

New Machine Learning Server for Deep Learning in Nuke(翻译)
Posted on 2019-07-09 12:04 SolHe 阅读(3145) 评论(0) 编辑 收藏 举报最近一直在开发Orchestra Pipeline System,歇两天翻译点文章换换气。这篇文章是无意间看到的,自己从2015年就开始关注机器学习在视效领域的应用了,也曾利用碎片时间做过一些算法移植的工作,所以看到这篇文章的时候很有共鸣,遂决定翻译一下。
原文链接:https://www.fxguide.com/fxfeatured/new-machine-learning-server-for-deep-learning-in-nuke/
正文:
Recent years have seen the arrival of Machine Learning (ML) research into the area of visual effects. From noise reduction to facial pipelines, Deep Learning has proven to be a rich tool for major effects projects. One of the hallmarks of Machine Learning and Deep Learning, as we discuss in the next section, has been the widescale publishing and sharing of code and libraries. Gone are the days of submitting a paper to SIGGRAPH and then waiting to have it accepted, then published and then a few years later appear in a product. Today work is posted on sites before it is accepted to conferences, with even key advances sometimes being seen first on social media, years before it might appear in a journal or conference proceeding.
近年来机器学习的研究已经进入了视效领域。从去噪到面部制作流程,对于一线视效项目,深度学习都被证明是一个潜力无限的工具。正如我们在文章下一段将要讨论的,机器学习和深度学习有一个特点,就是它们的成果在发表的同时,都会分享相关的代码和库。向SIGGRAPH提交论文,等待审核通过,再公开发表,几年之后再出现在某个软件中,这种技术迭代方式已经过时了。在今天,相关工作成果会先于学术会议,提前发表在网站上,你甚至能在一些非专业的社交媒体上见到相关研究的实时进度,这比在学术期刊或者学术会议上正式发表要早好几年。可见非正式的媒体渠道已日渐重要,在这上面你甚至能得到相关研究的第一手资料。
The Foundry has responded to this new innovative, dynamic and collaborative world by releasing the ML-Server. This is not plug and play Gizmos for Nuke. The Foundry has instead released a Machine Learning environment that allows series TDs and engineers