
本次作业的相关要求:点这里
成员:
211611302 洪康 211605242 杨慧德
一、单元测试
测试思路:
- 因为很多方法都是有返回值的,这样的方法是比较好测试的,只要返回值和预期相同即可。
- 把“调度场算法”和“计算后缀表达式”放在一起测试。传入一个正常的中缀表达式,如果能返回正确的计算结果,那测试就通过。
- 检验用户输入正确与否时,当用户输入错误会直接结束程序。因此测试的时候,主要是测试“正则表达式”能否正确排查错误的输入。
- 出题部分的测试比较麻烦,比较难测试随机出的题目的正确性,只能人工检查。
单元测试代码
@Parameters
public static Collection<Object[]>t(){
return Arrays.asList(new Object[][] {
{false,"-grade 100 -n 100"},
{false,"-grade 0 -n 3"},
{false,"-n 1"},
{false,"-na 1"},
{false,"-n 100 -grade 2.3"},
{false,"-n 0 -grade 3"},
{true,"-n 1 -grade 2"},
{true,"-n 100 -grade 2"},
{true,"-grade 3 -n 3"}
});
}
这段代码是检查用户输入是否符合规范。
测试覆盖率截图

二、结构优化(重构)
要区别设计良好的模块与设计不好的模块,最重要的因素在于,这个模块对于外部的其他模块而言,是否隐藏其内部数据和其他实现细节。设计良好的模块会隐藏所有的实现细节,把它的API与它的实现清晰地隔绝开来。然后,模块之间只通过它们的API进行通信,一个模块不需要知道其他模块的内部工作情况。这个概念被称为信息隐藏(infomation hiding)或封装(encapsulation),是软件设计的基本原则之一。
封装之所以非常重要,一大原因就是:它可以有效地解除组成系统的各模块之间的耦合关系,使得这些模块可以独立地开发、测试、优化、使用、理解和修改。这样可以加快系统开发的速度,因为这些模块可以并行开发,它也减轻了维护的负担,因为程序员可以更快地理解这些模块,并且在调试它们的时候可以不影响其他的模块。
封装提高了软件的可重用性,因为模块之间并不紧密相连,除了开发这些模块所使用的环境之外,它们在其他环境往往也很有用。最后,封装也降低了构建大型系统的风险,因为即使整个系统不可用,但是这些独立的模块却有可能是可用的。
上面这段话摘自《Effective Java》。
我在“第一次结对作业”中,本来是想不做大改动,直接在一二年级功能的基础上扩展三年级的混合运算,结果这个“扩展”让我大吃苦头。虽然我在代码中分了不少类,并且用了“简单工厂”来进行模块化设计,但由于我分的各个类相互依赖,互相调用,所以即使是只做了一个小小的改动,也得在多处地方进行修改调试,
就是在《Effective Java》中看到这段话后,我才明白是因为我代码的各个模块之间耦合度过高,所以才导致代码的扩展性和维护性不如人意。
所以,我这次的作业主要时间都花在代码的“解耦”上,想办法增强模块的独立性,减少类与类之间的通信,这又不得不提到设计模式的原则之一:迪米特法则。
迪米特法则(LoD):如果两个类不必彼此直接通信,那么这两个类就不应该发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
迪米特法则可降低系统的耦合度,使类与类之间保持松散的耦合关系。
在实际操作中,我重构代码的思路为:
