英伟达GPU不完全指北
1. GPU 概述(GPU 和 CPU 的设计区别):
CPU 设计的时候是为了满足很强的通用性,处理各种不同的数据类型,特别典型的就是浮点运算,这个需要消耗比较多的时钟周期,不仅仅是数据运算,还有逻辑运算,基于这样的需求,CPU 设计的内部结构非常复杂,这可以类比一个国家的皇帝,需要处理大臣们的奏折,也需要处理很多后宫的事情,计算机普及到后来,大家对于图形显示的要求越来越高,特别是 3D 建模这种事情,CPU 不能丢下自己的工作去干这种负荷高的工作,所以英伟达觉得可以有机可乘,就出现了 GPU。
GPU 设计出来的目的就比较单纯,就好像我需要把一块砖头搬到 10 楼,不管你用一个皇帝来搬砖,还是很多小孩子当苦力来搬砖,都是需要从 1 楼走到 10 楼,GPU 不需要跟太多其他人交涉,它需要干的事比较纯粹,单一繁重。
CPU 是一块超大规模的集成电路,主要逻辑架构包括控制单元(Control)、运算单元(ALU)、高速缓冲存储器(Cache),以及实现它们之间联系的数据(Data),控制及状态的总线(BUS)。简单说,就是计算单元 ALU、控制单元 Control 和存储单元 Cache。
CPU 遵循的是冯诺伊曼架构,其核心是:存储程序/数据、串行顺序执行。因此 CPU 的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以 CPU 在进行大规模并行计算方面受到限制,相对而言更擅长于处理逻辑控制。
GPU 是一种由大量运算单元组成的大规模并行计算架构,早先由 CPU 中分出来专门用于处理图像并行计算数据,专为同时处理多重并行计算任务而设计。
GPU 中也包含基本的计算单元 ALU、控制单元 Control 和存储单元 Cache,但 GPU 和 CPU 的架构有很大不同:
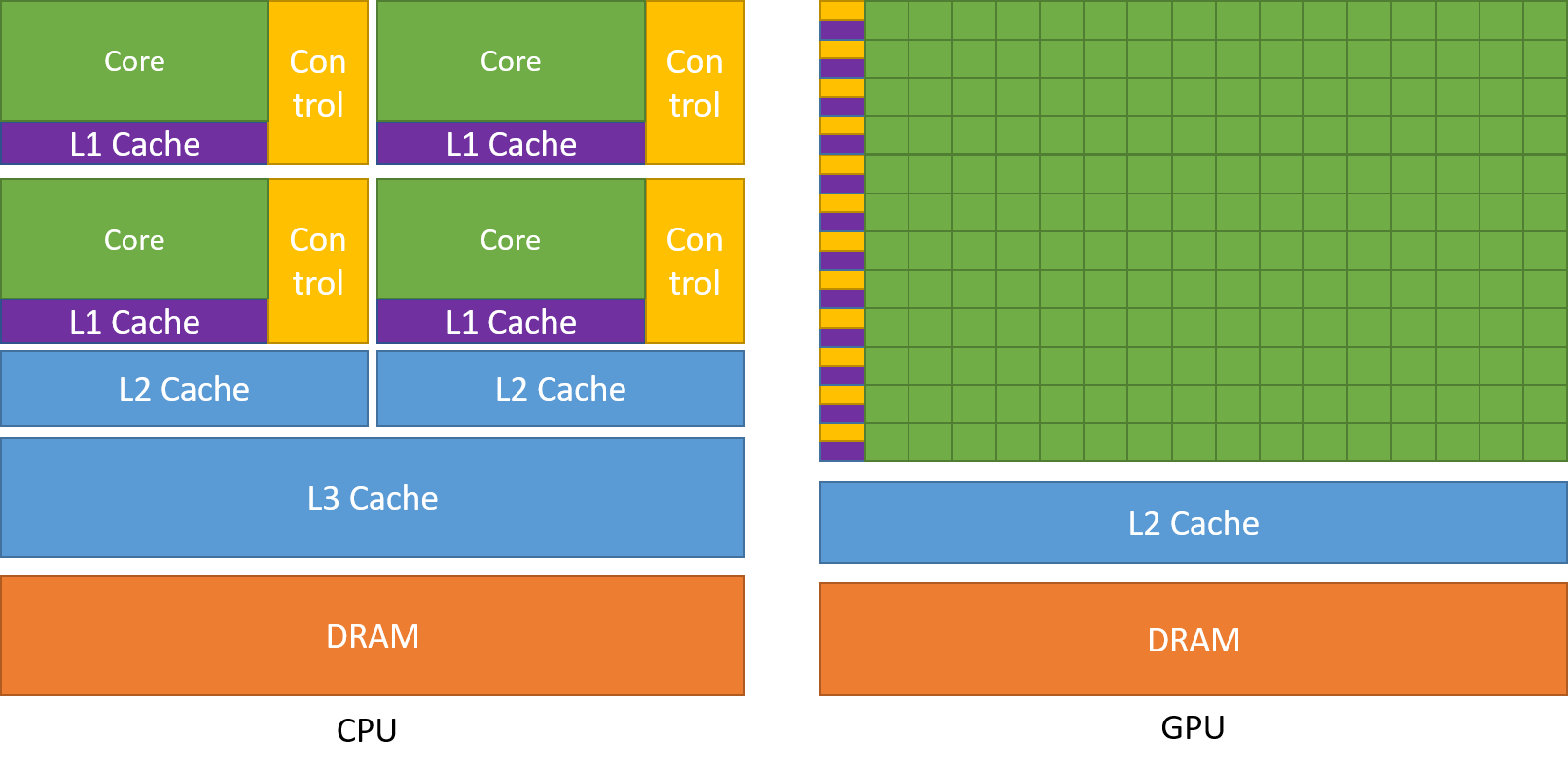
其中绿色的为 ALU,紫色和蓝色为 Cache,黄色为 Control。
从硬件架构分析来看,CPU 和 GPU 似乎很像,都有内存、Cache、ALU、Control,它们的区别如下:
