResNeSt 等。
ResNet 出現之前,研究表明,网络的性能会随着层数的加深而增加,但实际上这样单纯增加层数会给网络带来很多问题 (要么 exploding,要么 vanishing):1)模型退化,网络更深意味着参数空间训练时优化问题变得更难,训练误差比浅层网络更高,注意,这不是过拟合;2)梯度消失,梯度是从后向前传播的,增加网络深度后,比较靠前的层梯度会很小,这意味着这些层基本上学习停滞了,这就是梯度消失问题;
对于模型退化,可以这样理解:线性代数中有一种矩阵叫「退化矩阵」,也就是奇异矩阵,退化矩阵研究的是向量组中的向量,而模型退化研究的是神经元节点,这两个退化概念不见得是完全一致的,但至少是非常相似的。线性代数中,所谓退化矩阵也就是矩阵内存在线性相关的向量组。那怎么才算是「线性相关」呢?有两种情况下向量组存在线性相关:1)向量组中含有零向量;2)向量组中含有两个相等的向量。所以模型退化程度越高,线性相关的向量组越多,也就是模型退化时权重线性相关。原本理想状态是神经元分工合作来提取不同的特征,但是现在由于线性相关,神经元权重变得一致或者为 0(节点坏死),提取到的特征都是重复的,所以模型的表达能力下降。
而残差结构就是为了解决模型退化的问题。对比普通堆叠式的结构需要学习 x -> f(x) 的恒等映射,残差结构只需要学习 x -> f(x)-x,也就是所谓的残差。为什么残差连接有效?原文提出的假设是:当梯度趋近于零时,比起让参数拟合一个恒等映射,将残差函数 f(x)-x 逼近到零更加容易,也就是“在堆叠式的非线性映射中,神经网络难以学习到一个恒等映射,而残差连接使之容易”,但具体是为什么,文章并没有阐述。2016 年有一篇论文《Residual Networks Behave Like Ensembles of Relatively Shallow Networks》对残差结构的有效性进行了补充性研究,残差网络可以看作是多个神经网络的集成,其实到一定深度的层数是不必要的。文章做了一个实验,删除 VGG 中的一层,模型性能下降明显,而 ResNet 基本保持不变,也就是说残差结构中的跳跃连接保证了即使在某些神经元失效时,也就是某些层退化时,也不影响整体效果。
为什么叫残差网络?在统计学中,残差和误差是非常容易混淆的两个概念。误差是衡量真实值和观测值之间的差距,残差是指预测值和观测值之间的差距。对于残差网络的命名原因,作者给出的解释是,网络的一层通常可以看做 y=H(x),而残差网络的一个残差块可以表示为 H(x)=F(x)+x,也就是 F(x)=H(x)-x,在单位映射(identity map)中,y=x 是观测值,而 y=H(x) 是预测值,所以 F(x) 就是残差,因此得名残差网络。一般认为,越深的网络通常会带来更好的表现,但实际上,普通的更深的网络性能不但没有提升,反而会出现下降。于是文章提出了一个假设,越深的网络应该带来至少和浅层网络一样的性能,那么如何保证这个效果呢?文章提出了skip connection,也就是一个简单的浅层特征与深层特征相加,这样保证了,即使中间的运算得到的特征没有任何作用,那么这个深层网络也可以保证和浅层有相同的性能。然而实际的效果则出乎意料地好,因为skip connection的存在,每一个特征与特征相加的Block中间的卷积只需要拟合“残差”,剩余的可以跳过“skip”给更前面的。
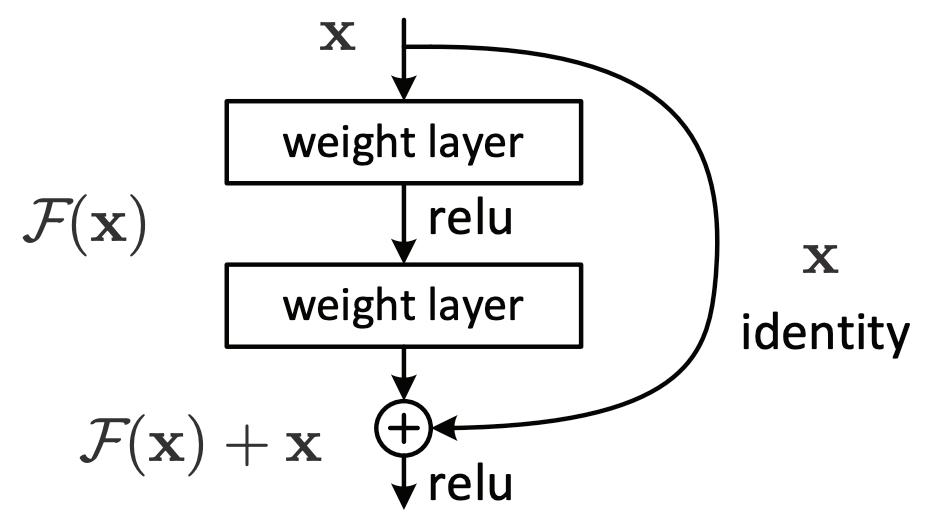
ResNet 的精髓在於 Residual Block,如上图所示,这个结构为什么有效?WIP
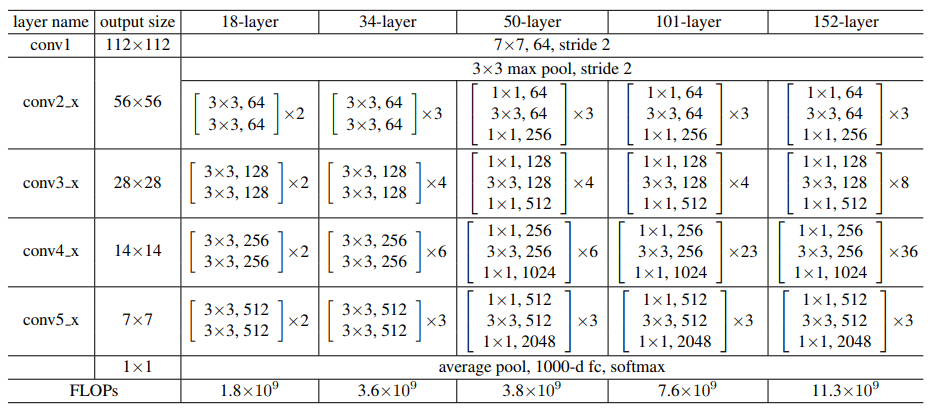

层数不同的 ResNet 的主要区别是 Residual Block(Unit) 的个数和结构不同。这是残差网络的核心思想,也是最基本的结构。根据论文,我们可以把 ResNet 大致分成三个部分:1)conv1 卷积层和池化层: 64 个 7x7,步长为 2 的 卷积核,后接 3x3 max pool,步长为 2;2)4 groups of convolutional layers: conv2.x, conv3.x, conv4.x, conv5.x;3)Average Pooling 和 FC 层。
结合论文来手撕代码是一种比较好的学习网络结构的方式,有助于从一个整体的设计中去理解当中的细节。pytorch 的代码中就是根据这三部分将 ResNet 写成一个类,不同层数的 ResNet 只有第二部分不同,而第二部分通过类内的私有函数 _make_layers 来构成差异。ResNet-18 和 ResNet-34 的 Residual Block 是 `BasicBlock` 结构,ResNet-50、ResNet-101 和 ResNet-152 的是 Bottleneck 结构。
_make_layers 函数:
