软工实践寒假作业(2/2)
课程实况
| 这个作业属于哪个课程 | 2020春/S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 学习GitHub-学习单元测试和性能分析-PSP表格-写一份可以处理疫情日志的代码 |
| 作业正文 | 我的软工实践寒假作业(2/2) |
| 其他参考文献 | CSDN/知乎/百度 |
Github仓库地址
https://github.com/sjdls/InfectStatistic-main
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 50 |
| Estimate | 估计这个任务需要多少时间 | 40 | 50 |
| Development | 开发 | 720 | 840 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 10 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 450 | 480 |
| Code Review | 代码复审 | 30 | 45 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 120 | 180 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 120 |
| 合计 | 880 | 1070 |
解题思路描述
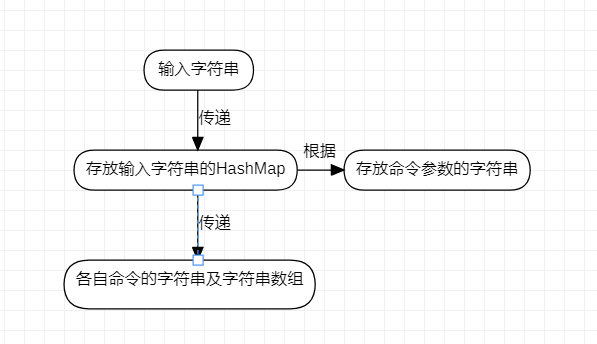
1.处理命令行参数
因为list命令的参数(-log、-out)是已知的,所以我使用一个HashMap存储每个命令对应的输入,再使用具体字符串及字符串数组存放。
2.读取日志名及内容
根据输入后初始化的相关字符串,先读取所有的日志名,根据是否满足小于等于输入的日期决定是否存下来,然后再根据存下的日志名进行内容的读取,每读取一行就处理一行。
3.找到适合处理的数据结构
因为日志的内容,实质上是对各省对应的各种类患者的数据进行修改,所以我使用HashMap存放日志中所提及的各省各种类患者的数据,每提到一个省,就先将其各种类患者数量置为0,再加入HashMap中。然后各种类患者的存储也使用HashMap,这样可以快速的根据输入的患者名称修改对应的数据。

4.对日志内容的处理
把日志内容根据字符串的间隔分为字符串数组,再根据数组的长度分开处理。长度相同的数组的命令其实在实现上是相似的,除了确诊感染的格式不太一致。然后根据要求修改对应省份的对应患者的数据。
