ConcurrentHashMap的介绍
ConcurrentHashMap的介绍
概要
在前面的文章《散列表》中,我们对HashMap进行了介绍。但是,在并发环境下,HashMap 存在线程安全问题,可通过 HashTable 或者 Collections.synchronizedMap 解决,但它们会对整个集合加锁,影响性能。为了兼顾线程安全和效率,ConcurrentHashMap 应运而生。
一、JDK1.7及之前 ConcurrentHashMap
1. 底层实现
在 JDK 1.7 及之前版本,ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
ConcurrentHashMap 将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。因此,就不会存在锁竞争,提高并发访问率。简单来说:ConcurrentHashMap 优势就是采用了锁分段技术,每一个Segment就好比自治区,读写操作高度自治,Segment之间互不影响。
Segment类如下:
static class Segment<K,V> extends ReentrantLock implements Serializable { }
在 JDK 1.7 中它使用的是数组+链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。大数组 Segment 可以理解为 MySQL 中的数据库,而每个数据库(Segment)中又有很多张表 HashEntry,每个 HashEntry 中又有多条数据,这些数据是用链表连接的,如下图所示:
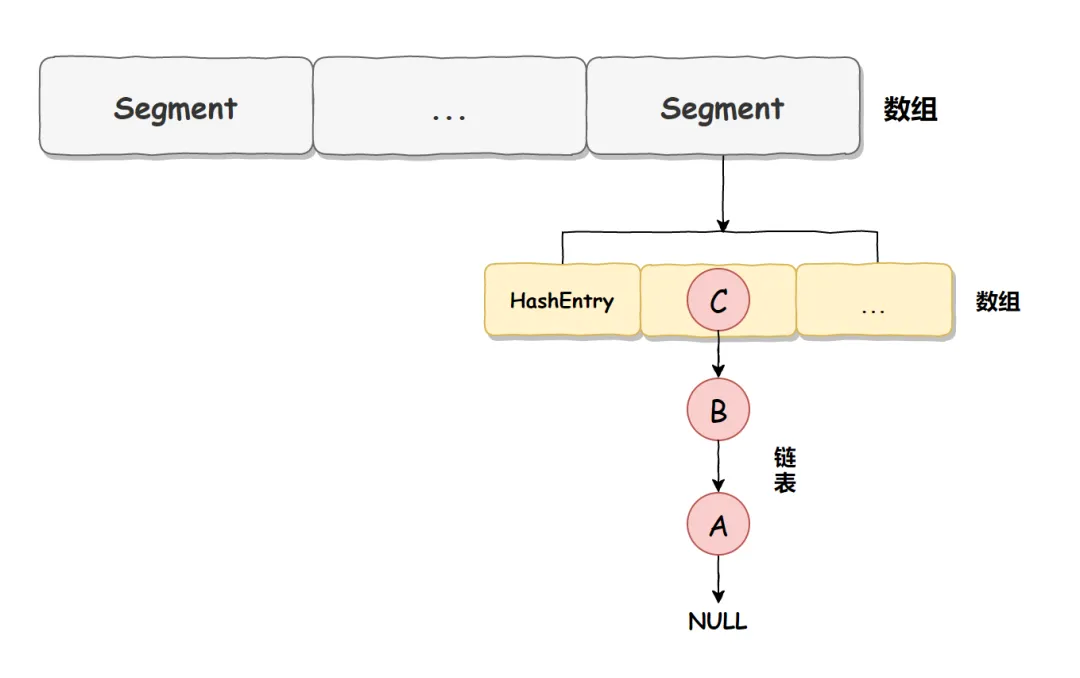
2. JDK1.7 线程安全实现
了解了 ConcurrentHashMap 的底层实现,再看它的线程安全实现就比较简单了。添加元素方法的部分源码如下:
1 final V put(K key, int hash, V value, boolean onlyIfAbsent) { 2 // 在往该 Segment 写入前,先确保获取到锁 3 HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); 4 V oldValue; 5 try { 6 // Segment 内部数组 7 