分布式系统关键技术:流量与数据调度
1、流量调度与服务治理的关系
服务治理时内部系统的事,流量调度可以是内部的,更是外部接入层的事。服务治理时数据中心的事,而流量调度要做的好,应该是数据中心之外的事,也就是我们常说的边缘计算或者CDN。
2、流量调度的主要功能和关键技术
流量调度系统应该主要具备的功能:
- 依据系统运行的情况,自动地进行流量调度,在无需人工干预的情况下,提升整个系统的稳定性;
- 让系统应对爆品突发事件时,在弹性计算扩所容的较长时家窗口内或底层资源消耗殆尽的情况下,保护系统平稳运行;
- 服务流控:服务发现、服务路由、服务降级、服务熔断、服务保护;
- 流量控制:负载均衡、流量分配、流量控制、异地灾备(多活);
- 流量管理:协议转换、请求校验、数据缓存、数据计算。
流量调度的关键技术(API Gateway)
- 高性能:必须具备高性能的技术(如:采用高性能的语言编写);
- 扛流量:要能抗流量就要使用集群技术,在集群技术中关键技术是要在集群的各个节点进行数据共享,这就需要使用Paxos、Raft、Gossip这样的通讯协议;
- 业务逻辑:需要具有简单的业务逻辑;
- 服务化:需要能够通过Admin API来不停机地管理配置变更,而不是通过.conf文件来人肉的修改配置。
3、状态数据调度
对于服务调度的场景来说,最难办的就是有状态的服务了(这些服务会保存一些数据,并且这些数据不能丢失,需要随服务一起调度),对于这样的场景,一般来说可以通过“转移问题”的方法来让服务变成“无状态的服务”(把这些有状态的数据存储在第三方服务上,如:Redis、MySQL、ZooKeeper、NFS、Ceph的文件系统中)。于是服务就变成了“无状态服务”,Redis、MySQL则有了状态。
4、分布式事务一致性的问题
如果要让数据服务可以像无状态的服务一一样在不同的机器上进行调度,就需要让数据具有多个副本,多副本的场景下副本的一致性是非常关键的问题,要解决数据副本间的一致性问题时,通常的技术方案有:
- Master - Slave 方案:Slave一般是Master的备份,读写请求都由Master负责,写请求到Master上后,由Master同步到Slave上(通常是Slave周期的Pull)。
- Master - Master 方案:指的是在一个系统中存在两个或者多个Master,每个Master购提供read-write服务。数据间同步一版是通过 Master 间异步完成,所以是最终一致性。
- 两阶段和三阶段提交方案:
- Paxos方案:
针对以上几种方案的对比:
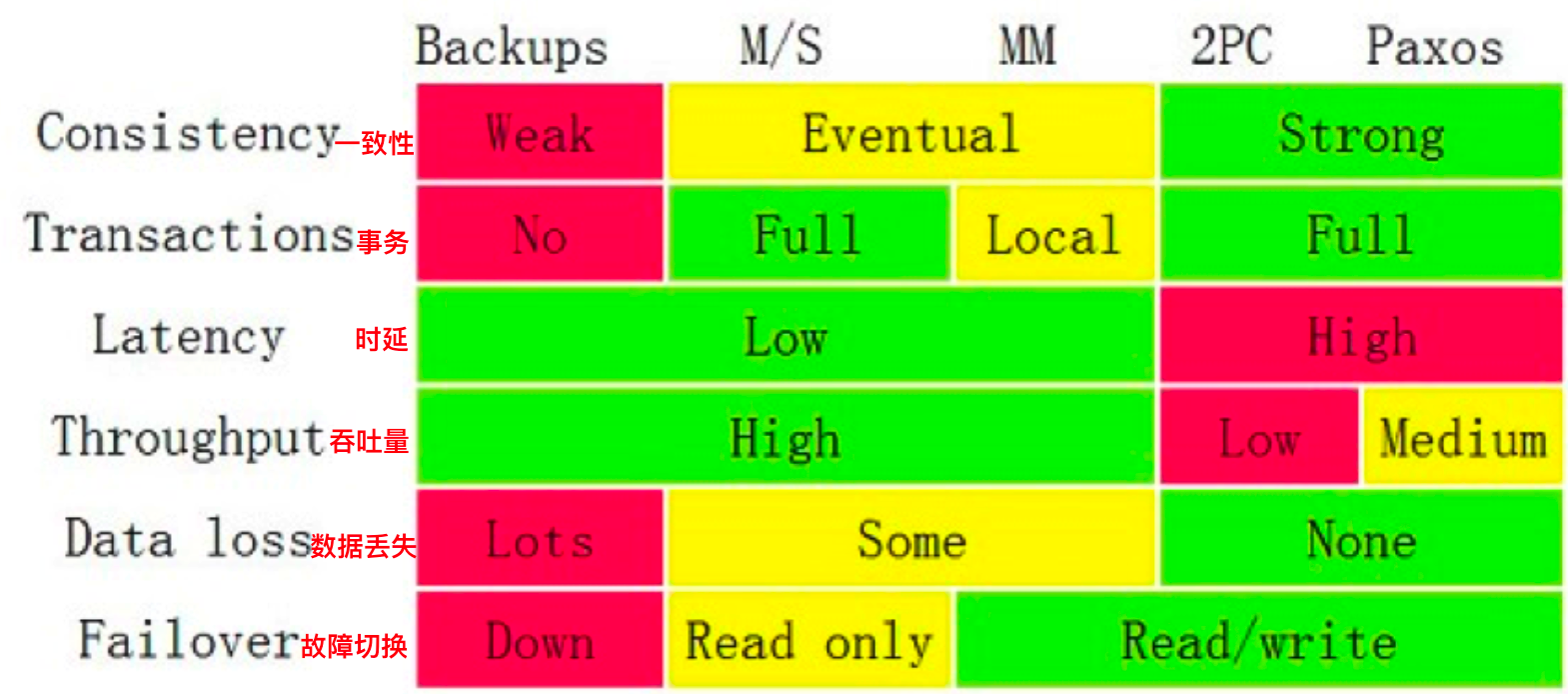
5、思考
1)什么是Scale
Scale 通常指的是规模的扩展性,即系统能够处理更多请求和数据的能力。这意味着分布式系统需要能够轻松地处理更多的用户请求、数据量和交互量,而不会崩溃或变得不可用。
Scale 通常涉及三个方面的扩展:硬件、软件和网络。硬件扩展包括使用更多的计算资源、存储资源和网络带宽,以支持更多的用户和请求。软件扩展包括使用更高级的算法、数据结构和编程语言,以提高系统的性能和可扩展性。网络扩展包括使用分布式缓存、负载均衡和消息传递技术,以提高系统的可用性和可靠性。
Scale 是分布式系统设计中非常重要的一个方面,它决定了分布式系统能够处理大量数据和请求的能力,以及系统的可扩展性和可用性。
6、参考文件
1)分布式系统关键技术:流量与数据调度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号