def _make_layer(self, block, planes, blocks, stride=1, norm_layer=None): if norm_layer is None: norm_layer = nn.BatchNorm2d downsample = None if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( conv1x1(self.inplanes, planes * block.expansion, stride), norm_layer(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample, self.groups, self.base_width, norm_layer)) self.inplanes = planes * block.expansion for _ in range(1, blocks): layers.append(block(self.inplanes, planes, groups=self.groups, base_width=self.base_width, norm_layer=norm_layer)) return nn.Sequential(*layers)
我认为这是 pytorch 的 resnet 代码中最关键的一个函数。其中,最巧妙的是 self.inplanes 的用法。在一开始的时候, self.inplanes = 64 ,因为第一个 Group 的第一个 Block 的输入通道数是 64,随后在构建第一个 Group 的余下 Blocks 前, self.inplanes = planes * block.expansion ,是因为本 Group 中余下的 Blocks 的输入通道数都是 64x4。另外,这个操作也起到积累的作用,实际上把本 Group 的最终输出通道数积累为下一个 Group 的第一个 Block 输入通道数。
至于参数,第一个参数 block 是指需要构造的 block 的类型,可以是 BasicBlock 或者 Bottleneck;第二个参数 planes 是指卷积核个数;第三个参数 blocks 是指定这个 group 中的 block 个数(不同层数的 ResNet,对应的四个带有残差结构的卷积块中的 3x3 卷积层具有相同的卷积核个数);第四个参数 stride 决定这个 block 是否通过带步长的卷积来进行下采样(在 );第五个参数 norm_layer 默认使用 nn.BatchNorm2d 作为 bn,没什么好讲的。下面详细介绍前四个参数不同设置间的差异。
block:
ResNet 共有两种 block 结构: BasicBlock (ResNet-18,34) 和 Bottleneck (ResNet-50,101,152)。在代码上,他们的不同主要有以下两点:1)BasicBlock 的结构是 3x3->3x3,Bottleneck 的结构是 1x1->3x3->1x1,both designs have similar time complexity;2)BasicBlock 的 expansion 为 1;Bottleneck 的 expansion 为 4,也就是每个 residual block 结构中后面的 1x1 卷积核个数是 3x3 卷积核的 4 倍。
planes:
这个参数决定四个卷积块中卷积层的卷积核个数。不同层数的 ResNet 都是 [64, 128, 256, 512] 的结构,但是值得注意的是,对于 Bottleneck (ResNet-50、ResNet-101 和 ResNet-152),第三个 1x1 卷积层的卷积核个数要乘以 4。
blocks:
卷积块中残差结构的个数。对于不同 ResNet,设置如下:ResNet-18: [2, 2, 2, 2];ResNet-34: [3, 4, 6, 3];ResNet-50: [3, 4, 6, 3];ResNet-101: [3, 4, 23, 3];ResNet-152: [3, 8, 36, 3]。
stride:
默认值为 1。所有 ResNet 中的第一个 group 都没有下采样操作,第二、三、四个 group 都有下采样操作,而且都是在第一个 block 的第一个 $\mathtt{3 \times 3}$ 卷积层把 stride 设为 2。
_make_layer 函数在构造 groups 的时候,先构造第一个 block,因为在 ResNet 中,第 1 个 group 的所有 block 是一样的,但是第 2、3、4 个 group 的第一个 block 是有下采样操作(都在 $\mathtt{3 \times 3}$ 卷积中进行),就会导致这个 block 的输入输出大小不一致。所以 Residual Block 有两种 Residual Connections:
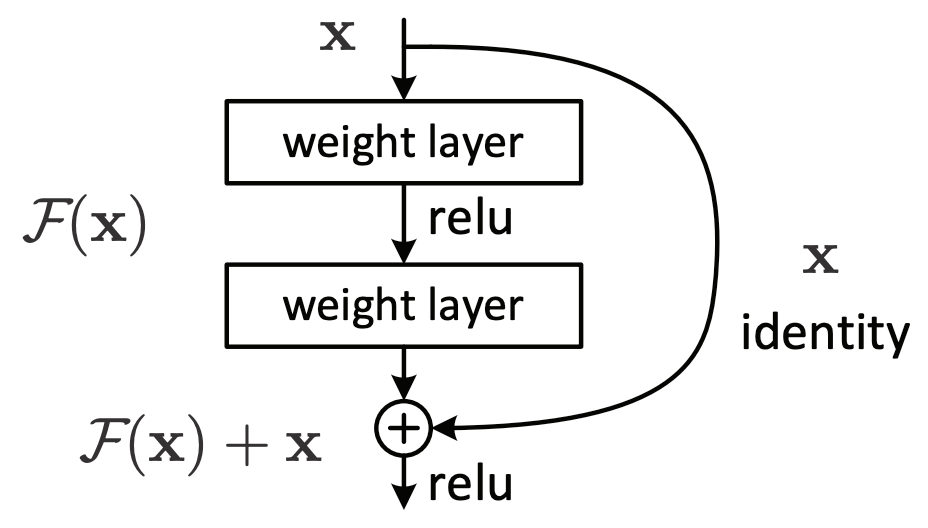 Identity Block:
Identity Block:
The identity shortcuts (x) can be directly used when the input and output are of the same dimensions.
$$\mathtt{y = F(x, {\lbrace W_i \rbrace}) + x}$$
Convolution Block:
When the dimensions change, A) The shortcut still performs identity mapping, with extra zero entries padded with the increased dimension. B) The projection shortcut is used to match the dimension (done by 1*1 conv) using the following formula.
