网络安全-进程管理
系统进程管理
进程程序之间区别
程序是数据和执行集合,是一个静态的概念,比如系统中常见的二进制文件,同时程序可以长期存在系统中;
进程是程序运行的过程,是一个动态的概念,进程是存在生命周期的概念的,会随着程序的终止而销毁;
进程运行生命周期
当父进程接收到任务调度时,会通过fork派生子进程来处理,所以子进程会继承父进程属性:
子进程在处理任务代码时,父进程其实不会进入等待,其运行过程是由linux系统进行调度的;
子进程在处理任务代码后,会执行退出,然后唤醒父进程来回收子进程的资源;
子进程在处理任务代码中,如果出现异常退出,而父进程没有回收子进程资源,会导致子进程运行实体消失,但仍然在内核的进程表中占据一条记录,长期下去对于系统资源是一种浪费;(僵尸进程)
子进程在处理任务代码中,父进程退出了,子进程没有退出,那么子进程就没有父进程来管理了;交由系统的system进程管理;(孤儿进程)
说明:每个进程都有父进程(PPID),对应的子进程为(PID)。
[root@hkw ~]# ps -ef
系统进程状态监控
# ps命令是“process status”的缩写,ps命令用于显示当前某一时刻系统的进程状态。
# 系统中出现的进程信息会有两类:用户操作运行的进程/系统运行产生的进程
01 -a 显示所有终端下执行的程序;
02 -A 显示系统中存在的所有程序信息
03 -u 显示进程所管理的用户信息,以及其他更详细的进程使用情况
04 -x 显示所有程序不以终端来区分,包含系统运行的进程
05 -e 此选项的效果和指定A选项相同
06 -f 显示更加详细的进程信息,包含UID,PPID等信息。
# 说明:以上参数在企业中经常采用组合方式使用:ps -ef (信息更简洁) / ps -aux(包含资源占用情况)
[root@hkw ~]# ps -aux
# 列信息说明
01 USER 管理此进程或运行此进程信息的用户名称,每个进程都要有一个用户管理
02 PID 此进程的编号标识信息,也是一个子进程编号
03 %CPU 进程运行过程中占用CPU资源的百分比
04 %MEM 进程运行过程中占用内存资源的百分比
05 VSZ 虚拟内存的使用情况,单位是kb(表示最大使用的内存情况 类似建筑面积)
06 RSS 实际内存的使用情况,单位是kb(表示进程运行实际内存使用情况 类似使用面积)
07 TTY 表示连接主机的终端类型;?表示是系统运行的进程
08 STAT 表示进程的运行状态情况,需要重点关注
09 START 表示进程启动的时间信息,什么时候出现的进程
10 TIME 表示进程运行过程中占用了CPU多长时间的资源
11 COMMAND 表示进程运行调用的命令(代码程序)是什么 []表示系统内核启动的进程
# 进程状态信息详述
状态标识
01 R 可以被CPU调度加载的执行或运行的状态
02 S 可将进程进行中断和睡眠挂起的状态
03 T 可以表示进程处于暂停状态或跟踪状态
04 D 不可中断睡眠状态
05 Z 进程处于僵尸状态
状态符号
01 s(a session leader) 进程是控制进程,Ss进程的领导者,即父进程
02 <(high-priority) 进程运行在高优先级上,S<表示优先级较高的进程
03 N(low-priority) 进行运行在低优先级上,SN表示优先级较低的进程
04 +(in the foreground process group) 当前进程运行在前台,R+表示该进程在前台运行
05 l(is multi-threaded) 进程是多线程的,Sl表示进程是以线程方式运行
pstree命令
# Linux系统中pstree命令的英文全称是“process tree”,即将所有行程以树状图显示;
树状图将会以 pid (如果有指定) 或是以systemd这个基本行程为根 (root),如果有指定使用者 id;
则树状图会只显示该使用者所拥有的行程。
# centos7 系统中默认没有pstree命令,需要先进行安装
[root@hkw ~]# yum install -y psmisc
01 -a 显示启动每个进程对应的完整指令,包含启动进程的路径、参数等
02 -c 显示的进程中包含子进程和父进程
03 -h 列出树状图时,特别标明现在执行的程序
04 -n 根据进程PID号来排序输出,默认是以程序名称排序输出的
05 -p 显示进程的PID
06 -u 显示进程对应的用户名称