to work with these new algorithms and thus get new ideas and tools into the hands of their artists inside the visual effects and animation studios. This new ML-Server allows companies to start experimenting with ML within their existing pipelines and build on the enormous flood of research that is being published.
The Foundry公司顺势而为,用ML-Server(机器学习服务)来回应这个创新的、变化的、协作的新世界。ML-server既不是Nuke插件,也不是Nuke中的玩具gizmo,它是一个机器学习环境。The Foundry发布ML-Server,使得TD和工程师们能够使用ML-Server提供的新算法,将新的创意和工具提供给视效工作室的艺术家们。新的ML-Server允许工作室在已有流程上开展测试,并构建在已发布的研究成果之上。显然,The Foundry已经把ML-Server整合到自家产品的工作流当中了。
The newly introduced open-source ML-Server client/server system enables rapid prototyping, experimentation and development of ML models in post-production, within the familiar, rock solid structure of Nuke. Furthermore, key data, code and examples from the Foundry system can now be found on their GitHub repository page:https://github.com/TheFoundryVisionmongers/nuke-ML-server
新推出的开源ML-Server使得开发者能够在后期制作中快速的编写原型、充分实验、开发产品,而这一切都是基于Nuke稳定的内核结构的,开发者要要使用ML-Server并不需要再阅读一套新的Nuke开发文档。另外,在GitHub上已经能下载The Foundry提供的数据、代码、样例了,链接如下(不得不吐槽这个账号下很多repository都是fork的):
https://github.com/TheFoundryVisionmongers/nuke-ML-server
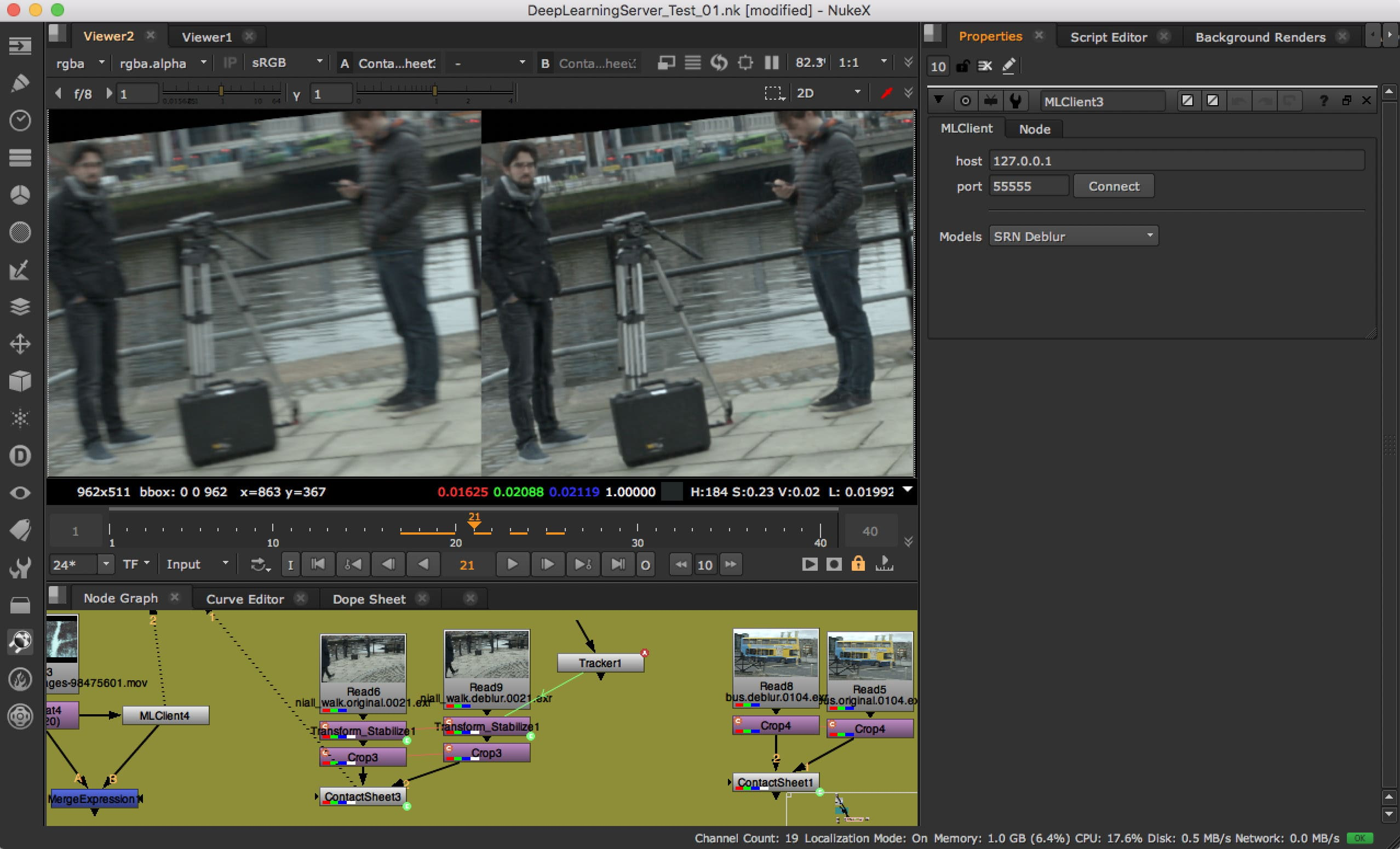
ML-Server is essentially a really thin client that connects to an IP address. This machine runs the project’s deep learning inference on a Python instance. This means you can take your Tensorflow or Cafe ML libraries and whatever models or data and set them up on the Server. Once set up, you are able to send out an image to the Server and perform some inference and send back a result.
