Llama3本地部署与高效微调入门
前言
为了保持公司在AI(人工智能)开源大模型领域的地位,社交巨头Meta推出了旗下最新开源模型。当地时间4月18日,Meta在官网上宣布公布了旗下最新大模型Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k。Meta表示,通过使用更高质量的训练数据和指令微调,Llama 3比前代Llama 2有了“显著提升”。未来,Meta将推出Llama 3的更大参数版本,其将拥有超过4000亿参数。Meta也将在后续为Llama 3推出多模态等新功能,包括更长的上下文窗口,以及Llama 3研究论文。Meta在公告中写道:“通过Llama 3,我们致力于构建能够与当今最优秀的专有模型相媲美的开源模型。我们想处理开发者的反馈,提高Llama 3 的整体实用性,同时,继续在负责地使用和部署LLM(大型语言模型)方面发挥领先作用。”
本文将详细介绍Llama3-8B的详细部署与微调过程
环境准备
- 操作系统:Ubuntu 22.04.5 LTS
- Anaconda3:Miniconda3-latest-Linux-x86_64
- GPU: NVIDIA GeForce RTX 4090 24G
本文描述的过程中,所有数据和代码统一放到
~/ai-test/目录下
- Step 1. 准备conda环境
创建一个新的conda环境:
conda create --name llama_factory python=3.11
激活刚刚创建的conda环境:
conda activate llama_factory
如果报错可以使用下面命令:
source activate llama_factory
- Step 2. 下载LLaMA-Factory的项目文件
下载LLama_Factory源码:
git clone https://github.com/hiyouga/LLaMA-Factory.git
切换到LLaMA-Factory路径:
cd ~/ai-test/LLaMA-Factory
- Step 3. 升级pip版本
建议在执行项目的依赖安装之前升级 pip 的版本,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。升级 pip 很简单,只需要运行命令如下命令:
python -m pip install --upgrade pip
