Elasticsearch系列之-windows安装和基础操作
ElasticSearch安装
安装JDK环境
因为ElasticSearch是用Java语言编写的,所以必须安装JDK的环境,并且是JDK 1.8以上
官网:https://www.oracle.com/hk/java/technologies/downloads/
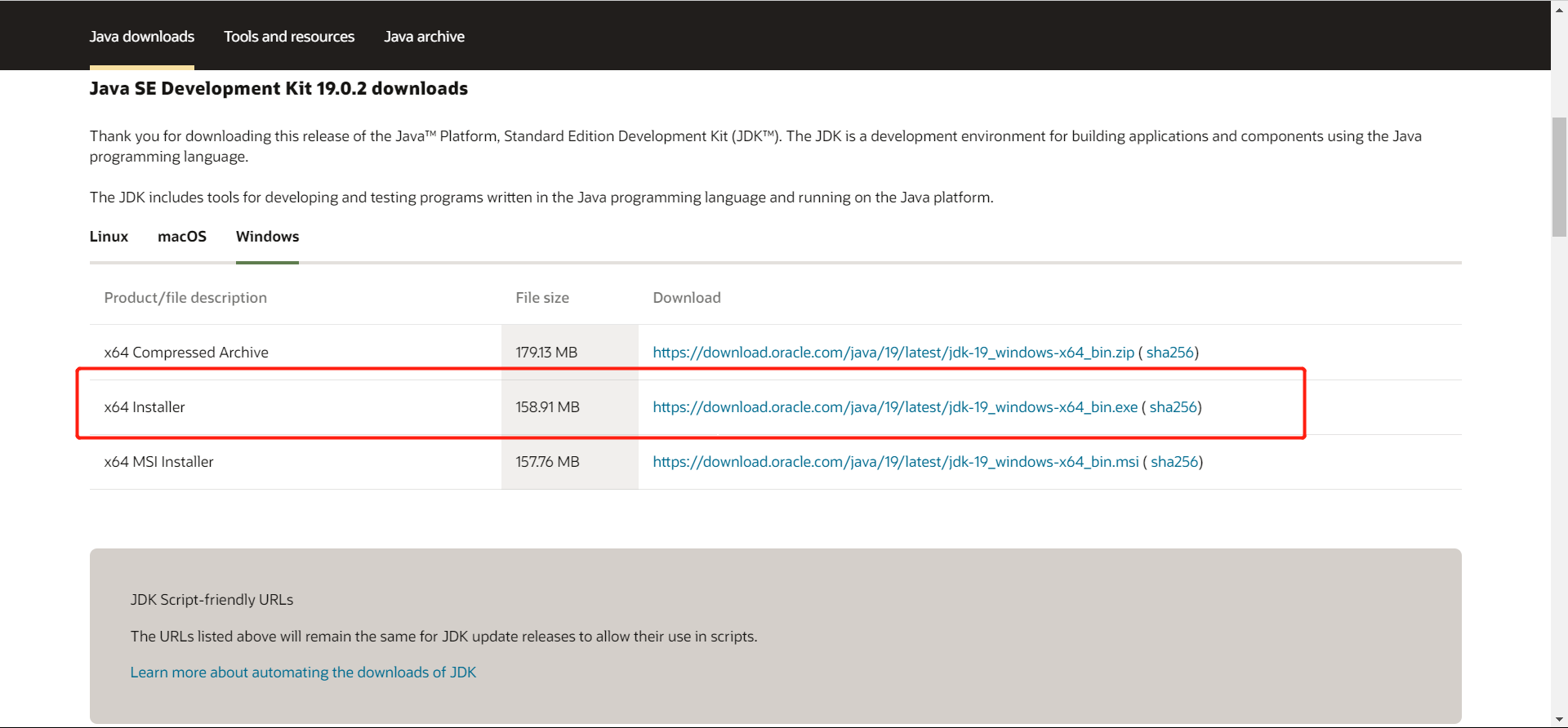
下载完后,配置环境变量
JAVA_HOME:jdk下载路径
ES官网下载最新版本
https://www.elastic.co/cn/downloads/elasticsearch
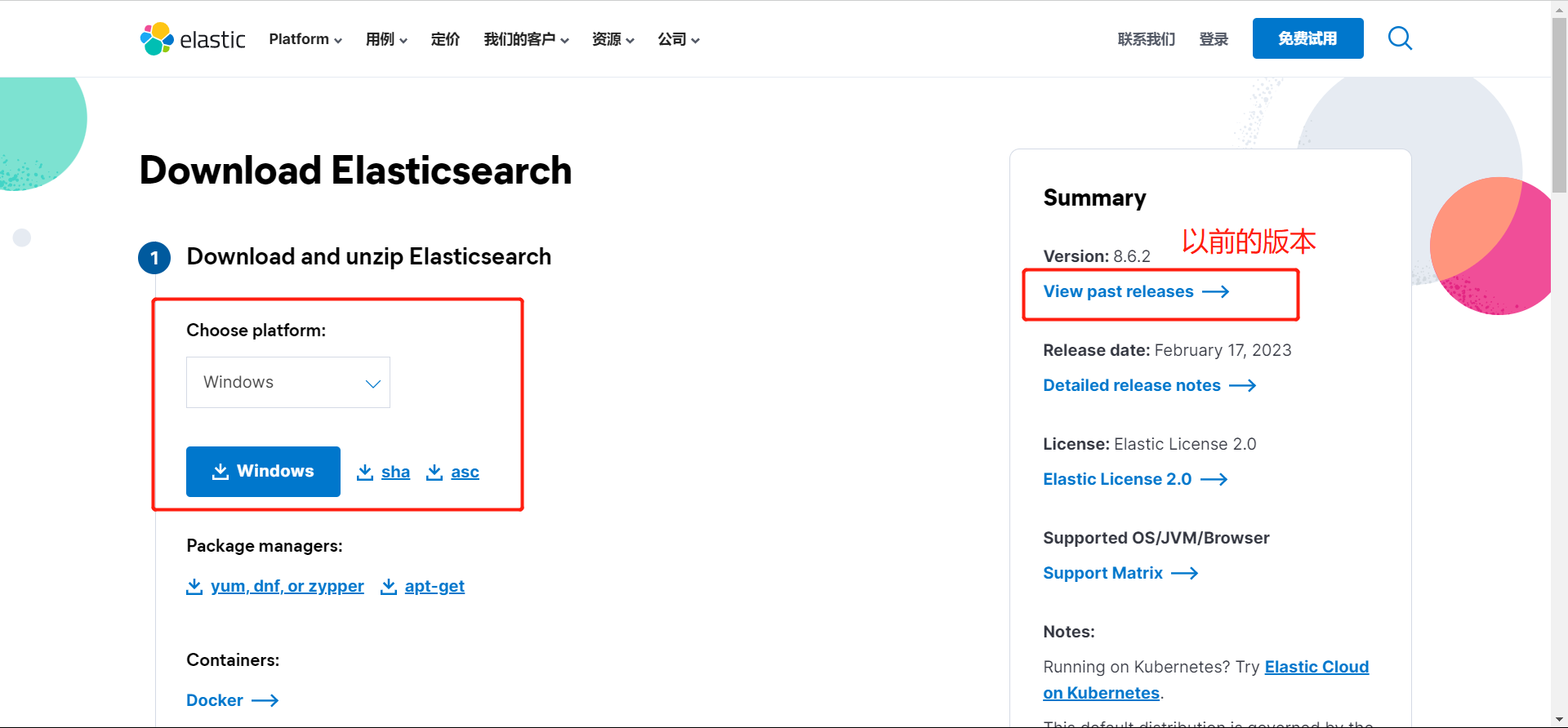
高版本自带了jdk

解压运行
下载的压缩包直接解压即可,bin目录下有elasticsearch,启动即可(可能过程会有点慢)
# Elasticsearch 可以作为一个守护进程在后台运行,在后面添加参数 -d 。
# 如果运行有这个报错:received plaintext http traffic on an https channel, closing connection Netty4HttpChannel,需要改一下配置
config/elasticsearch.yml
以下两处改为false即可
报错解决

启动成功截图

测试启动
# http://localhost:9200/
# 返回如下值,表示启动成功
{
"name": "HKWJSXL",
"cluster_name": "elasticsearch",
"cluster_uuid": "06EJyU5IR-SxulY4QHiiug",
"version": {
"number": "8.6.2",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "2d58d0f136141f03239816a4e360a8d17b6d8f29",
"build_date": "2023-02-13T09:35:20.314882762Z",
"build_snapshot": false,
"lucene_version": "9.4.2",
"minimum_wire_compatibility_version": "7.17.0",
"minimum_index_compatibility_version": "7.0.0"
},
"tagline": "You Know, for Search"
}
插件安装
elasticsearch的插件安装方式还是很方便易用的。它包含了命令行,url,离线安装三种方式。
核心插件随便选择一种方式安装均可,第三方插件建议使用离线安装方式
第一种:命令行
bin/elasticsearch-plugin install [plugin_name]