在Nuke中,ML-Server为艺术家提供了一个MLClient节点,这个节点是一个轻量客户端,它需要连接到服务端的IP地址。服务端所在机器会在一个Python进程上运行Nuke工程的深度计算。你可以在节点上选择Tensorflow或者Cafe ML或者任意其他模型数据并设置,在上图中MlClient就选择的尺度循环网络去模糊(SRN Deblur)的模型。一旦设置完毕,节点就会向服务端发送图片进行深度学习的计算,并从服务端获取计算结果。在上图中,IP地址设置为127.0.0.1,即服务端就在本机。你可以认为ML-Server在Nuke中被拆分成了客户端和服务端两部分,客户端以节点的形式呈现,服务端则与Nuke主程序集成在一起,客户端与服务端以HTTP的方式进行通信(这里是我猜的)。
History: Deep Learning Primer – Why is it different?深度学习入门知识 -- 为什么与众不同?
To understand why the Foundry have taken this open approach one has to look at the recent history of Machine Learning and Deep Learning in particular.
Hugo Larochelle at Google Brain has one of the best recounts of why Deep Learning is different from other areas and therefore why the Foundry’s approach makes so much sense. Larochelle argues that Deep Learning is different from other software and research areas for three reasons, built around how the the Deep Learning community has structured itself to facilitate rapid innovation:
- Quickly after the major algorithmic or coding innovations, the DL community adapted to exploit the computation resources of GPUs and graphics cards.
- The community produced a lot of tools for performing Deep Learning research with very high quality open source code libraries. The community published tools and libraries that make getting started feasible and (almost) easy.
- The community become really good at discussing and sharing information about how to do Deep Learning.
为理解为什么The Foundry会采用这种开放的方式,你就需要专门关注下机器学习和深度学习的近期事件。
谷歌大脑(Google Brain)的Hugo Larochelle非常能说明深度学习与其他研究领域为什么不同,以及The Foundry的策略为什么可行。围绕深度学习社区如何自我构建并促进快速创新的话题,Larochelle认为深度学习之所以不同于其他软件和研究领域主要有三个原因:
- 深度学习的主要算法和代码有革新后,深度学习社区很快就适应并开始采用GPUs和显卡等计算资源。
- 社区开发了很多新工具,便于社区成员用高质量的开源代码做深度学习的研究。这些社区工具使得深度学习的入门变得非常轻松。
- 社区很善于讨论和分享深度学习的有关信息。
It was only about ten years ago that the modern version of a layer neural network took off. Prior to that, working on AI and Neural Networks was a career killer, academic suicide, no one wanted to know. Today AI experts in Deep Learning make rockstar ‘telephone number’ long salaries.
现代层级神经网络大约也就诞生了十年时间。更早的时候,搞AI和神经网络就意味着职业生涯、学术生涯的自我毁灭,谁都不愿谈论此事。反观今天,AI专家赚到的钱如同摇滚明星一样,工资位数电话号码等长。
One key aspect to this explosion was that the new approaches were moving rapidly to running on GPUs in about 2010. This meant that researchers anywhere could now have amazing computational power and develop code in a way that previously only a few researchers could do. GPUs love parallel processing and the modern Deep Learning approaches are very well suited to modern graphics cards. This continues today with, for example, Nuke running on a high end graphics card inside a high end PC, which is a perfect vehicle for Machine Learning.
产生这种爆发性变化的一个关键原因就是,从2010年开始,新的方法可以快速转移到GPUs上运行。这就意味着任何地方的研究人员都可以拥有惊人的算力,要知道在之前只有少部分的研究人员才能拥有这种算力资源来做开发。GPUs喜欢并行计算,而现代深度学习的研究与现代显卡的特性简直是无缝衔接。直到今天也是如此。而Nuke恰好又运行在配备了高端显卡的顶级PC上,这简直就是开展机器学习的完美设备!
Secondly, the community decided to not develop silos of confidential code. The research companies and the big tech companies decided in around 2013 to post libraries that make getting applications running much easier. High quality, robust, easy to use, open and free code libraries for supporting Deep Learning research, such as Theano and Torch and a few others, appeared and this fed rapid research into deep learning. This means that on Nuke it is possible to take advantage of vast amounts of code and just focus on your industry specific application.