- Step 4. 使用pip安装LLaMA-Factory项目代码运行的项目依赖
在LLaMA-Factory中提供的 requirements.txt文件包含了项目运行所必需的所有 Python 包及其精确版本号。使用pip一次性安装所有必需的依赖,执行命令如下:
pip install -r requirements.txt --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
- Step 5. Llama3模型下载
在~/ai-test/创建如下目录:
mkdir model 存放模型文件
cd model
可以从下面地址中下载模型文件,这里我们从ModelScope来下载
- huggingface Llama3模型主页:https://huggingface.co/meta-llama/
- Github主页:https://github.com/meta-llama/llama3/tree/main
- ModelScope Llama3-8b模型主页:https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3-8B-Instruct/summary
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
- Step 6. 运行原始模型
切换到LLama_Factory目录下
cd ~/ai-test/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 python src/web_demo.py \
--model_name_or_path /home/oneview/ai-test/model/Meta-Llama-3-8B-Instruct \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager
运行如下:端口可能有所不同

访问http://127.0.0.1:8000如下图所示
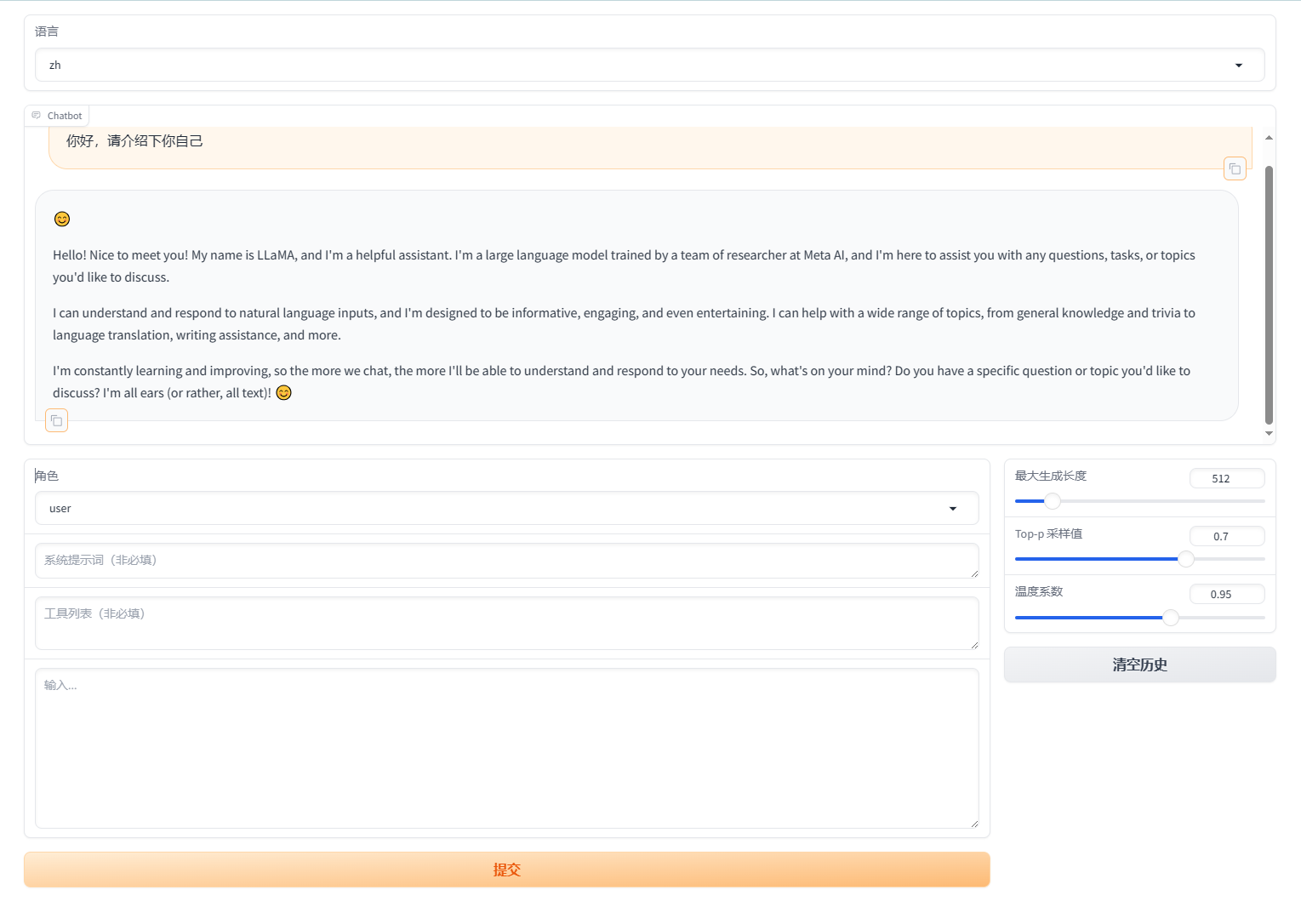
输入“你好,请介绍下你自己”,可以发现模型还不具备中文处理能力,后面我们将用中文数据集对模型进行微调。
通过上述步骤就已经完成了LLaMA-Factory模型的完整私有化部署过程。
用LLama_Factory对模型进行微调
