

sqlite3
以下是重要的 sqlite3 模块程序,可以满足您在 Python 程序中使用 SQLite 数据库的需求。
| 代码 | 作用 |
| sqlite3.connect(database [,timeout ,other optional arguments]) |
该 API 打开一个到 SQLite 数据库文件 database 的链接。您可以使用 ":memory:" 来在 RAM 中打开一个到 database 的数据库连接,而不是在磁盘上打开。如果数据库成功打开,则返回一个连接对象。当一个数据库被多个连接访问,且其中一个修改了数据库,此时 SQLite 数据库被锁定,直到事务提交。 |
| connection.cursor([cursorClass]) | 该例程创建一个 cursor,将在 Python 数据库编程中用到。该方法接受一个单一的可选的参数 cursorClass。如果提供了该参数,则它必须是一个扩展自 sqlite3.Cursor 的自定义的 cursor 类。 |
| cursor.execute(sql [, optional parameters]) | 该例程执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。 |
| connection.execute(sql [, optional parameters]) | 该例程是上面执行的由光标(cursor)对象提供的方法的快捷方式,它通过调用光标(cursor)方法创建了一个中间的光标对象,然后通过给定的参数调用光标的 execute 方法。 |
| cursor.executemany(sql, seq_of_parameters) | 该例程对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令。 |
| connection.executemany(sql[, parameters]) | 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executemany 方法。 |
| cursor.executescript(sql_script) | 该例程一旦接收到脚本,会执行多个 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句应该用分号(;)分隔。 |
| connection.executescript(sql_script) | 该例程返回自数据库连接打开以来被修改、插入或删除的数据库总行数。 |
| connection.total_changes() | 该例程返回自数据库连接打开以来被修改、插入或删除的数据库总行数。 |
| connection.commit() | 该方法提交当前的事务。如果您未调用该方法,那么自您上一次调用 commit() 以来所做的任何动作对其他数据库连接来说是不可见的。 |
| connection.rollback() | 该方法回滚自上一次调用 commit() 以来对数据库所做的更改。 |
| connection.close() | 该方法关闭数据库连接。请注意,这不会自动调用 commit()。如果您之前未调用 commit() 方法,就直接关闭数据库连接,您所做的所有更改将全部丢失! |
| cursor.fetchone() | 该方法获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
| cursor.fetchmany([size=cursor.arraysize]) | 该方法获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。该方法尝试获取由 size 参数指定的尽可能多的行。 |
| cursor.fetchall() | 该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
爬取数据
爬虫爬取2019年中国大学排名(前500名)各项指标的排名及综合状况,并储存在CSV文件里,输入代码如下:
import requests import pandas as pd import numpy as np from bs4 import BeautifulSoup import sqlite3 allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "error" def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): with open(r'D:\mypython\大学排名30.CSV','w') as f: f.write("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}\n".format((chr(12288)),"排名","学校名称","省市","总分","科研服务")) for i in range(num): u=allUniv[i] f.write("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}\n".format((chr(12288)),i+1,u[1],u[2],eval(u[3]),u[11])) f.close() if 1: print("successful") else: print("fail") def main(num): url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(500)
得到内容(格局有限,只展现一小部分吧)
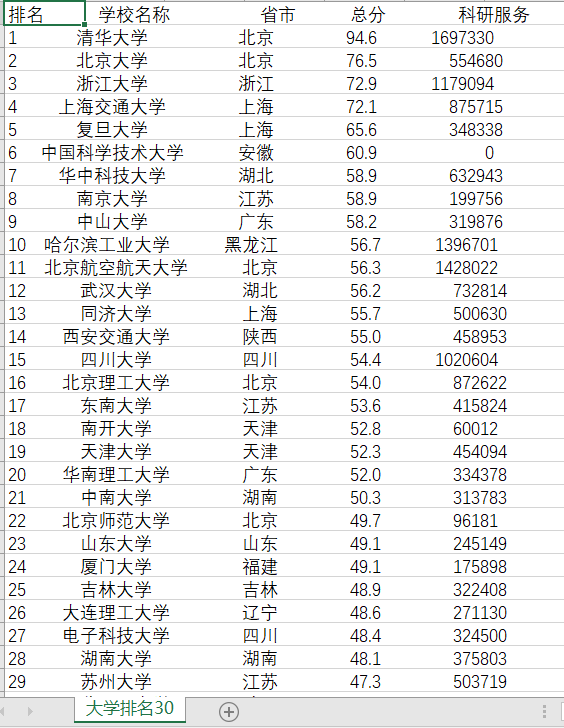
现在我们单独查询“广东技术师范大学”的信息吧,代码如下:
import requests from bs4 import BeautifulSoup allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): a="广东技术师范大学" print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","科研服务")) for i in range(num): u=allUniv[i] if a in u: print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[11])) def main(num): url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(500)
滴,得到信息:

然后只要在这修改成“广东”,就可爬取广东的大学信息
def printUnivList(num): a="广东"#"广东技术师范大学" print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","科研服务")) for i in range(num): u=allUniv[i] if a in u: print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[11]))
滴~
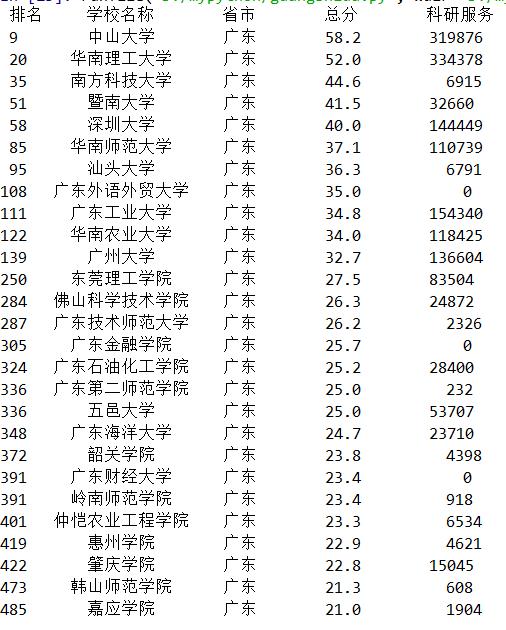
好了,今天就到这了...
| 2 | connection.close() |
