

爬虫综合大作业
一、爬取的对象
豆瓣图书的书籍,总共获取1万8千条数据。
二、保存数据为excel格式。

三、数据分析
1.通过在excel进行数据处理,筛选出20部评分高,评论多的作品,如下图所示。

于是,推荐阅读的书籍为:

闲暇时分,可通过了解作品详情,若感兴趣,可以阅读该作品,省去筛选作品的时间。
2.有部分作者,作品多,而且评分也高,比如:
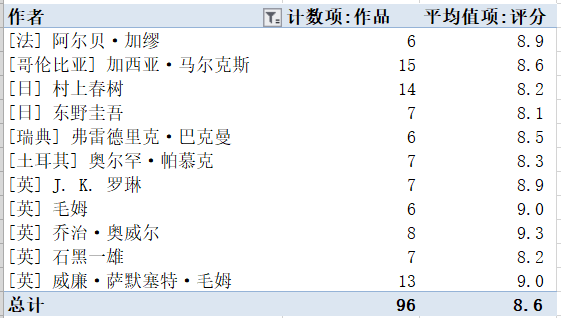
若读者们感兴趣,也可以找这些作者的作品来阅读。
运行代码:
import re import time import pandas as pd import random import requests from bs4 import BeautifulSoup user = ["Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",\ "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",\ "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",\ "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",\ "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",\ "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",\ "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",\ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",\ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20"] def get_user(): use = random.choice(user) return use def get_soup(url): headers = {'user-agent':get_user()} res = requests.get(url,headers=headers) res.encoding = 'utf-8' soup=BeautifulSoup(res.text,"html.parser") time.sleep(random.random()*3) book_list = [] for i in range(0,20): book_dict = {} try: book_dict['作品']= soup.find_all("h2", {"class": ""})[i].find_all('a')[0].text.strip().replace("\n","") book_dict['作者']= soup.select('.pub')[i].text.strip().split('/')[0] book_dict['评分']=soup.findAll("span", {"class": "rating_nums"})[i].text.strip() book_dict['评论次数']=soup.select('.pl')[i].text.strip().lstrip("(").rstrip(")人评价") book_dict['价格']=soup.select('.pub')[i].text.strip().split('/')[-1] book_dict['详情']= soup.find_all("div", {"class": "info"})[i].find_all('p')[0].text.strip().replace("\n","") except Exception as e: book_dict['作品']='' book_dict['作者']='' book_dict['评分']='' book_dict['评论次数']='' book_dict['价格']='' book_dict['详情']='' else: book_list.append(book_dict) return book_list allbook_list =[] for i in range(0,980,20): url='https://book.douban.com/tag/%E6%AD%A6%E4%BE%A0?start={}&type=T'.format(i) allbook_list.extend(get_soup(url)) bookdf= pd.DataFrame(allbook_list) bookdf bookdf.to_csv(r'C:\Users\Administrator\Desktop\book.csv', encoding="utf_8_sig")
posted on 2019-04-28 17:19 kenda_yellow 阅读(373) 评论(0) 编辑 收藏 举报