第二个方面,社区决定开放所有代码。相关研究公司和大型技术公司在2013年左右也决定发布使得程序更易运行的深度学习库。更高质量、更稳定、更易使用、开放、免费的代码库支持了深度学习的研究,Theano、Torch以及一些其他的库被开发出来,并反哺了深度学习的研究。这就意味着在Nuke上,开发者可以利用已有的行业成果,把精力集中在开发新功能上,而非深度学习的学术细节。
This exploded into commercial applications around 2016, fired by the third structural difference – people no longer waited to publish. Authors skipped journals and conferences with long lead times, and they started posting their work publicly on websites such as arxiv.org. 2016 was also when Google released AlphaGo and the world ‘discovered’ the amazing impact Deep Learning could have.
上文提到的第三点原因引发了2016年的商业软件大爆发,研究者不再等待软件的发布。研究者们跳过了长周期的期刊和会议,他们开始在网站上公开发表自己的成果,比如arxiv.org。2016年也是谷歌发布AlphaGO的年份,在这一年,全世界都意识到深度学习可能产生的巨大影响。
What is a Deep Neural Network? 什么是深度神经网络?
Artificial neural networks, or Convolutional Neural Networks (CNNs), are computer programs that enable a machine to learn. They are inspired by our understanding of how human brains work. We will discuss Deep Learning more in a follow up article here at fxguide with Andrew Glassner, but one should not think that Deep Learning is actual intelligence. Glassner says that comparing CNNs and our brains is like comparing a toothpick to a giant deciduous forest. That being said, in Deep Learning, a convolutional neural network is a class of deep neural networks, most commonly applied to analyzing visual imagery.
人工神经网络或者卷积神经网络是一种赋予计算机思考能力的计算机程序。它们的诞生受到人类大脑工作方式的启发。我们会在Andrew Glassner后续的文章中详细讨论深度学习,但你不应该认为深度学习是一种真正的智能。Glassner认为,卷积神经网络之于人类大脑就如同牙签之于森林。当然这就是一个比喻。实际上卷积神经网络是深度神经网络的一种,卷积神经网络最常用于分析视觉图像。
At the core of an artificial neural networks is the artificial neuron. They are like real neurons, in that artificial neurons are connected. CNNs are regularized versions of multilayer perceptrons (or binary classifiers). They function as fully connected networks, that is, every neuron in one layer is connected to all the neurons in the next layer. It is called ‘Deep’ since it has many layers, unlike the original neural networks from decades past.
人工神经网络的核心就是人工神经元。它们能互相通讯,有如真神经元一般。卷积神经网络是多层感应机(或两类分类器)的正则版本。它们如同充分连接的网络,每一个层的每一个神经元都与下一层的所有神经元相连。之所以称之为“深度”,是因为这种网络有很多层,与十几年前的神经网络大相径庭。
What can Deep Learning do?深度学习能做什么?
Deep Learning is data driven and so is a different way of solving a problem. It is less prescriptive and more of a learning approach based on data. Luckily, in the modern computer age there is a lot of data, and hence a lot of applications. It is also not often that ML produces a correct answer but that it produces a ML inference. Something that is plausible and looks correct, but may not be actual reality, which is exactly in line with visual effects. If the shot looks right, it is, unlike say medical applications which comes with vast ethical issues.
深度学习是数据驱动的,所以它也是一种很另类的解决问题的方法。它不是限定条件的状态机,它更多的是一种基于数据的学习方法。很幸运,现代计算机时代中,数据多的是,应用也多的是。机器学习通常不会返回你正确的答案,它只是执行机器学习的计算。就跟我们的肉眼视觉一样,有时候看起来很合理,但可能并不是那么一回事。
There are countless examples but generally Deep Learning has excelled in object classification, object segmentation, identification, image synthesis, computer vision and many other features that are really helpful in visual effects. The single biggest impact that was directly felt in our industry was noise reduction. This is the noise reduction of ray tracing and not the older style of convolution filtering that is traditional image processing. Films such as Big Hero 6 were able to produce results far faster than anyone had thought possible. This led to NVIDIA introducing real time ray tracing with the RTX cards at SIGGRAPH last year.