查看当前动态进程状态
# top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析;
top命令中按f可以查看显示的列信息,按对应字母来开启/关闭列,大写字母表示开启,小写字母表示关闭。
带*号的是默认列。
01 -d 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
02 -i 不显示任何闲置 (idle) 或无用 (zombie) 的行程
03 -n 更新的次数,完成后将会退出 top
04 -b 批次归档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到文件内
# 常见指令
01 h 查看获取帮助信息
02 1 显示所有CPU核心的负载情况(默认显示的是平均的)
03 z 以高亮显示数据信息
04 b 高亮显示处于R状态的进程信息
05 M 按照内存使用百分比排序输出
06 P 按照CPU使用百分比排序输出
07 q 退出top动态监控状态
# 输出内容信息说明
上半部分
01行 21:58:17 up 9:24 表示当前时间,以及系统运行了多久
2 users 多少用户在登录管理系统
load average 平均负载情况(每分钟 每五分钟 每十五分钟)
02行 xx total 表示系统中总的进程数量
xx running 表示系统中进程处于R状态数量
xx sleeping 表示系统中进程处于S状态数量
xx stopped 表示系统中进程处于T状态数量
xx zombie 表示系统中进程处于Z状态数量
03行 xx us 表示用户进程占用CPU百分比情况(用户控制的操作)
xx sy 表示内核进程占用CPU百分比情况(控制硬件的操作)
xx ni 表示优先级高的进程占用CPU百分比
xx id 表示系统CPU空闲状态的百分比(数值越大,表示服务器越空闲)
xx wa 表示系统CPU等待硬件资源处理任务的等待百分比(数据库存储数据)
xx hi 表示硬中断占用CPU的百分比
xx si 表示软中断占用CPU的百分比
xx st 表示服务器运行了很多的虚拟主机,虚拟主机占用了物理CPU资源百分比
下半部分
01列 PID 表示相应进程的标识信息,一般是子进程ID
02列 USER 表示相应进程的管理用户
03列 PR 表示相应进程任务的调度优先级
04列 NI 表示相应进程任务本身优先级数值
05列 VIRT 表示相应进程任务占用了多少虚拟内存(建筑面积)
06列 RES 表示相应进程任务占用了多少实际内存(使用面积)
07列 SHR 表示相应进程任务占用了多少共享内存(公摊面积)
08列 S 表示相应进程所处的进程状态
09列 %CPU 表示进程运行过程中占用CPU资源的百分比
10列 %MEM 表示进程运行过程中占用内存资源的百分比
11列 TIME+ 表示进程运行过程中占用了CPU多长时间的资源
12列 COMMAND 表示进程运行调用的命令(代码程序)是什么
系统进程状态管理
系统进程停止命令-kill
kill [参数] [进程号]
# kill命令默认使用信号为15,用于结束进程或工作。使用9表示强制杀死进程或作业。
01 -l 列出系统可以支持的进程控制信号
02 -s 指定向进程发送的控制信号
03 -a 处理当前进程时不限制命令名和进程号的对应关系
04 -p 指定处理进程时只打印相关进程的进程号,而不发送任何信号
linux信号
01 1) SIGHUP 表示重新加载服务配置文件
02 9) SIGKILL 表示强制杀死终止指定进程
03 15) SIGTERM 表示终止指定进程(默认使用的进程信号)
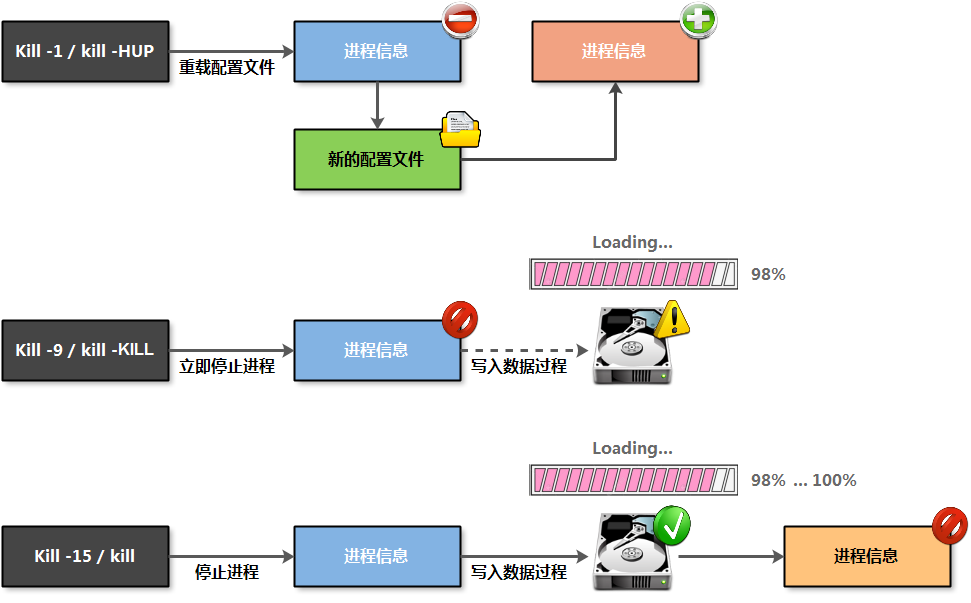
系统进程停止命令-pkill
pkill命令可以按照进程名杀死进程;pkill和killall应用方法差不多,也是直接杀死运行中的程序。
如果想杀掉单个进程,请用kill来杀掉。
01 -o 仅向找到的最小(起始)进程号发送信号
02 -n 仅向找到的最大(结束)进程号发送信号
03 -P 指定父进程号发送信号
04 -g 指定进程组
05 -t 指定开启进程的终端
系统进程停止命令-killall
killall命令使用进程的名称来杀死进程,使用此指令可以杀死一组同名进程。
默认此命令在系统中可能不存在,需要单独进行软件包安装部署。
[root@hkw ~]# yum install -y psmisc
