

scrapy基础
scrapy-1
一、简介
1.1、安装
pip install scrapy
1.2、爬虫流程
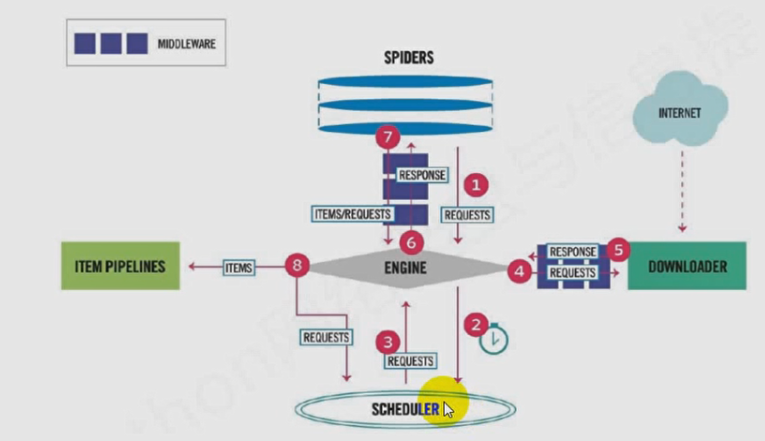
1.3、scrapy流程,文字解释
首先通过spider(爬虫)组件构建request对象,并将request对象经由scrapy Engine(scrapy 引擎) 发送给Scheduler(调度器),调度器对request对象进行整理,安排。经过 下载中间件到达下载器,下载器请求网页,返回response对象,由scrapy Engine(scrapy 引擎) 发送给爬虫组件进行数据提取,将提取出的数据发送给 Item Pipeline 进行数据的处理或者分析。
下载中间件:
- 对request对象进行修改,比如可以在此处设置代理,添加cookies,对请求头进行修改。
- 封装响应,则该请求不会交由下载器,而是直接返回,比如使用selenium访问网页,再构建response对象直接返回。
爬虫中间件:功能类似于下载中间件,但下载中间件更加常用。
二、常用命令
2.1、创建项目
scrapy startproject baidu
2.2、创建一个爬虫
scrapy genspider baidu_demo #爬虫名 www.baidu.com#限定域
2.3、爬虫文件解释
# -*- coding: utf-8 -*-
import scrapy
class BaiduDemoSpider(scrapy.Spider):
name = 'baidu_demo' #爬虫名
allowed_domains = ['www.baidu.com'] #允许爬取的域名
start_urls = ['http://www.baidu.com/'] #初始url
def parse(self, response): #对返回的响应进行解析
pass
2.4、settting.py配置文件重要配置参数
#USER_AGENT = 'baidu (+http://www.yourdomain.com)' #配置USER-AGENT
ROBOTSTXT_OBEY = False #是否遵循robots协议
#CONCURRENT_REQUESTS = 32 #同一时间的发送请求数 默认16
#DOWNLOAD_DELAY = 3 #向同一个网站发送请求的间隔,默认0
#向同一个域名或者同一个ip同时发送的请求数,二选一。
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
#COOKIES_ENABLED = False #是否保存cookies,默认保存
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} #默认请求头,按照需要更改。
#SPIDER_MIDDLEWARES = {
# 'baidu.middlewares.BaiduSpiderMiddleware': 543,
#} #爬虫中间件是否可用,数字越小优先级越高。
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'baidu.middlewares.BaiduDownloaderMiddleware': 543,
#} #下载中间件是否可用,数字越小优先级越高。
#ITEM_PIPELINES = {
# 'baidu.pipelines.BaiduPipeline': 300,
#} #配置 ITEM_PIPELINES(处理解析后的数据),是否可用,数字越小优先级越高。
2.5、简单示例
# -*- coding: utf-8 -*-
import scrapy
class BaiduDemoSpider(scrapy.Spider):
name = 'baidu_demo'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
with open('../baidu.html', 'w', encoding='utf-8') as file:
file.write(response.text)
执行爬虫
scrapy runspider baidu_demo(#爬虫名) [可选参数]
可选参数
-a 设置该爬虫的参数 格式:name=value
-o 输出文件 常用文件类型:csv、json、xml、pickle
-logfile=file(指定日志文件)
--nolog 不输出日志
-L Level(日志等级,默认DEBUG)


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何打造一个高并发系统?
· .NET Core GC压缩(compact_phase)底层原理浅谈
· 现代计算机视觉入门之:什么是图片特征编码
· .NET 9 new features-C#13新的锁类型和语义
· Linux系统下SQL Server数据库镜像配置全流程详解
· Sdcb Chats 技术博客:数据库 ID 选型的曲折之路 - 从 Guid 到自增 ID,再到
· 语音处理 开源项目 EchoSharp
· 《HelloGitHub》第 106 期
· mysql8.0无备份通过idb文件恢复数据过程、idb文件修复和tablespace id不一致处
· 使用 Dify + LLM 构建精确任务处理应用