5.对省份及种类的输出要求
根据输入后初始化的相关字符串,对种类及省份字符串进行修改,然后再排序省份字符串(全国特殊处理)。
6.输出
根据种类及省份字符串进行输出。
设计实现过程
1.处理命令行参数
使用一个字符串数组存放命令参数commandStrings
再使用一个HashMap进行输入的存储,可以根据commandString快速的对输入进行分类
然后分别将输入给到各自对应的字符串及字符串数组
2.读取日志名及内容
遍历输入的文件夹,根据是否满足小于等于输入的日期决定而是否存下来,然后再根据存下的日志名进行内容的读取,如果不是以“//”打头就提交处理。

3.对日志内容的处理
把日志内容根据字符串的间隔分为字符串数组,再根据数组的长度分开处理。长度相同的数组的命令其实在实现上是相似的,除了确诊感染的格式不太一致。由于不管是那种情况,第一个元素都是省名,先判断存放的HashMap是否有这个省份,没有就put并初始化。接着提交给相关的处理函数。
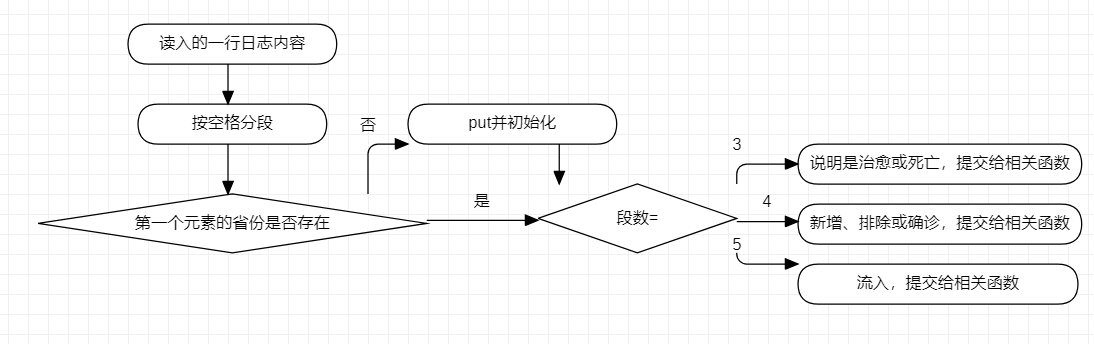
当数组长度为3时,说明为治愈或死亡且修改的患者类型为感染患者,数组的第一个元素为省名,第三个元素为变化的人数。第二个元素确定是治愈或死亡。先将治愈与死亡存放在一个字符串数组cureAndDeadStrings中,这样以后要修改的时候方便。由于使用的省份、患者的存储结构是HashMap,所以可以直接根据输入的字符串直接作为key与修改对应的人数。
当数组长度为4时,说明为新增、排除和确诊感染同理,将这三者存放在字符串数组addAndExcludeAndDiagnosisStrings,然后判断第二个元素是新增还是排除,若都不是,就判断第三个是不是确诊感染,若都不是,提示错误。而数组的第一个元素是省份,第四个为变化人数,接着在根据之前的判断,若为新增,就判断第三个元素的患者类型,直接作为key修改对应人数。若为排除,就修改疑似患者;若为确诊感染,就同时修改感染与疑似患者。
当数组长度为5时,一定是流入。第四个元素为被流入的省份,判断存放的HashMap是否有这个省份,没有就put并初始化。接着直接将第二个参数作为key传给HashMap去修改两个省份的对应患者数量。
4.对省份及种类的输出要求
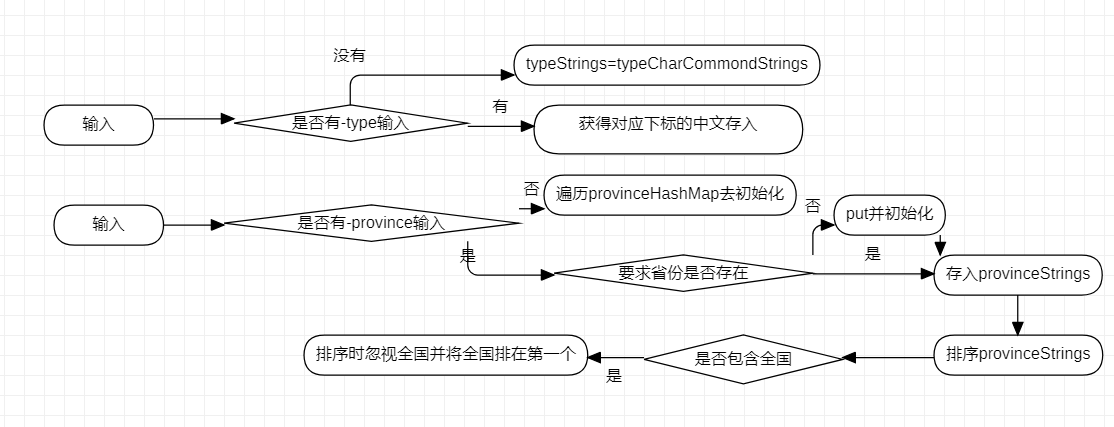
先创建一个字符串数组typeAbbreviationCommandStrings去存储患者类型的缩写,再创建一个字符串数组typeCharCommondStrings存储对应的中文。创建一个HashMap去存储相应的缩写对应的中文的下标。