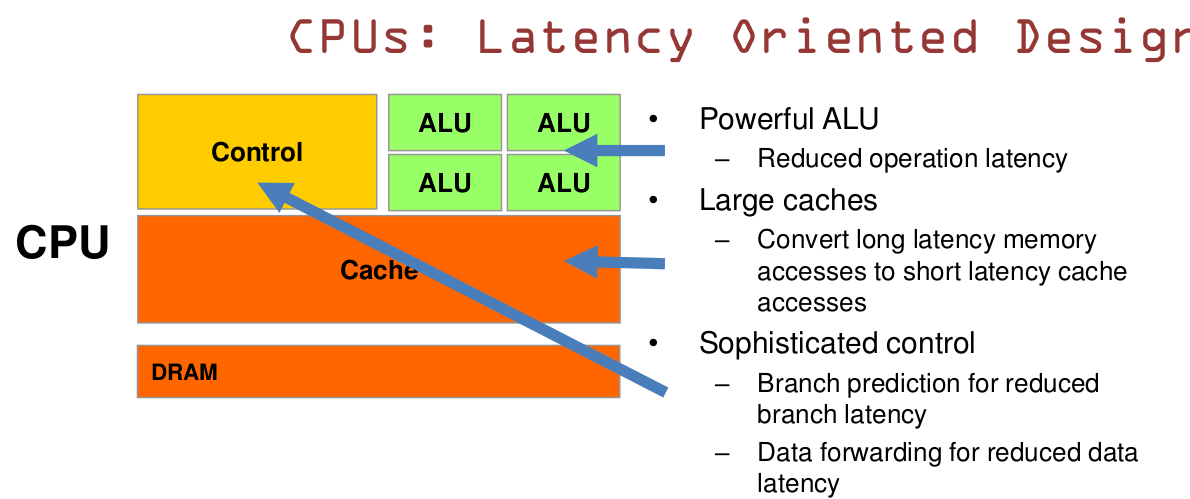
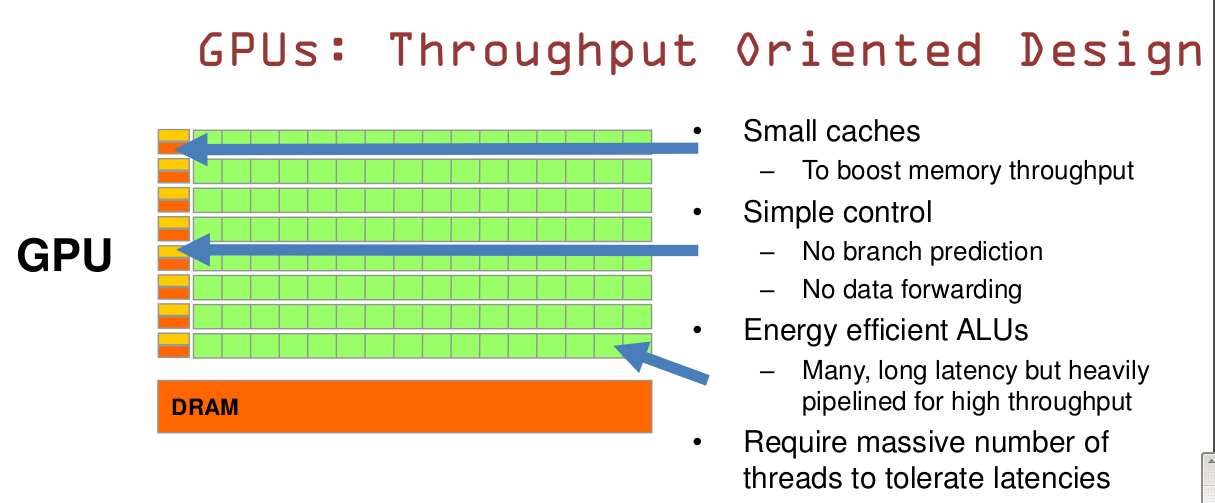
CPU 有 70% 的晶体管用来构建 Cache 和一部分控制单元,计算单元相对少,适合逻辑控制运算。而 GPU 是大部分晶体管用来构建计算单元,但只能进行低复杂度的运算,适合大规模并行计算。
总而言之,CPU 是基于低延迟的设计,GPU 是基于大的吞吐量设计。
2. 英伟达 GPU 的命名:
我们日常提及 GPU 和显卡时,经常将两者混为一谈,GPU 是显卡(Graphics Card,Video Card,Display Card)的最核心部件,显卡除了 GPU 外,还有扇热器、通讯元件、与主板和显示器连接的各类插槽。
从事深度学习领域一般和 Nvidia 的 gpu 接触得比较多,N 卡的命名大致有 3 个层次:
- GPU 架构(Micro Architecture):表示 GPU 在芯片设计层面上的不同处理方式,包括计算单元(SIMD)的个数、有无 L1 和 L2 缓存,是否有双精度 FP64 支持等。按时间顺序:Tesla(08), Fermi(10), Kepler(12), Maxwell(14), Pascal(16), Volta(17), Turing(18), Ampere(20),均用著名科学家的名字来命名;
- 显卡系列:GeForce(消费级,用于家庭娱乐),Tesla(专业级,用于大规模并联电脑运算,不提供视频输出),Quadro(专业级,用于专业绘图设计);
- 芯片型号:1)对于 Tesla 系列,如 P100,K80,T4 等,其中第一个字母表示架构名称,P:Pascal,K:Kepler,T:Turing,从 Pascal 到 Ampere,有:P4/P6/P40/P100,V100,T4,A40/A100,其中推理 gpu 为:P4 & P40 -> T4;2)而对于 GeForce 系列,按时间顺序大致可分为:GeForce 600 及更早(9800 GTX,GTX 690 等)、GeForce 700(GTX Titan