虽然深度学习在生活生产中有不计其数的应用,但它一般还是更善于做对象分类、对象分割、识别、图像合成、计算机视觉,二者恰恰就是我们视效行业喜闻乐见的。我们行业能直观感受到的最大影响就是去噪点了。这是光线追踪的去噪,可不是传统图像处理的那种老式的卷积滤波方法。2014年的超能陆战队的制作速度就超乎预期,这也引得NVIDIA去年在SIGGRAPH上推出了实时光线追踪的RTX显卡。
Today there are great examples of relatively straightforward ML tools, such as the cloud based chroma-key tool “Blue Fairy”, which is a cloud based service that aims to reduce or eliminate the need for artists to create their own alpha, by using AI.
今天有很多相对简单的机器学习工具,比如基于云的抠像工具“Blue Fairy”,这是一个基于云服务,旨在减轻艺术家抠像压力的AI工具。
Blue Fairy的展示视频链接 (视频看不了就看原文吧)
下图为法国人Cronobo开发的Nexture, 用于增强皮肤微结构的细节和材质。

Nexture combines a state-of-the-art artificial neural network with a custom image synthesis algorithm, to transfer details from a reference pattern bank. This dataset was captured on actual human skin by the team at Cronobo. To quickly get up to speed, Nexture features a human-skin texture bank, included with the software and specifically tailored for texture transfer. It contains a diversity of 100 patterns commonly found on human skin at different scales.
Nexture软件把人工神经网络与自定义图像合成算法结合起来,把参考模式库中的图片细节赋予到原始贴图上。这个数据集由Cronobo团队在真实人类皮肤上采集获得。为了加快生成速度,Nexture包含了一个人类皮肤材质库,这样做可以优化材质传输的环节。它包含了人类皮肤上一百种不同尺寸的图案。

我们在之前的文章中也谈到过Roto-Bot。看名字你就知道,它解决的是合成领域最头痛的问题。
The real question is, what can you now do with Machine Learning inside Nuke?
既然看了那么多的案例,那么问题来了,现在在Nuke中机器学习都能做些什么?
ML-Server in NUKE (*Not for everyone) ML-Server In Nuke (在这里内容就硬核起来了)
While the tools and approaches that can now be experimented with using ML-Server will no doubt one day be standard features, for now ML-Server is aimed at companies with dedicated IT or programming teams.
尽管现在你已经可以使用ML-Server测试一些工具和方案了,并且毫无疑问在未来ML-Server会成为Nuke的一个标准功能,但现在ML-Server依然是为有成熟技术团队的公司准备的,所以你好歹也得有个专业IT和专业的开发团队吧。
However, visual effects and animation software is traditionally not web or cloud based. Current software development approaches and release cycles compound the problem. They require vendors to be the gate-keepers of what technology makes it into the next version, with long delays between idea and release.
另外,视效、动画软件自诞生以来就不是基于云的。传统的软件开发方式还有发布周期都使得问题复杂化。从想法到开发再到发布的漫长的周期中,会出现很多问题,要搞定机器学习就需要软件商真正地去保驾护航,
ML-Server system follows a client/server model. The client plug-in inside NUKE communicates with a server that can run and return the results of an ML inference. This approach solves a number of practical considerations, most notably connecting the heterogeneous computing environments between host software and ML frameworks. For example, only the server is required to have the high-end hardware or specific OS required by the ML framework. And as it is a server, it can be a shared resource among artists or ML practitioners.
ML-Server系统沿用了C/S架构模型。客户端就是Nuke中的插件,服务端运行并返回机器学习计算的结果,客户端与服务端之间以这种方式保持通信。这种方法解决了一系列的实际问题,尤其是在主机软件和机器学习框架之间建立异构计算环境。举个例子,只有安装服务端的主机需要顶级硬件或者特定的操作系统来运行机器学习框架,服务端一般也会与多个客户端保持连接。
Nuke中的尺度循环网络去模糊(SRN DeBlur)
Some of the initial ML applications the Foundry have tested involving using these openly published ML Libraries. For example, SRN Blur was published as a ML approach to removing motion blur. This was first published as Scale-recurrent Network for Deep Image Deblurring. As with so many ML solutions this is able to be easily incorporated into ML-Server, since the work is open source, works with code libraries and is not shielded away behind patents or unworkable SDKs.
