
分布式并行计算MapReduce
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS,MapReduce功能:
分布式文件系统HDFS主要用于大规模数据的分布式存储,而MapReduce则构建在分布式文件系统上,对于存储在分布式文件系统的数据进行分布式计算。
HDFS的工作原理:
Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS体系结构中有两类节点,一类是NameNode,又叫"元数据节点";另一类是DataNode,又叫"数据节点"。这两类节点分别承担Master和Worker具体任务的执行节点。总的设计思想:分而治之——将大文件、大批量文件,分布式存放在大量独立的服务器上,以便于采取分而治之的方式对海量数据进行运算分析。
MapReduce的工作原理:
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
HDFS的工作过程:
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
MapReduce的工作过程:
执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

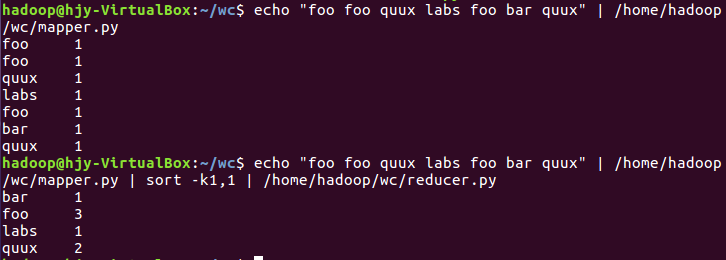
2)编写map函数和reduce函数,在本地运行测试通过
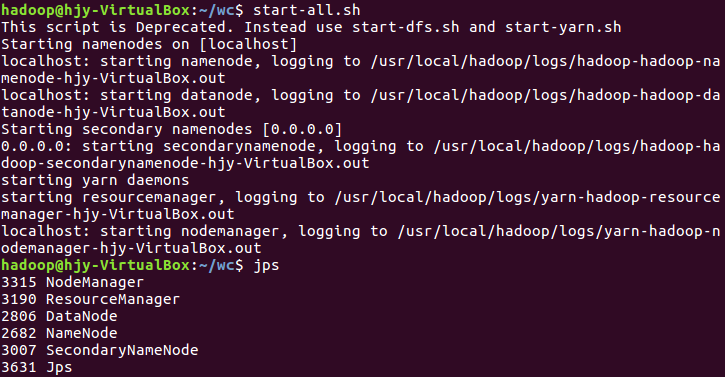
3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

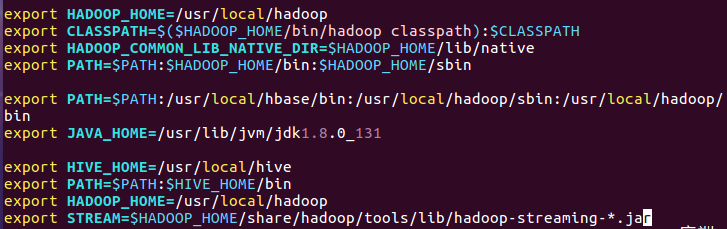
5)streaming的jar文件的路径写入环境变量,让环境变量生效
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
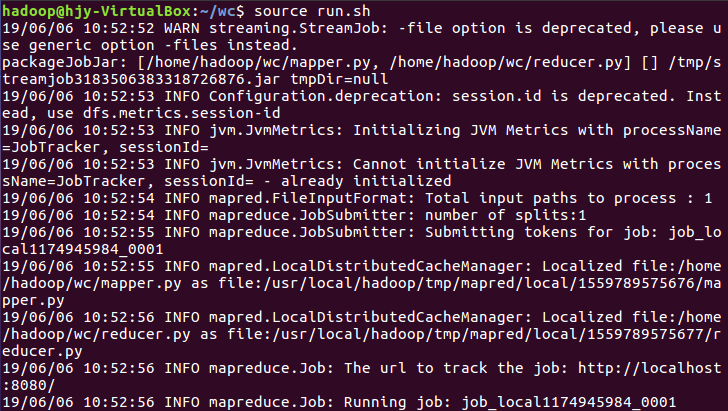
7)source run.sh来执行mapreduce
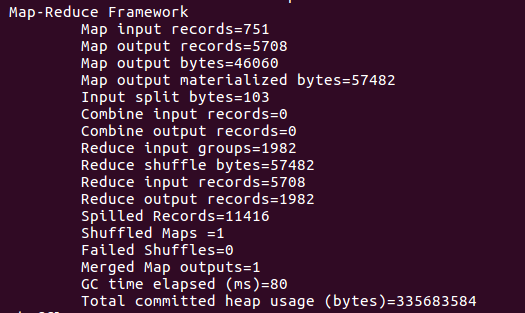
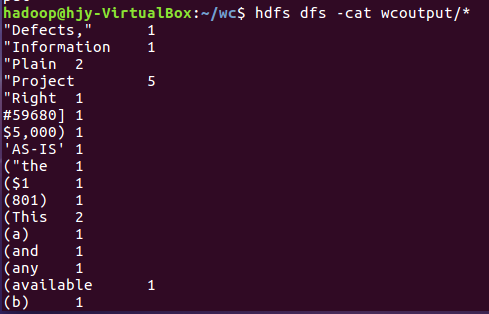
8)查看运行结果
posted on 2019-06-06 10:52 kenda_yellow 阅读(600) 评论(0) 编辑 收藏 举报