HashEntry<K,V>[] tab = table; 8 int index = (tab.length - 1) & hash; 9 HashEntry<K,V> first = entryAt(tab, index); 10 for (HashEntry<K,V> e = first;;) { 11 if (e != null) { 12 K k; 13 // 更新已有值... 14 } 15 else { 16 // 放置 HashEntry 到特定位置,如果超过阈值则进行 rehash 17 // 忽略其他代码... 18 } 19 } 20 } finally { 21 // 释放锁 22 unlock(); 23 } 24 return oldValue; 25 }
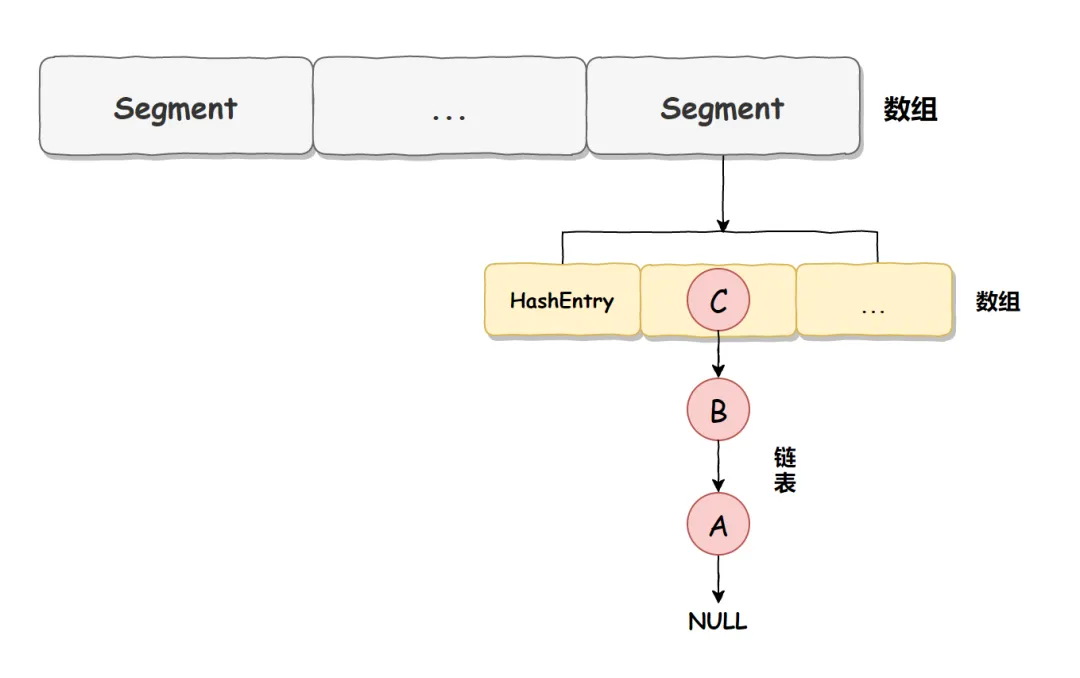
Segment 本身是基于 ReentrantLock 实现的加锁和释放锁的操作,这样就能保证多个线程同时访问 ConcurrentHashMap 时,同一时间只有一个线程能操作相应的节点,这样就保证了 ConcurrentHashMap 的线程安全了。也就是说 ConcurrentHashMap 的线程安全是建立在 Segment 加锁的基础上的,所以我们把它称之为分段锁或片段锁。
如下图:
3. 读写的详细过程
1)get() 方法
- 为输入的Key做Hash运算,得到hash值。
- 通过hash值,定位到对应的Segment对象
- 再次通过hash值,定位到Segment当中数组的具体位置。
2)put() 方法
- 为输入的Key做Hash运算,得到hash值。
- 通过hash值,定位到对应的Segment对象
- 获取可重入锁
- 再次通过hash值,定位到Segment当中数组的具体位置。
- 插入或覆盖HashEntry对象。
说明:从步骤可以看出,ConcurrentHashMap在读写时都需要二次定位。首先定位到Segment,之后定位到Segment内的具体数组下标。
二、JDK1.8 ConcurrentHashMap
1. 底层实现
在 JDK 1.7 中,ConcurrentHashMap 虽然是线程安全的,但因为它的底层实现是数组 + 链表的形式,所以在数据比较多的情况下访问是很慢的,因为要遍历整个链表,而 JDK 1.8 则使用了数组 + 链表/红黑树的方式优化了 ConcurrentHashMap 的实现,具体实现结构如下图:
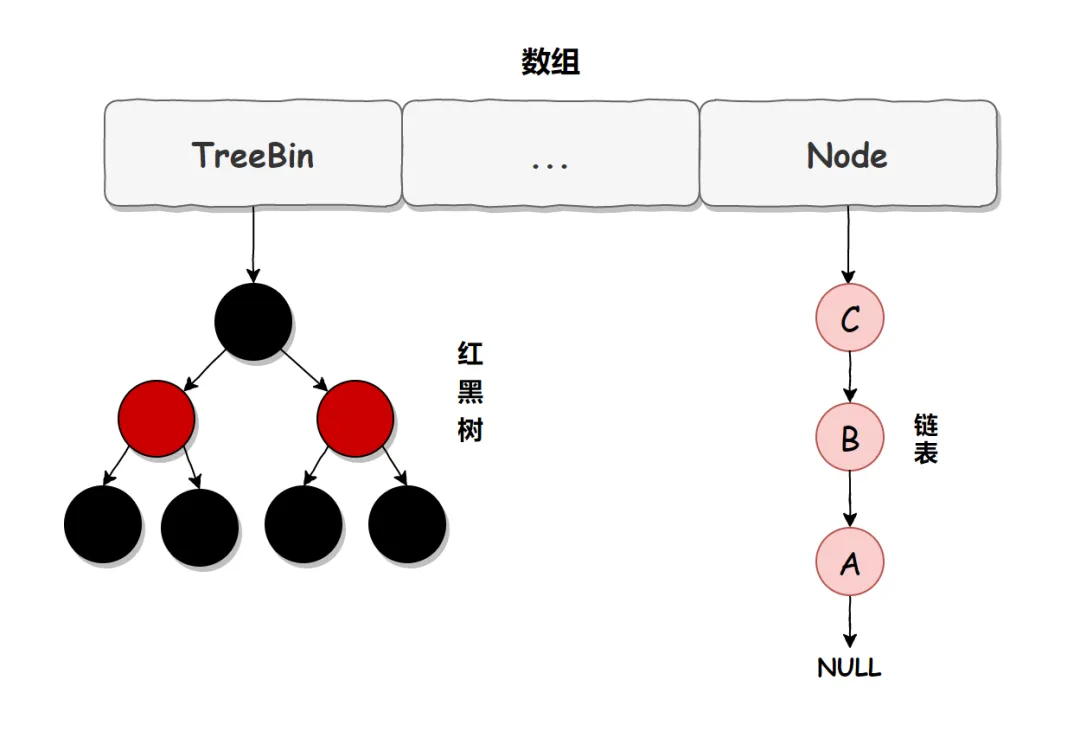
ConcurrentHashMap 已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
链表升级为红黑树的规则:当链表长度大于 8,并且数组的长度大于 64 时,链表就会升级为红黑树的结构。
2. JDK1.8 线程安全实现
部分源码如下:
1 final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); 2 int hash = spread(key.hashCode()); 3 int binCount = 0; 4 for (Node<K,V>[] tab = table;;) { 5 Node<K,V> f; int n, i, fh; K fk; V fv; 6 if (tab == null || (n = tab.length) == 0) 7 tab = initTable(); 8 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 节点为空 9 // 利用 CAS 去进行无锁线程安全操作,如果 bin 是空的 10 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value))) 11 break; 12 } 13 else if ((fh = f.hash) == MOVED) 14 tab = helpTransfer(tab, f); 15 else if (onlyIfAbsent 16 && fh == hash 17 && ((fk = f.key) == key || (fk != null && key.equals(fk))) 18 && (fv = f.val) != null) 19 return fv; 20 else { 21 V oldVal = null; 22 synchronized (f) { 23 // 细粒度的同步修改操作... 24 } 25 } 26 // 如果超过阈值,升级为红黑树 27 if (binCount != 0) { 28 if (binCount >= TREEIFY_THRESHOLD) 29 treeifyBin(tab, i); 30 if (oldVal != null) 31 return oldVal; 32 break; 33 } 34 } 35 } 36 addCount(1L, binCount); 37 return null; 38 }