$$\mathtt{y = F(x, {\lbrace W_i \rbrace}) + W_s x)}$$
以上为 ResNet 的详细介绍,由于 ResNet 取得了巨大的成功,其结构简单有效,因此后续也诞生了很多改进性的研究,以下简要介绍基于 ResNet 的一些重要变体:
ResNet-V2 (2016):
其实工程师在 Pytorch 上实现 ResNet 原始版本的时候就发现,在原本应该在 Bottleneck 中 1x1 conv 上进行的下采样工作(也就是步长为 2)挪到处于中间的 3x3 conv 来进行,这样可以比原先的设计得到更快、更好、更稳定的结果,这里可以称为 ResNet-V1.5 版本。
而 ResNet-V2 则是原来 V1 版本那帮研究者对 V1 版本的一些改进,其实很简单,就是改进了残差单元,将 BN+ReLU 挪到 Conv 层之前:
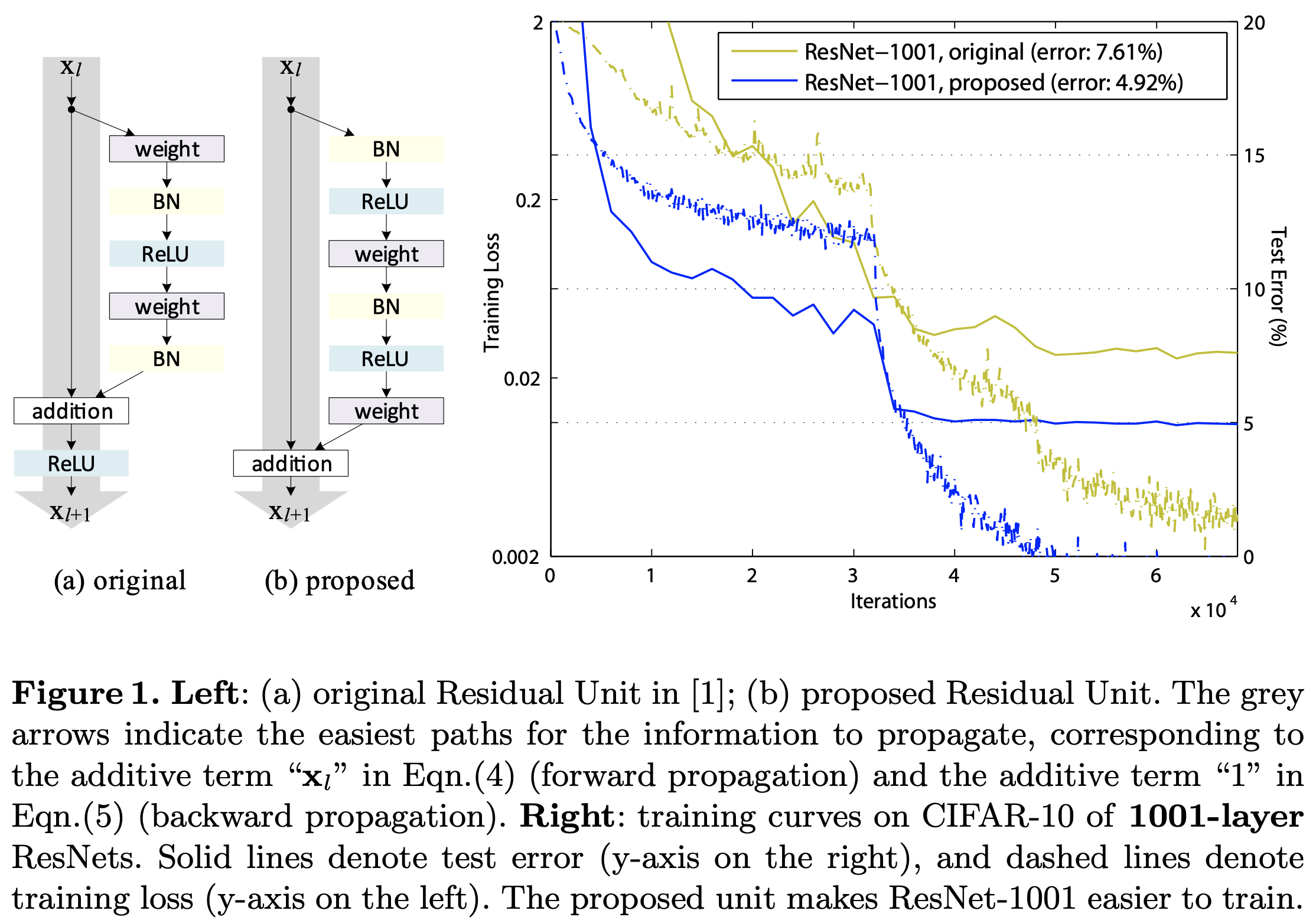
实验结果也证明了其有效性,这个改进使的每个 Conv 层的输入都是预激活并且归一化的信号,从而使得网络更易于训练并且泛化性能也得到提升。
WRN (2016):
ResNeXt (2016):
关于 ResNeXt 其实一句话概括就是:它引入了一个新的维度参数 Cardinality(以下简称 C)。所以 ResNeXt 中的 X 就是 “the next dimension”的意思。一个网络的“深度depth”代表有多少个卷积层,“宽度width”代表卷积层有多少个 Channels,而 ResNeXt 中引入的 C 则是借鉴 Inception 中的“split-transform-merge”的思想,将 ResNet 中 Bottleneck 结构中的 3x3 卷积分成 C 组,具体变化如下:
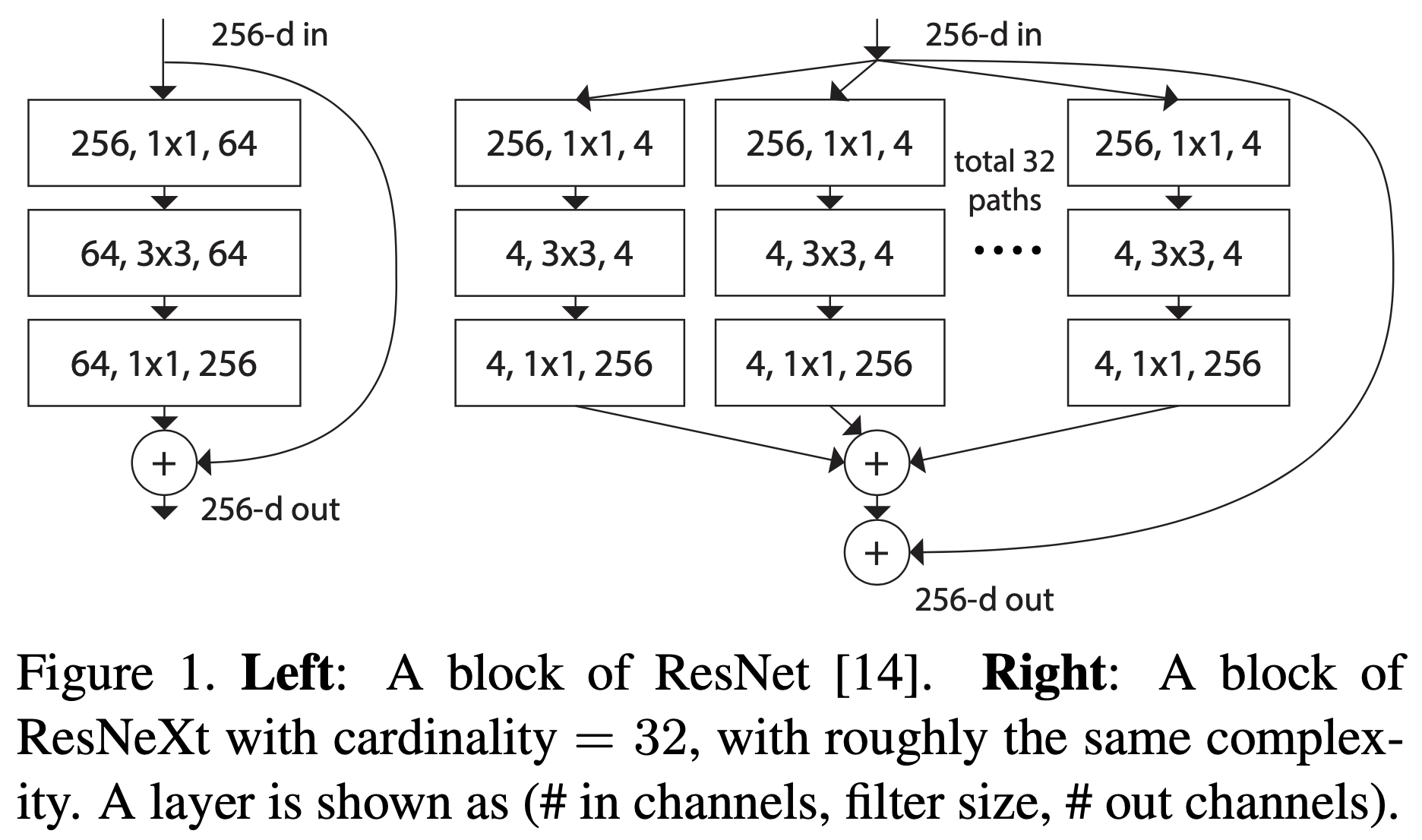
上面两个结构复杂度(时间和空间)几乎相等,在此就不展开计算了。当然 Inception 系列的“split-transform-merge”有各种各样的配方,但 ResNeXt 的作者认为在面对新的任务和不同的数据集时,我们很难知道应该具体怎么选择哪个结构,所以作者采用了最简单的一种结构。下图全面对比一下同等级的 50 系列的模型结构:
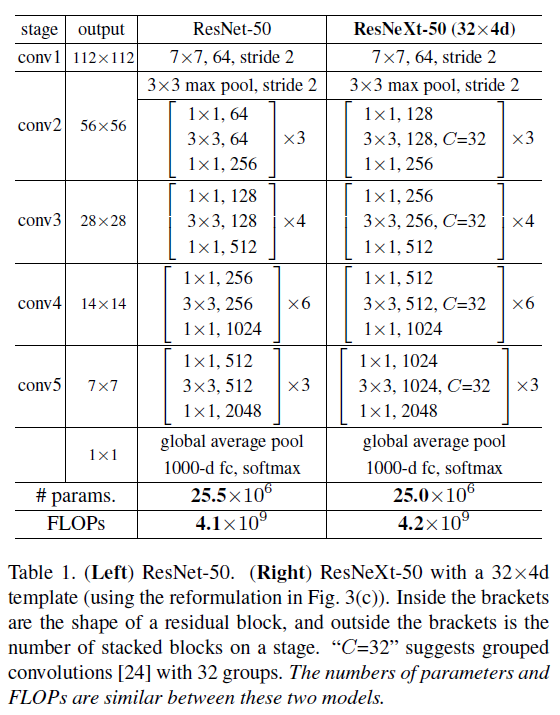
ResNeXt 相比 ResNet 主要多了两个参数:1)Cardinality,C;2)Width of bottleneck,d。其中 C 代表将原来 ResNet 中 3x3 的卷积层拆分成多少组,而 d 代表拆分后每组的宽度是多少。注意 ResNeXt 和 ResNet 中每个 bottleneck 输入输出的 宽度是一致的,但是当中的 3x3 卷积的总宽度不一致。
论文中还阐述了有两种相同的实现形式,如下图所示,而作者最终采用的是 c:
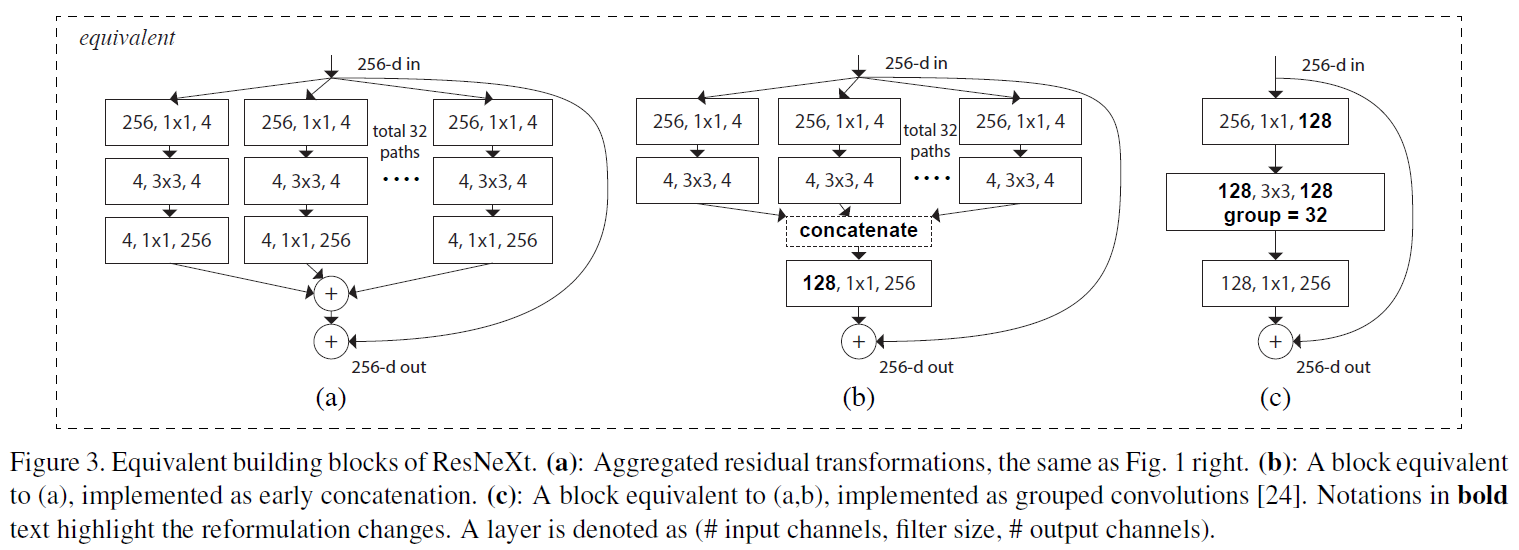
具体WIP。
文章作者用控制变量法通过一些对比试验说明了 ResNeXt 的分组结构的有效性,特别是在 width 和 depth 都到达一定瓶颈时,实验详情和一些结论如下:
分组数 C 越大,提升越大。作者第一个实验先比较了 C 和 d 的组合关系,也就是在保持相同模型 Complexity 的情况下,C 和 d 应该如何搭配如何取舍?结论就是:在模型 Complexity 不变的情况下,C 从 1 增到 32(相应 d 越来越小)的过程中,模型准确率越来越高,最终在 32x4d 时取得最优,并且比同等规模 ResNet 性能好。论文中 Table 2、Table 3 和 Fig. 5 证明了结论。
增大分组数 C 比增大 Depth 和 Width 更能提高模型效果。论文中 Table 4 证明了结论。
即使去掉 Shortcut 连接,ResNeXt 受到的影响也没有 ResNet 那么大。作者对比了 ResNet-50 和 ResNeXt-50-32x4d 分别 with residual 和 without residual 的效果,结果去掉 residual 后者 error 只下降 3.9%,而前者下降 7.3%。
数据集越复杂越大,ResNeXt 提升的效果越明显。作者认为 ResNeXt 在 ImageNet-1K 上到达瓶颈是不是因为模型,而是数据集不够大不够复杂。于是作者又用 ImageNet-5K(数量约为 1K 的 5 倍)来试验,作者用 ImageNet-1K 和 ImageNet-5K 分别来训练 ResNet-50 和 ResNeXt-50-32x4d,对比在不同规模的数据集下 ResNeXt 相比 ResNet 提升多少。1K 上 top-1 和 top-5 分别提升 2.7% 和 1.6%,而在 5K 上 分别提升 3.2% 和 2.6%。论文中 Table 6 和 Fig. 6 证明了结论。
DenseNet (2016)