第二种:url安装
bin/elasticsearch-plugin install [url]
# bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.6/elasticsearch-analysis-ik-7.17.6.zip
第三种:离线安装
# https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.6/elasticsearch-analysis-ik-7.17.6.zip
# 点击下载离线包
# 将离线包解压到ElasticSearch 安装目录下的 plugins 目录下
# 重启es。新装插件必须要重启es
注意:插件的版本要与 ElasticSearch 版本要一致
插件安装:中文分词器
elasticsearch提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whitespace analyzer(空格分词器)、language analyzer(语言分词器)
而如果我们不指定分词器类型的话,elasticsearch默认是使用标准分词器的
我们需要下载中文分词插件,来实现中文分词
地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
# 下载分词插件
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.6/elasticsearch-analysis-ik-7.17.6.zip
# 要跟es版本一致,不一致ik要下载近似版本,在plugin-descriptor.properties文件中最后一行改为对应的es版本,比如elasticsearch.version=7.17.9
kibana安装
Kibana是一款开源的数据分析和可视化平台,Kibana一定要跟es版本对应
下载
官网下载:https://www.elastic.co/cn/downloads/past-releases#kibana
跟ES一样的操作,下载解压即用
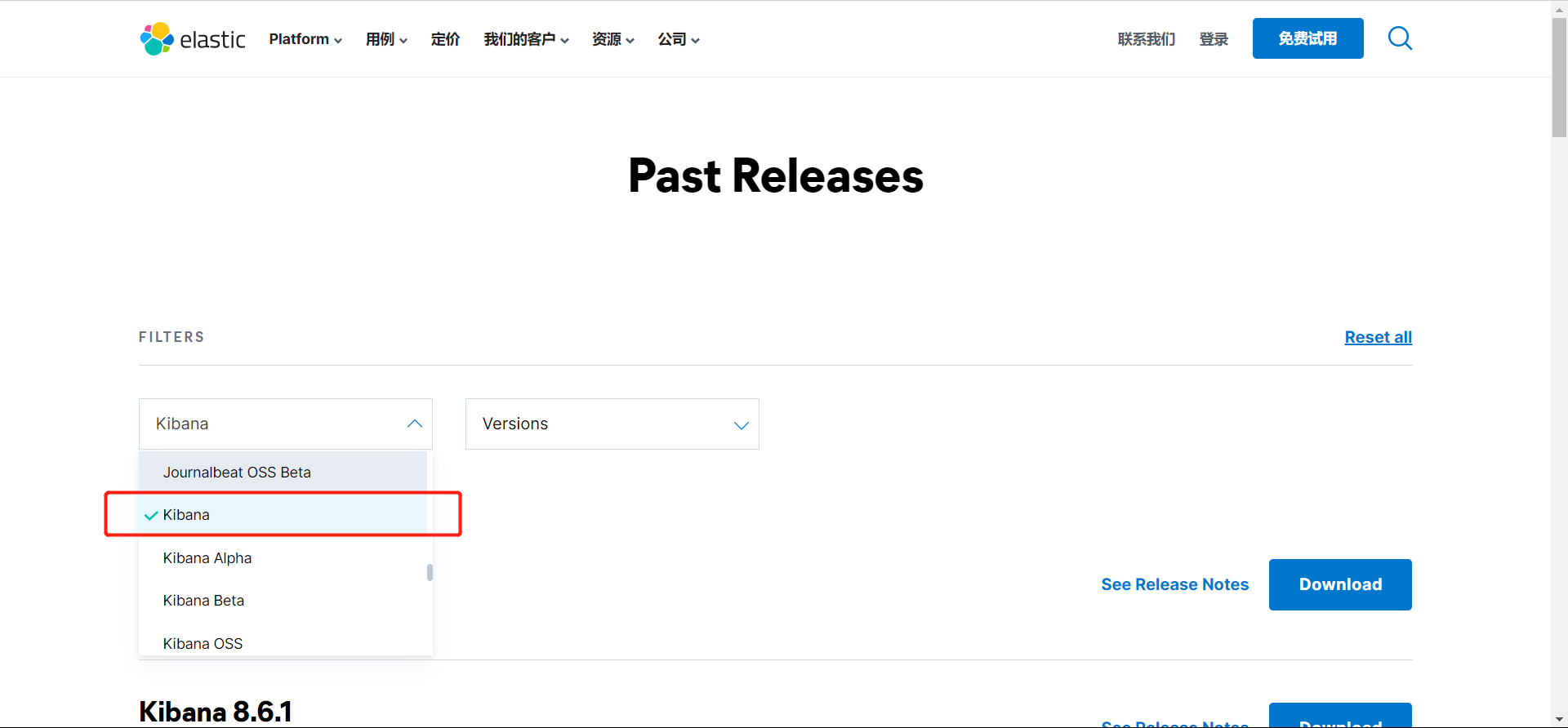
配置
# 修改kibana配置,直接在最后追加
/config/kibana.yml
# kibana监听的端口和地址
server.port: 5601
server.host: "127.0.0.1"
server.name: root
# 连接哪个es
elasticsearch.hosts: ["http://localhost:9200/"]
# 中文显示
i18n.locale: "zh-CN"
运行
直接运行bin下的kibana
浏览器打开:http://localhost:9100/,kibana运行后需要一分钟只有时间才能打开页面
