
java 框架-缓冲-Redis 2Jedis操作
https://www.cnblogs.com/wlandwl/p/redis.html
1.Redis简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
2.Redis优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
3.linux环境下安装Redis
1.下载地址:http://redis.io/download,下载最新版本的linux版本Redis。
2.本教程使用的最新文档版本为 4.0.6,下载文件后,上传到linux服务器上面,并解压安装。
操作指令为:$ tar xzf redis-4.0.6.tar.gz $ cd redis-4.0.6 $ make
3.make成功执行完后 redis- 4.0.6目录会生成src 目录,在一次执行命令:$ make install

4.启动redis服务,使用默认配置方式启动:进入到redis-4.0.6/src目录,执行启动命令:redis-server
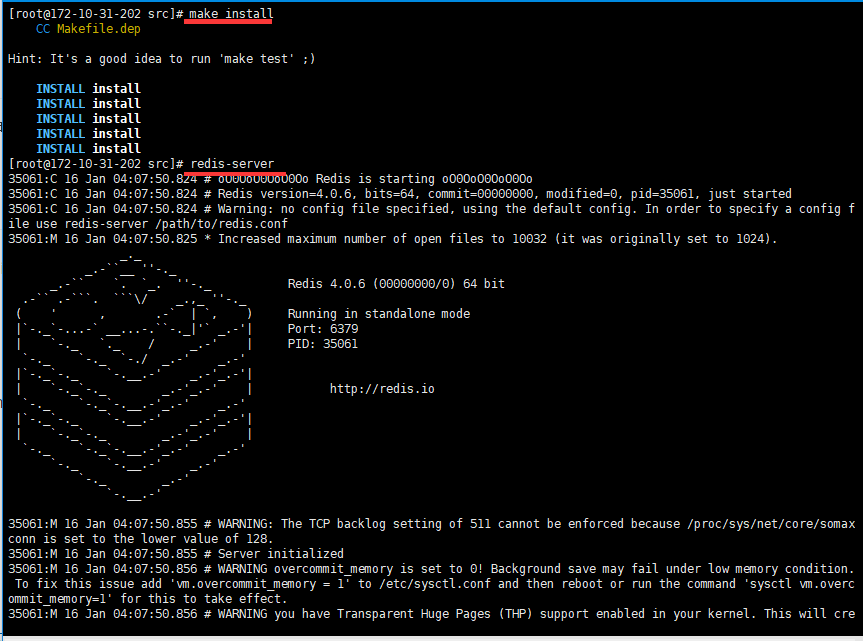
注意:这里直接执行Redis-server 启动的Redis服务,是在前台直接运行的(效果如上图),也就是说,执行完该命令后,如果Linux关闭当前会话,则Redis服务也随即关闭。正常情况下,启动Redis服务需要从后台启动,并且指定启动配置文件。
后台启动redis服务
- 首先编辑conf文件,将daemonize属性改为yes(表明需要在后台运行),并指定ip地址,开放redis端口号:6379。操作指令为:cd redis-4.0.6/ vi redis.conf
- 再次启动redis服务,并指定启动服务配置文件: redis-server /usr/local/redis/etc/redis.conf
- 在防火墙中开放端口:6379

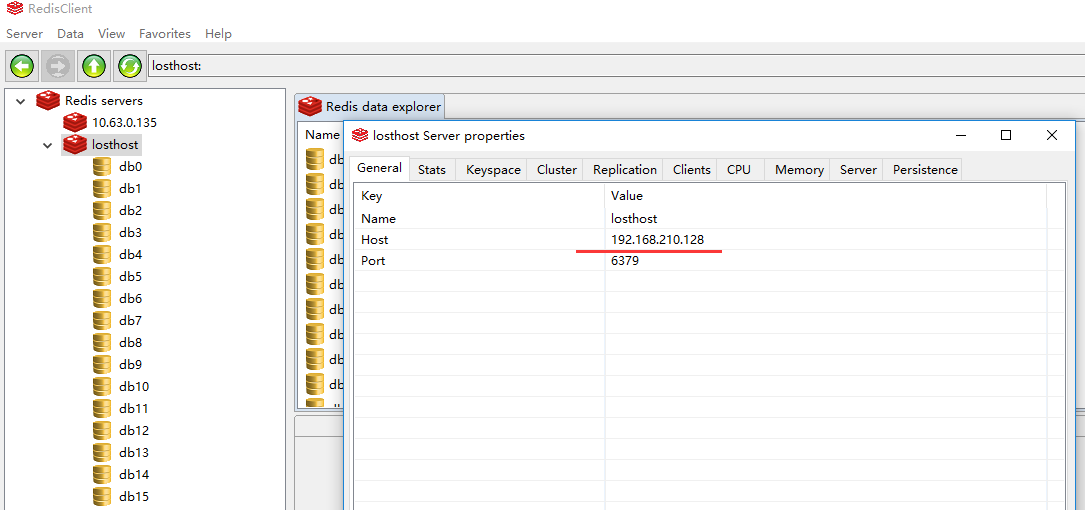
在本地电脑上,安装一个redis客户端连接工具,如:redisclient-win32.x86.1.5。利用连接工具可方便查看redis中设置的缓存数据,连接如图所示:
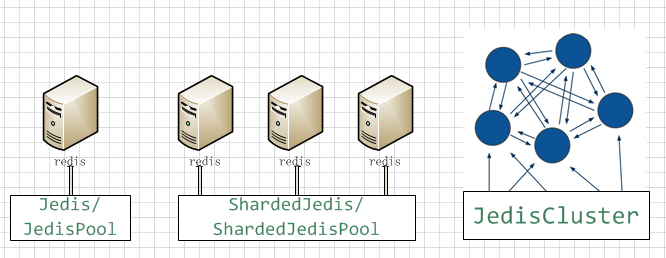
4.jedis操作Redis介绍
jedis 是 Redis 官方首选的 Java 客户端开发包,上手比较容易。jedis提供了以下三种操作方式:
- 单机单连接方式:此方式仅建议用于开发环境做调试用。
- 单机连接池方式:此方式适用于仅使用单个Redis实例的场景
- 多机分布式+连接池方式:此方式适用规模较大的系统,往往会有多个Redis实例做负载均衡。并且还实现主从备份,当主实例发生故障时,切换至从实例提供服务。
- redis3.0推出JedisCluster。使用JedisCluster连接使用这种方式时,默认Redis已经进行了集群处理,JedisCluster即针对整个集群的连接.
jedis操作redis模式
(1)事务方式(Transactions)
所谓事务,即一个连续操作,是否执行是一个事务,要么完成,要么失败,没有中间状态。而redis的事务很简单,他主要目的是保障,一个client发起的事务中的命令可以连续的执行,而中间不会插入其他client的命令,也就是事务的连贯性。
测试截图

(2)管道(Pipelining)
管道是一种两个进程之间单向通信的机制。那再redis中,为何要使用管道呢?有时候,需要采用异步的方式,一次发送多个指令,并且,不同步等待其返回结果。这样可以取得非常好的执行效率。管道模式测试代码:

@Test
public void jedisPipelined() {
Jedis jedis = new Jedis("192.168.210.128", 6379);
Pipeline pipeline = jedis.pipelined();
long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
pipeline.set("p" + i, "p" + i);
}
List<Object> results = pipeline.syncAndReturnAll();
long end = System.currentTimeMillis();
System.out.println("Pipelined SET: " + ((end - start)/1000.0) + " seconds");
jedis.disconnect();
}
注意:事务和管道都是异步模式。在事务和管道中不能同步查询结果。如下代码操作为非法操作:
Transaction tx = jedis.multi();
for (int i = 0; i < 100000; i++) {
tx.set("t" + i, "t" + i);
}
System.out.println(tx.get("t1000").get()); //不允许
List<Object> results = tx.exec();
(3)管道中调用事务
在某种需求下,需要异步执行命令,但是,又希望多个命令是有连续的,所以可采用管道加事务的调用方式。jedis是支持在管道中调用事务的。
(4)分布式直连同步调用与分布式连接池同步调用
这个是分布式直接连接,并且是同步调用,每步执行都返回执行结果。如果,分布式调用代码是运行在线程中,那么分布式直连同步调用方式就不合适了,因为直连方式是非线程安全的,这个时候需使用选择连接池调用。案例代码:
//分布式直接链接并同步调用
public void jedisShardNormal() {
List<JedisShardInfo> shards = Arrays.asList(
new JedisShardInfo("localhost",6379),
new JedisShardInfo("localhost",6380));
ShardedJedis sharding = new ShardedJedis(shards);
