

jieba库,它是Python中一个重要的第三方中文分词函数库。
1.jieba的下载
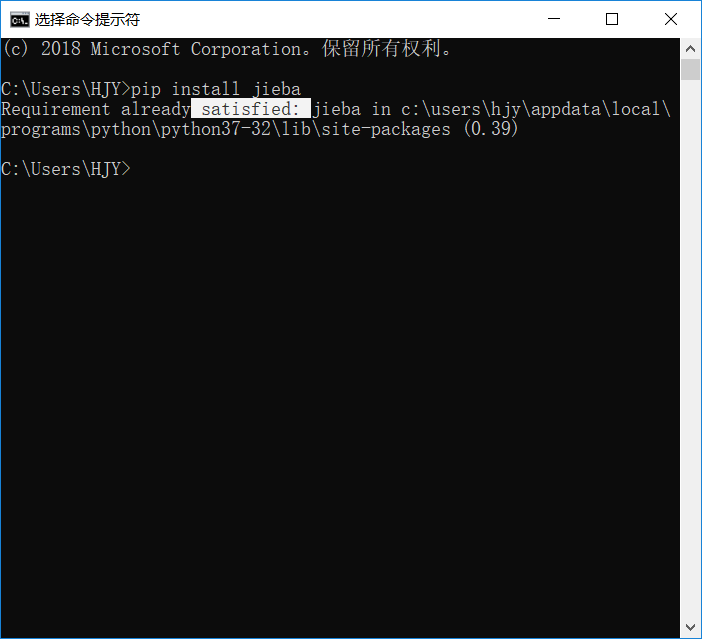
由于jieba是一个第三方函数库,所以需要另外下载。电脑搜索“cmd”打开“命令提示符”,然后输入“pip install jieba”,稍微等等就下载成功。
(注:可能有些pip版本低,不能下载jieba库,需要手动升级pip至19.0.3的版本,在安装jieba库)
当你再次输入“pip install jieba”,显示如图,jieba库就下载成功。
2.jieba库的3种分词模式
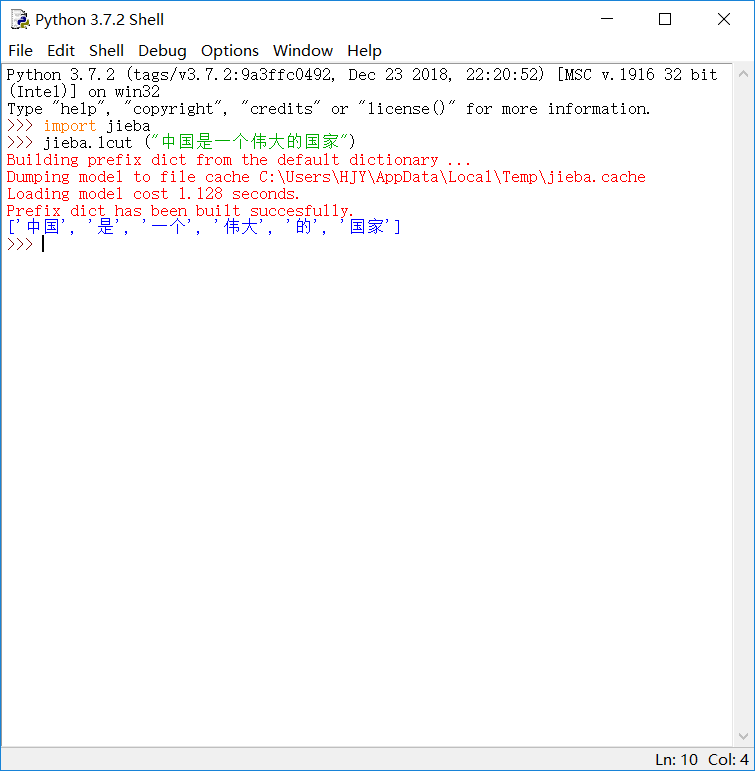
精确模式:将句子最精确地切开,适合文本分析。
例:
全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
例:(“国是”,黑人问号)

搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
例:(没什么不同,可能我还没发现它的用处)

3.jieba应用
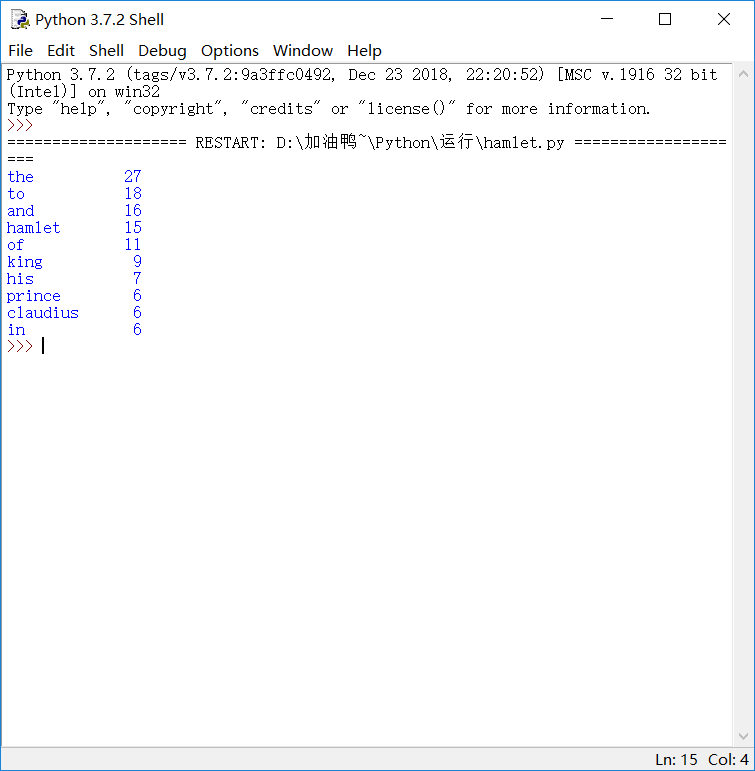
我选取了哈姆雷特(https://en.wikipedia.org/wiki/Hamlet#Act_I)的一小片段,txt形式存放在我的一个文件夹里,对它进行分词,输入代码:
def get_text(): txt = open("D://加油鸭~//hamlet.txt", "r",encoding='UTF-8').read() txt = txt.lower() for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格 return txt hamletTxt = get_text() # 打开并读取文件 words = hamletTxt.split() # 对字符串进行分割,获得单词列表 counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 # 分词计算 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) for i in range(10): word, count = items[i] print("{0:<10}{1:>5}".format(word,count))
得到结果,如图:
最后,我们还可以做词云图,这个呢我下次再给大家分享吧,再见~