判断是否有-type的参数输入,若没有,typeStrings=typeCharCommondStrings。若有输入,直接将输入作为HashMap的key去获得对应的下标去取得typeCharCommondStrings的中文。
判断是否有-province的参数输入,若没有,就遍历存储省份的HashMap存入provinceStrings,若有输入,就判断存储省份的HashMap是否有对应的省份,没有就put并初始化。然后对provinceStrings进行排序,且若其中存在“全国”,就将全国提到第一个。
5.输出
判断要求输出的文件是否存在,若不存在先创建。接着把provinceStrings与typeStrings作为key传入给provinceHashMap,取得对应的值,同时输出语句,并在结束后输出"// 该文档并非真实数据,仅供测试使用"。
6.总体流程

代码说明
数据结构
存储结构
总体使用HashMap,这样就可以以string为key进行修改,十分方便
// 存放输入信息
public static HashMap<String, String> inputHashMap = new HashMap<String, String>();
// 存放省份与患者
public static HashMap<String, HashMap<String, Long>> provinceHashMap = new HashMap<String, HashMap<String, Long>>();
//存放具体的对应命令的信息
public static String logNameString = "";
public static String outNameString = "";
public static String dateString = "";
public static String[] typeStrings;
public static String[] provinceStrings;
//存放文件夹下的文件名
public static String[] logNameStrings;
固定的数据
将这些已知的数据存放在数组里,以后要修改就会方便很多
public static String[] commandStrings = { "-log", "-out", "-date", "-type", "-province" };
// 可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择