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
String result = sharding.set("sn" + i, "n" + i);
}
long end = System.currentTimeMillis();
System.out.println("Simple@Sharing SET: " + ((end - start)/1000.0) + " seconds");
sharding.disconnect();
}
//分布式结合线程池使用
public void jedisShardSimplePool() {
List<JedisShardInfo> shards = Arrays.asList(
new JedisShardInfo("localhost",6379),
new JedisShardInfo("localhost",6380));
ShardedJedisPool pool = new ShardedJedisPool(new JedisPoolConfig(), shards);
ShardedJedis one = pool.getResource();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
String result = one.set("spn" + i, "n" + i);
}
long end = System.currentTimeMillis();
pool.returnResource(one);
System.out.println("Simple@Pool SET: " + ((end - start)/1000.0) + " seconds");
pool.destroy();
}
(5)分布式直连异步调用与分布式连接池异步调用
操作与同步相对,案例代码如下:
//分布式连接池异步调用测试 线程池使用
public void jedisShardPipelinedPool() {
List<JedisShardInfo> shards = Arrays.asList(
new JedisShardInfo("localhost",6379),
new JedisShardInfo("localhost",6380));
ShardedJedisPool pool = new ShardedJedisPool(new JedisPoolConfig(), shards);
ShardedJedis one = pool.getResource();
ShardedJedisPipeline pipeline = one.pipelined();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
pipeline.set("sppn" + i, "n" + i);
}
List<Object> results = pipeline.syncAndReturnAll();
long end = System.currentTimeMillis();
pool.returnResource(one);
System.out.println("Pipelined@Pool SET: " + ((end - start)/1000.0) + " seconds");
pool.destroy();
}
(6)安全线程连接池(JedisPool)
注意Jedis对象并不是线程安全的,在多线程下使用同一个Jedis对象会出现并发问题。为了避免每次使用Jedis对象时都需要重新构建,Jedis提供了JedisPool。JedisPool是基于Commons Pool 2实现的一个线程安全的连接池。
//线程池模式使用测试:
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10);
JedisPool pool = new JedisPool(jedisPoolConfig, "localhost", 6379);
Jedis jedis = null;
try{
jedis = pool.getResource();
jedis.set("pooledJedis", "hello jedis pool!");
System.out.println(jedis.get("pooledJedis"));
}catch(Exception e){
e.printStackTrace();
}finally {
//还回pool中
if(jedis != null){
jedis.close();
}
}
pool.close();
(7)多机分布式集合连接池使用
此方式适用规模较大的系统,往往会有多个Redis实例做负载均衡。并且还实现主从备份,当主实例发生故障时,切换至从备用实例提供服务。如服务器1挂掉后,可用服务器2继续支撑redis缓存处理。测试代码:
**
* Description: 多机分布式+连接池方式:
* Copyright: 2018 CSNT. All rights reserved.
* Company:CSNT
*
* @author wangling
* @version 1.0
*/
public class MultipleJedisPoolTest {
static JedisPoolConfig config;
static ShardedJedisPool sharedJedisPool;
static {
// 生成多机连接List
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();
shards.add( new JedisShardInfo("127.0.0.1", 6379) );
shards.add( new JedisShardInfo("192.168.210.128", 6379) );
// 初始化连接池配置对象
config = new JedisPoolConfig();
config.setMaxIdle(10);