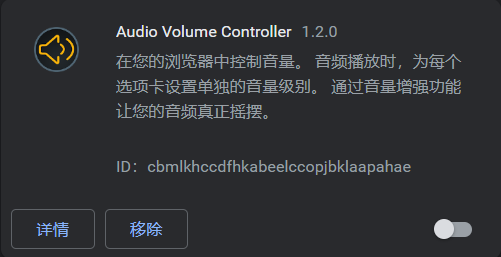
出现以下页面,可能是插件的原因,开个无痕窗口就行。(我这里是一个管理音量的插件引起的)

elasticsearch-head安装
elasticsearch-head是elasticsearch的一款可视化工具(第三方开发),依赖于node.js ,所以需要先安装node.js
安装nodejs
nodejs官网下载:https://nodejs.org/en/download/
node -v
# 显示版本号即安装成功
配置阿里源
# 切换阿里源
npm config set registry https://registry.npm.taobao.org/
# 查看是否成功
npm config get registry
# 或者
npm get registry
安装cnpm
# npm是国外的服务器,cnpm是淘宝的,速度会快点
npm install -g cnpm --registry=https://registry.npm.taobao.org
# 查看是否安装成功
cnpm -v
# 成功后可以使用cnpm代替npm命令
安装grunt
head插件需要通过grunt启动
cnpm install -g grunt-cli,-g表示全局安装
grunt -version查看版本
下载head
下载前可以前解决掉跨域问题
# 修改 Elasticsearch 安装目录中config 文件夹下 elasticsearch.yml 文件,加入下面两行:(:后必须空格,不然启动闪退)
http.cors.enabled: true
http.cors.allow-origin: "*"
重启es
github下载地址:https://github.com/mobz/elasticsearch-head
# 解压后切换到目录下
cd elasticsearch-head
# 通过npm安装依赖
cnpm install
# 启动
cnpm run start
# 在浏览器里打开
http://localhost:9100/
倒排索引
倒排索引:对文章进行分词,对每个词建立索引,这样建会出现索引爆炸,解决方法:索引跟标题建关系,标题再跟文章建索。
索引操作
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices.html
增删改查
# 新建索引
'''
number_of_shards
每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。
number_of_replicas
每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
'''
PUT t1
