
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》并提问,完成词频统计程序,撰写博客 |
| 其他参考文献 | ... |
作业基本信息...
part1:阅读《构建之法》并提问
一、基本要求
-
1:11.5.5 小强地狱部分,提到“阈值不宜频繁调整,最好事先宣布阈值”,这要怎么尽量一次性做到?
此处阈值指的是bug数量的界限,如果开发人员“入狱”的比例过高,说明了阈值设置或者bug计算不合理,需要调整。我的想法是,假设在bug计算合理的条件下,阈值设置直接按照书上所说的5%-30%设置,还会不会出现不合理的情况,仍需要调整?如果仍然需要调整,那么多次调整会不会带来开发效率下降等不利影响?(可能多次调整才会趋近于合理) -
2:14.1.3 CMMI是如何运行到实际的软件质量保障方面的?
书上提到软件工程的质量是可以利用CMMI衡量的,可以提高企业的管理水平,降低企业成本。我查了资料,发现关于CMMI的说法也大多和课本差不多,比较详细而已(都是提到五个等级、连续⑩阶段式实施方法)。但由于没有项目经验,还是不懂CMMI是如何应用才能保障软件的质量的。 -
3:16.1.1 “灵光一闪现,伟大的创新就紧随其后”部分,如何在拥有基础的前提下,把握好”灵光一闪“的机会?
“不要一开始就想着找到并拼对所有的拼图块,以为能够打造一个巨大的创新”,这句话照应上文“没有前人的积累和自身扎实的功力,就没有‘最后一块’等着大家去拼”。我的理解是,既然IT行业需要站在前人的肩膀上才会创新,那么就算“站在前人的肩膀上”,要怎样才能像牛顿、阿基米德等人把握好“灵光一闪”的机会?这个问题不是很明白。 -
4:16.1.3 “好的想法会赢”部分中,提到了两种电脑键盘布局,两种键盘就其效率而言,更高效的那种反而不是我们日常使用的键盘样式。好的想法不一定赢,但是好的想法和成功的关系是完全意义上的必要不充分条件吗?
查阅了相关资料,发现清一色的都是“有想法就去做,去尝试,想赢但也不怕输”的类似观点。也可以说,好的想法出现是想赢,但不一定会赢。那么虽然还提到了“提出一个创新的想法时需要考虑的问题”,对照一下本案例,仅仅是与大众习惯不符,为什么就输了呢?我认为这些问题仍然不是很理解。还有,如果是必要不充分条件,那为什么还要鼓励大家有更多的想法,而某些人有好多好的想法却没有赢,阻碍其他更多想法出现,自相矛盾? -
5:16.3.2 动量和加速度部分,遗留下来的问题不太明白:如何平衡大量收入但在减少的软件产品和没赚钱但用户量上升很快的软件产品之间的投入。
书上、网络上均没提到对这个问题的合适的解答,我的思考是,如果软件在未来很有前景,就尽量以“加速度”为主,“动量”为辅;如果这个软件现在已经成熟,用户数量已经较多的情况下,尽量以“动量”为主,“加速度”为辅。
二、附加题:大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?
故事标题:永远不要自称为程序员
很多公司的经理不懂计算机,在他们心目中,程序员就是一群高成本的劳动力,只会在一台复杂的机器上干一些难懂的事情。如果你自称为"程序员",当公司需要压缩成本的时候,某些经理首先就会想到解雇你,因为你的工资高。有一家公司叫Salesforce,口号是"没有软件",意思就是如果经理们购买了他们的服务,就不再需要别的软件管理销售业务了,也就是说,不再需要自己雇佣程序员了。正确的做法是,你应该把自己描述成与增加收入、降低成本有关系的人,比如"xx产品的开发者"或"改进者"。有一个 Google Adsense程序员的自我介绍,是这样写的:“Google公司97%的收入,与我的代码有关。”
(摘自:https://blog.csdn.net/yiliang121816976/article/details/45289841)
个人见解:
- 在企业里面不会自称程序员,但是在外人眼里还是程序员。
part2:WordCount编程
1、Github项目地址
Github项目
网址:https://github.com/sanluo-huiyi/PersonalProject-Java/
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 300 |
| • Design Spec | • 生成设计文档 | 90 | 60 |
| • Design Review | • 设计复审 | 50 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| • Design | • 具体设计 | 60 | 50 |