在完成了Llama3模型的快速部署之后,接下来我们尝试围绕Llama3的中文能力进行微调。
所谓微调,通俗理解就是围绕大模型进行参数修改,从而永久性的改变模型的某些性能。而大模型微调又分为全量微调和高效微调两种,所谓全量微调,指的是调整大模型的全部参数,而高效微调,则指的是调整大模型的部分参数,目前常用的高效微调方法包括LoRA、QLoRA、p-Tunning、Prefix-tunning等。而只要大模型的参数发生变化,大模型本身的性能和“知识储备”就会发生永久性改变。在通用大模型往往只具备通识知识的当下,为了更好的满足各类不同的大模型开发应用场景,大模型微调已几乎称为大模型开发人员的必备基础技能。
- LLaMA-Factory项目介绍
LLaMA Factory是一个在GitHub上开源的项目,该项目给自身的定位是:提供一个易于使用的大语言模型(LLM)微调框架,支持LLaMA、Baichuan、Qwen、ChatGLM等架构的大模型。更细致的看,该项目提供了从预训练、指令微调到RLHF阶段的开源微调解决方案。截止目前(2024年3月1日)支持约120+种不同的模型和内置了60+的数据集,同时封装出了非常高效和易用的开发者使用方法。而其中最让人喜欢的是其开发的LLaMA Board,这是一个零代码、可视化的一站式网页微调界面,它允许我们通过Web UI轻松设置各种微调过程中的超参数,且整个训练过程的实时进度都会在Web UI中进行同步更新。
简单理解,通过该项目我们只需下载相应的模型,并根据项目要求准备符合标准的微调数据集,即可快速开始微调过程,而这样的操作可以有效地将特定领域的知识注入到通用模型中,增强模型对特定知识领域的理解和认知能力,以达到“通用模型到垂直模型的快速转变”。
基于LLaMA-Factory的Llama3中文能力微调过程
基于LLaMA-Factory的完整高效微调流程如下,本次实验中我们将借助Llama-Factory的alpaca_data_zh_51k数据集进行微调,暂不涉及关于数据集上传和修改数据字典事项:

- Step 1. 查看微调中文数据集数据字典
我们找到./LLaMA-Factory目录下的data文件夹:
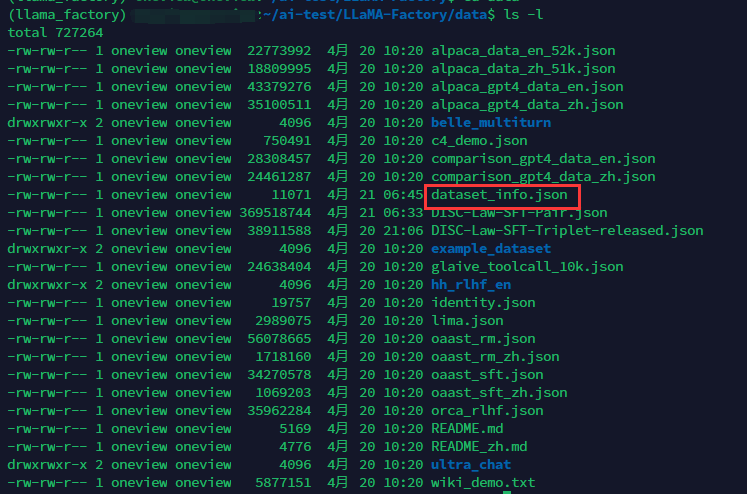
查看dataset_info.json:
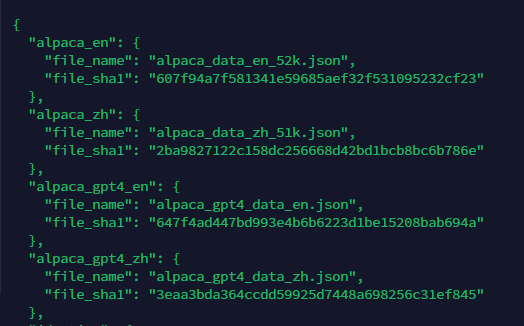