config.setMaxTotal(30);
config.setMaxWaitMillis(2*1000);
// 实例化连接池
sharedJedisPool = new ShardedJedisPool(config, shards);
}
/**
* @param args
*/
public static void main(String[] args) {
// 从连接池获取Jedis连接
ShardedJedis shardedJedisConn = sharedJedisPool.getResource();
shardedJedisConn.set("Lemon", "Hello,my name is Lemon");
System.out.println(shardedJedisConn.get("Lemon"));
// 释放连接
close(shardedJedisConn, sharedJedisPool);
}
private static void close(ShardedJedis shardedJedis,ShardedJedisPool sharedJedisPool){
if(shardedJedis!=null &&sharedJedisPool!=null){
sharedJedisPool.returnResource(shardedJedis);
}
if(sharedJedisPool!=null){
sharedJedisPool.destroy();
}
}
}
5.Redis常用命令
1 连接操作命令
- quit:关闭连接(connection)
- auth:简单密码认证
- help cmd: 查看cmd帮助,例如:help quit
2 持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shutdown:将数据同步保存到磁盘,然后关闭服务
3 远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
4 对key操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key
- randomkey:随机返回key空间的一个
- keyrename(oldname, newname):重命名key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):按索引查询
- move(key, dbindex):移动当前数据库中的key到dbindex数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
5 String
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string的value
- setnx(key, value):添加string,名称为key,值为value
- setex(key, time, value):向库中添加string,设定过期时间time
- mset(key N, value N):批量设置多个string的值
- msetnx(key N, value N):如果所有名称为key i的string都不存在
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
6 List
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的 元素
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素
- ltrim(key, start, end):截取名称为key的list
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值
- lrem(key, count, value):删除count个key的list中值为value的元素
- lpop(key):返回并删除名称为key的list中的首元素
- rpop(key):返回并删除名称为key的list中的尾元素
- blpop(key1, key2,… key N, timeout):lpop命令的block版本。
- brpop(key1, key2,… key N, timeout):rpop的block版本。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
7 Set
- sadd(key, member):向名称为key的set中添加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :移到集合元素
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
- sunion(key1, (keys)) :求并集
- sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
- sdiff(key1, (keys)) :求差集
- sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
8 Hash
- hset(key, field, value):向名称为key的hash中添加元素field
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, (fields)):返回名称为key的hash中field i对应的value
- hmset(key, (fields)):向名称为key的hash中添加元素field
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
6.参考网址
7.源码下载
在Git上面下载:https://github.com/wuya11/jedisDemo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号