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
# 查看索引
# 获取test1索引的配置信息
GET t1/_settings
# 获取所有索引的配置信息
GET _all/_settings
# 同上
GET _settings
# 获取多个索引的配置信息
GET t1,t2/_settings
# 修改索引(一般不太用,只能用来修改副本数量)
PUT t1/_settings
{
"number_of_replicas": 2
}
# 如遇到报错:cluster_block_exception,因为
# 这是由于ES新节点的数据目录data存储空间不足,导致从master主节点接收同步数据的时候失败,此时ES集群为了保护数据,会自动把索引分片index置为只读read-only
PUT _all/_settings
{
"index": {
"blocks": {
"read_only_allow_delete": false
}
}
}
# 删除索引
DELETE t1
映射管理(类型)(表)
#1 在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个mapping type。 在5.x中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x中运行。 Mapping types将在Elasticsearch 7.0.0中完全删除
##索引如果不创建,只有插入文档,会自动创建
# 创建映射(类型,表)
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
###查看映射
GET lqz/_mapping
GET _all/_mapping
# 特殊说明索引映射都不存在,也可以插入文档
PUT lqz1/_doc/1
{
"title":"白雪公主和十个小矮人",
"price":"99",
"addr":"黑暗森里",
"publish_date":"2018-05-19",
"name":"lqz"
}
# 查看索引
GET lqz/_settings
#查看映射
GET lqz/_mapping
文档操作
文档基本增删查改
"""插入文档"""
PUT books/_doc/1
{
"title":"大头儿子小偷爸爸",
"price":100,
"addr":"北京天安门",
"company":{
"name":"我爱北京天安门",
"company_addr":"我的家在东北松花江傻姑娘",
"employee_count":10
},
"publish_date":"2023-08-19"
}
PUT books/_doc/2
{
"title":"白雪公主和十个小矮人",
"price":"99",
"addr":"黑暗森里",
"publish_date":"2022-05-19"
