
K-means聚类流程,欧式/余弦距离
K-means聚类:根据距离,相似性分组。相似度组内大,组间小。用途:知识发现;异常检测;特征提取与数据压缩。
K:分几个组。先随机取初始点,看每个点到初始点距离进行分组 <----> 求平均位置(一般不会落在样本上)
没有点再被重新划分类别(各组中心点不变化)--> 终止(收敛),得到模型
K = ?:肘部法(elbow),搜索合适的K,让total loss 最小(每个簇的MSE加和)。
total loss 在K = m时最小(为0,无误差)。K = 1时最大
找合适elbow point:此点处K增加,loss再减少会过拟合。
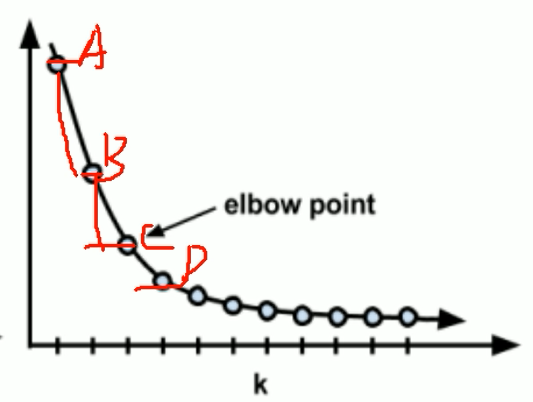 | A - B | - |B - C| = 收益(gain),elbow point为收益最大的点。类似梯度下降中early stopping:连续10次 losst+1 - losst < Threshold
| A - B | - |B - C| = 收益(gain),elbow point为收益最大的点。类似梯度下降中early stopping:连续10次 losst+1 - losst < Threshold
K-means是一种高斯混合模型
深度学习中,注意力(Attention)提特征方式不同,结果不同。Data --> algorithm --> model
计算相似度:距离1.欧式
2.余弦:看θ大小,cosθ接近1相似,-1相反。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端