01 -e 对长名称进行精确匹配
02 -l 输出所有已知信号列表
03 -p 杀死进程所属的进程组
04 -i 交互式杀死进程,杀死进程前需要进行确认
05 -r 使用正则表达式匹配要杀死的进程名称
06 -s 用指定的进程号代替默认信号“SIGTERM”
07 -u 杀死指定用户的进程
停止命令区别
总结:kill pkill killall三个杀进程命令之间区别:
kill:是可以杀死进程信息,会根据pid进行杀进程,多次杀进程会有提示信息
pkill:是可以杀死进程信息,会根据进程名进行杀进程,多次杀进程不会有提示信息
killall:是可以杀死进程信息,会根据进程名进行杀进程,但是命令软件程序包需要单独安装
后台进程管理命令
系统进程管理命令-jobs bg fg
- 命令-jobs 用于做查看工作的
主要可以用于显示任务号及其对应的进程号;
任务号是以普通用户的角度进行的,进程号是从系统管理员角度来看的;一个任务可以对应一个或者多个进程号。
- 命令-bg 将进程作业信息放入后台运行
用于将作业放到后台运行,使前台可以执行其他任务。
该命令的运行效果与在指令后面添加符号&的效果是相同的,都是将其放到系统后台执行。
- 命令-fg 将进程作业信息放入前台运行
用于将后台作业(在后台运行的或者在后台挂起的作业)放到前台终端运行。
与bg命令一样,若后台任务中只有一个,则使用该命令时,可以省略任务号。
jobs
01 -l 显示作业列表时包括进程号
02 -n 显示上次使用jobs后状态发生变化的作业
03 -p 显示作业列表时仅显示其对应的进程号
04 -r 仅显示运行的(running)作业
05 -s 仅显示暂停的(stopped)作业
bg
01 作业标识 指定需要放到后台的作业标识号
fg
01 作业标识 指定需要放到后台的作业标识号
screen
[root@hkw ~]# yum install -y screen
01 -A 将所有的视窗都调整为目前终端机的大小
02 -v 显示版本信息
03 -x ※ 恢复之前离线的screen作业,实现共享屏幕操作screen作业任务
04 -ls/-list ※ 显示目前所有的screen作业
05 -wipe 检查目前所有的screen作业,并删除已经无法使用的screen作业
06 -d<作业名称> ※ 将指定的screen作业离线(挂起)
07 -r<作业名称> ※ 将指定的screen离线作业恢复
08 -S<作业名称> ※ 指定screen作业的名称
09 -m 即使目前已在作业中的screen作业,仍强制建立新的screeN作业
10 -R 先试图恢复离线的作业,若找不到离线的作业,即建立新的screen作业
11 -s 指定建立新视窗时,所要执行的shell
[root@hkw ~]# screen
-- 输出组合键ctrl+a->d可以暂时退出screen操作界面
-- 输出组合键shift+alt+d表示彻底中止screen操作界面(等价于执行了exit命令)
# screen命令操作总结:
创建screen操作界面空间:screen -S 空间名称
查看screen操作界面空间:screen -list
进入screen操作界面空间:screen -r 空间编号/空间名称 (退出 ctrl+a+d 挂起 exit 彻底退出)
修改screen操作界面空间:screen -d 空间编号/空间名称 将指定空间设置为挂起状态
共享screen操作界面空间:screen -x 空间编号/空间名称 实现多个不同终端用户共享操作界面
# 说明:如何判断你在screen中,可以先按ctrl+a再按w,查看xshell或crt工具栏下方或上方会有提示显示
系统负载
系统平均负载案例实战
stress:是Linux系统压力测试工具,可以用作异常进程模拟平均负载升高的场景;
mpstat:是多核CPU性能分析工具,用来实时查看每个CPU的性能指标,以及所有CPU的平均指标;
pidstat:是常用的进程性能分析工具,用来实时查看进程的CPU、内存、I/O以及上下文切换等性能指标;
# 软件下载安装过程
[root@hkw ~]# yum install -y sysstat
[root@hkw ~]# yum install -y stress
# 软件升级部署过程
[root@hkw ~]# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm
[root@hkw ~]# rpm -Uvh sysstat-11.7.3-1.x86_64.rpm
模拟CPU密集型情况
1.在A终端运行stress命令,模拟一个CPU核心使用率100%场景:
[root@xiaoq ~]# stress --cpu 1 --timeout 600
2.在B终端运行uptime查看平均负载的变化情况
[root@xiaoq ~]# watch -d uptime
-- watch -d 表示高亮显示数据实时变化的信息
00:51:56 up 21:24, 8 users, load average: 0.98, 0.89, 0.58
-- 发现平均负载数值持续升高
3.在C终端运行mpstat查看CPU使用率的变化情况
[root@xiaoq ~]# mpstat -P ALL 5
-- -P ALL表示监控所有CPU,后面数字5表示间隔5秒输出一组数据
Linux 3.10.0-1127.el7.x86_64 (xiaoq.edu) xx/xx/xx _x86_64_ (2 CPU)
00:53:17 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
00:53:22 all 50.05 0.00 0.20 0.00 0.00 0.10 0.00 0.00 0.00 49.65
00:53:22 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
00:53:22 1 0.20 0.00 0.60 0.00 0.00 0.00 0.00 0.00 0.00 99.20
-- 如果是单核CPU,会显示只有一个all和0的CPU信息;
-- 如果是多核CPU,会显示所有CPU核心信息和总的核心使用率平均值
4.在B终端中可以看到:1分钟平均负载慢慢增加到将近1;
在C终端中可以看到:正好一个CPU核心的使用率为100%,但是iowait只有0;
说明平均负载的升高正是由于CPU使用率为100%;
如何获得哪个进程导致了CPU使用率为100%,可以使用pidstat来查询:
[root@xiaoq ~]# pidstat -u 5 1
-- 间隔5秒后输出一组数据
Linux 3.10.0-1127.el7.x86_64 (xiaoq.edu) _x86_64_ (2 CPU)
01:03:20 UID PID %usr %system %guest %CPU CPU Command
01:03:25 0 6238 100.00 0.20 0.00 100.00 0 stress
-- 这里明显看到,stress进程CPU使用率为100%
模拟IO密集型情况
1.在A终端运行stress命令,模拟系统磁盘I/O压力,即不停地执行sync:
[root@xiaoq ~]# stress --io 10 --timeout 600
-- 将数值调整为10,是为了给系统磁盘的I/O压力更大些
2.在B终端运行uptime查看平均负载的变化情况
[root@xiaoq ~]# watch -d uptime
15:46:54 up 1 day, 3:38, 3 users, load average: 5.50, 1.54, 0.57
3.在C终端运行mpstat查看CPU使用率的变化情况
[root@xiaoq ~]# mpstat -P ALL 5
-- -P ALL表示监控所有CPU,后面数字5表示间隔5秒输出一组数据
15:47:07 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
15:47:12 all 0.83 0.00 94.81 0.00 0.00 0.00 0.00 0.00 0.00 4.36
15:47:12 0 0.83 0.00 93.33 0.00 0.00 0.00 0.00 0.00 0.00 5.83
15:47:12 1 0.62 0.00 96.48 0.00 0.00 0.00 0.00 0.00 0.00 2.90
-- 可以看出内核态消耗的CPU资源更多
4.在B终端中可以看到:1分钟平均负载慢慢增加到将近1;
在C终端中可以看到:正好一个CPU核心的内核使用率为100%,但是用户使用率只有0.83;
说明平均负载的升高正是由于I/O压力增大造成;
