
redis对象有5种类型(type),8种编码格式(encoding),8种编码格式都有对应的数据结构。
对象类型:
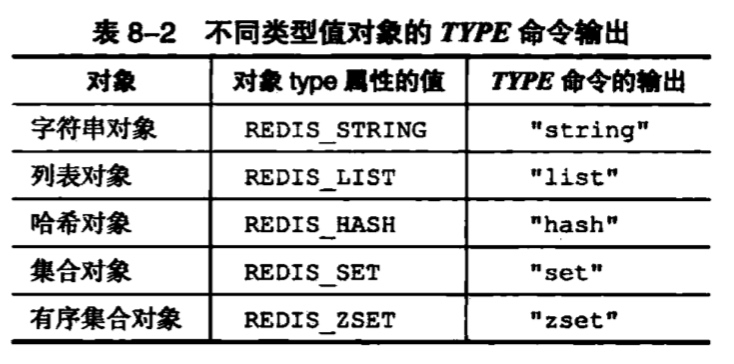
编码格式:

有11种组合方式:
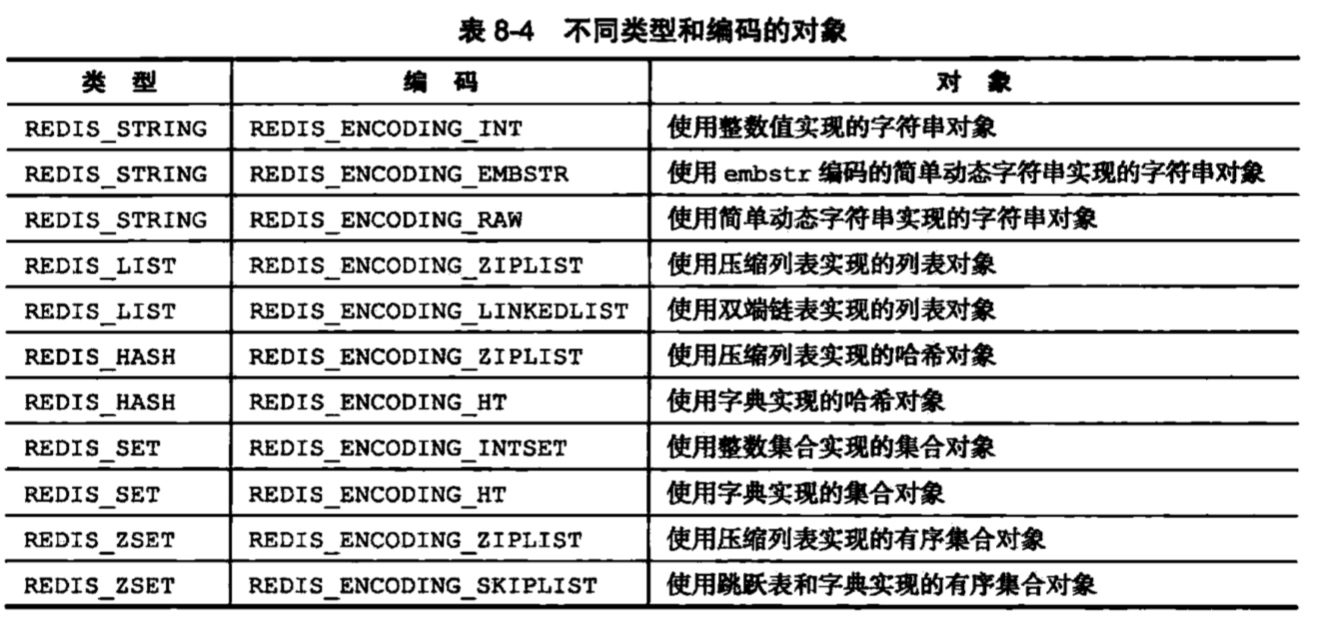
五种类型的编码选择:
1. 字符串类型
int:全部为数值类型。
embstr:长度小于32字节的字符串。
raw:长度大于32字节的字符串。
2. 列表对象类型
以下条件下用压缩列表ziplist实现:
* 列表对象字符长度都小于64字节。
* 元素个数小于512个。
其他情况用双向列表linkedlist实现。
3. 哈希对象类型
以下条件下用压缩列表ziplist实现:
* 列表对象字符长度都小于64字节。
* 元素个数小于512个。
其他情况用字典ht实现。
4. 集合对象类型
以下条件下用整数集合intset实现:
* 列表对象都是整数对象。
* 元素个数小于512个。
其他情况用跳跃表skiplist实现。
5. 有序集合对象类型
以下条件下用压缩列表ziplist实现:
* 列表对象长度小于64字节。
* 元素个数小于128个。
其他情况同时用字典ht和跳跃表skiplist实现。
注释:
用字典是为了便于o(1)复杂度查询某个元素,用跳跃表是为了便于范围查询。
## 1. sds
数据结构:

总结:
* 便于存储特殊字符,二进制安全。
* 高效查询字符长度,复杂度O(1)。
* 惰性空间分配,减少扩容,缩容次数。
* 防止数组溢出。
* \0结尾,可以延用部分C语言函数库。
## 2. 链表
节点结构:
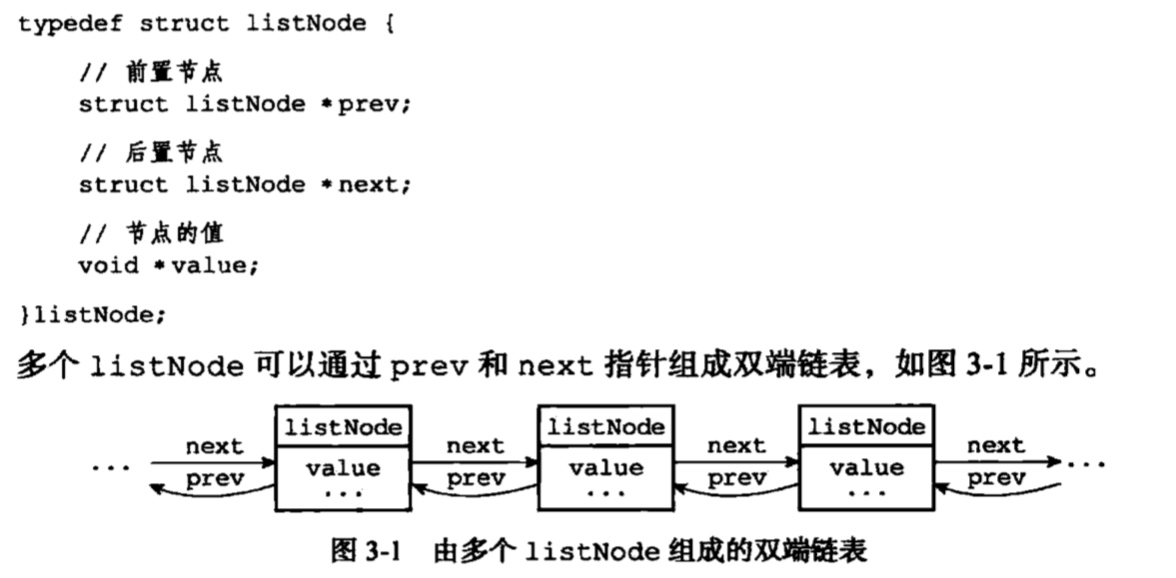
链表结构:

总结:
* 双向无环链表。
## 3. 整数集合
数据结构:

总结:
* 保存有序,不重复的整数集合。
* 数据类型由encoding决定,可以存储16位,32位,64位整数,尽可能的节省内存。
* 只支持类型升级,不支持降级。
## 4. 字典
字典结构:

hash表结构:

节点结构:

总结:
* 字典底层用两个hash表实现,h[0]在平时使用,h[1]在rehash的过程中用到。
* rehash使用渐进式rehash,将任务均摊。rehash过程中,insert操作只在h[1]中,delete,select,update操作可能会对两个表同时操作。
* hash表用链地址法解决hash冲突。
* hash值使用murmurhash2算法实现,可以获得比较散列的hash值。
## 5. 跳跃表
跳跃表模型:
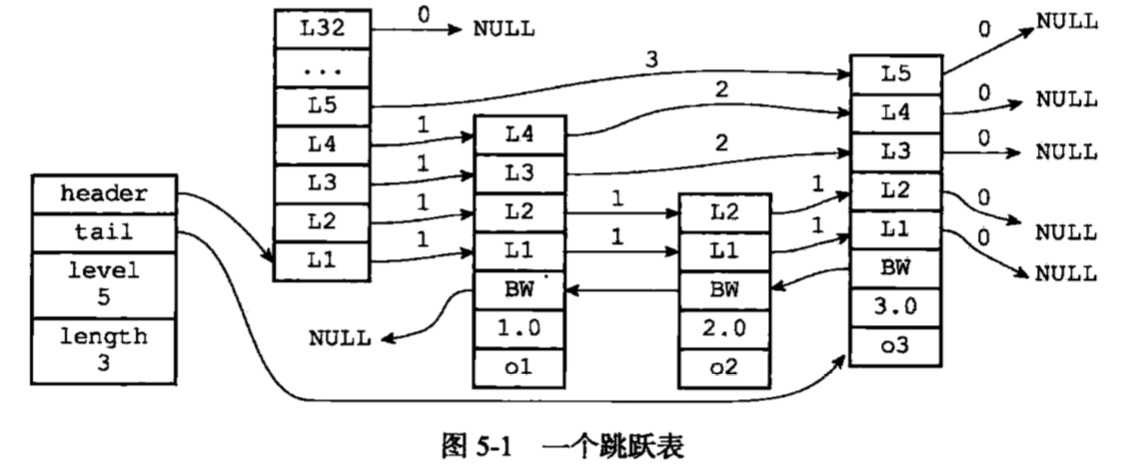
节点结构:

总结:
* 每个节点的层高由随机函数生成(1~32),每落在每层的概率相差两倍。
* 每个节点的分值可以相等,节点对象唯一。
* 节点按分值排序,当分值相等时,按对象排序。
## 6. 压缩列表
压缩列表结构:

各节点结构:

总结:
* content字节数<254 previous_entry_length用1个字节;content字节数>=254 previous_entry_length用5个字节。
* encoding 前两位表示编码,00,01,11表示数组类型,长度分别为1字节,2字节,5字节,11表示整数类型。后面位数存content长度。
* zlbytes 整个压缩列表字节数
* zltail 起始地址到entryN的偏移量,便于找到尾部节点。
* zllen 节点个数,当个数>65535时需遍历整个列表获取节点个数。
* zlend 特殊标志0xff 表示结尾。
* 节点新增,或者节点删除都可能导致连锁更新,但出现概率不高。