Z、GTX Titan Black、GTX Titan、GTX 780ti)、GeForce 900(GTX Titan X、GTX 980ti)、GeForce 10(Titan V、Titan Xp、GTX 1080ti、Titan X)、GeForce 20(Titan RTX、RTX 2080ti)、GeForce 30(RTX 3090);
3. Nvidia历代GPU架构:
Tesla(2008) -> Fermi(2010) -> Kepler(2012) -> Maxwell(2014) -> Pascal(2016) -> Volta(2017) -> Turing(2018) -> Ampere(2020)
4. GPU 数据流动路径:
假设现在有一批图片集放在硬盘当中,待读取进内存送入 GPU 进行运算,那么一般会经历以下流程:
1)CPU 发出读取的指令,从硬盘中找到图片数据,并存到内存中;2)CPU 从内存中读取一批数据,转化为 numpy array,并作数据预处理/增强操作,如翻转、平移、颜色变换等,处理完毕后送回内存;3)CPU 内存(内存)和 GPU 内存(显存)各开辟一块缓冲区,内存中的一个 batch 的数据通过 PCI-e 通道传输到显存当中;4)GPU 核心从显存中获取数据并进行计算,计算结果返回至显存中;5)计算好的结果将从显存经过 PCI-e 通道返回到内存;
所以这 5 个步骤涉及到几个影响数据传输速度的环节:1)硬盘读取速度;2)PCI-e 传输速度;3)内存读写速度,即内存频率;4)CPU 频率;
1)硬盘:在深度学习模型进行训练前,往往需要从本地硬盘读取数据到内存,并做一些预处理,硬盘读取速度会极大影响训练的效率。如果读取速度快、送进 GPU 的数据多,GPU 的利用率就越高。目前市售硬盘有机械硬盘和固态硬盘两种,固态差不多是机械的 7 倍。
