
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
ndarray的属性:

1 >>> b=np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11]]) 2 >>> b 3 array([[ 0, 1, 2, 3], 4 [ 4, 5, 6, 7], 5 [ 8, 9, 10, 11]]) 6 >>> b[0] 7 array([0, 1, 2, 3]) 8 >>> b[1] 9 array([4, 5, 6, 7]) 10 >>> b[2] 11 array([ 8, 9, 10, 11]) 12 >>> b.ndim 13 2 14 >>> b.shape 15 (3, 4) 16 >>> b.size 17 12 18 >>> b[0].ndim 19 1 20 >>> b[0].shape 21 (4,) 22 >>> b[0].size 23 4 24 >>> b[0][0] 25 0 26 >>> b[0][1] 27 1 28 >>> b[0,0] 29 0 30 >>> b[0,1] 31 1 32 >>>
ndarray的类型:
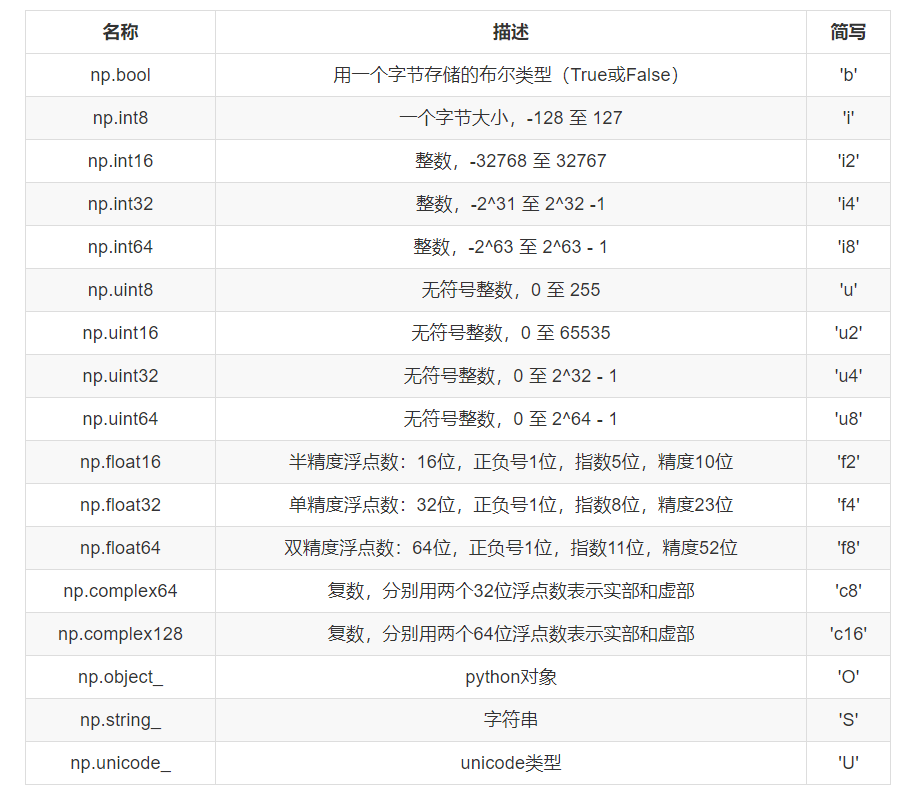
1 >>> a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32) 2 >>> a.dtype 3 dtype('float32') 4 5 >>> arr = np.array(['python', 'tensorflow', 'scikit-learn', 'numpy'], dtype = np.string_) 6 >>> arr 7 array([b'python', b'tensorflow', b'scikit-learn', b'numpy'], dtype='|S12')
生成0和1的数组:
- np.ones(shape, dtype)
- np.ones_like(a, dtype)
- np.zeros(shape, dtype)
- np.zeros_like(a, dtype)
1 >>> ones = np.ones([4,8]) 2 >>> ones 3 array([[1., 1., 1., 1., 1., 1., 1., 1.], 4 [1., 1., 1., 1., 1., 1., 1., 1.], 5 [1., 1., 1., 1., 1., 1., 1., 1.], 6 [1., 1., 1., 1., 1., 1., 1., 1.]])
>>> np.zeros_like(ones)
array([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
a = np.array([[1,2,3],[4,5,6]])
# 从现有的数组当中创建
a1 = np.array(a)
# 相当于索引的形式,并没有真正的创建一个新的
a2 = np.asarray(a)
等差数组:np.linspace (start, stop, num, endpoint)- 创建等差数组 — 指定数量
- 参数:
- start:序列的起始值
- stop:序列的终止值
- num:要生成的等间隔样例数量,默认为50
- endpoint:序列中是否包含stop值,默认为ture
1 np.linspace(0, 100, 11)
2 array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])
数字数列数组:np.arange(start,stop, step, dtype)
- 创建等差数组 — 指定步长
- 参数
- step:步长,默认值为1
1 np.arange(10, 50, 2)
2 array([10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 3 44, 46, 48])
等比数组:np.logspace(start,stop, num)
-
创建等比数列
-
参数:
- num:要生成的等比数列数量,默认为50
1 np.logspace(0, 2, 3) 2 array([ 1., 10., 100.]) 3 >>> np.logspace(1, 5, 5,base=2) 4 array([ 2., 4., 8., 16., 32.])
正态分布创建方式:np.random.randn(d0,d1,...,dn)
从标准正态分布中返回一个或多个样本值
np.random.normal(loc=0.0,scale=1.0,size=None)
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
np.random.standard_normal(size=None) 返回指定形状的标准正态分布的数组。
1 x=np.random.normal(1.75,1,100000) 2 >>> x 3 array([2.31923933, 1.91259365, 4.41394574, ..., 2.46176548, 0.01535258, 4 3.47832857])
均值分布:
np.random.rand(d0, d1, ..., dn)
返回[0.0,1.0)内的一组均匀分布的数。
np.random.uniform(low=0.0, high=1.0, size=None)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
np.random.randint(low, high=None, size=None, dtype='l')
从一个均匀分布中随机采样,生成一个整数或N维整数数组,
取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。
-
数组形状改变
- 对象.reshape()
- 没有进行行列互换,新产生一个ndarray
- 对象.resize()
- 没有进行行列互换,修改原来的ndarray
- 对象.T
- 进行了行列互换
- 对象.reshape()
-
数组去重
- np.unique(对象)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号