WIP
SENet (2017)
Attention 机制。其他注意力机制还有 CBAM。
WIP
ShuffleNet (2017)
适用于移动端的轻量级网络。
WIP
MobileNet (2017)
模型压缩,模型加速,模型轻量化,构建小而高效的网络。
WIP
EfficientNet (2019)
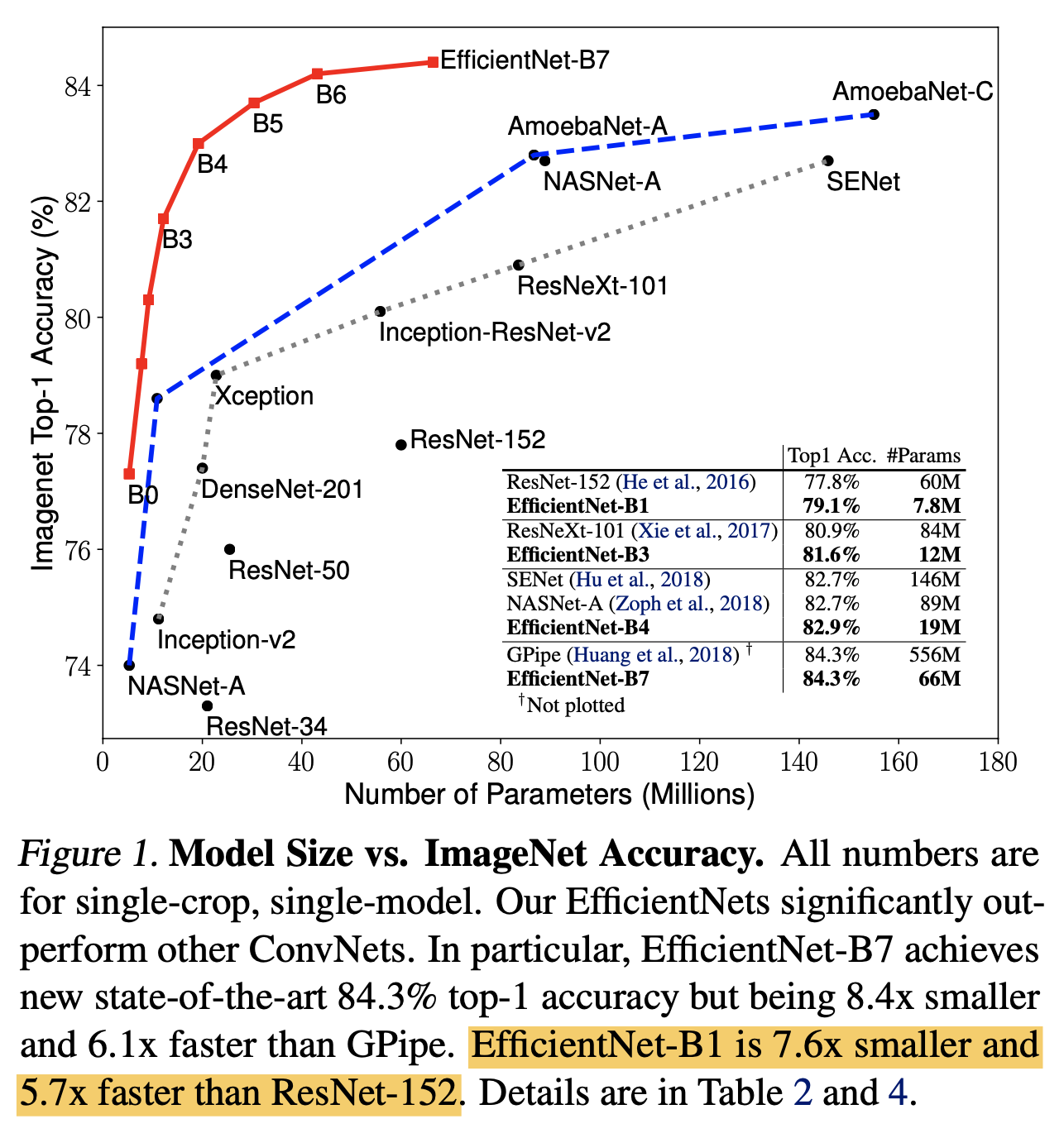
EfficientNet 来自于 2019 年 Google Brain 的一篇论文「EfficientNet:Rethinking Model Scaling for Convolutional Neural Networks」, 这篇文章主要研究的是「模型缩放」的问题。在此之前,最常见的模型缩放研究是单独针对 Depth,Width 和输入图像的 Resolution 这三个维度,如下图中 abcd 所示。例如大名鼎鼎的 ResNet 其实就是通过加深模型 Depth 来提升性能,而 WRN 则是在 Width 维度上进行探索。而在这篇文章中,作者希望系统性地找到一个方法(当然在设计模型的时候你可以随意搭配上述三个维度,但是这样实验工作量会非常大而且最终效果可能不是最优),可以同时兼顾速度和精度地对模型进行缩放。
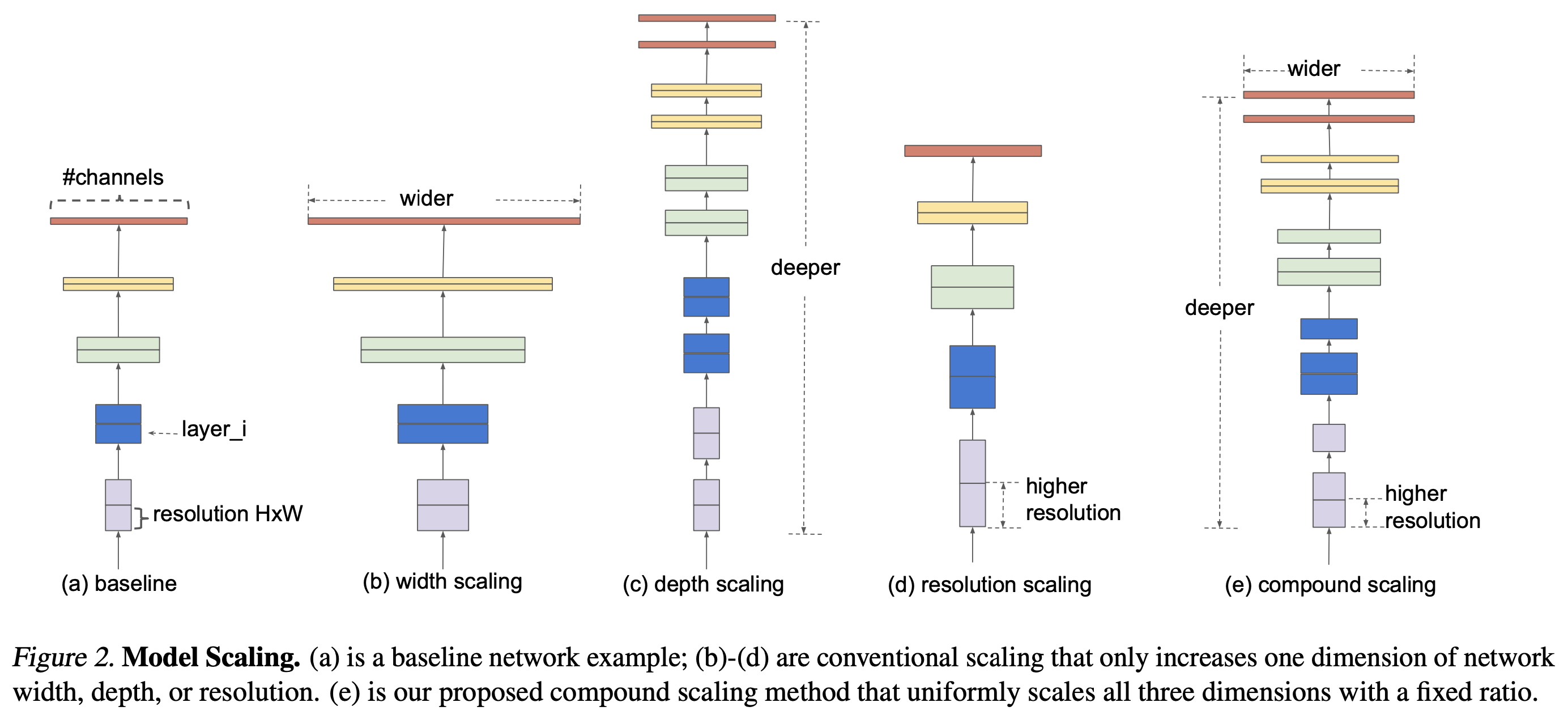
于是作者提出了一个所谓 Compound Scaling Method,如上图 e 所示,该方法可以用一些列的 Scaling Coefficients 来对模型的 width,depth 和 resolution 三个维度进行缩放。