如何获得哪个进程导致了I/O压力增加的,可以使用pidstat来查询:
[root@xiaoq ~]# pidstat -u 5 1
-- 间隔5秒后输出一组数据
Linux 3.10.0-1127.el7.x86_64 (xiaoq.edu) 01/29/22 _x86_64_ (2 CPU)
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 8394 0.20 21.16 0.00 65.07 21.36 - stress
Average: 0 8395 0.20 11.78 0.00 76.65 11.98 - stress
Average: 0 8396 0.40 16.17 0.00 71.46 16.57 - stress
Average: 0 8397 0.20 17.37 0.00 70.86 17.56 - stress
-- 可以看出,stress进程导致CPU资源占用,对应I/O压力升高
模拟CPU大量进程调用
当系统中运行进程超过CPU运行能力时,就会出现等待CPU的进程;
1.在A终端运行stress命令,模拟产生出8个进程情况:
[root@xiaoq ~]# stress -c 8 --timeout 600
2.在B终端运行uptime查看平均负载的变化情况
[root@xiaoq ~]# watch -d uptime
16:15:21 up 1 day, 4:07, 3 users, load average: 3.40, 7.00, 6.66
-- 由于系统CPU总核心数为2,明显比8个进程要少得多,因此系统的CPU处于严重过载状态
3.在C终端运行pidstat查看目前进程应用的情况
[root@xiaoq ~]# pidstat -u 5 1
-- 间隔5秒后输出一组数据
[root@xiaoq ~]# pidstat -u 5 1
Linux 3.10.0-1127.el7.x86_64 (xiaoq.edu) 01/29/22 _x86_64_ (2 CPU)
16:15:43 UID PID %usr %system %guest %wait %CPU CPU Command
16:15:48 0 9104 24.95 0.00 0.00 75.85 24.95 1 stress
16:15:48 0 9105 25.15 0.00 0.00 75.05 25.15 0 stress
16:15:48 0 9106 25.15 0.00 0.00 74.85 25.15 0 stress
16:15:48 0 9107 24.75 0.00 0.00 75.05 24.75 1 stress
-- 显示不同CPU核心的进程占用资源情况,但没有top命令查看的更加直观。
可以看出,8个进程在争抢2个CPU核心,每个进程等待CPU的时间(也就是命令输出%wait列)高达75%;
这些超过CPU计算能力的进程,最终导致CPU过载。
三种平均负载升高实战情况总结
| 序号 | 负载升高场景 | 平均负载变化 | use% | sys% | wait% | CPU整体使用率 | 磁盘IO消耗 |
|---|---|---|---|---|---|---|---|
| 01 | CPU密集型进程 | 升高 |
消耗多 |
消耗少 | 消耗少 | 使用率高(某个核心) |
磁盘消耗小 |
| 02 | IO密集型进程 | 升高 |
消耗少 | 消耗多 |
消耗多 |
使用率低 | 磁盘消耗大 |
| 03 | 大量进程产生 | 升高 |
消耗多 |
消耗少 | 消耗多 |
使用率高(所有核心) |
磁盘消耗小 |
异常问题处理思路总结
-
查看获取系统的负载情况:
可以利用uptime/w/top的命令进行查看获取。
-
查看分析系统的使用情况:mpstat
CPU使用率高的原因:进程等待高、内核态占用高、软中断数量多、更高优先级进程多。
-
查看哪个进程造成的问题:
可以利用top命令获取到哪个进程造成了CPU资源占用率高的情况。
-
追踪指定进程的运行情况:ps pidstat
可以通过命令追踪进程的整体运行情况,了解进程对应的服务信息。
-
根据服务的日志进行分析:
在追踪进程过程中获取到服务程序信息,可以根据服务程序产生的日志信息,细化分析具体问题原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号