2)PCI-e:内存中的数据通过 PCI-e 总线传输到 GPU 显存当中,如果是单显卡机器,大部分都能工作在 PCI-e3.0x16 带宽下,此时带宽为 15.754GB/s,当一个 batch 的数据(假设 tensor shape:(32,224,224,3),float32 size=32x224x224x3x8=0.0385GB)通过 PCI-e3.0x16 传输至 GPU 时,理论上所需要时间为:2.44ms。但目前市售的桌面级 cpu(以英特尔酷睿系列的 i7 cpu 为例),CPU 直连的 PCIe 通道一般只有 16 条,如果插了双 GPU,那么只能工作在 PCIe 3.0 x8 带宽上(如果你的主板支持的话),那么理论延迟时间加倍。因此一般多卡机器如 4 卡、8 卡、10 卡,均最低使用双路工作站或服务器级别的 CPU,如英特尔至强系列,此系列单 U 最低都能提供 40 条 PCIe 总线。但这些延迟时间相比起 GPU 计算、IO 等这些时间来说,其实影响甚微,加上还有软件层面的速度优化,这个延迟可以忽略不计,因此装机时不必太多纠结于 PCIe 通道数上。
3)CPU 频率:由于所有的数据预处理操作都在 CPU 上执行,因此 CPU 频率越高,生成图片的速度就越快,当机器拥有多显卡时,CPU 喂数据的速度会成为整个系统的瓶颈。
4)内存频率:即使内存频率低至 1866MHz,带宽已经达到 15GB/s,已经接近 PCI-e3.0x16 的带宽(15.75GB/s),也就是说内存传输数据到显存的时候也能跑满 PCI-e3.0x16 的带宽,因此内存带宽远远不是瓶颈。
5. Nvidia Pascal - Ampere 框架 GPU 主要参数对比:
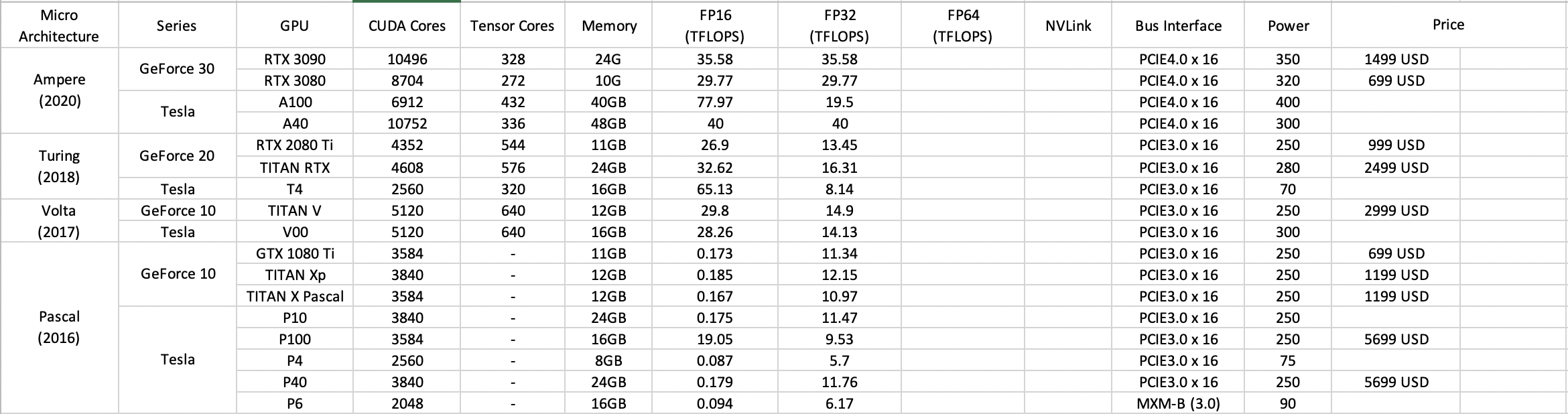
PS:
- CUDA Cores:WIP
- Tensor Core:提供混合精度(半精度+单精度)计算,提高运算速度,Tensor Core 是一种新型的处理核心,它执行一种专门的矩阵数学运算,适用于深度学习和某些类型的 HPC,Tensor Core 执行融合乘法加法,其中两个 4x4 FP16 矩阵相乘,然后将结果添加到 4x4 FP16 或 FP32 矩阵中,最终输出新的 4x4 FP16 或 FP32 矩阵,NVIDIA 将 Tensor Core 进行的这种运算称为混合精度数学,因为输入矩阵的精度为半精度,但乘积可以达到完全精度。