public static String[] typeAbbreviationCommandStrings = { "ip", "sp", "cure", "dead" };
public static HashMap<String, Integer> typeAbbreviationCommandHashMap = new HashMap<String, Integer>();
// 存放患者的类型
public static String[] typeCharCommondStrings = { "感染患者", "疑似患者", "治愈", "死亡" };
public static String[] cureAndDeadStrings = { "治愈", "死亡" };
public static String[] addAndExcludeAndDiagnosisStrings = { "新增", "排除", "确诊感染" };
public static String inflowString = "流入";
处理日志内容的函数
按日志内容数组的大小进行分类然后去处理
public static void dealLogContent(String lineString) {
String[] inputStrings = lineString.split(" ");
initProvinceHashMap(inputStrings[0]);
if (inputStrings.length == 3) {
if (Arrays.asList(cureAndDeadStrings).contains(inputStrings[1])) {
cureAndDead(inputStrings);
inputStrings[0] = "全国";
cureAndDead(inputStrings);
}
} else if (inputStrings.length == 4) {
int tem = -1;
if (inputStrings[1].equals(addAndExcludeAndDiagnosisStrings[0])) {
tem = 0;
} else if (inputStrings[1].equals(addAndExcludeAndDiagnosisStrings[1])) {
tem = 1;
} else if (inputStrings[2].equals(addAndExcludeAndDiagnosisStrings[2])) {
tem = 2;
}
addAndExcludeAndDiagnosis(inputStrings, tem);
inputStrings[0] = "全国";