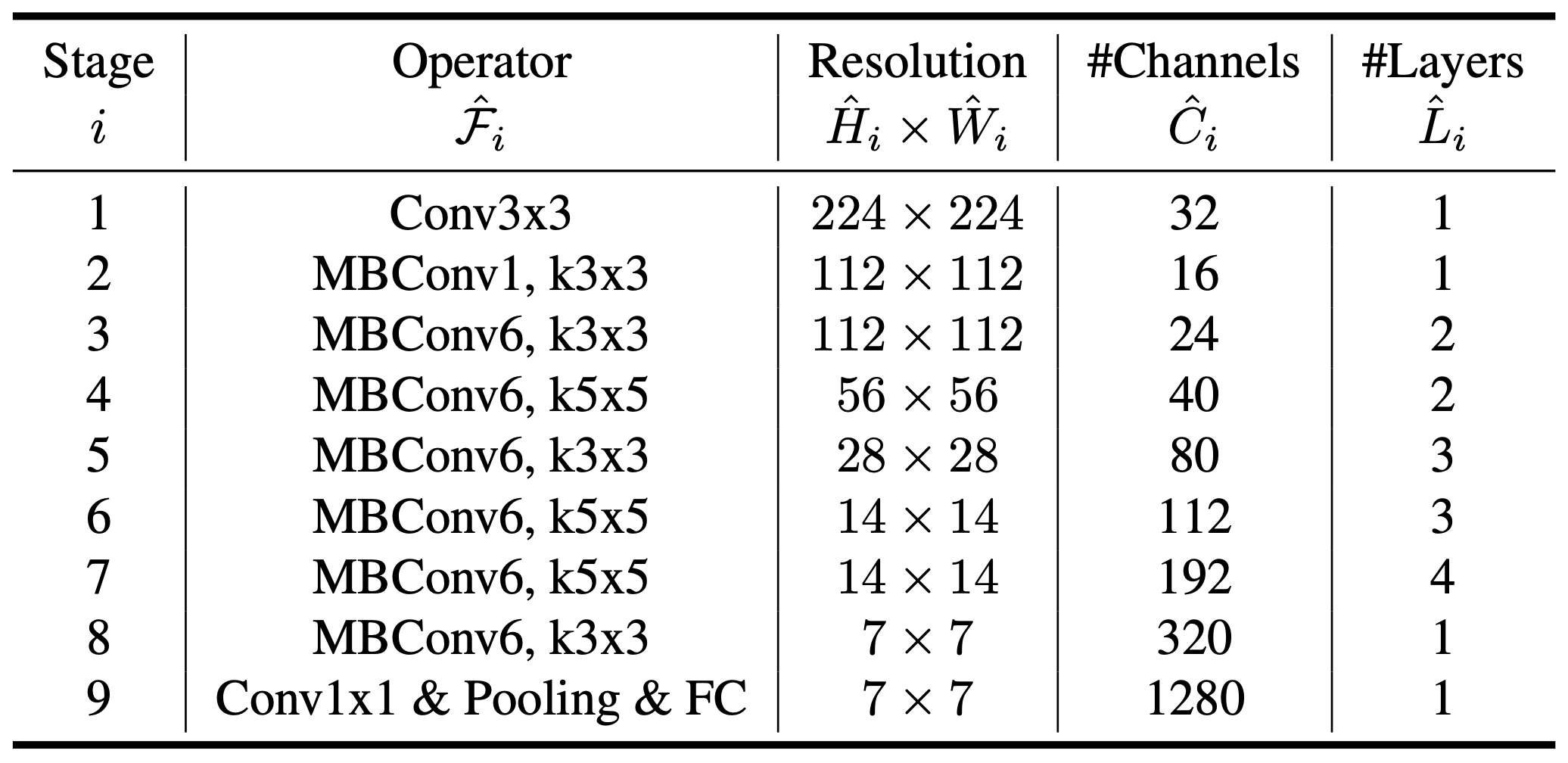
那 Scaling Coefficient是如何得到的?EfficientNet 具体又是怎么设计的?作者提出的是一种「模型缩放的方法」,当然作者在一些之前常见的 ConvNet 上做了验证实验,但为了充分体现这个方法的有效性,作者首先用简单的 Grid Search 的方法,针对模型的 Acc 和 FLOPs,搜索出一个最优的 Baseline 模型 EfficientNet-B0,模型结构其实和 MnasNet 非常相似,如下图所示:
得到 EfficientNet-B0 后,对其进行 Model Scaling,那每个维度的放大倍率是多少,作者设计了一个混合系数 $\mathtt{\Phi}$ 来决定三个维度的放大倍率,具体计算公式如下:
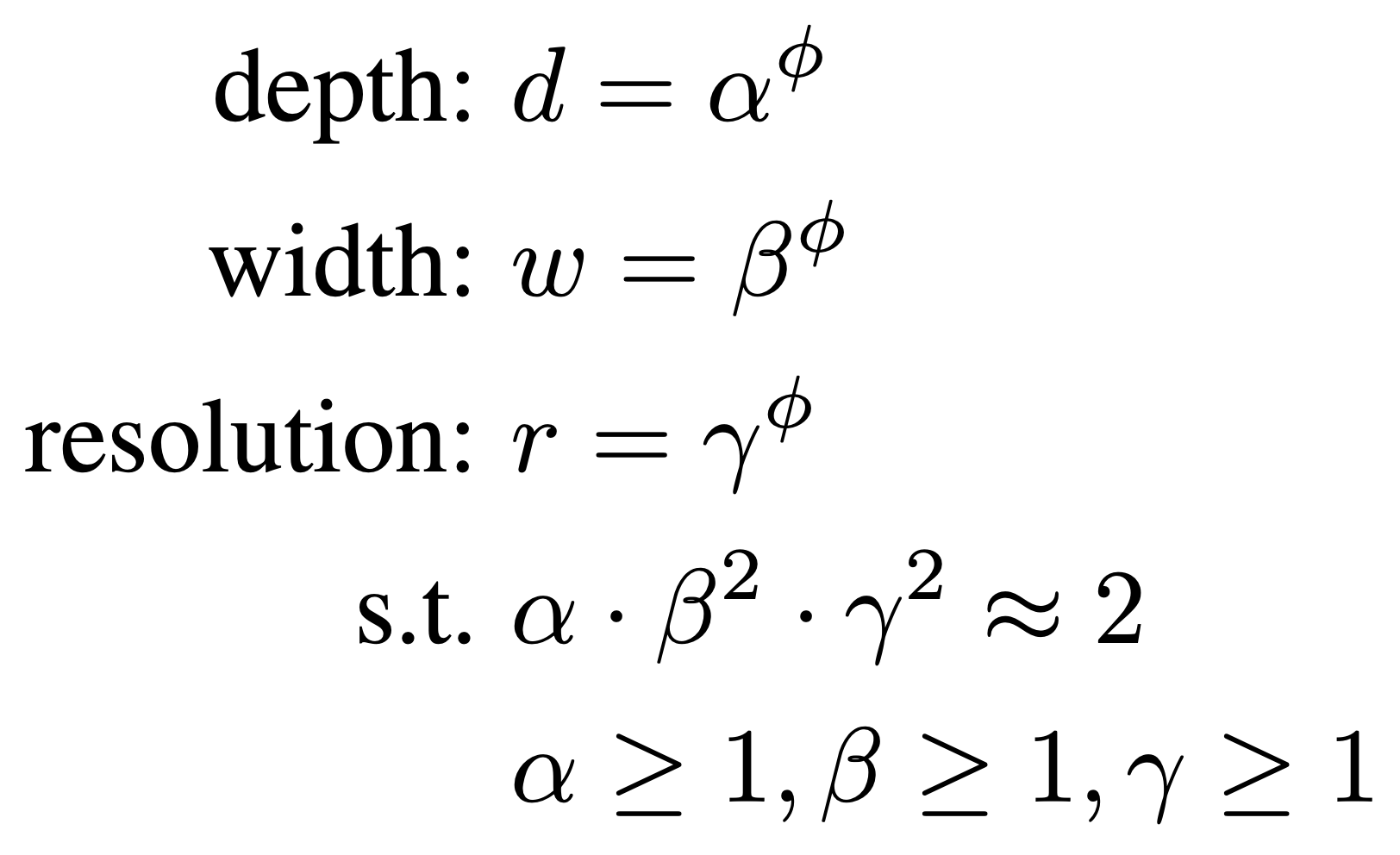
通过一个固定的混合系数 $\mathtt{\Phi}$,我们可以同时放大 depth,width 和 resolution,放大倍率分别为 $\mathtt{\alpha^\Phi}$, $\mathtt{\beta^\Phi}$ 和 $\mathtt{\gamma^\Phi}$,而 $\mathtt{\alpha}$,$\mathtt{\beta}$ 和 $\mathtt{\gamma}$ 为常量,作者通过 Grid Search 发现它们分别为 1.2,1.1 和 1.15 时 EfficientNet-B0 是最佳的。这样限制的原因是对于给定一个新的 $\mathtt{\Phi}$,模型 FLOPs 都会大约增加 $\mathtt{2^\Phi}$。