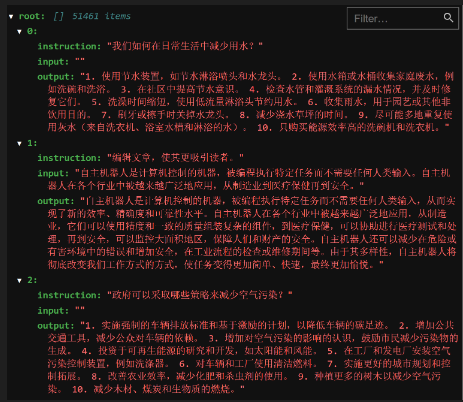
找到当前数据集名称:alpaca_zh。数据集情况如下:
- Step 2. 创建微调脚本
所谓高效微调框架,我们可以将其理解为很多功能都进行了高层封装的工具库,为了使用这些工具完成大模型微调,我们需要编写一些脚本(也就是操作系统可以执行的命令集),来调用这些工具完成大模型微调。这里我们需要先回到LlaMa-Factory项目主目录下:
切换到./LLaMA-Factory目录,创建一个名为single_lora_llama3.sh的脚本(脚本的名字可以自由命名)。
#!/bin/bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NCCL_P2P_DISABLE="1"
export NCCL_IB_DISABLE="1"
# 如果是预训练,添加参数 --stage pt \
# 如果是指令监督微调,添加参数 --stage sft \
# 如果是奖励模型训练,添加参数 --stage rm \
# 添加 --quantization_bit 4 就是4bit量化的QLoRA微调,不添加此参数就是LoRA微调 \
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \ ## 单卡运行
--stage sft \ ## --stage pt (预训练模式) --stage sft(指令监督模式)
--do_train True \ ## 执行训练模型
--model_name_or_path /home/oneview/ai-test/model/Meta-Llama-3-8B-Instruct \ ## 模型的存储路径
--dataset alpaca_zh \ ## 训练数据的存储路径,存放在 LLaMA-Factory/data路径下
--template llama3 \ ## 选择Qwen模版
--lora_target q_proj,v_proj \ ## 默认模块应作为
--output_dir /home/oneview/ai-test/Llama3/output \ ## 微调后的模型保存路径
--overwrite_cache \ ## 是否忽略并覆盖已存在的缓存数据
--per_device_train_batch_size 2 \ ## 用于训练的批处理大小。可根据 GPU 显存大小自行设置。
