

正则表达式——元字符
‘’正则表达式:
对文本字符串按照某种规则进行检索、替换
分类:
BRE(基本正则表达式) ---> ERE(扩展正则表达式) --->PCRE(高级语言使用的正则表达式)
基本语法:
元字符metacharacter:
| . | 匹配除换行符外任意一个字符 |
| [abc] | 字符集合,只能表示一个字符位置。匹配所包含的任意一个字符 |
| [^abc] | 字符范围,只能表示一个字符位置,匹配除去所包含的任意一个字符 |
| [a-z] |
字符范围,也是个集合,表示一个字符位置
匹配所包含的任意一个字符
|
| [^a-z] |
字符范围,也是个集合,表示一个字符位置
匹配除去集合内字符的任意一个字符
|
| \b | 匹配单词的边界 |
| \B | 不匹配单词的边界 |
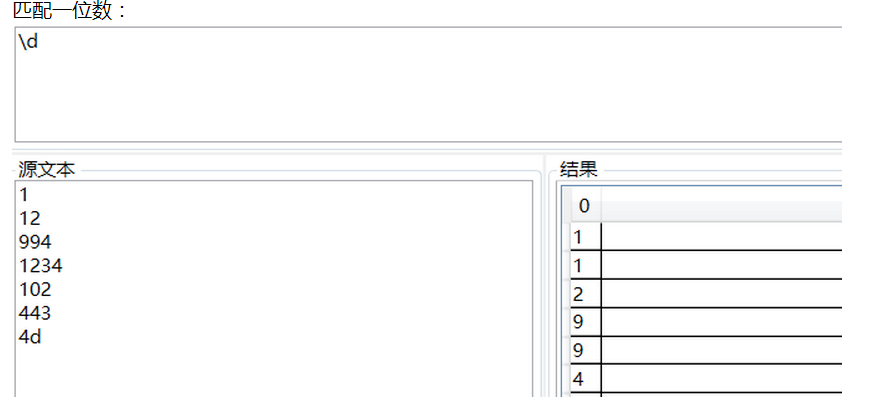
| \d | [0-9]匹配1位数字 |
| \D | [^0-9]匹配1位非数字 |
| \s | 匹配1位空白字符,包括换行符、制表符、空格[\f \r \n \t \v] |
| \S | 匹配1位非空白字符 |
| \w | 匹配[a-zA-Z0-9_],包括中文 |
| \W | 匹配\w之外的字符 |
单行模式:
' . ' 可以匹配所有字符,包括换行('\n')
^ 表示整个字符串的首位, $行尾
多行模式:
' . ' 可以匹配除了换行符之外的字符
^ 表示每行的行首, $行尾
开始指的是\n后紧接着下一个字符,结束指的是\n前的字符
*表示前面的正则表达式会重复0次或多次
+重复至少1次
?重复0次或1次
{n}重复固定n次
{n,}重复至少n次
{n,m}重复n-m次
1、匹配手机号
133xxxxxxxx
\d{11}
2、匹配座机:
025-12345678
0100-1234567
\d{3,4}-\d{7,8}
x|y: 匹配x或y
wood took foot food
w|food 或者 (w|f)ood
\数字 匹配对应的分组
(very)\1 匹配到的是 very very 匹配的组是(very)
(?:pattern)括号为了改变优先级 不需要分组就可以使用?:
(?