碰巧的是,Tensor Core 所做的这种运算在深度学习训练和推理中很常见,Tensor Core 可以让 tensor 的计算速度大幅度上升 30%-100%。使用混合精度主要有两方面的好处:1)FP16 需要更少的显存,因此更容易训练和部署大型神经网络;2)数学运算在降低精度的 Tensor cores 运行得更快。而实际上大多数情况下我们并不需要 FP32,FP16 便可以很好地表示大多数权重和梯度,在工程化代码中我们可以结合 Nvidia 的 apex 库来使用混合精度运算,在选择 GPU 的时候,如果选择了没有Tensor Core 的 GPU,即使用了 apex,最终也是按单精度计算的,起不到训练提速的效果;
- 显存带宽(Memory Bandwidth):解释1)显存带宽是指显示芯片与显存之间的数据传输速率。据我的观察,如果我们在做图像方面的深度学习研究的话,一个具有较大显存带宽的 GPU 允许你在设置较大的 batch_size,也就是你可以同时拿出来较多的数据来一起训练;解释2)显存带宽=显存位宽x显存频率/8,显存带宽可以看作是显存位宽和显存频率的综合指标,指的是单为时间内数据的吞吐量。看显卡的人不要被奸商忽悠了。有的人告诉你这个显存位宽有多高多高,但总带宽很低。打个比方,显存位宽就是一条马路的宽度,越宽表示可以并排行驶的车辆就越多,显存频率就是汽车的速度,越高就表示车越快。那么带宽就是单位时间内这条街道所通过汽车的总数量。所以记住,看显卡不要只看位宽,一定要看带宽。不过目前的gpu几乎没有卡在带宽上的,基本都够用。显存带宽=总线条数 * 显存数据频率 * 显存位宽(显卡瞬间处理数据的吞吐量) / 8;
- GPU工作频率:WIP;
- 显存容量(VRAM):显存容量是显卡上显存的容量数,显存容量决定着显存临时存储数据的多少。还是举做图像方面的研究的例子,一个较大的显存容量能让你一次性把更多的训练图片读入内存中,甚至可以将整个数据集直接存入一个变量里面,感觉比写个像 tfrecord 这种队列或者堆栈去慢慢读数据要爽的多,至少可以解决 shuffle 不充分的问题嘛~