| • Coding | • 具体编码 | 300 | 900 |
| • Code Review | • 代码复审 | 60 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 150 | 240 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 90 | 80 |
| • Size Measurement | • 计算工作量 | 15 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 15 |
| 合计 | 950 | 1795 |
3、解题思路描述
(1) 统计文件的字符数(对应输出第一行):只需要统计Ascii码,汉字不需考虑;空格,水平制表符,换行符,均算字符。
- 考虑用utf-8格式读入文件数据。
- 直接统计数量:遍历文件,直到文件结束。
(2) 统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。分割符:空格,非字母数字符号。
- 遇到数字则判断是在第几个位置,如果是前四个则跳过,直到遇到下一个分隔符。
- 用一个布尔变量来标记该字母是否需要跳过。
(3) 统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
- 先统计文件总行数,再统计文件空行数,有效行数=总行数-空行数。
- 判断空行:去除回车、换行符、空格等字符,判断该行是否为空。
(4) 统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
- 面对问题的复杂,没有思路,只好借助网络找资料和代码参考。
- 查阅资料,初步考虑用正则表达式切割字符串,用map存储频次。
- 关于排序,初步考虑利用冒泡排序算法,降序排序。
- 不到10个不重复单词的情况下,降序输出所有单词及其出现次数。
(5) I/O部分
- 考虑用InputStreamReader读入单字符,用BufferedReader读入整行字符。
- 利用FileWriter写入文件。
4、代码规范制定链接5
代码规范
网址:https://github.com/sanluo-huiyi/PersonalProject-Java/blob/main/221801110/codestyle.md
5、设计与实现过程
整个程序除了WordCount类,有两个类,类名分别为Lib和Frequency。将除了统计词频的所有功能写入Lib.java文件,统计词频功能写入Frequency.java文件,WordCount类只要写一个主函数调用即可。
Lib类有三个函数,分别统计字符数量、单词数量、有效行数:
public class Lib {
//统计字符数量
//传入参数:文件名
//返回值:字符数量
public static int numOfChar(String filename);
//统计单词数量
//传入参数:文件名
//返回值:单词数量
public static int numOfWord(String filename) ;
//统计有效行数
//传入参数:文件名
//返回值:有效行数
public static int numOfLine(String filename);
}
Frequency类主要是统计词频功能,包含两个函数。一个是构造函数,用于将读入的数据分成一个一个单词,然后压入map集合;另一个为结果函数,主要用来排序并保存。还有几个函数要用到的类变量:
public class Frequency {
//指定文件路径和文件名
private static String path;
//定义一个结果集字符串
public static String result = "";
//定义一个map集合保存单词和单词出现的个数
private TreeMap<String,Integer> tm;
public Frequency(String path);
public static String saveResult(Map<String,Integer> map);
}
5.1 统计文件的字符数
读入文件之后,逐个字符扫描,直到文件结束为止,即可:
readFile = new InputStreamReader(new FileInputStream(file),"UTF-8");
int tempChar;
while ((tempChar=readFile.read()) != -1) {
count++;