<name>exp)
(?'name'exp)
分组捕获,可以通过name访问分组
python语法 (?P<name>exp)
零宽断言
(?=exp)
断言后面必定跟个exp
f(?=oo) f后面必定有oo出现
(?<=exp)
(?<=f)ood 匹配 ood,前面一定会出现f
断言左边必定有个exp前缀
负向零宽断言
(?!exp) 断言exp一定不会出现在右侧,也就是说断言后面一定不是exp
foo(?!d) foo后面一定不是d
(?<!exp) 断言exp一定不能出现在左侧,也就是说断言前面一定不能是exp
(?<!f)ood ood的左边一定不是f
断言不占分组号
贪婪与非贪婪:
编译器默认是贪婪模式,匹配尽量长的字符串
非贪婪模式,在重复的符号后面+'?',匹配最少的字符串
| 代码 | 说明 |
| *? | 匹配任意次 |
| +? | 匹配至少一次 |
| ?? | 匹配0或1次 |
| {n,}? | 匹配至少n次 |
| {n,m}? | 匹配至少n次,至多m次 |
引擎选项:
| 代码 | 说明 |
| IgnoreCase | 匹配时忽略大小写 |
| Singleline |
单行模式:
可以匹配所有字符
|
| Multiline |
多行模式:
^行首、$行尾
|
| IgnorePatternWhitespace | 忽略表达式中的空白字符,如果要使用空白字符串要是用转义 |
练习:
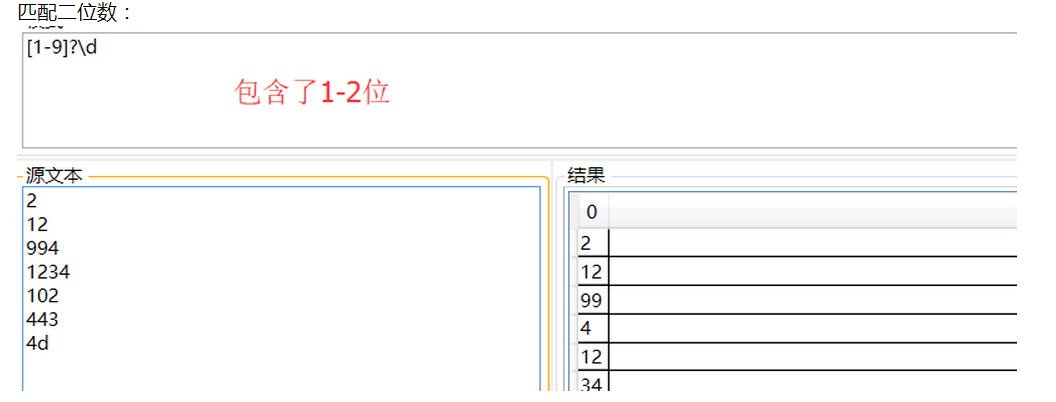
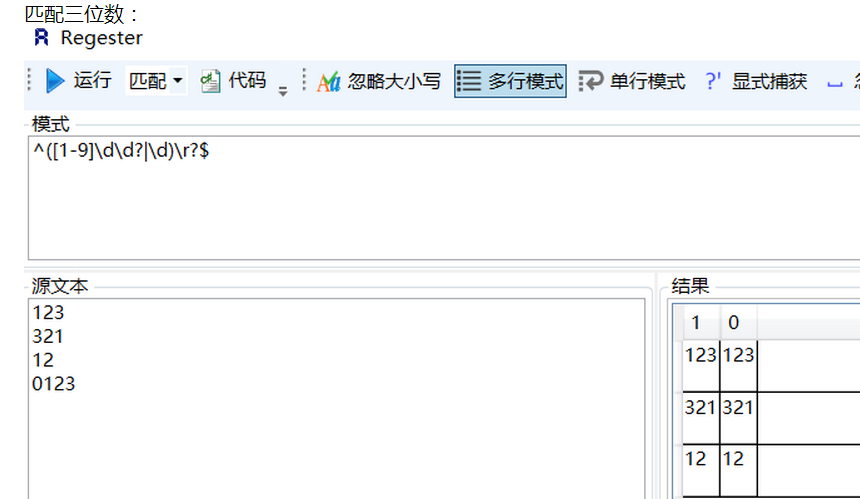
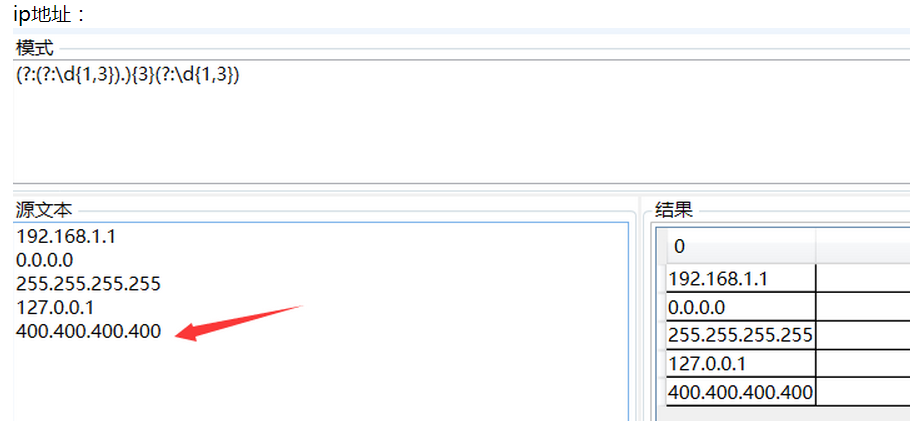
1、匹配0-999任意数字:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号