一些The Foundry测试过的初始应用包含了这些公开发布的机器学习库。比如,尺度循环网络去模糊(SRN DeBlur)就是一种消除运动模糊的机器学习方法。它是首次应用于对深度图像去模糊。之所以ML-Server能集成如此多的机器学习解决方案,是因为这项工作本身就是开源的,它可以与代码库一起运行,也不会被各种专利、各种license所阻隔。


The Foundry has taken SRN Debur and incorporated it in ML-Server. While below are just stills, this tool is remarkable. Fxguide visited the Foundry in the UK and the actual results are incredible.
The Foundry已经采用了尺度循环网络去模糊并把它添加到了机器学习服务端中。虽然下面这些图片都是静态的,但依然使人印象深刻。Fxguide访问了The Foundry在英国的工作室,真实的成果令人震惊。
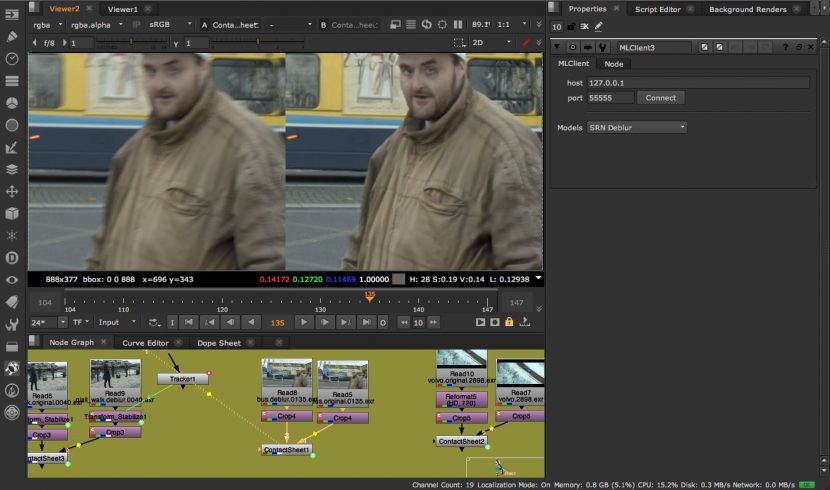
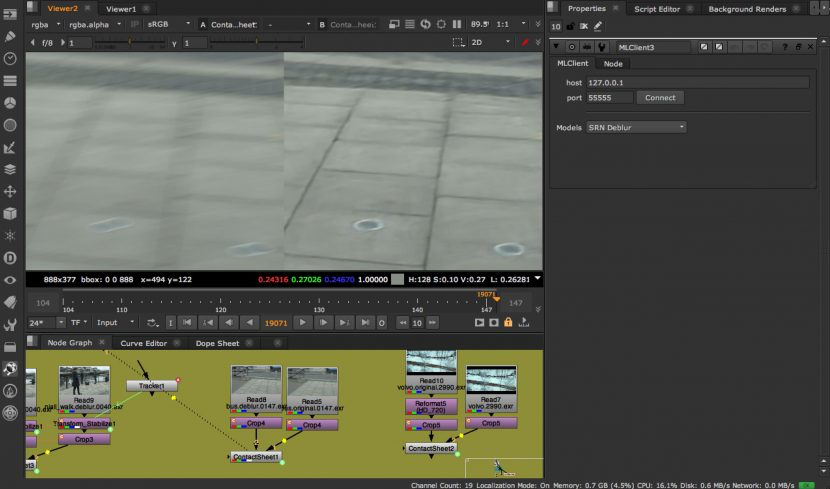
PWC_MotionVectors
optical flow estimation is a core computer vision problem and has many applications, e.g., action recognition, retiming, and video editing. PWC_MotionVectors is a motion vector ML solution that produces very clean and useable motion vectors. It was made with a compact but effective CNN model for optical flow, called PWC-Net. PWC-Net has been designed according to simple and well-established principles and is an example of a ML solution that might be core to some larger Nuke solution.
