embedding是什么
部分内容参考:https://zhuanlan.zhihu.com/p/164502624
近年来,NLP自然语言处理、推荐系统,以及计算机视觉已成为目前工业界算法岗的主流方向,无论在哪个领域,对“Embedding”这个词概念的理解都是每个庞大知识体系的基石。
“Embedding”直译是嵌入式、嵌入层。
看到这个翻译的时候是不是一脸懵圈?什么叫嵌入?意思是牢固地或深深地固定?那么它能把什么嵌入到什么呢?
很开心地告诉你,它能把万物嵌入万物,是沟通两个世界的桥梁,是打破次元壁的虫洞!
用数学的话来说:“它是单射且同构的(看到这么好的性质是不是很激动!)”
简单来说,我们常见的地图就是对于现实地理的Embedding,现实的地理地形的信息其实远远超过三维,但是地图通过颜色和等高线等来最大化表现现实的地理信息。
通过它,我们在现实世界里的文字、图片、语言、视频就能转化为计算机能识别、能使用的语言,且转化的过程中信息不丢失。
怎么理解Embedding
首先,我们有一个one-hot编码的概念。
假设,我们中文,一共只有10个字,那么我们用0-9就可以表示完。
比如,这十个字就是“小普喜欢星海湾的朋友”
其分别对应“0-9”,如下:

那么,其实我们只用一个列表就能表示所有的对话。
例如:

或者:

但是,经过one-hot编码把上面变成:

即:把每一个字都对应成一个十个(样本总数/字总数)元素的数组/列表,其中每一个字都用唯一对应的数组/列表对应,数组/列表的唯一性用1表示。
那问题来了,费老大劲整这个干嘛呢?有什么优势?
很明显,计算简单嘛,稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和就行,也许你心算都能算出来;而一维列表,你能很快算出来?
何况这个列表还是一行,如果是100行、1000行或1000列呢?所以,one-hot编码的优势就体现出来了,计算方便快捷、表达能力强。
然而,缺点也随着来了。
比如:中文大大小小简体繁体常用不常用有十几万,然后一篇文章100W字,你要表示成100W X 10W的矩阵???
这是它最明显的缺点:过于稀疏时,过度占用资源。
比如:其实我们这篇文章,虽然100W字,但是其实我们整合起来,有99W字是重复的,只有1W字是完全不重复的。
那我们用100W X 10W的岂不是白白浪费了99W X 10W的矩阵存储空间。
那怎么办???
这时,Embedding层就出现了!
假设:我们有一个2 x 6的矩阵,然后乘上一个6 x 3的矩阵后,变成了一个2 x 3的矩阵。
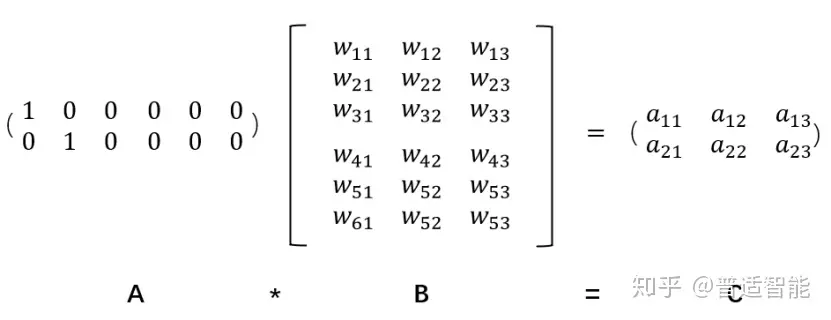
先不管它什么意思,这个过程,我们把一个A中的12个元素的矩阵变成C中6个元素的矩阵,直观上,大小是不是缩小了一半?
对!!!Embedding层,在某种程度上,就是用来降维的,降维的原理就是矩阵乘法。
假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了10W/20=5000倍!!!
这就是嵌入层的一个作用——降维。
接着,既然可以降维,当然也可以升维。
为什么要升维?