--gradient_accumulation_steps 64 \ ## 梯度累加次数
--lr_scheduler_type cosine \ ## 指定学习率调度器的类型
--logging_steps 5 \ ## 指定了每隔多少训练步骤记录一次日志。这包括损失、学习率以及其他重要的训练指标,有助于监控训练过程。
--save_steps 100 \ ## 每隔多少训练步骤保存一次模型。这是模型保存和检查点创建的频率,允许你在训练过程中定期保存模型的状态
--learning_rate 5e-5 \ ## 学习率
--num_train_epochs 1.0 \ ## 指定了训练过程将遍历整个数据集的次数。一个epoch表示模型已经看过一次所有的训练数据。
--finetuning_type lora \ ## 参数指定了微调的类型,lora代表使用LoRA(Low-Rank Adaptation)技术进行微调。
--fp16 \ ## 开启半精度浮点数训练
--lora_rank 4 \ ## 在使用LoRA微调时设置LoRA适应层的秩。
注:实际脚本文件最好不要出现中文备注,否则容易出现编辑格式导致的问题。
然后为了保险起见,我们需要对齐格式内容进行调整,以满足Ubuntu操作系统运行需要(此前是从Windows系统上复制过去的文件,一般都需要进行如此操作):
sed -i 's/\r$//' ./single_lora_llama3.sh
- Step 3. 运行微调脚本,获取模型微调权重
当我们准备好微调脚本之后,接下来即可围绕当前模型进行微调了。这里我们直接在命令行中执行sh文件即可,注意运行前需要为该文件增加权限:
chmod +x ./single_lora_llama3.sh
./single_lora_llama3.sh
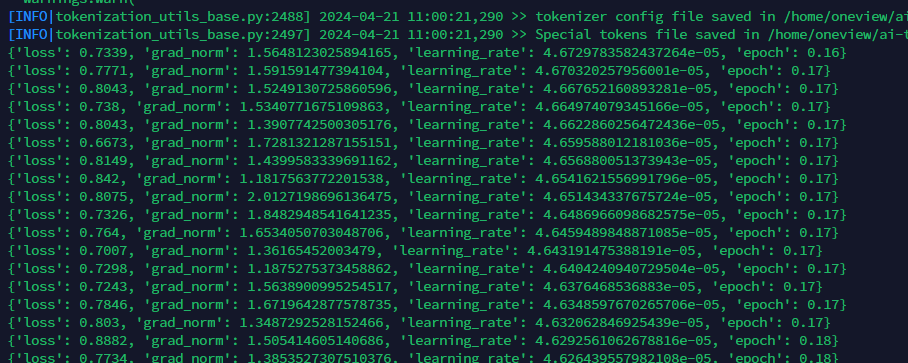
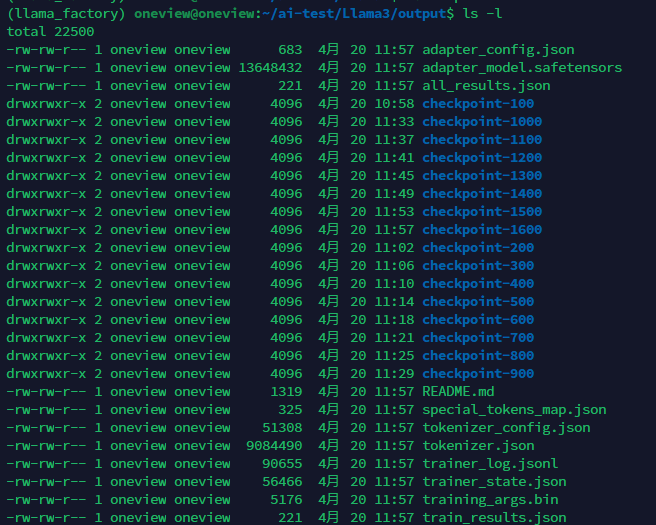
当微调结束之后,我们就可以在当前主目录下看到新的模型权重文件:
- Step 4. 合并模型权重,获得微调模型
接下来我们需要将该模型权重文件和此前的原始模型权重文件进行合并,才能获得最终的微调模型。LlaMa-Factory中已经为我们提供了非常完整的模型合并方法,同样,我们只需要编写脚本文件来执行合并操作即可,即llama3_merge_model.sh。同样,该脚本文件也可以按照此前single_lora_llama3.sh脚本相类似的操作,就是将课件中提供的脚本直接上传到Jupyter主目录下,再复制到LlaMa-Factory主目录下进行运行。