光流的计算是计算机视觉的核心问题,它在生产制作中有许多应用,比如动作识别,变速,视频编辑等。(光流是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。)PWC_MotionVectors是一个采用机器学习的运动矢量解决方案,它能生成干净可用的运动矢量信息。它由一个被称为PWC-Net的紧凑高效的卷积神经网络构成。PWC-Net根据简单、且成熟的原则设计而成,同时也是机器学习领域中一个不错的例子,它很有可能成为更为复杂的Nuke工具的核心。
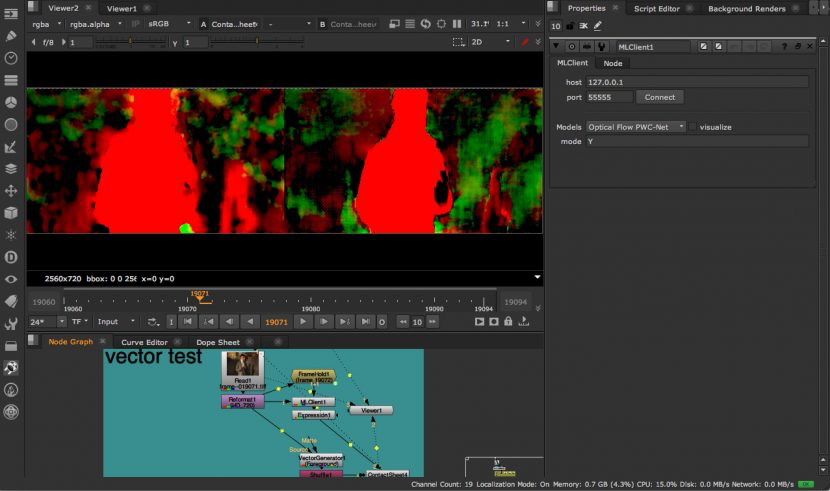
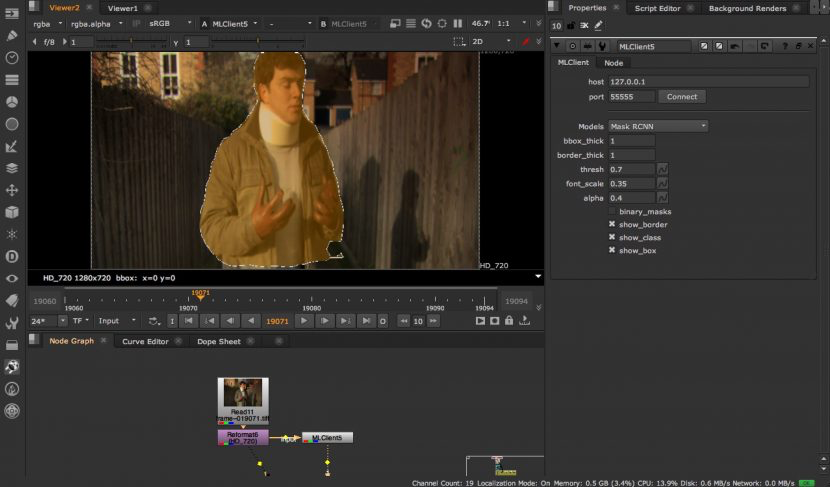
Nuke中的遮罩-区域卷积神经网络(Mask RCNN)
Mask RCNN is a conceptually simple, flexible, and general framework for object instance segmentation. Their published approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method is shown below in Nuke.