}
PUT books/_doc/3
{
"title":"白雪公主和十个小矮人",
"price":"99",
"addr":"黑暗森里",
"publish_date":"2020-05-19",
"name":"hkw"
}
"""查询文档"""
# 查询id为1的文档
GET books/_doc/1
# 只要title字段
GET books/_doc/1?_source=title
# 只要title和price字段
GET books/_doc/1?_source=title,price
# 要全部字段
GET books/_doc/1?_source
# 查询name字段是hkw的所有人
GET books/_doc/_search?q=name:hkw
# 结构化查询
GET books/_doc/_search
{
"query": {
"match": {
"name": "hkw"
}
}
}
"""修改文档两种方式"""
# 第一种(会覆盖原来的)
PUT books/_doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
# 第二种(局部修改,不会覆盖没有修改的)
POST books/_update/1
{
"doc": {
"desc": "皮肤很safasdfsda黄,武器很长,性格很直",
"tags": ["很黄","很长", "很直"]
}
}
"""删除文档"""
DELETE books/_doc/1
批量操作之_mget
# 批量查询
# 批量获取t1索引_doc类型下id为1的数据 和 t2索引_doc类型下id为1的数据
GET _mget
{
"docs":[
{
"_index":"t1",
"_type":"_doc",
"_id":1
},
{
"_index":"t2",
"_type":"_doc",
"_id":1
}
]
}
# 批量获取t1索引下id为1和2的数据
GET t1/_mget
{
"docs":[
{
"_id":2
},
{
"_id":1
}
]
}
# 同上
GET t1/_mget
{
"ids":[1,2]
}
批量操作之bulk
PUT t1/_doc/2/_create
{
"field1" : "value22"
}
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
模糊查询
match_all:查询所有
match_phrase:短语查询
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
"query": "中国世界",
"slop": 2 # 中国和世界之间最多间隔2个字符
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号