这张图,如果要你在10米开外找出四处不同!是不是太困难了!(小普这就叫复联的鹰眼来帮我!)当然,目测这是不可能完成的。
但是让你在一米外,也许你一瞬间就发现鼻子是不同的,然后再走近半米,你又发现右下角元宝也是不同的。再走近20厘米,又发现耳朵也不同,最后,在距离屏幕10厘米的地方,终于发现第四个不同的地方在眼睛的高光。
但是,其实无限靠近并不代表认知度就高了,比如,你只能距离屏幕1厘米远的地方找,找出四处不同,小普怕不是要被读者打死了。
由此可见,距离的远近会影响我们的观察效果。
同理也是一样的,低维的数据可能包含的特征是非常笼统的,我们需要不停地拉近拉远来改变我们的感受,让我们对这幅图有不同的观察点,找出我们要的"茬"。
Embedding的又一个作用体现了:对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。
同时,这个Embedding是一直在学习在优化的,就使得整个拉近拉远的过程慢慢形成一个良好的观察点。
比如:小普来回靠近和远离屏幕,发现45厘米是最佳观测点,这个距离能10秒就把4个不同点找出来了。
因此它就是作为这个桥梁的存在,让我们手头的东西可伸可缩,变成我们希望的样子。
语义理解中Embedding意义
从词向量说起
从字面本身计算语义相关性是不够的 - 不同字,同义:「快乐」vs.「高兴」 - 同字,不同义:「上马」vs.「马上」 所以我们需要一种方法,能够有效计算词与词之间的关系,词向量(Word Embedding)应运而生
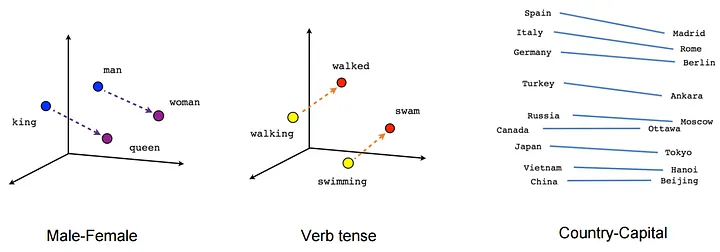
词向量的基本原理:用一个词上下文窗口表示它自身
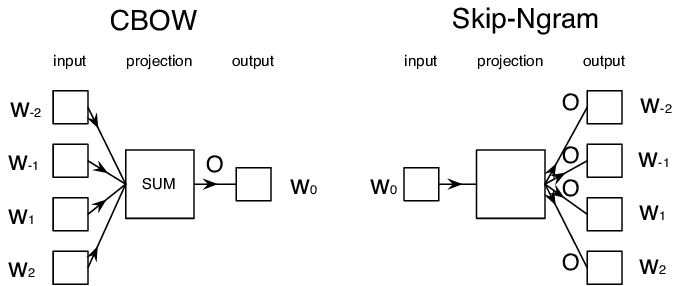
词向量的不足
- 同一个词在不同上下文中语义不同:我从「马上」下来 vs. 我「马上」下来- https://nlp.stanford.edu/projects/glove/
- https://fasttext.cc/
基于整个句子,表示句中每个词,那么同时我们也就表示了整个句子
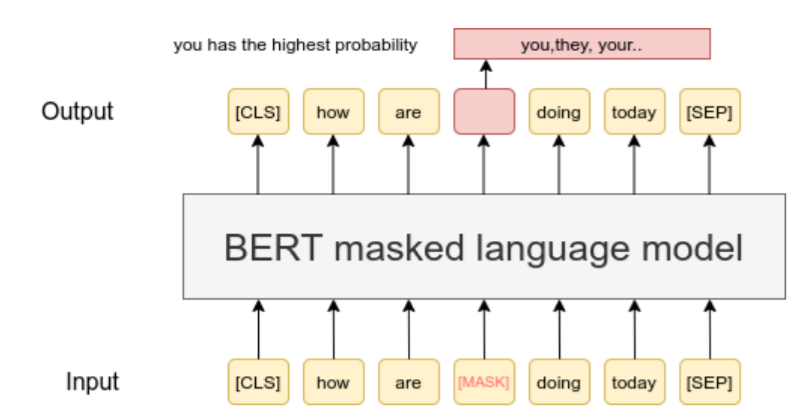
所以,句子、篇章都可以向量化
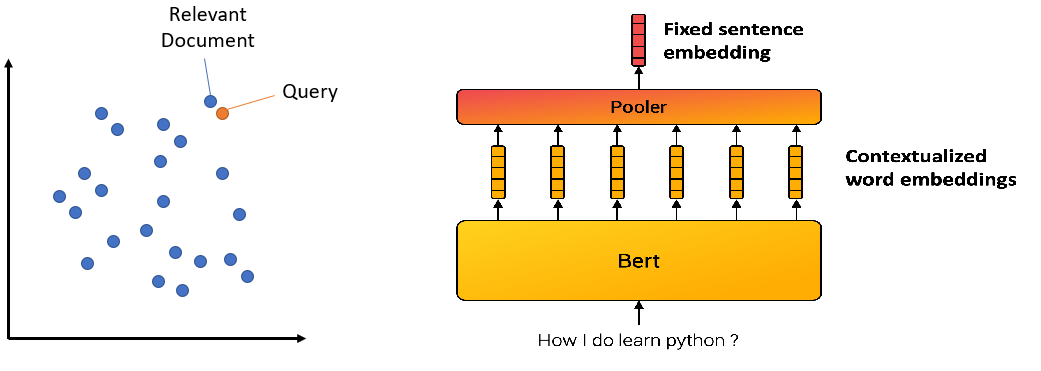
Sentence Transformer
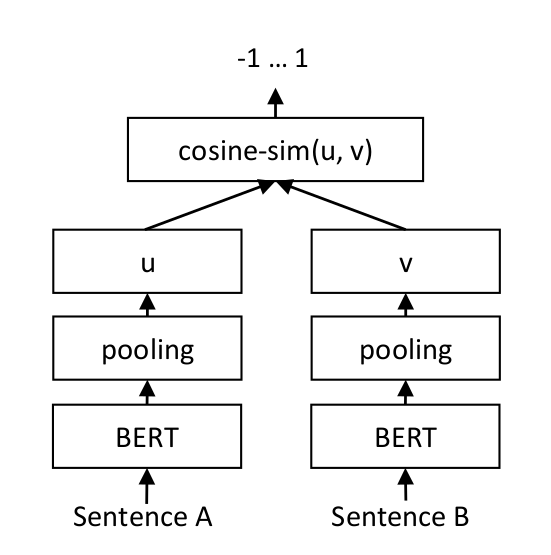
向量相似度计算¶
from dotenv import load_dotenv
import numpy as np
from numpy import dot
from numpy.linalg import norm
from langchain.embeddings import OpenAIEmbeddings
import warnings
warnings.filterwarnings("ignore")
load_dotenv()
def cos_sim(a, b):
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
x = np.asarray(a)-np.asarray(b)
return norm(x)
model = OpenAIEmbeddings(model='text-embedding-ada-002')
query = "业绩增长"
documents = [
"小明,我们公司三季度接了个大单",
"小明,我们公司今天三季度同比增长60%",
"小明,我们公司第二季度,有一笔交易被认定的死账",
"小明,公司CEO信心满满,下一季度再创新高",
"小明,公司计划要扩招300人",
]
query_vec = model.embed_query(query)
doc_vecs = model.embed_documents(documents)
print("Cosine distance:") # 越大越相似
print(cos_sim(query_vec, query_vec))
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print("\nEuclidean distance:") # 越小越相似
print(l2(query_vec, query_vec))
for vec in doc_vecs:
print(l2(query_vec, vec))
Cosine distance:
1.0
0.8063100782497249
0.8492772395611916
0.7755446349946937
0.8278780825719825
0.8181322596289557
Euclidean distance:
0.0
0.6223984603937824
0.549040545750145
0.6700080074227571
0.5867229626118574