遮罩-区域卷积神经网络(Mask RCNN)是一个概念简单、灵活通用的图像实体分割框架。它们发布的方法有效的检测图像中的问题,同时为了每个图像实体生成高质量的遮罩。这个方法在下图中可以得到很直观的展示。
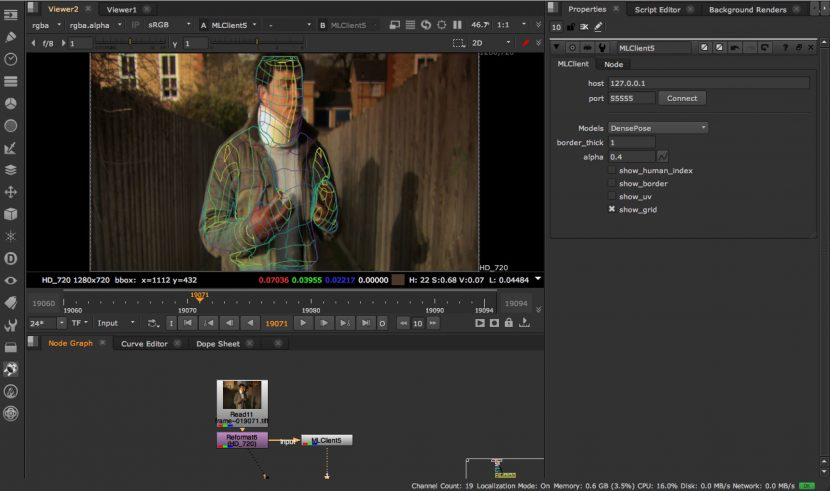
Nuke中的人体姿态估计(DensePose)
Given the work inObject segmentation, it is a natural step to consider roto. This is the killer app that alone would make the world of difference to visual effects and stereo pipelines. DensePose is a specialist pose estimation tool that is trained on humans and thus is very specific. Dense human pose estimation aims at mapping all human pixels of an RGB image to the 3D surface of the human body.
当我们做物体分割的时候,我们很自然的会想到roto。DensePose是一个杀手锏级别的应用,它可以使视效和立体流程的工作的变得大不一样。DensePose是一个专业的针对人体姿态的计算工具,它能做密集的人体姿态计算,并把图像中人物的所有像素都映射到一个三维人类角色上。
A possible ML tool is general purpose, artist lead, roto tool. Roto replies on image segmentation and object classification. But the ML-server approach that the Foundry has been experimenting with allows for artist input. As discussed below, this is critical.
大家最希望的机器学习工具通常是一个通用的,艺术家导向的roto工具。Roto结果会依照图像分割和物体识别由机器学习工具计算出来。但是The Foundry的ML-Server一直都在做机器学习工具与用户交互的实验。如下文所述,这是至关重要的。
艺术家的参与 (Artist Involvement)
The Foundry is quick to not promote ML as an artist replacement, as they point out that post-production is not an automated turn-key process. It often requires hundreds, sometimes thousands, of skilled artists and users to complete a show. In contrast, Machine Learning often aims to solve an entire problem in one go, removing artists from the creative or technical process. For many artists this is a cardinal sin. ML based tools will be widely adopted only if they offer artists the same level of control they are accustomed to. Removing artists from the process also fails to leverage one of the most important things that ML can offer: the ability for an algorithm to learn from its mistakes and correct future errors.
The Foundry很快就停止了试图推动机器学习替代艺术家的尝试,他们认为,后期制作并不是一个自动化的钥匙交接过程。它通常需要成百上千的熟练的艺术家和用户来完成一个项目。另一方面,机器学习通常用于一次性解决问题,把艺术家排除在创意或技术性工作之外。对于很多艺术家来讲这是不道德的。基于机器学习的工具只有符合艺术家使用习惯的时候才会被广为接受。把艺术家从制作中移除掉,也无法利用艺术家的工作成果来帮助算法查漏补缺。(The Foundry的求生欲好强)
The Foundry’s team of Dan Ring, Johanna Barbier, Guillaume Gales and Ben Kent have approached the problem in two ways. Firstly, they have designed tools that can include sensible user interaction, and secondly they have provided a mechanism for an algorithm to update itself using the knowledge of its talented users.
The Foundry的的团队(包括Dan Ring,Johanna Barbier,Guillaume Gales和Ben Kent)用两种策略来解决了这个道德和算法纠偏的问题。首先,他们确保设计的工具包含了合理的用户交互方式,其次,他们提供了一种机制,算法可以使用技能精湛的艺术家的数据来实现自我更新。
The team stress that the ML-Server is not a polished nor commercial product, but it is a vehicle for exploration. It is an enabling technology that the Foundry wants to give out to their customers immediately. The great thing is that once ML-Server is set up, a team can create their own model, and within five minutes, see it in Nuke.
该团队强调ML-Server既不用于打磨产品,也不是商业产品,它是一种探索工具。它是Foundry想立刻提供给客户的一项技术。最令人兴奋的是,一旦ML-Server建立起来,团队就可以创建自己的模型,并在五分钟内打开Nuke看到它。