以上,作者得到 EfficientNet-B0 到 B7,并对比了与它们 Top-1/Top-5 Acc 差不多的模型的 Params 和 FLOPs:
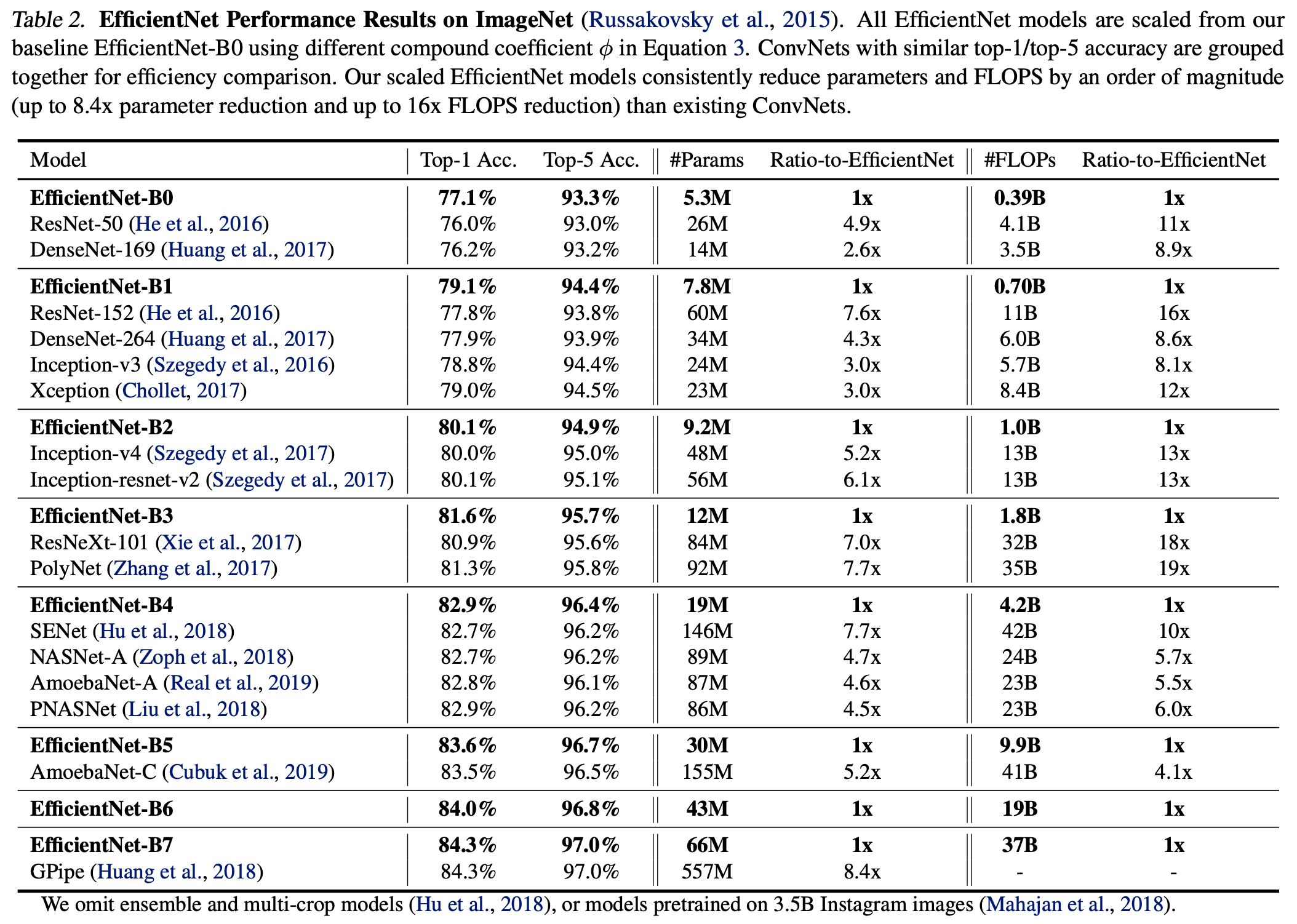
由于 EfficientNet 的有效性,后续也有不少延伸研究,例如 EfficientNet-L2、FixEfficientNet、Noisy Student 等,这一系列在 rwightman 中被称为 MBConvNet Family。EfficientNet-B0 到 B7 的 Pytorch 可参考 lukemales,使用方法也非常简单:
首先 pip 安装 efficientnet_pytorch 包:
pip install efficientnet_pytorch
然后调用模型方法为:
from efficientnet_pytorch import EfficientNet model = EfficientNet.from_pretrained('efficientnet-b0') # pretrained model = EfficientNet.from_name('efficientnet-b0') # from scratch
Res2Net (2019)
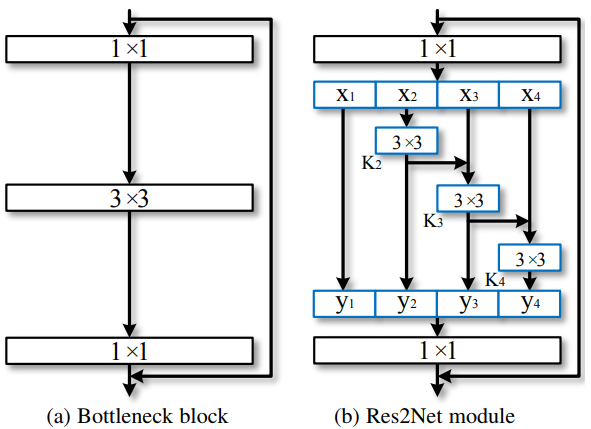

Res2Net 旨在提升网络多尺度特征的表达能力。
WIP

 浙公网安备 33010602011771号
浙公网安备 33010602011771号