Jmeter正则表达式提取器详解
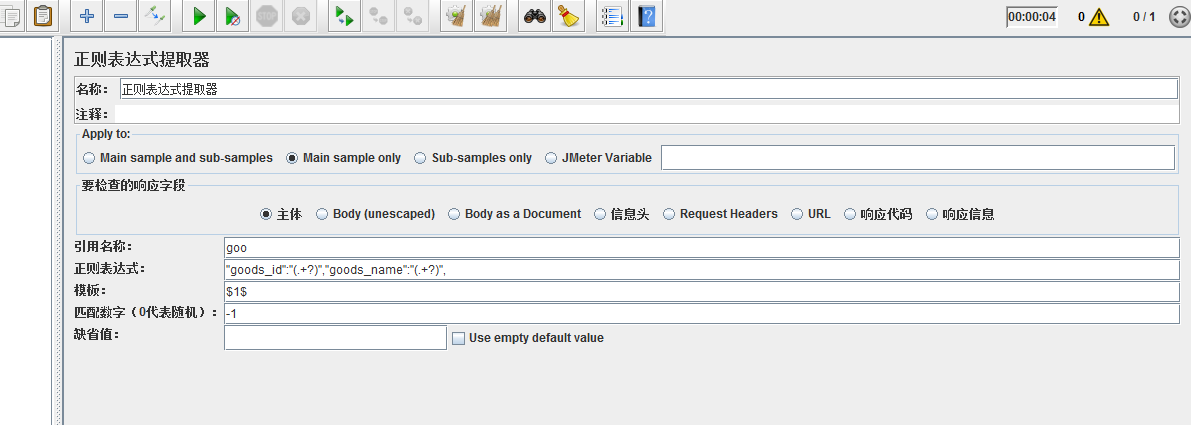
名称:次正则提取器的名称,最好取名唯一且有意义,为了方便与其他正则提取器区分。
Apply to:应用范围
Main sample and sub_samples:p匹配范围包括当前父取样器并覆盖至子取样器
Main sample only:匹配范围是当前父取样器
sub-samples only:仅匹配子取样器
Jmeter Variable:支持对Jmeter变量值进行匹配
要检查的响应字段:样本数据来源
主体:响应数据的主体部分,排除Header部分;http协议返回请求的主体部分就是Body
Body(unescapad):针对替换了转移码的Body部分。
Body as a Document:返回内容作为一个文档进行匹配。
信息头:只匹配信息头部分内容。
Request Headers
URL:只匹配URL链接。
响应代码:匹配响应代码,比如Http协议返回码200代表成功。
响应信息:匹配响应信息,比如处理成功返回“成功”字样。
引用名称:这个根据你的喜好随便填写,没啥讲的,只是在后面进行引用是需要的
正则表达式:这里填写需要匹配的内容(正则表达式自己网上查下);这里(.+?)的正则表达式的意思是“.”匹配任意元素;“+”指前面的"."诶匹配任意元素的次数是一次或多次;“?”则是标识前面匹配上最小长度值(非贪婪模式)。
例如:
数据:abbb
使用正则匹配:a(.+?) 匹配结果:ab
使用正则匹配:a(.+) 匹配结果:ab,abb,abbb
模板:表示提取到第几个值
$-1$:表示取所有匹配模板值
$0$:表示随机取匹配模板值
$1$:表示取第一个匹配模板值
$2$:表示取第二个匹配模板值
$n$:n表示正整数,提取第n个匹配模板值。
匹配数字:0便是随机取;-1表示取所有;正数表示对应取第一个匹配到的值
缺省值:缺省值相当于默认值;当未匹配到数据时,缺省值就是引用变量的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号