- 半精度、单精度、双精度计算性能,FP16/FP32/FP64 Computing:xx TFLOPS:对于深度学习来说,单精度的运算最常见,但近来混合精度计算越来越受欢迎,所以半精度算力也越来越重要,而双精度一般在 HPC 应用中常见,所以基本上可以忽略;
- GPU-GPU 带宽(NVLink or PCI-e):xx GB/s:NVLink 是英伟达在 2014 年推出的 GPU 互联技术,由于以往的多卡环境中,GPU 与其他 GPU 通信的时候,必须先通过 PCI-e 把数据传输到 CPU,再由 CPU 传输到其他 GPU,整体计算速度受限于 PCI-e 的速度,NVLink 的出现正是为了解决这个问题:
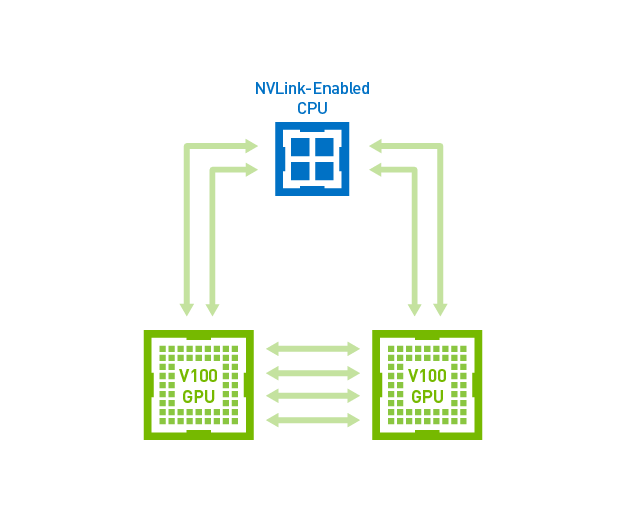
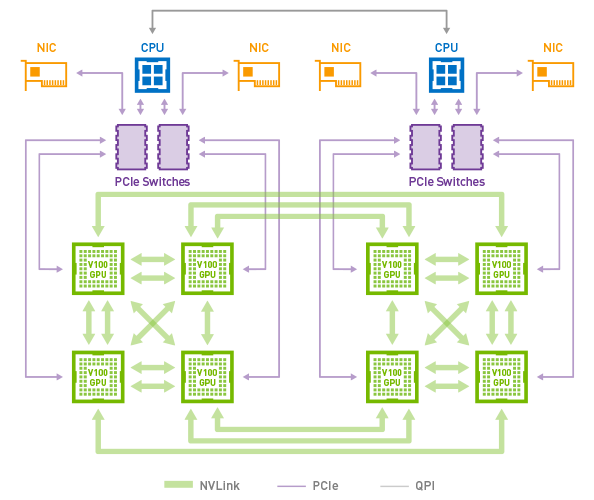
第一张图,有了 NVLink,GPU 与 GPU 之间的通信不需要再通过 CPU,直接通过 NVLink 通信,双向带宽高达 100GB/s(NVLink 2.0)。第二张图是单服务器双路 CPU 及 8 路 GPU 的架构,两个 CPU 分别对应 4 个 GPU,当中一组 GPU 需要向另一组 GPU 进行通信时,以往同样只能先通过 PCI-e 传输到CPU,然后再通过 QPI 通道(带宽为 25.6GB/s)传输到另一个 CPU,最后再通过 PCI-e 送进另一组 GPU。而 NVLink 支持跨 CPU 节点的直接通信,每个 V100 有 6 条 NVLink 通道,总带宽高达 300GB/s;
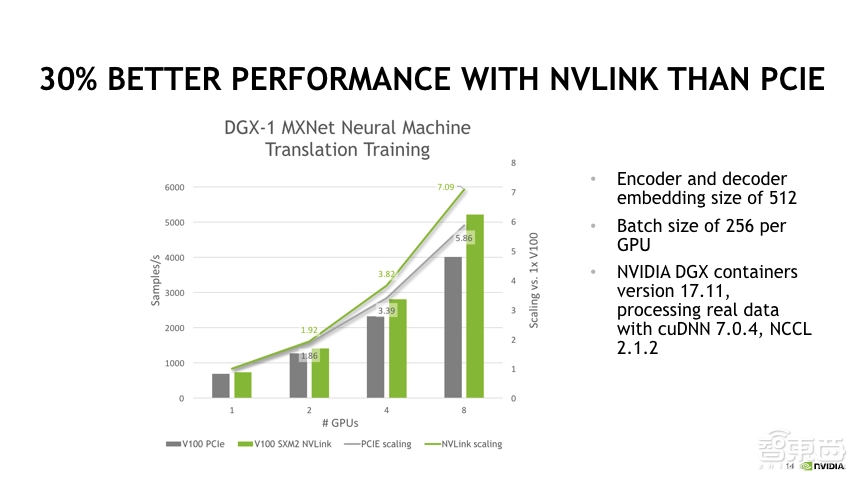
结论:
1. GPU 越多,NVLink 优势越明显;
2. Tensor Core:Tensor Core 可以进行混合精度计算,可以让 tensor 的计算速度大幅度上升30%-100%;
6. Nvidia GPU 的选择:
对于深度学习的研究者来说,一般选择 Tesla 或 GeForce 系列的 GPU,一般来说 GeForce 的性价比比较高,虽然 GeForce 定位为消费级,但是它在深度学习上的性能表现也很不错,很多人都用来做训练、推理,特别是单张 GPU 的性能和 Tesla 系列的差别越来越小,例如早已停产的 GTX 1080 和 P4 参数差不多,性能甚至更好一些,但是价格前者只有后者的 1/3。既然这样,那 Nvidia 为什么还要推出 Tesla 系列呢?主要原因有以下四个:
1)虽然单卡性能相当,但是 Tesla 系列 GPU 在集群部署下性能优势明显,集群 GPU 数量越多,优势越大,所以一般企业级大 GPU 集群才需要用到 Tesla 系列,而 Nvidia 官方也禁止使用 GeForce 系列 GPU 用于深度学习训练,一经使用,自动过保;
2)Tesla 系列更适合大规模部署,因为功耗低,功耗优化明显,例如 P4 只有 75W,而 1080 则高达 175W,大规模部署情况下功耗成本小,且 Tesla 系列都是被动散热,不提供风扇,更适合于机房服务器统一散热的恒温环境。
3)GeForce 消费级 GPU 更新换代快,一般一两年,可能你产品还没做出来,这个 GPU 已经停产了,无法再采购。
4)对于特殊的研发要求,Tesla 系列往往会提供一个顶配的超高配置的型号,提供给不差钱的研发需求。
7. References:
[1] https://www.cnblogs.com/xiaozhi_5638/p/10923351.html
[2] https://www.cnblogs.com/timlly/p/11471507.html
[3] https://zhuanlan.zhihu.com/p/42749496
[4] https://blog.csdn.net/iamuw/article/details/107845679
[5] https://www.techpowerup.com/gpu-specs/
[6] https://www.cnblogs.com/timlly/p/11471507.html#445-cpu-gpu数据流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号