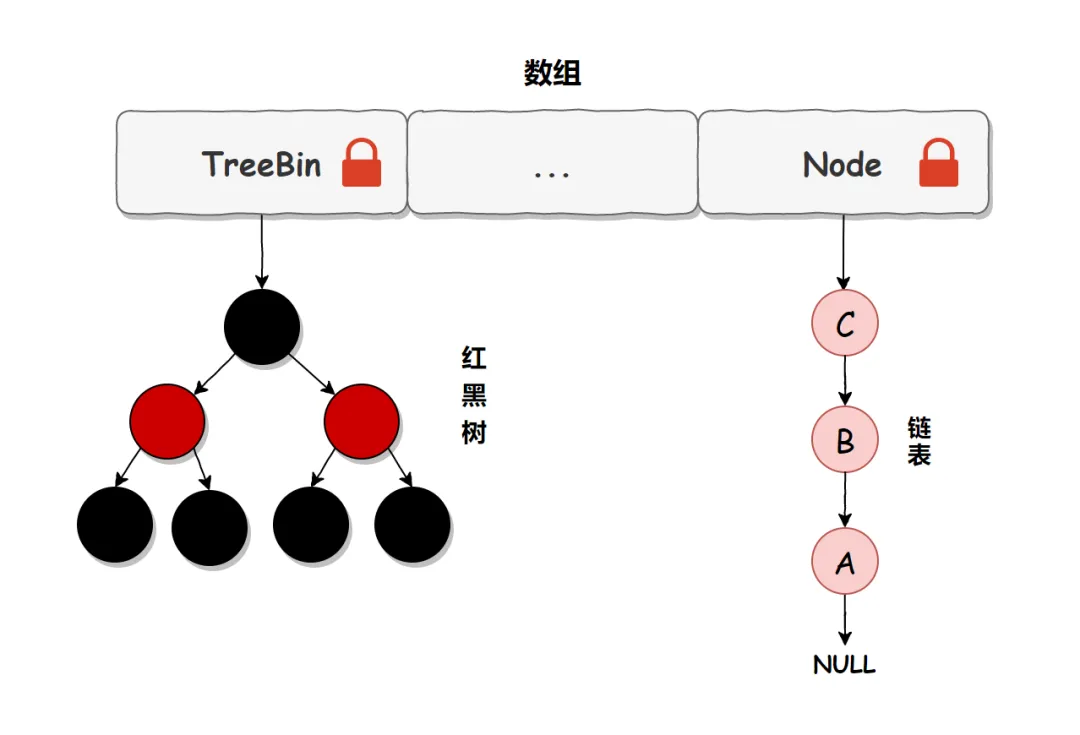
从上面的源码可以看出,在 JDK 1.8 中,添加元素时首先会判断容器是否为空,如果为空则使用 volatile 加 CAS 来初始化。如果容器不为空则根据存储的元素计算该位置是否为空,如果为空则利用 CAS 设置该节点;如果不为空则使用 synchronize 加锁,遍历桶中的数据,替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
上述流程简化一下,我们可以简单地认为:在 JDK 1.8 中,ConcurrentHashMap 是在当前链表或红黑二叉树的首节点来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。而且 JDK 1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度。
如下图:
三、JDK1.7和JDK1.8的ConcurrentHashMap实现的区别
- Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值(默认为8)时,将链表转换为红黑树)。
- 并发度:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
总结一下:
1) 在 JDK 1.7 时,ConcurrentHashMap使用的是数组+链表的形式实现的,其中数组分为两类:大数组 Segment 和小数组 HashEntry,而加锁是通过给 Segment 添加 ReentrantLock 锁来实现线程安全的。
2)在JDK 1.8 中 中,ConcurrentHashMap 使用的是数组+链表/红黑树的方式实现的,它是通过 CAS 或 synchronized 来实现线程安全的,并且它的锁粒度更小,查询性能也更高。
参考资料:
https://javaguide.cn/
https://www.51cto.com/article/795865.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号