首先简单查看llama3_merge_model.sh脚本文件内容:
#!/bin/bash
python src/export_model.py \ ## 用于执行合并功能的Python代码文件
--model_name_or_path /home/oneview/ai-test/model/Meta-Llama-3-8B-Instruct \ ## 原始模型文件
--adapter_name_or_path /home/oneview/ai-test/Llama3/output \ ## 微调模型权重文件
--template llama3 \ ## 模型模板名称
--finetuning_type lora \ ## 微调框架名称
--export_dir /home/oneview/ai-test/Llama3/output_lora \ ## 合并后新模型文件位置
--export_size 2 \
--export_legacy_format false
注:实际脚本文件最好不要出现中文备注,否则容易出现编辑格式导致的问题。
然后运行脚本,进行模型合并:
./llama3_merge_model.sh
接下来即可查看刚刚获得的新的微调模型:
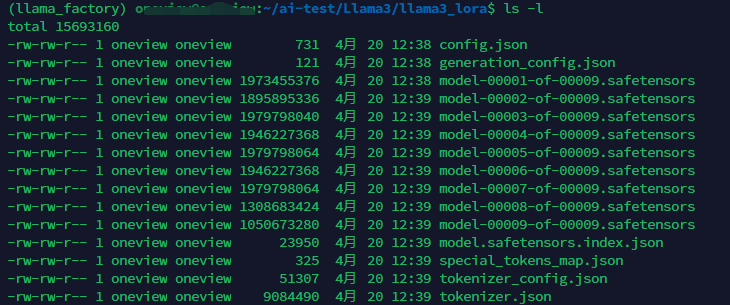
- Step 5. 测试微调效果
切换到LLama_Factory目录下
cd ~/ai-test/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 python src/web_demo.py \
--model_name_or_path /home/oneview/ai-test/Llama3/llama3_lora \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager
运行如下:端口可能有所不同

访问http://127.0.0.1:8000
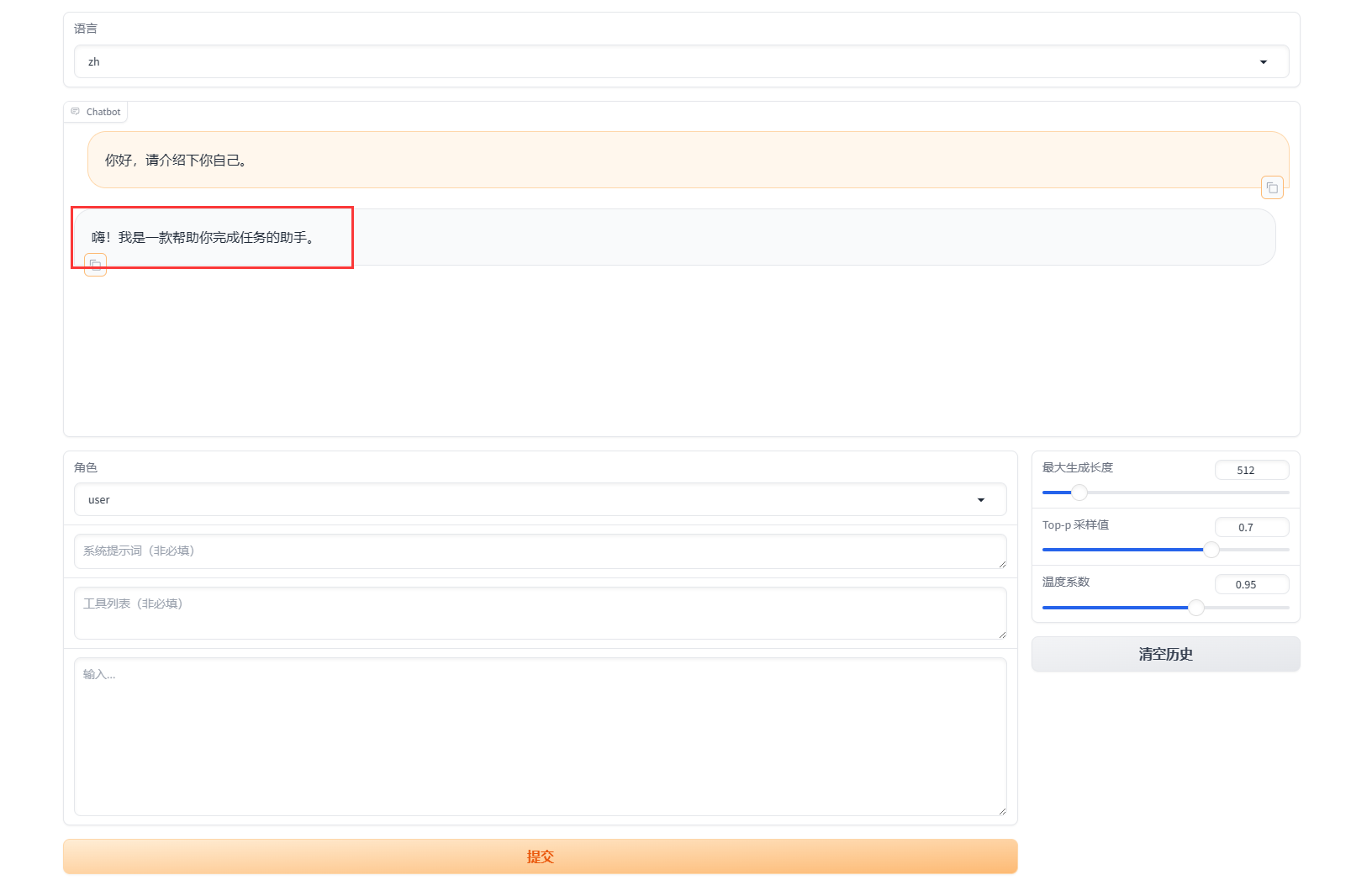
可以看到,现在的回答已经是中文了:)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号