addAndExcludeAndDiagnosis(inputStrings, tem);
} else if (inputStrings.length == 5) {
if (inflowString.equals(inputStrings[2])) {
inflow(inputStrings);
}
}
}
下面是一个处理的例子,治愈与死亡的情况
cureAndDead
public static void cureAndDead(String[] inputStrings) {
Long originalLong = new Long(0);
Long changesLong = new Long(0);
originalLong = provinceHashMap.get(inputStrings[0]).get(typeCharCommondStrings[0]);
changesLong = Long.valueOf(inputStrings[2].substring(0, inputStrings[2].length() - 1));
originalLong -= changesLong;
provinceHashMap.get(inputStrings[0]).put(typeCharCommondStrings[0], originalLong);
originalLong = provinceHashMap.get(inputStrings[0]).get(inputStrings[1]);
originalLong += changesLong;
provinceHashMap.get(inputStrings[0]).put(inputStrings[1], originalLong);
}
会发现,当使用HashMap进行存储的时候,修改很方便,直接将输入的要求去增加和修改即可。因为不管是治愈还是死亡,感染人数都是减少。然后再直接将治愈/死亡作为key传入直接增加相应的人数,很方便。
单元测试
testInit

testInitProvinceHashMap
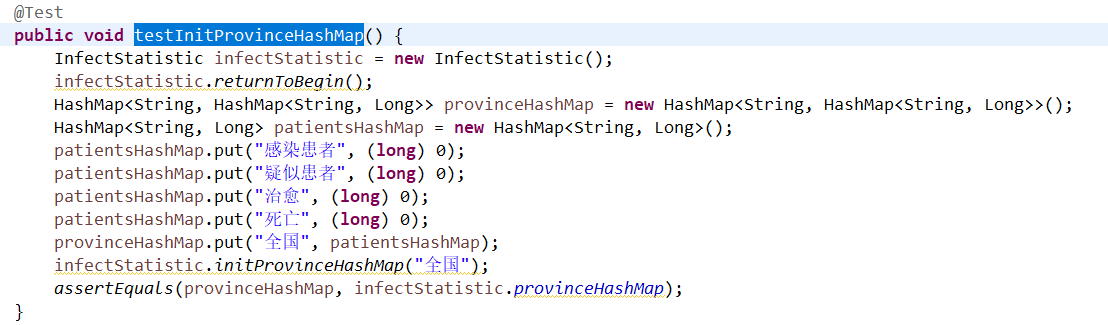
testAddAndExcludeAndDiagnosis
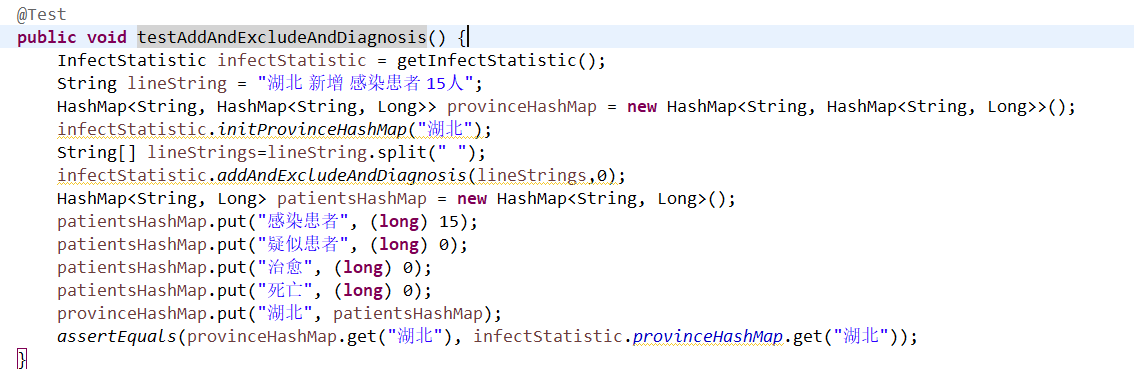
testCureAndDead
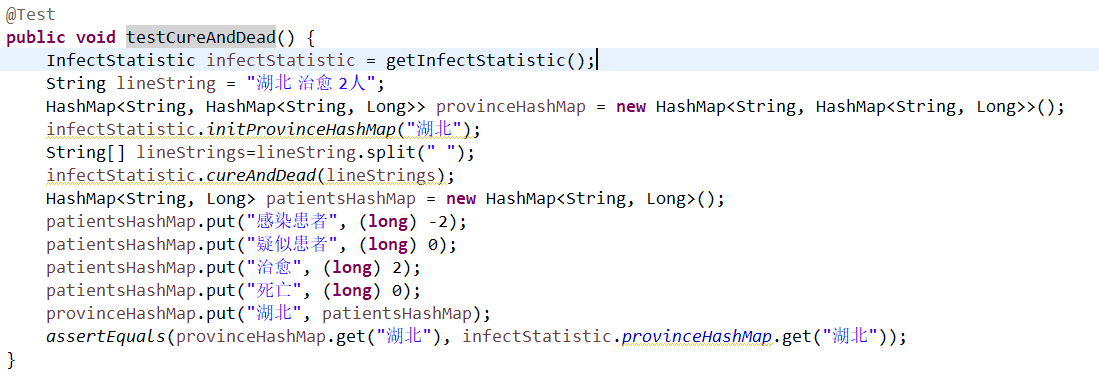
testInflow
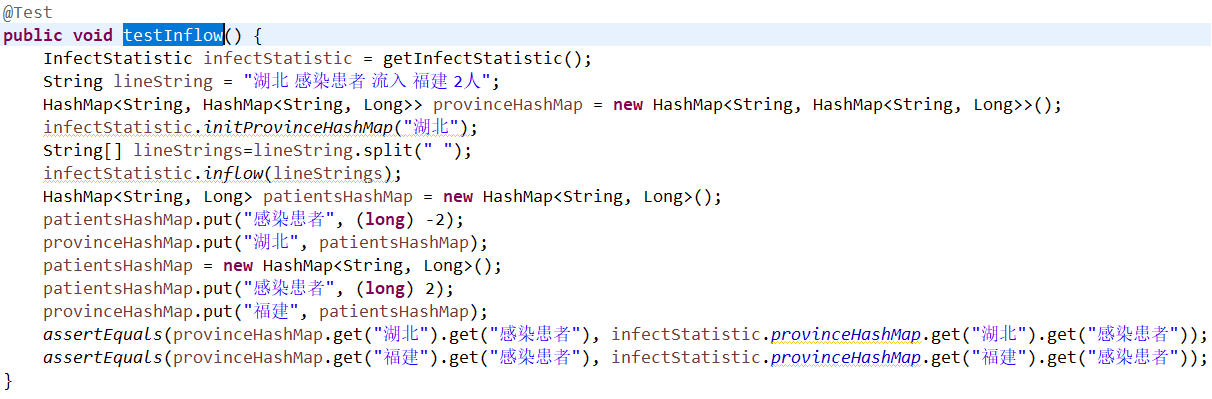
testDealLogContent