}
readFile.close();
5.2 统计文件的单词总数
一开始的想法是硬编码,引入一个标志位(初始值为false),表示当前是不是一个单词。
读入第一个字符,判断是不是字母,如果是,标志位置为true;之后如果遇到数字,判断是不是在前四个,如果是,标志位置为false。直到遇到下一个分隔符才统计单词数量。
for (int i = 0; (tempchar=readFile.read()) != -1; ) {
char ch = (char)tempchar;
//是字母
if (ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <='z'){
i++;
flag = true;
}
//是数字,判断是不是在第五个及之后出现
else if (ch >= '0' && ch <= '9'){
i++;
if (i < 5) {
i = 0;
flag = false;
}
}
//分割符情况
else {
if (i >= 4 && flag == true) countWord++;
flag = false;
i = 0;
}
}
后面发现似乎可以和后面的“统计文件中各单词的出现次数”用同样思路(利用正则表达式判断),并且上面的程序段有bug,因为最后一行末尾可能没有分隔符,故修改:
//读入文件、变量声明省略
bufferedReadFile = new BufferedReader(new FileReader(file));
while ((tempString = bufferedReadFile.readLine()) != null){
tempString = tempString.toLowerCase();
String reg1 = "[^a-zA-Z0-9]+";
String reg2 ="[a-z]{4}[a-z0-9]*";
//将读取的文本进行分割
String[] str = tempString.split(reg1);
for (String s: str){
if (s.matches(reg2)){
countWord++;
}
}
}
5.3 统计文件的有效行数
读入文件之后,逐行扫描,去除空白字符,若该行一个字符都没有,则代表一行空白(也即是无效行):
bufferedReadFile = new BufferedReader(new FileReader(file));
String tempString;
while ((tempString = bufferedReadFile.readLine()) != null){
countSum++;
//去掉空白字符
tempString=tempString.replace("\f","");
tempString=tempString.replace("\b","");
tempString=tempString.replace("\r","");
tempString=tempString.replace("\t","");
tempString=tempString.replace("\n","");
tempString=tempString.replace(" ","");
if (tempString.equals("")) {
countNull++;
}
}
二者相减即是文件的有效行数。
5.4 统计文件中各单词的出现次数
此功能比较复杂,函数体也比较大,和前三个功能混子一起似乎不是很合适。考虑用一个类进行封装,类名为Frequency。
过程大致是:获取文件;利用正则表达式分割文本;先判断集合中是否已经存在该单词再压入集合;最后进行排序。
除了最后的排序,剩下的功能全部写入同一函数,部分代码如下:
while ((tempString=bufferedReadFile.readLine())!=null){
tempString = tempString.toLowerCase();
String reg1 = "[^a-zA-Z0-9]";
String reg2 ="[a-z]{4}[a-z0-9]*";
//将读取的文本进行分割
String[] str = tempString.split(reg1);
for (String s: str){
if (s.matches(reg2)){
//判断集合中是否已经存在该单词,如果存在则个数加1,否则将单词添加到集合中,且个数置为1
if (!tm.containsKey(s)){
tm.put(s,1);
}
else {
tm.put(s,tm.get(s)+1);