- 增强封装性,使尽量少的类或者成员被外界访问。
- “解耦”,提高模块的独立性。具体操作为:不让各个类相互调用,让一个类“知道”尽量少的类。如果一个类需要调用另一个类的某一个方法的话,通过第三方类来转发这个调用。
重构后的UML图:
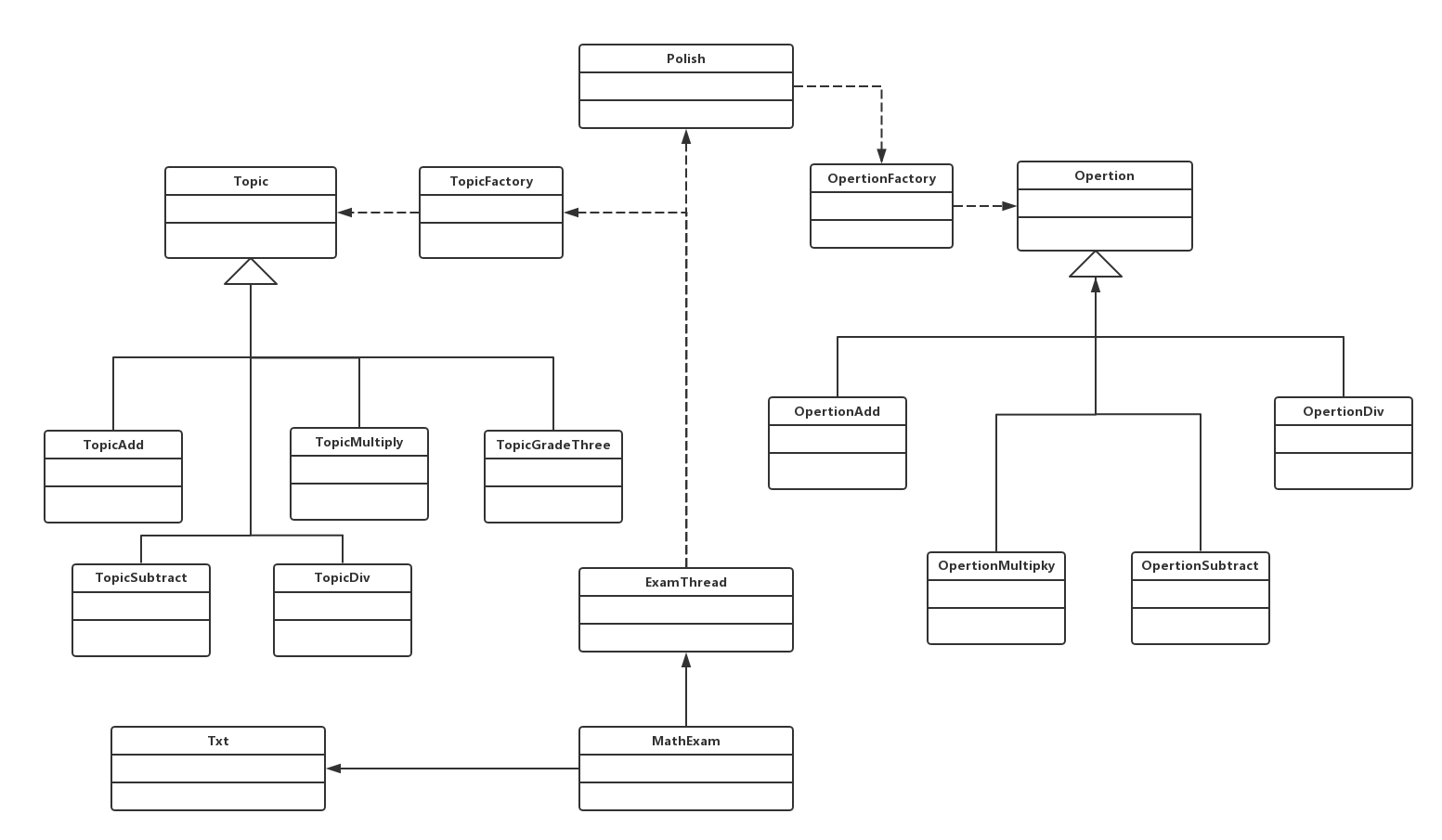
模块介绍
- MathExam:包含主方法的类,功能:检查用户输入、创建线程生成题目、将生成的题目传递给Txt类。
- Txt:生成文本
- ExamThread:该类实现了Runnable接口,可以并发地生成题目和答案。
- Topic:生成各个年级的题目。Topic类为父类,它有五个子类。TopicFactory会根据不同的年级,返回Topic类的子类对象,生成相对应年级的题目。
- Polish:将生成的题目(中缀表达式)转化为后缀表达式,并对后缀表达式进行计算。
- Opertion:根据不同符号进行运算。Opertion类为父类,它有四个“加减乘除”的子类。OpertionFactory会根据不同的符号,返回Opertion类的子类对象,得到运算结果。
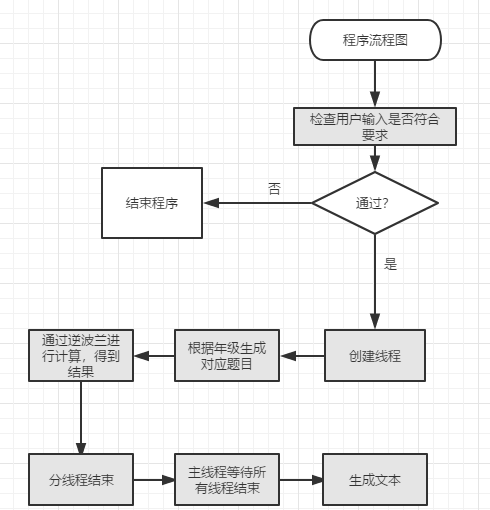
流程图
三、性能调优
关于性能优化,我一开始想到的就是运用多线程。多线程的知识有在上学期学习过,但一直很少在实战中运用,这次也算练练手。
比如说一次出两百道题,线程数为2。只需要让线程no.1负责前一百道,线程no.2负责后一百道,主线程只要等待两个线程都执行完毕后,把两个线程生成的字符串再整合起来,就可以进行文本的生成了。
多线程比较需要注意的就是静态变量,因为如果同时对一个静态变量进行修改的话,就很容易产生BUG。但我的代码中的变量大部分都是实例变量,仅有的几个静态变量都只进行"读"的操作,不会对其进行修改。所以也不需要上锁,在主线程中用线程的join方法就可以等待其他线程,然后同时生成题目了。
关于测试代码性能,我主要用两个方式来进行测试
1. 直接记录程序运行时间
2. Jprofiler效能工具
直接记录运行时间是采用如下的代码,在main方法的开头和结尾都记录时间,然后用末尾的时间减去开头的时间,就作为程序的运行时间。
public static void main(String[] args) {
long timeStart = System.currentTimeMillis(); //开始时间
...
...
long timeEnd = System.currentTimeMillis(); //结束时间
System.out.println(timeEnd - timeStart + " ms");
}
-
暂时撤销出题数的限制后,经过多次测试,出10万道三年级题目的运行时间为:
- 单线程:1473 ms
- 双线程:1037 ms
- 四线程:900ms
-
出100万道三年级题目的运行时间为:
- 单线程:10300 ms
- 双线程:6100 ms
- 四线程: 4300 ms
在出题数较大的前提下,可以看出多线程确实能显著地缩短运行时间。
不过如果是用 Jprofiler 进行测试,就....
一百万道题,单线程:
![]()
一百万道题,双线程:


很纳闷的是,时间不仅没缩短,还稍稍增加了少许,这个结果我确实想不通,因为无论是通过第一种方式测运行时间还是通过我主观上的感觉(4s和10s还是很容易感受出来区别的),我的多线程应该都是能有效提升效率的,但不知道为什么 Jprofiler 并不认可.....