0.6031048671185539
基于相似度聚类¶
from langchain.embeddings import OpenAIEmbeddings
from sklearn.cluster import KMeans, DBSCAN
texts = [
"这个接口返回的参数不对",
"帮我添加一个下载按钮",
"我需要在window上也能用",
"接口报500错误",
"接口反应超时了",
"服务挂了",
"我需要新增一个新的配置",
"这个可以取消不用做了",
"我们做一个适配的接口吧",
"系统上报一个监控到的错误日志"
]
model = OpenAIEmbeddings(model='text-embedding-ada-002')
X = []
for t in texts:
embedding = model.embed_query(t)
X.append(embedding)
# clusters = KMeans(n_clusters=3, random_state=42, n_init="auto").fit(X)
clusters = DBSCAN(eps=0.55, min_samples=2).fit(X)
for i, t in enumerate(texts):
print("{}\t{}".format(clusters.labels_[i], t))
0 这个接口返回的参数不对
-1 帮我添加一个下载按钮
-1 我需要在window上也能用
0 接口报500错误
0 接口反应超时了
-1 服务挂了
-1 我需要新增一个新的配置
-1 这个可以取消不用做了
-1 我们做一个适配的接口吧
-1 系统上报一个监控到的错误日志
本地部署¶
# %pip install sentence_transformers
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-zh-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
Downloading pytorch_model.bin: 100%|██████████| 1.30G/1.30G [02:45<00:00, 7.87MB/s]
Downloading (…)nce_bert_config.json: 100%|██████████| 52.0/52.0 [00:00<?, ?B/s]
Downloading (…)cial_tokens_map.json: 100%|██████████| 125/125 [00:00<?, ?B/s]
Downloading (…)cec2c/tokenizer.json: 100%|██████████| 439k/439k [00:00<00:00, 474kB/s]
Downloading (…)okenizer_config.json: 100%|██████████| 394/394 [00:00<00:00, 140kB/s]
Downloading (…)bb65dcec2c/vocab.txt: 100%|██████████| 110k/110k [00:00<00:00, 55.3MB/s]
Downloading (…)5dcec2c/modules.json: 100%|██████████| 229/229 [00:00<?, ?B/s]
query = "前瞻性"
documents = [
"我们需要借助最近流行的起来的GPT帮我们提升工作效率",
"你按照这个guide page一步一步走就可以了",
"我们一起来探索下,看看这个新的开源框架能不能帮助到我们",
"Hugging Face上有很多新的开源模型,我们可以基于我们环境来尝试试验下",
"Langchain上的开源工具也很多,我们的选择性很大,加油",
]
query_vec = model.embed_query(query)
doc_vecs = model.embed_documents(documents)
print("Cosine distance:") # 越大越相似
print(cos_sim(query_vec, query_vec))
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
Cosine distance: 0.9999999999999999 0.22479291416184247 0.12025486693514557 0.2333528960497604 0.2213879507146927 0.1755505059722227
- Sentence Transformer: https://www.sbert.net/index.html
- BGE Embedding: https://huggingface.co/BAAI


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本