
pyspider基础
一、简介
1.1、简介
pyspider 是一个使用python编写,并且拥有强大功能web界面的爬虫框架。
-
强大的web界面可进行脚本编辑,任务监控,项目管理,结果查看等功能。
-
pyspider支持多种数据库进行数据存储。MySQL, MongoDB, Redis, SQLite, Elasticsearch...(保存数据,默认使用sqlit3)
-
并且支持多种消息队列。RabbitMQ, Beanstalk, Redis...(用于调度器进行各个组件的协调工作,数据传递等。)
-
通过装饰器,配置任务优先级,爬虫什么时侯再重新爬取,任务失败再从新自动抓取...
-
可使用phantomjs,只需要添加参数,就可对动态页面进行爬取..
-
支持python2,python3.
1.2、框架结构

通过上面的图,我们可以看出pyspider由四部分组成
- Scheduler:任务管理,多个模块之间的协调管理控制。
- Fetcher:发送请求,获取响应,这里还可以调用phantomjs。
- Processor:对返回的数据进行提取,保存等。
- webui/monitor:可视化的方式实现脚本编写,任务管理,监控,调度,结果展示。
1.3、pyspider工作流程:
def on_start(self):
self.crawl('https://travel.qunar.com/?from=header', callback=self.index_page)
当我们启动一个pyspider项目时,默认会调用如上方法。该方法会将第一个任务加入newtask_queue(默认使用python多进程中的队列。调度器(Scheduler)会从任务队列(newtask_queue)中拿出任务交给抓取器(Fetcher),进行页面请求。将数据发送给处理器(Processor)进行数据提取,如果有继续需要请求的url,请再次调用self.crawl方法,则该任务会被加入任务队列,等待调度器进行调度
二、安装
pip install pyspider
pip uninstall wsgidav #直接安装pyspider 默认这个库版本为3.+,会报错,要使用 2.+版本。
pip install wsgidav==2.4.1
2.1、启动命令:
pyspider #在哪里启动pyspider,数据文件就会位于哪里,可以通过配置文件进行修改。
2.2、访问界面
http://127.0.0.1:5000/
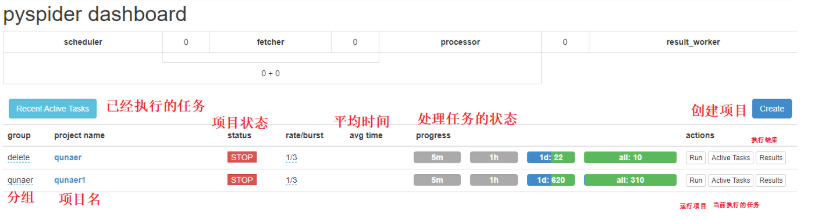
2.3、仪表盘各项功能简介
访问上面的url,我们可以进入到pyspider的管理界面
2.4、重要
-
项目状态有如下分类
TODO一个项目被创建,等待编写脚本执行STOP停止一个运行的项目CHECKING,如果我们需要对一个运行中的项目,进行修改,则应设置为该状态。DEBUG/RUNNING,我们想执行一个项目,则需要将状态设置为这两个状态其中之一。然后再点击右方的run按钮。
-
当组名设置为delete,项目状态为STOP时,24小时爬虫项目会被删除。
-
我们可以点击右方的Results查看抓取数据结果,抓取的数据默认保存在pyspider启动目录下/data/result.db
-
rate 代表每一秒发送的请求数,默认1,代表每一秒发送一个请求,数值越大,速度越快。
-
burst 当所有任务被执行完成后,处理数据时又出现新的任务时,此时会默认同时执行3个,但是第四个请求需要等待1秒,也就是rate的值。
三、糗事百科推荐笑话爬取
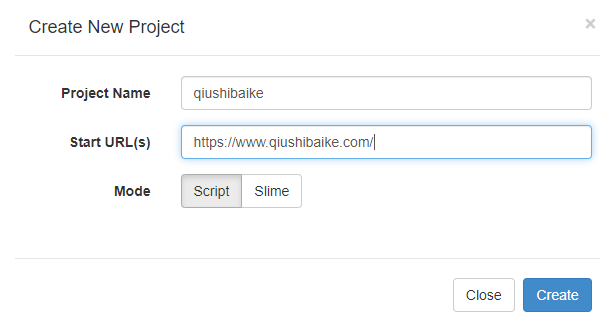
1、创建项目
2、常用工具

3、代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2020-04-09 17:40:39
# Project: qiushibaike
from pyspider.libs.base_handler import *
headers={
'user_agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
class Handler(BaseHandler):
crawl_config = {
'validate_cert':False,
'headers':headers
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.qiushibaike.com/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a.recmd-content').items():
self.crawl(each.attr.href, callback=self.detail_page)
flag=response.etree.xpath('//span[contains(text(),"下一页")]')
print(flag)
if flag:
next_url=response.doc('.pagination>li:last-child>a').attr("href")
print(next_url)
self.crawl(next_url, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
item={
"url": response.url,
"title": response.doc('h1.article-title').text(),
"content":response.etree.xpath('string(//div[@class="content"])'),
"video_source":response.doc('#article-video >source').attr("src"),
"img_urls":response.etree.xpath('//div[@class="thumb"]//img/@src')
}
return item
4、执行

5、等待一会,就可以查看到数据,可直接下载json,或者csv格式的数据。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号