}
}
}
}
//...
排序过程:将Map类型转换成的List,利用Map.Entry输出map键值对,并且获取list列表中存放的数据。还需要自定义比较器实现降序排序:
public static void printResult(Map<String,Integer> map) {
List<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return (o2.getValue().compareTo(o1.getValue()) ); //降序排序,当o2小于、等于、大于o1时,返回-1,0,1
}
});
int num = list.size();
//System.out.println(num);
for (int i = 0; i < num && i < 10; i++) {
Map.Entry<String,Integer> entry = list.get(i);
//输出...
}
}
6、性能改进
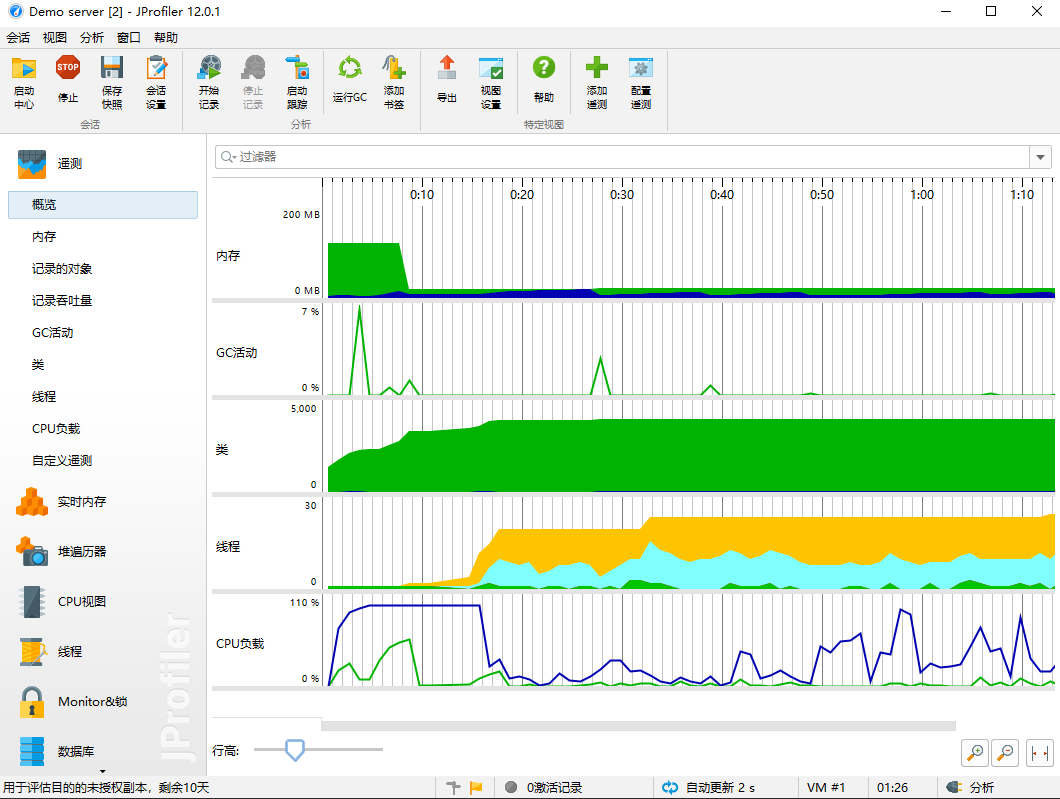
改进思路:
- 提高I/O速度,使用BufferedReader类代替。但是没有全部使用,只在按行读入文件时使用。
- 更多的考虑正确性,性能改进部分没有考虑多少。
7、单元测试
以下三个函数分别测试字符、单词、行数功能:
@Test
public void numOfChar() {
int a = Lib.numOfChar("d:\\1.txt");
System.out.println("characters: " + a);
}
@Test
public void numOfWord() {
int b = Lib.numOfWord("d:\\1.txt");
System.out.println("words: " + b);
}
@Test
public void numOfLine() {
int c = Lib.numOfLine("d:\\1.txt");
System.out.println("lines: " + c);
}
以下函数用于测试词频功能:
@Test
public void saveResult() {
Frequency d = new Frequency("d:\\1.txt");
}
测试结果如下:

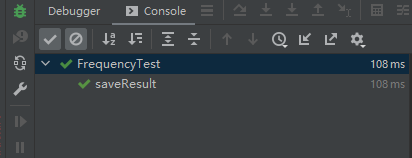
说明没有问题。
关于构造测试数据,我主要考虑了几个点:
- 同一单词,大小写同时出现的文本,如文本中含有"aaaaa"、"AAaaa"、"AAAAA"、"AaAaA"等。
- 使用不同分割符表示的文本。
- 文章最后一行有没有换行符的不同文本。
- 只含空白符的文本。
- 不同单词数小于十个的文本。
- 含有空白行的非空文本。
- 百万字符的超长文本。
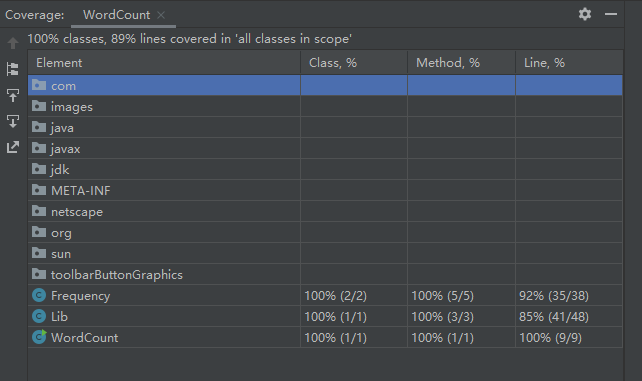
代码测试覆盖率:
8、异常处理说明
当且仅当文件不存在时会抛出异常。
try {
//读文件
//处理文件
}
catch (Exception e){
System.err.println("文件不存在");
}
利用不存在的文件名进行测试。
9、心路历程与收获
-
完成本次作业困难重重。
-
装IDEA的时候倒算是顺利,一下就装上。
-
但是,首先是GitHub,弄了半天不知道怎么fork,怎么上传代码,导致这一过程反复很多次,同时询问了一位同学,才明白的。
-
最主要的是,刚看到题目时认为很简单,只需要实现四个功能即可,感觉像是一道中等难度的算法与数据结构编程题。实际上细节的东西非常多(比如分隔符的种类不仅仅是空格,统计词频后还要进行排序等等),也正因此实际耗费时间比计划多得多。计划不准确。
-
有些作业要求没看清楚就开始写,导致经常性修改,比如代码规范制定,写代码的时候意外发现不合要求,只能花更多时间修改。
-
本次作业最大的收获是,学会了使用GitHub的上传代码功能,还有用了Java编程语言的TreeMap、正则表达式等之前没用到过的,当作多学了一些知识。
-
不足之处在于,由于能力限制,关于本作业,没有比较好的封装和单元测试,写出来的函数比较低级,与别人的差距明显的体现出来。还有,整体设计不是很恰当,总是拘泥于一个个功能的实现,没有考虑到功能之间的相关性,如统计单词总数和统计词频里面有些功能是相似的,可以共用模块,没有做到,代码有一定的冗余。
-
整体不是很满意,任务一花太多时间去做(差不多一周),导致任务二时间趋紧,但是尽量去完成就行。还有很多知识要学,后面的作业须努力。