testTypeScreen

testProvinceScreen

testSortProvinceStrings

testMain
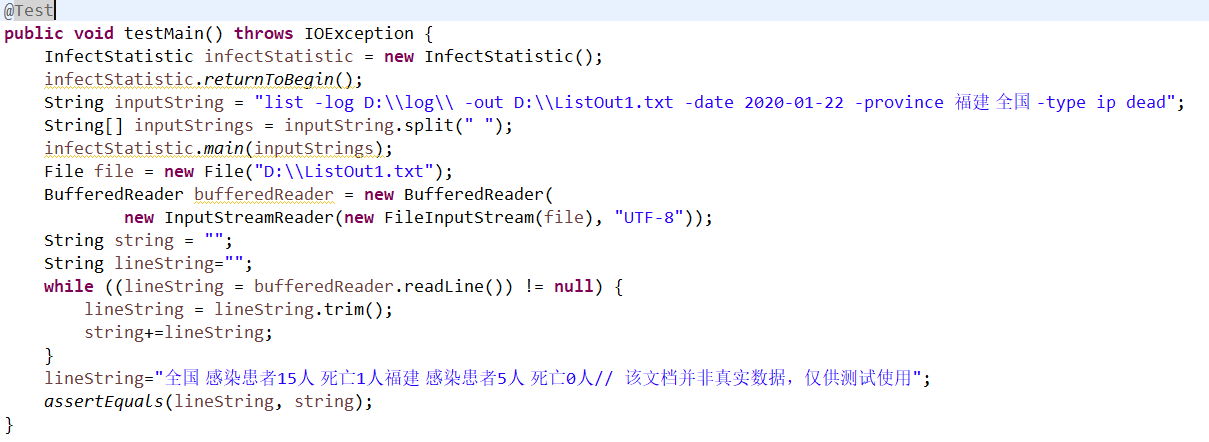
单元测试覆盖率和性能测试
单元测试覆盖率
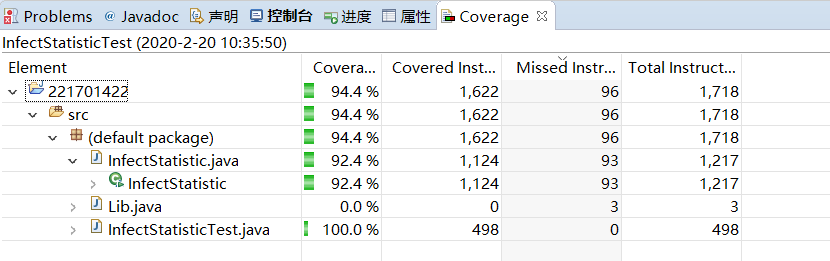
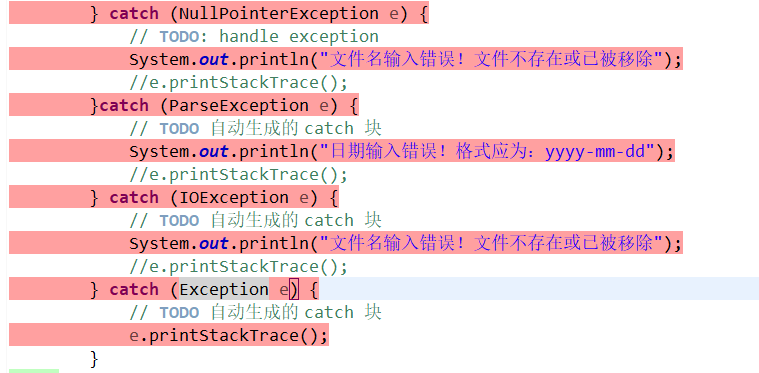
可以看到,没有被覆盖的代码大部分都是异常的处理,以及一些错误的处理。
性能测试
profile快照

Classes
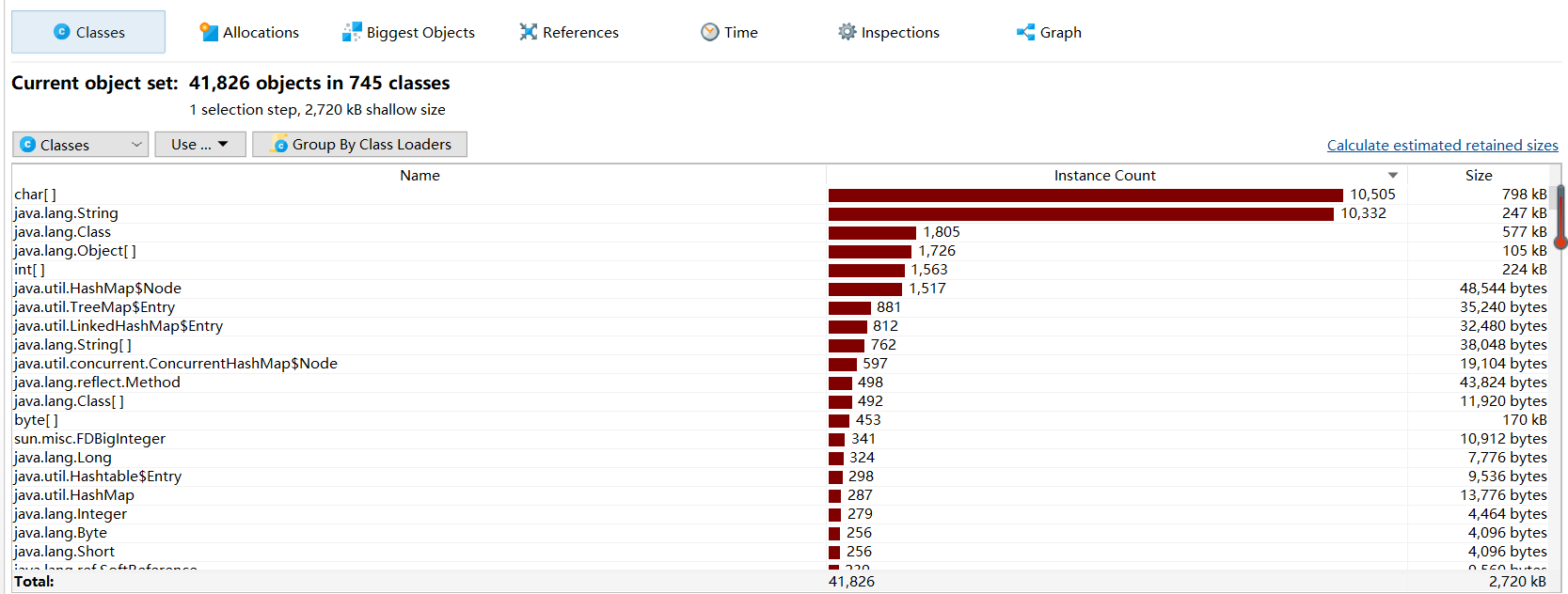
Biggest Objects
代码规范的链接
https://github.com/sjdls/InfectStatistic-main/blob/master/README.md
心路历程与收获
其实编码部分没有我想象的难,在我使用HashMap之后,其实大部分问题都能迎刃而解,说明很多问题只要找到方法,其实都是可以化繁为简的。学习git以及之后单元测试等部分,让我知道了程序员的共工作不仅是要能够写出代码,还要写的规范,还要能够测试优化。在制定了自己的代码规范后,可以提升自已以后编写代码的速率。同时单元测试和性能优化也让我学到了很多,能够更好的优化自己的代码。通过使用git,我可以方便的回档自己的代码。经过几天的代码编写,我发现网络真的是个好东西,不会的其实很多都可以搜索到。但同时也让我发现自己的基础还是很薄弱的,各种函数的作用名称等,我都不太知道,在此次作业之后,我要好好的补习这方面的知识。
技术路线图相关的5个仓库
Unity-MPipeline
https://github.com/sjdls/Unity-MPipeline Unity3D中定制的高质量渲染管道
Unity-MPipeline-Framework
https://github.com/sjdls/Unity-MPipeline-Framework 一种方便的脚本化绘制流水线编程框架
Unity3DTraining
https://github.com/sjdls/Unity3DTraining 太空大战小游戏
https://github.com/sjdls/3DMoonRunner 月光跑酷3D版
https://github.com/sjdls/Unity3DTraining/tree/master/Fruit_Ninja 切水果游戏
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号